
RetinaNet图像识别技术在煤矿目标监测领域的应用研究
2020-11-04 06:46谭章禄陈孝慈
矿业安全与环保 2020年5期
谭章禄,陈孝慈
(中国矿业大学(北京) 管理学院,北京 100083)
安全生产对煤矿企业发展至关重要[1]。目前,国内大部分煤矿企业已建成覆盖企业关键区域的视频监控系统,但相关的管理控制工作需依赖人工完成,监控系统总体上处于只监不控的状态,其自动化程度较低。究其原因,主要是技术成熟度不足,同时煤矿井下生产环境恶劣,导致井下图像成像质量较差,图像自动化识别错误率高,难以满足煤矿企业较高的需求。
现有的图像识别主要集中于理论研究层次,如人脸识别和行为识别研究等,少量研究成果被推广应用于安全监测、建筑范围划分、交通标志及道路识别、车辆检测等领域。孙继平等[2]提出了基于图像识别的矿井火灾综合判别系统;黄宏伟等[3]基于深度学习方法,提出了一种基于全卷积网络的盾构隧道渗漏水病害图像识别算法;韩豫等[4]利用图像识别技术,设计开发了一套完整的建筑工人智能安全检查系统,并在实际运行中取得了较好的效果;VISHWANATHAN H等[5]对比了Canny法、Sobel法及Zhang法3种边缘检测方法,分析了这些方法在车辆识别、路况识别及交通标志识别应用方面的优缺点;KOSZTOLANYI-IVAN G等[6]利用图像识别技术辨识道路场景,经过训练的图像分类器能较好地识别具有明显建筑或者非建筑特征的道路场景。
上述研究为图像识别技术的发展及应用做出了突出贡献,但由于技术水平的限制和应用环境的差异,图像识别技术难以向煤炭行业深入推广。随着煤矿安全管理向自动化、信息化发展,自动化目标检测技术呈现出广阔的发展前景[7]。一方面,相较于数值、文本数据,图像、视频数据能最大限度地重现目标对象的直观状态,包含的信息更加丰富;另一方面,随着视频监控系统[8-9]在煤矿企业的逐步推广,不少煤矿企业已经积累了数量可观的图片和视频数据,这些专业化的数据是提升图像识别准确度、推进图像识别理论落地的重要保障;最后,随着安全生产愈来愈受到管理者的重视,少人化乃至无人化必将成为安全管理的新的发展方向。近年来,图像识别技术获得了较快的发展,特别是基于卷积神经网络(convolutional neural networks,简称CNN)构建的目标检测器,在多个领域表现突出,利用图像识别技术弥补安全监控系统的短板,提升管理效率和煤矿自动化水平,具有重要的理论和现实意义。
1 技术方法及图像识别流程
1.1 煤矿目标监测难点
1)数据源质量不稳定,尤其是从煤矿井下工作面获取的图像、视频等数据。煤矿监控系统的建成时间较早,硬件设施性能偏低且不易更换,图像、视频的质量主要受限于摄像头等硬件的性能。同时,井下扬尘、水汽常导致摄像头镜片被污染,进而影响成像质量。
2)煤矿企业对检测器的准确率要求较高,特别是对人的识别。过高的错误率将导致大面积误判,进而影响煤矿正常生产。
3)图像识别速度难以满足使用要求。实现实时识别是企业对目标检测器的基本要求,这要求目标检测器在处理每一张图像时都必须迅速。
上述因素制约了图像识别技术在煤矿目标监测中的推广应用。
1.2 RetinaNet检测器
RetinaNet是Facebook AI团队于2018年新提出的单阶段(one-stage)目标检测器[10],其结构如图1所示。

图1 RetinaNet检测器结构
从检测器的框架来看,RetinaNet是特征金字塔网络(feature pyramid networks,简称FPN)和全卷积神经网络(fully convolutional networks,简称FCN)的结合,其中FPN是基于CNN根据金字塔概念改进而来,具有更好的特征提取效率[11];FCN同样是基于CNN改进得到,主要实现了图像的像素级分类[12]。
RetinaNet检测器由1个主干网络和2个特定子网组成。如图1(a)所示,在主干网络中,ResNet[13]用于有效特征的提取,其是一种基于CNN的特征提取网络;图1(b)中,FPN负责进一步强化ResNet形成的多尺度特征,得到包含多尺度目标区域信息的Feature maps集合;FCN子网中,图1(c)用于执行卷积对象分类,图1(d)用于卷积边界框回归。
在图像识别时,检测器一般通过交叉熵损失函数(cross-entropy loss,简称CE loss)判定预测值与真实值的差异程度。以二分类为例,目前普遍应用的加权CE loss如式(1)所示:
CE(pt)=-αtlogpt
(1)
(2)
(3)
式中:pt、αt分别为与p和α相关的系数;p为y=1时的模型估计概率,若p≥0.5则认为该样本为简单样本,y=1表示样本为正样本,y≠1表示样本为负样本;α为加权因子。
由式(1)可知,即使面对容易分类的简单样本,CE loss也会产生损失。当p值很大时,这类样本对检测器产生的影响较小。但随着样本数量的增加,产生的loss总和也增加,简单样本对检测器的影响不能忽视。虽然系数αt能够控制正、负样本的权重,但无法控制简单样本与非简单样本的权重。通过RetinaNet检测器设计了全新的focal loss,相对于加权CE loss做了进一步改进:
FL(pt)=-(1-pt)γlogpt
(4)
式中:γ为聚集参数(focusing parameter),且γ≥0;(1-pt)γ为调制系数(modulating factor)。
与加权CE loss相比,focal loss实现了对正、负样本loss的自动调节,同时降低了简单样本的loss,也提升了非简单样本的loss,从而引导模型更多地去辨识非简单样本,有效地提升了模型的准确度。focal loss相比于CE loss给loss总量带来的影响如表1所示。

表1 focal loss与CE loss的loss总量对比
实际应用时,研究者多使用进一步改进形成的加权focal loss:
FL(pt)=-αt(1-pt)γlogpt
(5)
由式(5)可知,加权focal loss能同时调整正、负样本,以及简单、非简单样本的权重。在图像识别时,如无特殊情况,则α∈[0.25,0.75],γ=2[10]。
2 实验及结果分析
2.1 实验设计
实验平台采用GTX920m GPU,操作系统为Windows 10 Professional,检测器通过Python语言编程实现。图像识别主要流程如图2所示。

图2 图像识别主要流程
2.2 评价指标
图像识别结果混淆矩阵如表2所示,在图像识别时,用混淆矩阵表示各个对象识别的最终结果。

表2 图像识别结果混淆矩阵
表2中,真正例(True Positive,简称TP)表示被模型辨识为正的正样本,数量为A;真负例(True Negative,简称TN)表示被模型辨识为负的负样本,数量为D;假正例(False Positive,简称FP)表示被模型辨识为正的负样本,数量为C;假负例(False Negative,简称FN)表示被模型辨识为负的正样本,数量为B。
精确率(Precision)与召回率(Recall)是2个主要识别结果的评价指标[14]。其中,精确率表示被模型辨识为正的正样本数占所有被模型辩识为正的样本数的比重,计算公式为:
(6)
召回率表示被模型辨识为正的正样本数占所有正样本数的比重,计算公式为:
(7)
2.3 参数配置
RetinaNet检测器在使用时需预先确定ResNet网络层数、α值及概率阈值参数(minimum percentage probability)等参数。利用MS-COCO数据集[15]训练生成的不同参数下的识别模型,设计预实验选取最佳参数。
ResNet是RetinaNet检测器的重要组成部分,ResNet网络深度越深,则RetinaNet检测器的计算复杂度越大[12]。为了获取性能与速度的平衡,用独立的ResNet搭建目标检测器,仅改变ResNet网络层数,预实验不同网络深度下ResNet错误率如表3所示。
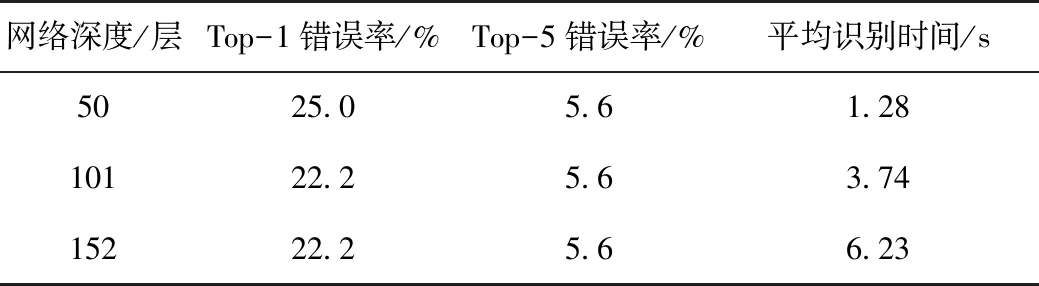
表3 预实验不同网络深度下ResNet错误率
由表3可知,网络深度为50层的ResNet错误率略高,但识别速度最快,若选择网络深度为50层的ResNet,耗时相比网络深度为101层和152层的ResNet可减少一半以上。鉴于图像识别的实时性需求,设定网络深度为50层。
其实,长期以来,个股长期停牌后暴跌的例子不胜枚举。*ST天马(002122.SZ)自去年12月19日停牌至今年5月14日,复牌后*ST天马连续29个一字跌停,市值缩水近80亿元,蒸发了近76%。这也打破了*ST保千(600074.SH)连续28个一字跌停的纪录。
α值作用于focal loss,是影响RetinaNet检测器的关键要素之一。设定ResNet网络深度为50层,概率阈值参数为0.3,仅改变α的取值,预实验RetinaNet不同α错误率如表4所示。

表4 预实验RetinaNet不同α错误率
由表4可知,当α=0.25时检测器性能最好。因此,设定α=0.25。
概率阈值参数作用于被呈现的结果,检测器会对每一个可能的对象给出一个概率值,即被检测对象有多大的可能性是检测器判定的目标,如果概率值小于概率阈值参数,则该概率值不被呈现给使用者。设定ResNet网络深度为50层,α=0.25,仅改变概率阈值参数的取值,预实验RetinaNet不同概率阈值参数实验结果如图3所示。

图3 预实验RetinaNet不同概率阈值参数实验结果
由图3可知,在概率阈值参数为0.3时,检测器的综合表现最好,因此,设定概率阈值参数为0.3。
综上,在正式实验中,设定ResNet网络深度为50层,α=0.25,概率阈值参数为0.3。
2.4 图像识别结果分析
选择包括井下巷道、工作面在内的50幅相关图像,对其随机编号进行实验。测试图片的清晰度均不同(图片每英寸像素点数量在72~300内)。图像识别实验结果如表5所示。
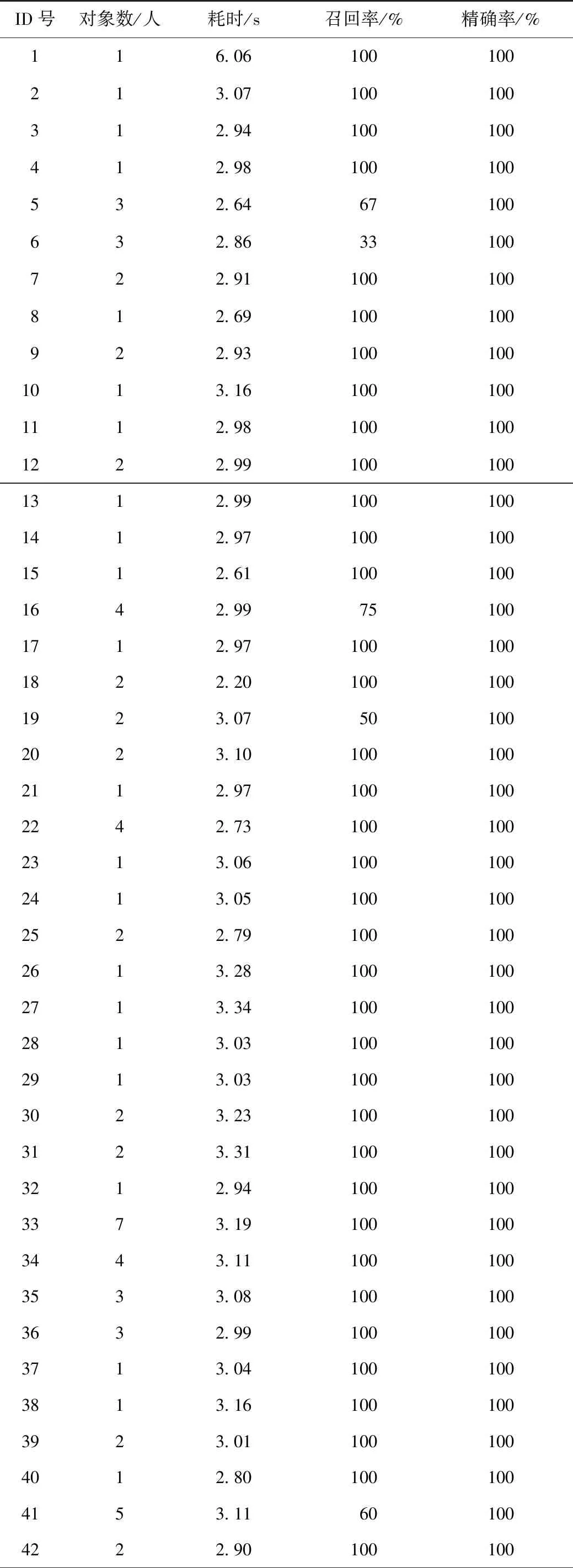
表5 图像识别实验结果
表5中ID号表示图片编号,对象数表示图中的人数。实验表明,RetinaNet检测器对人物的识别速度较快,被检测出的样本中,人物均能被正确识别。同时,RetinaNet检测器有着较高的召回率,能够有效地抓取并识别所要识别的对象。在实验环境下,检测器已表现出良好的性能,平均召回率为92.78%,平均精确率为100%,体现出较好的实用价值。在部分样本中,RetinaNet检测器的召回率并不理想,具体案例如表6所示。

表6 图像识别实验案例
表6中,图例为被识别图像全图,对表5、表6分析可知:
1)图像的分辨率对图像识别的结果影响不大,因为分辨率较高的图像,并不一定包含更多的有效信息,过多的背景噪点会影响识别结果。
2)图像中的对象与周围环境的对比度会影响图像识别的最终结果。如图片5、16、19中各有一人衣着与背景色极为相近,难以辨识出清晰轮廓,所以未能被识别。
3)人物重叠对图像识别效果的好坏影响极大,如图片6、41中,虽然人物轮廓清晰,但是由于人员相互遮挡,所以识别效果并不理想。
4)从实时性的角度分析,每张图片的识别时长在1 s上下浮动。权威的研究结果[16]表明,若通过更高算力的GPU运行检测器,同时采用分布式计算技术,其识别速度还能进一步加大,从而实现图像识别的实时性。
2.5 视频识别结果分析
视频识别是检测器以视频的帧为单位,对每帧图像进行辨识。视频识别实验结果如表7所示。

表7 视频识别实验结果
表7中,ID号表示视频编号,总帧数表示视频画面的总帧数,精确率表示对每帧画面识别后的平均精确率,召回率表示对每帧画面识别后的平均召回率。从视频识别的结果来看,检测器对人物基本实现了准确有效地识别。由表7可知:
1)视频2与视频5中,人员与背景的区分度较为明显,尤其以视频2的效果最佳。视频2由井下红外摄像机拍摄,视频5中画面的整体环境明亮,检测器对两视频中的人物基本实现了及时跟踪监测。
2)实验视频的帧数不一,在整个识别过程中,井下人员一直处于有效监测中,表明检测器对视频识别具有较好的稳定性。
3)在视频1、3、4中,背景环境复杂,检测器的召回率较差,难以保证识别每一个目标对象。但检测器仍能保证较好的精确率,被识别的对象基本都能够被正确辨识。
实验结果表明,在合理设置检测器参数的前提下,视频画面中待识别对象与背景的区分度是检测器快速、准确识别的关键;由检测器的监测效果可知,企业无需更新煤矿的监控设备,在现有设备的基础上,只需要合理地搭建检测器,即能实现较好的自动识别效果。实际应用时,在满足需求的前提下,无需通过检测器对视频对象中的每一帧进行检测,而是选取单位时间内的最优判别结果作为识别对象,即可降低误判,提升识别效率。
3 结论
1)RetinaNet检测器在煤矿目标监测中显示出较好的可靠性和稳定性,在实验过程中表现出了较高的精确率,RetinaNet检测器具有较强的实用价值。
2)由于人与环境对比度不足,检测器的召回率有待进一步提高。增强识别对象与背景的区分度能够改善目标监测的效果,企业对一些日常细节的改进,能够有效提升检测器的识别率。将图像识别系统与煤矿企业现有的人员定位、煤矿监控系统深度结合,可实现对煤矿井下高危区域的自动监测,能进一步提高煤矿企业安全管理的信息化水平。
3)现阶段,专业的图形数据不足是制约检测器性能的重要原因之一,为了提高检测器的识别能力,煤矿企业有必要建立类似MS-COCO的标准化图片数据集,以便于更准确地训练模型,进而发掘数据的深度价值,进一步实现场景辨识、危险行为辨识、危险源辨识等深层次的功能。
猜你喜欢
中国交通信息化(2022年2期)2022-04-26
建材发展导向(2021年19期)2021-12-06
临床骨科杂志(2020年1期)2020-12-12
商品与质量(2020年18期)2020-11-27
电子制作(2019年16期)2019-09-27
电子制作(2018年19期)2018-11-14
火力与指挥控制(2018年10期)2018-11-13
电子制作(2018年14期)2018-08-21
电子制作(2017年10期)2017-04-18
