
基于Twitter大数据处理的境外舆情分析系统设计与实现
2020-11-10 04:38刘斌
电脑知识与技术 2020年27期

摘要:境外舆情对于我国的国际形象和国内的稳定具有重要作用,是国家安全的重要部分。通过对Twitter数据分析,该文设计了基于Twitter的境外舆情分析系统。该系统使用Twitter提供的APl数据作为数据源,使用自然语言处理的方法进行数据清洗,通过数据挖掘方法对数据进行大数据分析,最后通过工具进行可视化展示。
关键词:社交网络;境外舆情分析;大数据挖掘;Twitter
中图分类号:G350 文献标识码:A
文章编号:1009-3044(2020)27-0030-04
开放科学(资源服务)标识码(OSID):
1 背景
舆情是公众对社会现象、问题、信仰、态度、情绪等的反应。境外舆情对于我国的国际形象和国内的稳定具有重要作用,是国家安全的重要部分。通过境外舆情进行分析系统,及时发现并处理不利于我国的舆论是十分必要的。
Twitter[1](官方中文译名推特,但繁体中文和简体中文的界面均记作Twitter)是一个社交网络与微博服务,它可以让用户更新不超过280个字符的消息(中文、日文和韩文为140个),这些消息也被称作“推文(Tweet)”,是全球使用最多的社交网络服务。
Twitter是互联网上访问量最大的十个网站之一,世界排名前100名的公司中已经有73%出现在了Twitter上,比尔·盖茨、Lady Gaga、FBI、美国红十字会、卡塔尔半岛电视台等很多名人和组织都通过Twitter与大众进行互动,甚至还有60余位国家首脑活跃其中。从个人的生活琐事至官方代言、企业营销,再到全球性的新闻事件,以Twitter为代表的微博网站作为互联网Web2.0时代的最新的应用,凭借其对信息传播模式的变革影响着这个世界的沟通方式与生活方式。因此,Twitter数据十分适合进行境外舆情分析。
2 系统设计
通过对Twitter平台进行分析。它与其他数据分析系统有相当大的区别:
1 )Twitter在国内无法访问,需要使用境外代理服务。
2)Twitter数据是以数据流的方式进行传输,需要使用Twit-ter自身的数据传输接口[2-4]。
3 )Twitter数据的键值的特殊格式需要使用NoSQL方式进行存储。
4)舆情分析主要任务包括发现目前流行的话题和话题的导向。
系统分为五个部分,系统结构如图1所示:
1)舆情数据抓取:使用python的tweepy[5]工具包来获取Twitter数据。
2)舆情数据预处理:使用NLTK[6]工具包来进行数据预处理。
3)舆情数据存储;使用NoSQL数据库MongoDB[7]来存储数据。
4)舆情数据分析:使用GemSim[8]发现舆情主题,使用vad-erSentiment[9]进行主题情感分析。
5)分析结果可视化:使用Flask[10]开发web应用,使用mat-plotlib[11],D3.js[12]和wordcloudn3]来进行数据可视化。
2.1 Twitter数据抓取
基于Twitter Streaming API[6]的Twitter实时数据抓取。Twit-ter公司为了便于开发者使用Twitter的数据,提供了开发者平台,该平台提供了不同的API接口,用于调取不同的Twitter数据。该接口分为两大类:‘rwitter REST API和Twitter StreamingAPI。Twitter REST API用于读写Twitter数据,包括用户资料、用户推文、用户好友、用户时间轴、检索推文、地理位置信息、区域话题趋势等等。Twitter REST API使用Twitter应用和用户提供的OAuth信息进行身份验证,返回结果是JSON格式数据。Twitter Stream API用于实时的监控和获取Twitter数据流。
OAuth(开放授权)是一个开放标准,允许用户让第三方应用访问该用户在某一网站上存储的私密的资源(如照片,视频,联系人列表),而无须将用户名和密码提供给第三方应用。Twitter OAuth由以下四个部分组成:consumer key,consumer se-cret.access token和access token secret。JSON这种数据格式的特点是,冗余少,数据结构清晰,非常适用于对数据的抽取分析。
Twitter的Streaming API提供给开发者获取Twitter全球实时数据流的途径。通过该方法抓取的Twitter实时数据流,效率高质量好,但由于抽样获取数据不齐全。Twitter Streaming API包括三个方面Public Streams,User Streams和Site Streams。一般使用Public Streams,Twitter Streaming API和REST API的区别如图3,图4所示。
为了便于使用本系统使用基于python实现的Twitter API工具包tweepy來调用Twitter Streaming API获取实时数据。tweepy工具包可以使用地理坐标信息或关键词信息来获取实时数据。
2.2 Twitter数据预处理
Twitter数据文本含有很多标签、注释、标签和地址等特殊符号的情况,综合使用Python自然语言处理工具包NLTK和正则表达式等工具对其进行数据清洗。主要处理过程包括,提取词元(token)、词根化(stemming),保留表情、标签等特殊符号,去停用词.完整的Twitter数据预处理过程如图4所示。
2.3 数据存储
通过Twitter Streaming API抓取的数据格式JSON,先分析该JSON文件的结构,如表1所示。
从结构中我们可以选出重要的字段,“text”推文的文本内容,“created at”推文创建时间,“favorite count”喜爱的成员个数,“retweet count”转推成员个数,“retweeted”是否被转推,“Lang”语言,“id”推文的标识,“entities”推文中实体名:如URLs,hashtag,“place”推文发布位置信息,“user”推文发布者信息和“source”发送推特源等字段。
这种用JSON格式数据的键值性数据,并不适合存储在关系型数据库中。可以存储到MongoDB这样的NoSQL型数据库,使用它存储twitter数据最大的好处是大大地压缩存储空间,而且对于大量数据可以提供强大的查询操作和检索机制,分析处理过程。
在python中使用pymongo[15]来对mongo dB数据库进行操作,对于获取的每一条twitter数据只需要将我们关心的推文内容,地理位置,标签,创建时间,语言,发送源等字段信息保存起来即可,大幅减少需要存储的数据量。存储在mongodb数据库中状态,可以通过命令行查看(如图5),也可以通过可视化软件Rob0 3T[16](如图6)来加以查看。
2.4 twitter热点主题发现
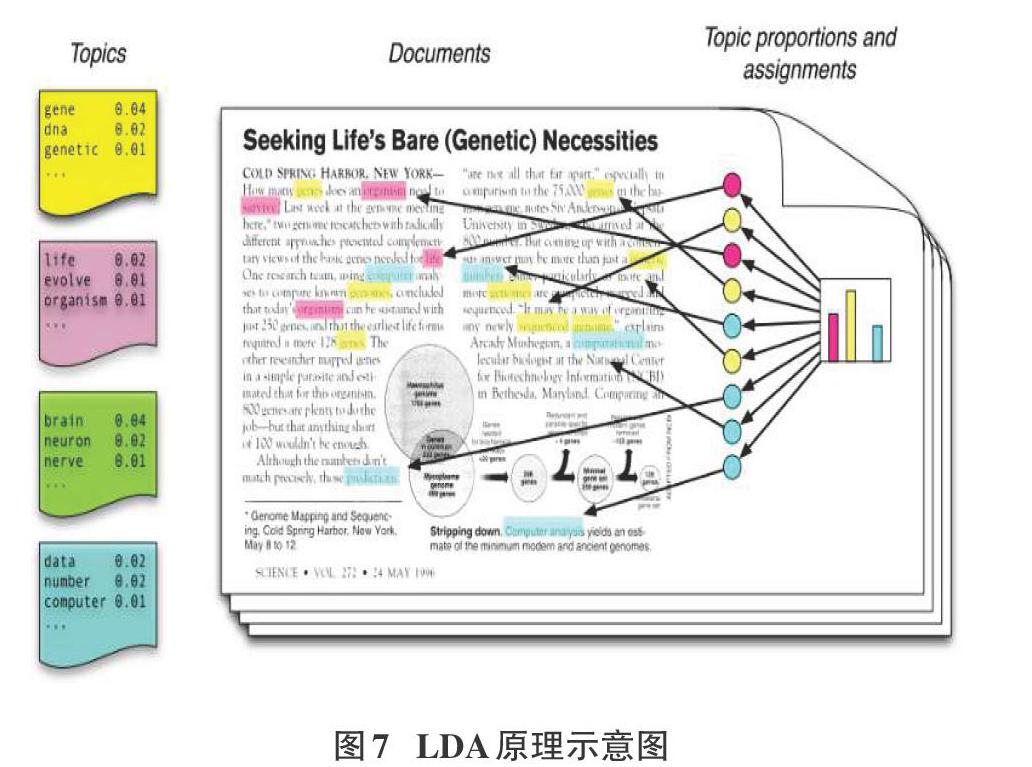
隐含狄利克雷分布简称LDAn[17](Latent Dirichlet allocation),是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。LDA方法原理示意图如图7所示。
LDA是一种典型的词袋模型,即它认为一篇文档是由一组词构成的一个集合,词与词之间没有顺序以及先后的关系。一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
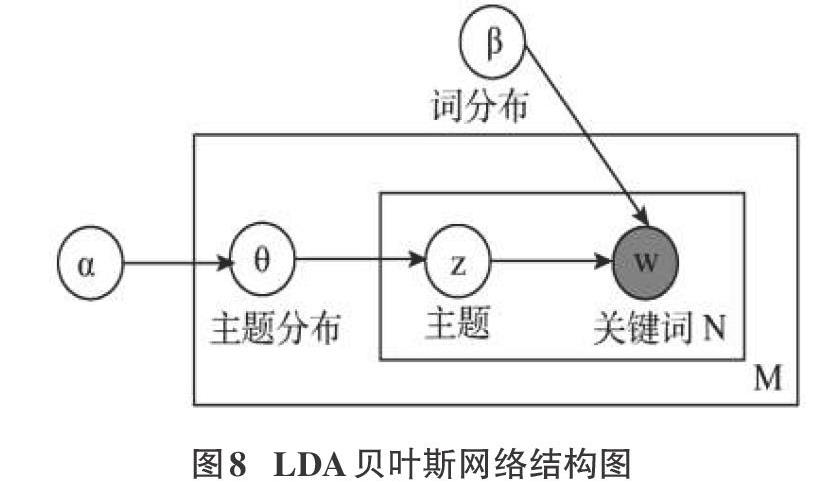
狄利克雷分布作为多项式分布的共轭先验概率分布。因此正如LDA贝叶斯网络结构中所描述的,在LDA模型中一篇文档生成的方式图8所示。
但GemSim库已经提供了所有需要的基本功能。通过以下步骤使用GemSim提取LDA主题模型:
1)获取语料。
2)文本预处理。
3)LDA分析。
4)显示结果。
表2为使用GemSim建立里约2016奥运会LDA话题模型代码示例。图9为获得的十大话题。
2.5 twitter情感分析
文本情感分析是以情感为计算对象,对文本的正面和负面情绪等不同情绪,通过工程方法进行分析处理,得出情感倾向性的计算过程。通常情况下,文本情感分析被当作分类问题来处理。与常规的文本分类问题不同的是情感分类的类别标签是情感因素。文本情感分析可分为二分类和多分类。前者是将文本情感分為正面和负面;后者是将情感细化为高兴、悲伤、愤怒、害怕、憎恨等。按照文本情感分析的粒度大小,文本情感分析可划分为词语级别的情感分析、句子级别的情感分析和段落级别的情感分析。情感分析也称为观点挖掘,是自然语言处理的核心研究内容之一。其研究目的是使用自然语言处理手段对文本中体现的个人观点情感进行分析、评估。
为了高效地对twilter文本进行情感分析,本系统使用py—thon的基于情感词典的VADER分析包vaderSentiment,进行情感分析,而且实验证明它对于mitter这样的微博分析尤其出色。其情感词典不仅包括了很多的带有很强感情色彩的词语及对应的分值比例还包括了twitter数据中可能会出现的表情符号的感情分值和比例,因此对于twilter的情感分析十分高效精确。开发vaderSentiment分析包的佐治亚理工学院的C.J.Hutto等人,通过实验分析出对于小而多的社交网站数据的情感分析,使用vaderSentiment效果更好。
2.6 数据可视化
数据可视化是数据挖掘的一个重要的部分。数据可视化借助图形化手段,清晰有效地传达与沟通信息。数据可视化与信息图形、信息可视化、科学可视化以及统计图形等有密切关系。数据可视化为人类洞察数据的内涵、理解数据蕴藏的规律提供了重要的手段。
本系统采用使用python T具包matplotlib实现数据分析可视化,使用JavaScript包D3.js实现数据动态可视化,使用python的wordcloud包实现词云图。
3 系统实现
通过本文设计的系统分析当前编程语言的流行程度,得出在twitter上Java、Python、C++的正面、负面和一般评价。
3.1开发语言和环境
开发语言主要为python,开发环境如表3所示。
3.2实验结果
通过抓取得到4个小时的twitter数据。图10为对编程语言的分析结果python在twitter上关注度最高,其次是Java,最后是C++,这也与现实中python目前是最热门的编程语言相符。对于三种编程语言的正负面评价,对于python的正面评价最高。
4 总结
本文设计并实现了基于Twitter大数据的境外舆情分析系统,通过实例证明了该系统可以较好地满足要求。但本系统只可以使用文字信息,为了将要研究如何将Twitter图片和视频信息也进行分析和处理,这将取得更好的效果。
参考文献:
[1] Twitter[EB/OL]. [2020-02-20]. https://zh. wikipedia. org/wiki/Twitter.
[2] Ali D. Mining the social web: data mining facebook, twitter, Linkedln, google+ , github, and more, by Matthew A. RusseII[J].Journal of Information Privacy and Security, 2015, 11(2): 137- 138.
[4] Twitter development document[EB/OLl. [2020-02-20l. https://dev.twitter.com/overview/documentation.
[5] Tweepy: an easy-to-use python library for accessing the twit-ter api[EB/OL].[2020-02-20].http://www.tweepy.org/.
[6] N LTK[E B/OLl.[2020-02-20l.https ://www.nltk.org/.
[7] Mongodb[E B/OL].[2020-02-20].https://www.mongodb.com/e n.
[8] GemSim[EB/OLl. [2020-02-20]. https://sourceforge. net/projects/gemsim/.
[9] VaderSentiment[EB/OL]. [2020-02-20]. https://github. com/vad-erSentiment.
[10] flask[E B/O L].[2020-02-20l.http://flask.pocoo.org/.
[11] matplotlib[EB/OL].[2020-02-20l.https://matplotlib.org/.
[12] d3.j s[E B/OLl.[2020-02-20l.https://d3j s.org/.
[13] wordcloud[EB/OL]. [2020-02-20]. https://amueller. github. io/word_cloud/.
[14] "Twitter's API - HowStuffWorks[EB/OL].[2020-02-20].https://computer. howstuffworks. com/intemet/social-networking/net-works/twitter2.htm.
[15] pymongo[EB/OL]. [2020-02-20]. https://api. mongodb. com/py-thon/current/tutorial.html.
[16] Rob0 3T[EB/OLl.[2020-02-20].https://robomongo.org/.
[17] LDA[EB/OL]. [2020-02-20]. https://en. wikipedia. org/wiki/La-tent_Dirichlet_allocation.
作者簡介:刘斌(1983-),男,中级工程师,硕士,研究方向为大数据挖掘、自然语言处理。
