
基于Hadoop的交通视频大数据监控方案
2020-11-05 03:18李晓蕾
液晶与显示 2020年11期
李晓蕾
(宁波财经学院,浙江 宁波 315175)
1 引 言
在交通道路维护中,实时交通监控是一项复杂而富有挑战的任务。传统的交通监控系统的监控方案从高清摄像机中获取或存储数字视频到计算机中,其流媒体数据通过mysql等数据库技术保存数据,而交警则通常采用手动记录行驶的车辆,通过路边运动摄像机对车辆进行计数的方法来进行人工监控。如果视频分析没有自动完成,则需要大量的人工操作,并需要多方协同来手动分析视频中的场景。这些方法的人力成本和时间成本都相对昂贵。特别是交通事件的发生最常见的问题是车辆的颜色、尺寸和类型,这些信息用人力往往很难准确地捕捉到,并且时常存在误差。基于视频流的分析可以辅助交警或者交通管理人员对交通现场进行快速处理,可以极大提升交通道路的安全性,因此视频流分析技术一大重要应用场景便是自动化安全和监视系统。执法机构、交通监控工作站和组织都可以将视频分析技术用于公共安全。与手动应用程序相比,自动视频分析需要较少的成本和人力来分析视频流,因此得到了学术界和工业界的青睐。许乐等研究者用自动化的视频分析研究不同自动化系统视频图格式,实现格式之间的转化,减轻了数据维护人员的工作量[1]。视频分析还可以帮助检测人脸、车辆颜色和车牌等物体,完成自动对象检测、目标分类等复杂的计算机任务[2]。其中对象检测是交通监控系统和执法机构应用中最常见的技术之一,最常见的算法是模板匹配[3],使用高斯混合模型(GMM)进行背景分离[4]和级联分类器[5]。模板匹配仅适用于模板中定义的对象,但是这类方法计算量巨大,不适用于新对象时常出现或者消失的场景,因此不适用于交通视频。背景帧提取方法是一种检测在背景中移动的对象并分离出来的方案,但是背景分离和帧差异也面临计算成本高昂的问题,通常不适用于实时处理。江鹏宇用级联分类器AdaBoost算法对运动目标区域进行行人检测,减小视频中背景的干扰,加快检测速度,并利用卡尔曼滤波算法和匈牙利最优匹配算法对视频监控中的行人进行跟踪{6}。近年来Hadoop快速发展,为大规模数据处理提供了高效的解决方案。毕莎莎针对实时云转码系统中已转码的视频媒体文件重新使用率不高的情况,引入转码缓存机制,采用云存储空间缓存视频,根据视频资源的流行度和请求间隔来实时替换出效能值较小的视频[7]。刘云恒等学者采用基于Hadoop技术的视频大数据处理平台,并采用以Map-Reduce算法为基础的人脸检索与识别算法来实现公安视频大数据的智能信息处理[8]。
2 基于Hadoop的交通视频分析技术
2.1 基于Hadoop的视频分析
使用基于Hadoop的GPU集群进行视频流分析可以从不同的资源(如GPS、社交媒体、物联网、平板电脑、Web服务和视频)生成大量数据[9]。在传统的数据库技术中,分析处理和存储视频数据是一项艰巨的任务[10],为了处理大量视频数据,可以在不同节点之间分配处理。大范围内可能有数百个甚至更多的摄像机在本地服务器上捕获流和过程。视频流分析需要大规模的计算,当前很多企业采用云计算来完成这类海量计算,云计算可提高实时监控交通视频数据的效率。商业供应商还提供视频分析应用程序。一个最常见的做法便是将Hadoop用于将视频帧拆分为较小的单元,并以并行模式将它们转换为一系列图像帧。 HDFS通过多个物理磁盘群集存储大量数据。分割成较小单元后的序列文件分布在HDFS的节点上,以提高处理速度。原始视频流分为64 MB(默认)大小的块[11]。录像模块将视频流传输到监管站,并将视频存储在其本地存储中。视频流是从不同的地方捕获,并由IP无线传输模块通过媒体服务器传输到监控站。实况视频流由监管站处理,并存储结果以供进一步分析。有关车速、事故和交通拥堵,以及城市主要站点和线路可以存储在Hive里。当道路拥堵发生时,Hive表可以向旅行者建议替代路线,当检测到道路交通事故时,系统会向附近的医院和公路救援队发送警报。
2.2 算法步骤
对于交通视频数据分析,交通异常的检测是最重要的部分之一,在国内的交通事故中,90%以上交通事故都和道路拥堵有关。因此本文重点研究Hadoop下交通拥堵的检测和分级。
本文提出算法的主要核心是根据Hadoop中交通视频得到的路网历史数据,对每个车道的合理速度值进行整理和清晰,根据整个路段中每个时段不同方向上的信息,对每个路段每个时段的拥堵概率进行先验判断。通常来说,每个道路的拥堵状态都具有一定的周期性特点,特别是对于工作日而言,其出行规律具有较高的相似性。因此本文采用将1天24 h分为若干个时间段,统计各个时间段的拥堵概率。其主要流程如下:
(1)原始数据预处理:由于原始数据在采集过程中可能存在数据丢失、数据监测出错等情况,因此首先用预处理进行修正。将交通视频的流量、速度和交通指挥部门的历史数据进行对比,将超过阈值范围内的流量和速度定义为错误数据进行修正,为了简化处理的复杂度,本文将超过阈值范围内的数据和缺失的统计数据用历史平均数据来代替。
(2)交通拥堵判断:本文将一天分解为144个时间段,每隔10 min是一个时间单位,在此基础上计算如下指标:
车道占有率:
(1)
(2)
式中,N是一个方向上的车道个数,车道占有率定义为汽车占用道路的时间比,i代表第i个车道,T代表观测时间。
(3)
(4)
式中,speedi代表i车道的速度,vi代表i车道的流量。将交通部门在某一车道的历史速度求解平均值,如果当前速度speedi低于历史平均值,则认为可能出现了拥堵。
(3)拥堵率计算
某个时间点内拥堵率计算如下:
(5)
式中,h代表对应的时间段id,M是h时间内通过车速低于历史平均值的次数,N是统计数据中历史数据个数。
(4)计算路段异常度
本文将路段异常度定义为某天道路拥堵的异常程度,该指标的数值越高,则路况越拥堵,发生交通状况的可能性也大幅提高,因此需要交警部门进行疏导,从而避免事故的发生。异常度的计算流程如图1所示。
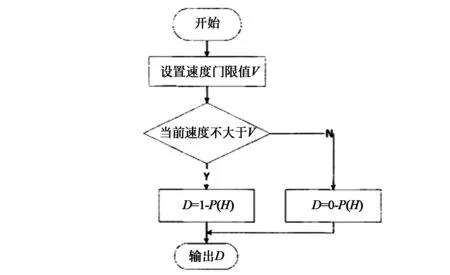
图1 异常度计算流程Fig.1 Calculation flow of abnormality degree
从图1可以看出,在当前速度大于阈值V时,D=0-P(H),即异常度为负值(代表没有交通异常发生),而当当前速度低于阈值V时,则异常度为正值。
(5)数据实时更新
随着时间的推移,道路周边基础设施如写字楼的建成、地铁的运营等因素,历史拥堵数据会发生变化,因此需要采用实时更新的方式来保证历史数据的准确性。当然交通视频历史数据的更新本身较为耗费计算资源,为了减少不必要的重复计算,本文提出的分片更新算法如图2所示。
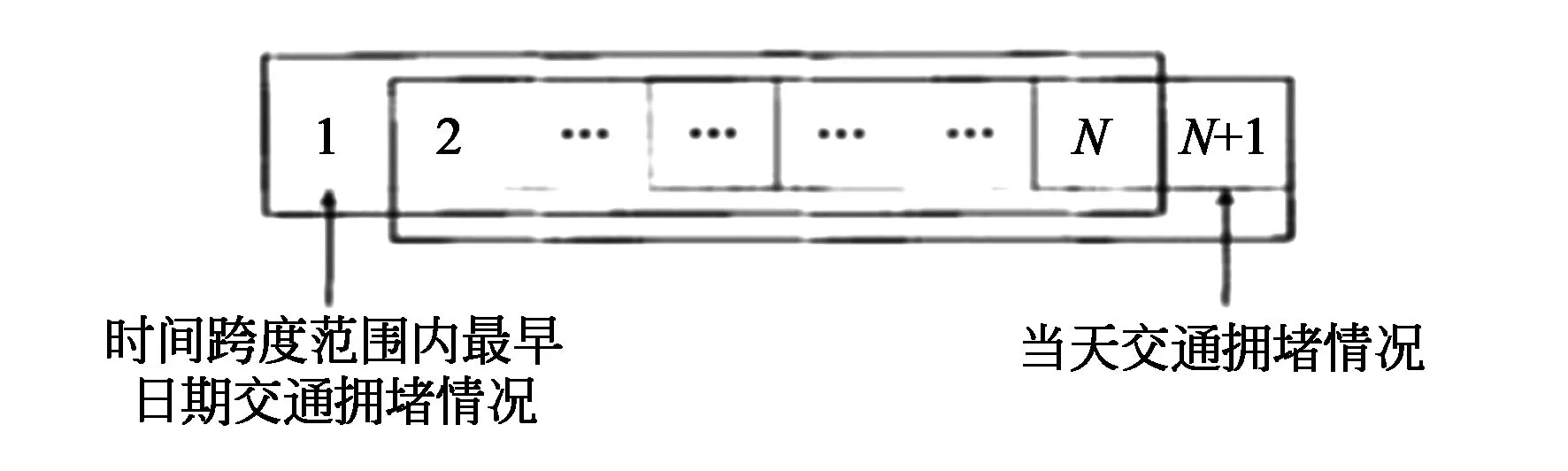
图2 历史数据更新算法示意图Fig.2 Schematic diagram of historical data update algorithm
更新算法的核心是将时间跨度范围内最早日期的拥堵状况与当前的状况进行比较,如果交通情况从拥堵恢复为不拥堵则记为M=-1,否则记为M=1。
2.3 基于Hadoop的拥堵检测分布式计算
从上述关于异常拥堵的算法中,可以看到由于本文算法对实践切割相对较细,因此要获得全天144个时间段的拥堵情况,需要计算车道占有率、车道交通流量、车道平均速度,其计算复杂度较高,为了提高计算效率,本文采用分布式并行的方案来加快算法的运行时间。本文采用Hadoop的MapReduce架构,利用HDFS将数据冗余备份,由于MapReduce的本地化数据技术能尽量减少网络IO,而且节点可以自适应实现负载均衡,因此本节的重心放在MapReduce的计算模型。
对于车道占有率,在MapReduce计算的Map阶段,我们将数据按行切分,将代表时间段的字段COLLECT_TIME划分到不同时间槽中,具体的时间段用time_id作为key,occ代表拥堵情况。在Reduce阶段,对于相同的key求解value的算术平均值就可以获得平均占有率。
对于车道流量,本文在一个时间段内的某条道路进行计算,设road_id为道路的id,flow为流量,因此将road_id和time_id设置为key,flow设置为value,对于相同的key求解所有value的和就得到了总流量。
对于车辆的平均速度,本文利用同一个道路上不同路段的way_id的数据speed、flow进行汇集,将way设置为key、speed,flow设置为value,在reduce阶段,式(3)和(4)可以分别算出车道平均速度和总速度。
3 实验及结果分析
本文选取浙江省某市的交通视频监控的200个采集点的数据进行分析,其交通视频监控设备如图3所示。

图3 交通视频监控画面Fig.3 Traffic video monitoring screen
标注出该组的道路编号,车道标号way_id,车道流量为total_flow,speed是总速度,occ是车道占有率,本文的实验流程如下:
(1)数据预处理,如前文所述,由于视频数据在分析过程中,可能存在一定的误判或者丢失,因此为了提高数据的容错能力,本文先进行预处理。其预处理规则见表1。

表1 错误数据判别原则Tab.1 Error data discrimination principle
将上述数据按照“阈值关系理论” 进行处理, 不符合要求的数据标记为无效数据并进行修正。
将经过预处理的数据按照144 个10 min时间段从0点到24点的顺序进行排列,按照式(1~5)计算出当前的历史拥堵概率。 结果如图4所示。从图中可以看出,上午11∶00到11∶45拥堵概率接近45%, 下午18∶00 到19∶00拥堵概率在70%左右。
本文在选取了2019年8月16日的交通数据进行异常度分析,其结果如图4所示。

图4 拥堵情况计算结果Fig.4 Calculation results of congestion
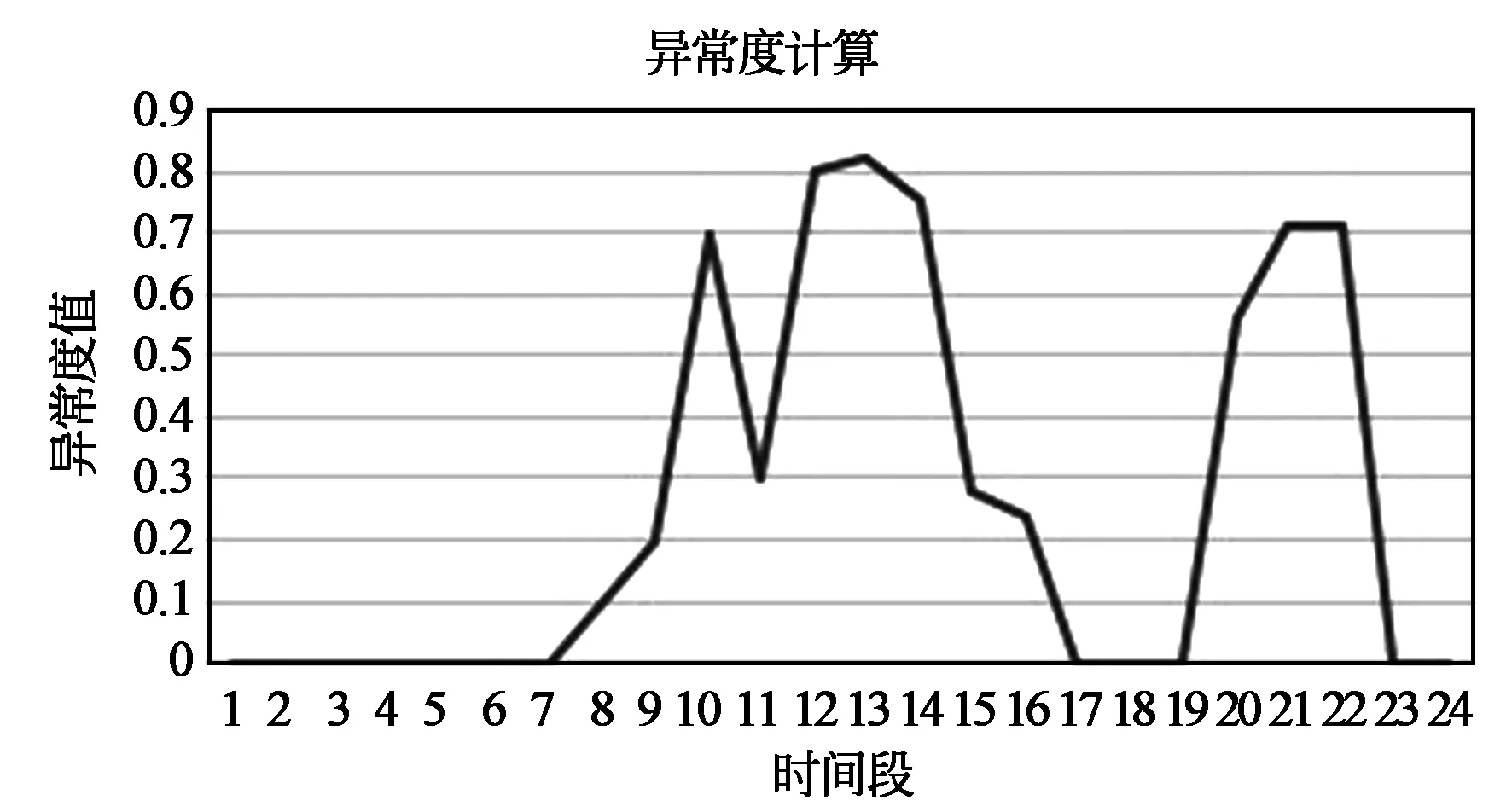
图5 异常度计算Fig.5 Calculation of abnormality degree
通过异常度计算(如图5所示),可知,异常度的取值在[0,1]之间,可以看到9∶50,13∶00,21∶00出现了明显的异常,通过调取该市当时的交通监控视频,我们发现这几个时间点都出现了不同程度的交通事故,引起了车辆的缓行,最后导致道路流量产生了异常。
在计算复杂度上,本文采用传统的分布式架构方案进行对比,在10台8核16G的分布式服务器和对等的Hadoop集群中,选取2018年8月16日的交通视频进行计算,用计算延迟和处理时间来代表算法结果,统计如表2。

表2 计算延迟统计表Tab.2 Statistics of calculation delay
可以看到,本文提出的基于Hadoop方案的计算延迟可以控制在每10 min 2.1 s,基本可以满足实时分析的需求,同时可以看到传统分布式算法的计算延迟和计算总时间随着时间的加长有恶化的趋势,但是本文方案可以有效避免这一情况。
4 结 论
本文对Hadoop大数据背景下的交通视频监控技术进行了深入研究,并对交通路况异常拥堵进行了分析, 然后阐述了基于交通视频数据的异常堵点检测算法的设计方案,利用拥堵概率、交通异常度等概念为交通状态分析提出了精确指标。 针对海量交通监控视频,本文设计了基于Hadoop组件MapReduce的并行实现算法,最后通过浙江省某市的实际交通数据验证算法的有效性和准确性。经过实验证明,本文算法可以有效计算出交通拥堵情况和异常情况,对大数据背景下海量交通监控视频的分析提供有益参考。
猜你喜欢
无线互联科技(2022年11期)2022-08-18
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中国交通信息化(2020年11期)2021-01-14
数字通信世界(2020年11期)2020-12-04
今日农业(2020年13期)2020-08-24
物流科技(2017年5期)2017-07-06
意林(2017年8期)2017-05-02
办公自动化(2016年13期)2016-08-24
医学研究杂志(2015年5期)2015-06-10
