
Spark平台下电影推荐系统的设计
2020-11-12 10:38李光明房靖力
计算机应用与软件 2020年11期
李光明 房靖力
(陕西科技大学电子信息与人工智能学院 陕西 西安 710021)
0 引 言
随着计算机网络的迅速发展,各种大型网站在实时建立和更新[1]。随着各类网站的建立,产生了大量的数据信息。在当今大数据时代[2]的背景下,人们逐渐从信息匮乏的阶段过渡到信息爆炸的阶段,在面对如此巨大的信息量时如何从大量信息中快速有效找到对自己有用的信息显得尤为重要,个性化推荐系统由此产生。
个性化推荐系统的核心是推荐算法模型的建立和算法模型运行平台的运行速度。近年来,推荐算法在不断发展,文献[3]利用深度学习结合基于用户的协同过滤算法进行个性化推荐;文献[4]采用自注意力与Metric Learning结合学习用户的短期爱好进行精准推荐;文献[5]基于协同注意力机制,对用户与物品的若干相关评论进行选择,选出最重要的信息进行推荐。以上几种推荐算法在实验中都取得了不错的推荐效果,但是针对搭建一个运行于Spark分布式集群并对平台中MLlib的协同过滤算法的优化还有待进一步的研究。
对于同时考虑算法模型以及算法模型运行平台速度的研究,虽然从单机版的推荐系统产生,到如今的智能化、个性化推荐系统,经历了许多的技术架构演变,常见的推荐系统有基于Mahout的推荐系统[6]、基于Hadoop[7-8]的个性化推荐系统等。但推荐系统还面临以下挑战:(1) 随着数据量不断加大以及用户对推荐效果的要求不断提升,使用传统分布式技术架构的推荐系统平台的迭代计算速度已经远远落后[9]并且会出现推荐效果差的情况,因此技术架构需要有较大的改变与提升;(2) 当选择的数据文本存在着评分矩阵较为稀疏时[10],对最终的推荐结果准确性也会产生一定的影响。
由于Spark分布式技术近年来已经趋于成熟,目前已广泛应用于大数据量的处理方面,针对以上问题,本文结合Spark分布式技术对推荐系统进行设计,主要贡献如下:(1) 使用包括Hadoop、Flume、Kafka、Spark,及Spark生态圈[11]内组件Spark Streaming等进行推荐系统架构设计,并使用JavaEE[12]对系统展示端与数据管理端进行设计实现;(2) 融合基于改进后的余弦相似性的协同过滤[13]及基于用户喜爱物品的物品协同过滤并加入一个平衡因子ω解决因不同用户评分方式不同导致的数据不一致性。
1 Spark平台与系统设计
1.1 Spark平台架构
Spark平台包括Spark Core基本处理框架、Spark SQL结构化数据的分析查询引擎、MLlib机器学习库、GraphX图形计算框架,以及Spark Streaming类似于Storm的流处理框架,实现了类似于Hadoop生态圈的另一Spark生态软件栈。
Spark集群中主要配置一个Master节点和多个Worker节点,通过在Master节点和Worker节点分别启动运行。如图1所示,Spark中Driver通过运行编好的Application的main函数来创建Spark的运行环境SparkContext,而SparkContext通过集群资源管理(Cluster Manager)来进行资源申请、调度、监控等。每个Worker Node进程负责创建Spark Executor进程对Spark RDD进行分布式计算[14]。
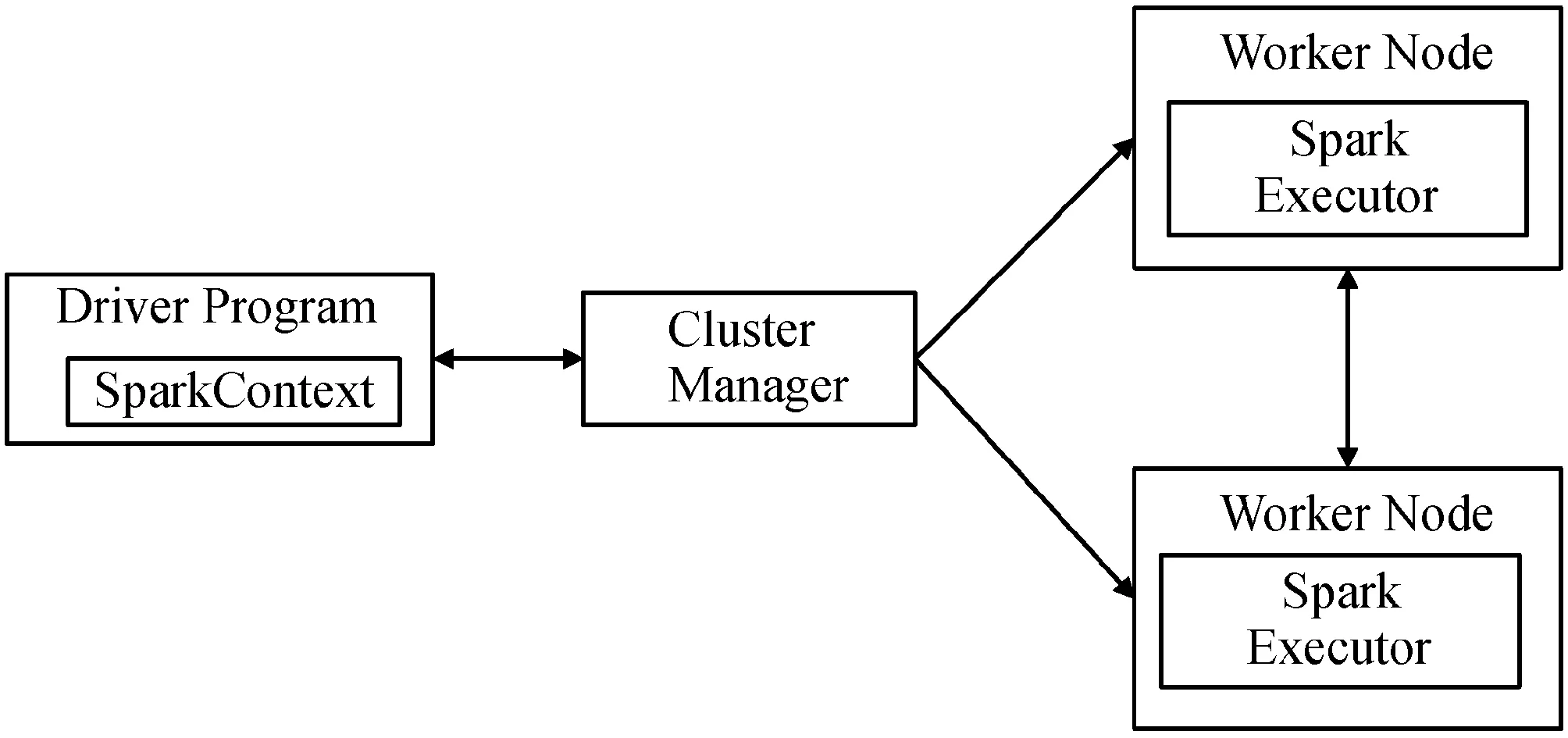
图1 Spark运行框架
1.2 系统架构设计
在考虑系统架构设计时,需考虑后期各个模块的可维护性和可扩展性[14]。本系统包括三个主要的子系统模块,分别是前端展示系统、后端数据管理系统,以及离线数据推荐与实时数据推荐模块,具体的系统架构如图2所示。

图2 系统总体架构设计图
图2中的系统总体架构设计包括展示层、应用层、数据处理层及存储层四个层次,每层的详细信息如下:
(1) 展示层:主要包括前端页面展示系统与后端数据管理系统,前端页面展示系统采用SSM框架、BootStrap、HTML、Jquery、JSP等技术进行展示界面设计,展示界面分为门户界面与详细信息界面,分别为用户提供热门Item与TOP-N的Item的具体展示。后端数据管理系统主要采用SSM后端框架、Easy-UI前端框架、JSP等技术进行后端界面设计,后端系统主要对系统用户数据、推荐结果数据、Item信息数据等进行维护,以保证前端页面的数据真实性与可靠性。
(2) 应用层:系统核心算法原型为Spark的机器学习库中的协同过滤算法模型,该算法模型采用Scala语言编写,本文采用优化后的基于MLlib的系统过滤推荐算法模型。
(3) 数据处理层:该层主要包括离线数据处理及实时数据处理模块。其中,离线处理模块在实验阶段主要将MovieLens的离线数据导入HDFS中,由Spark Streaming读取HDFS中的离线数据再经过MLlib中优化后的协同过滤算法模型迭代计算生成最终推荐结果存入Hive数据仓库中,再由Spark SQL对Hive中的数据进行TOP-N排序[16],产生TOP-N推荐结果存入MySQL数据库中供展示层调用。而实时数据处理模块主要是对前端页面进行埋点,本系统的埋点范围主要包括页面跳转信息、用户在页面停留时间信息、点击信息、评分信息等构成用户隐式动作信息日志并存于Tomcat服务器中,由Flume数据采集软件采集到服务器中的日志文件上传到Kafka消息队列中,接下来由Spark Streaming对Kafka消息队列中的数据进行数据流处理。同样通过算法模型将最终结果存入MySQL数据库中,应用层定时读取实时结果数据展示在个性化推荐栏中。
(4) 存储层:该层主要包括的持久层软件有HDFS、MySQL与Hive数据仓库工具,为展示层、应用层、数据处理层提供数据支撑。
1.3 系统功能设计
一个完整的推荐系统包括前端页面展示系统、后端数据管理系统、实时数据流处理模块、离线数据处理模块、推荐算法模块等。本系统应用以上各类子系统、模块,并基于Spark大数据处理平台以及平台机器学习库的协同过滤算法模型对数据量进行处理,得出推荐结果。
前端子系统与后端数据管理子系统和推荐模块之间都是相互独立、解耦合并易扩展。每个子系统都拥有独立的前后端开发框架与独立的持久层软件,系统之间通过数据接口进行连接。
前端展示系统与后端数据管理系统的系统功能模块图如图3和图4所示。
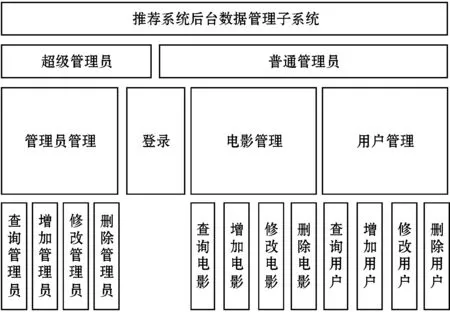
图4 后端数据管理子系统功能模块图
1.3.1前端展示子系统
前端展示子系统包括用户注册以及个人资料编辑,对电影的查看、评价、收藏、搜索,对推荐出的TOP-N电影展示等功能模块。其中推荐注册模块除了填写用户个人信息之外,需要用户选取感兴趣的几个电影主题,系统结合用户的人口统计学信息及兴趣信息解决协同过滤算法的冷启动问题,可以为新用户提供基于兴趣的几个热门电影。同时,在用户浏览电影信息、对电影评分、收藏电影时,通过网页埋点的方式获取他们的隐式评分数据及隐式动作数据,可以实时分析用户的兴趣主题电影。
1.3.2后端数据管理子系统
后端数据管理子系统主要用于对各类计算后的推荐数据及电影信息数据、用户信息数据进行操作。系统共包含普通管理员与超级管理员两类用户,超级管理员对普通管理员的信息进行管理维护。普通管理员主要对电影信息及用户信息进行管理维护,其中电影管理模块的数据主要来源为离线电影信息数据,即经过推荐算法模型计算后的TOP-N电影信息,前端通过各项电影的推荐权重进行推荐,权重越高,电影排名越靠前,同时管理员可以人工操作近期上映的热门电影并将推荐权重升高,进而在页面上显示TOP-N电影。
2 推荐系统
2.1 推荐系统概述
现如今的推荐系统主要应用于电商、新闻、旅游方面,为用户提供个性化的物品、新闻、旅游信息,通过推荐系统,在用户可以得到自己想要的信息同时,也为企业带来了潜在的客户与利益。
一般推荐系统的推荐方式包括TOP-N推荐与评分预测等。TOP-N推荐是基于用户的兴趣与隐式行为信息为用户推荐N个他可能感兴趣的物品信息,而评分预测是猜测U对某个物品I可能的打分。
2.2 协同过滤算法
协同过滤(Collaborative Filtering,CF)[17]主要有基于User的协同过滤算法、基于Item的协同过滤算法、基于Model的协同过滤算法。基于User的协同过滤算法主要计算用户的相似度,当用户U1和用户U2对物品A都有较高的评分时,则认为用户U1与U2具有较高的相似度,所以当U1对物品B评分较高时,便会将物品B推荐给用户U2。基于物品的协同过滤算法主要计算物品的相似度,该算法认为两个物品具有相似度是因为两个物品同时属于许多个用户样本兴趣列表中,当多个用户对物品A感兴趣的同时对物品B也具有同样的兴趣度,则认为物品A、B具有很高的相似度。
2.3 隐式行为数据处理
在前端页面中通过网页埋点的方式对用户操作隐式行为进行记录,通过这些隐式行为信息可以发现用户对电影的偏好规律进而基于此进行推荐。本文获取的隐式行为数据包括用户的收藏信息、页面跳转信息、页面停留时间、电影评分信息等。
在对以上数据处理后形成一个三元组(userId,itemId,preferDegree),userId:用户ID,itemId:物品ID(在这里为电影ID),preferDegree:偏好度。其中偏好度通过用户的点击次数、页面跳转次数、页面停留时长、电影评分等进行加权平均。权重系数如表1所示。
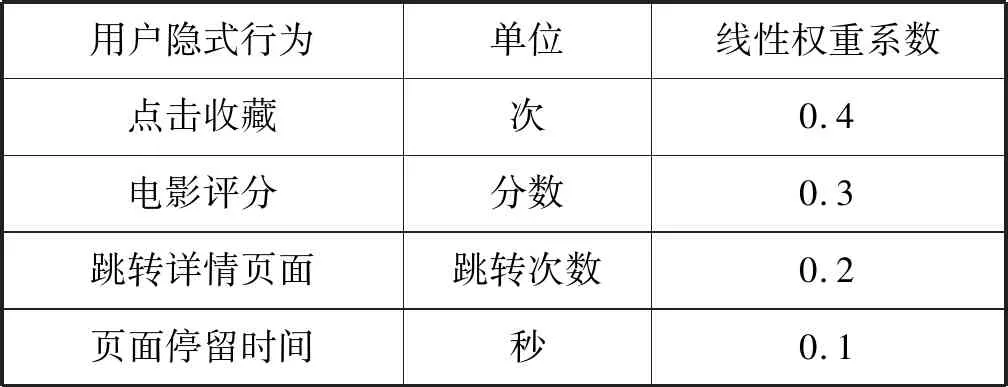
表1 隐式行为权重系数
根据表1的隐式行为信息与权重信息可以得到如下的偏好度结果公式:
Pij=μ1pij+μ2pij+μ3pij+μ4pij
(1)
式中:Pij表示用户i对电影j的四种隐式行为及权重系数的乘积之和,即最终的偏好度;μn表示用户行为信息的权重系数;pij表示用户i对电影j操作行为,使用操作单位数乘以权重系数,若无操作,则为0。最终将Pij作为三元组的preferDegree结果,作为最终偏好度。
2.4 基于物品的协同过滤算法流程及改进
基于物品的协同过滤算法(Item CF)主要为用户推荐与他们之前喜欢物品相似的物品。算法模型与物品属性无关,而与喜欢物品的用户行为有关。例如“啤酒纸尿裤”案例,发现美国男人在买纸尿裤的同时也会买一罐啤酒,超市于是将啤酒和纸尿裤放在一起增加销售量。Item CF即认为喜欢物品A的用户同时也喜欢具有相似性的物品B。同时,在用户对Item的评分过程中会对A、B这两个“看似相似”物品的打分产生一定的偏差,有可能出现同时喜欢A、B物品(这里认定评分大于4为喜欢该电影)的用户数很多但用户U对A打高分却对B打低分的情况。所以需要对Item CF的算法流程做如下改进:
(1) 对数据集进行遍历,对喜欢每个电影的用户数进行分类统计,存入新的文件movie_popular中,则movie_popular[j]表示喜欢电影j的用户数。
(2) 使用movie_popular列表构建电影喜好相似度矩阵,该矩阵将同时喜欢物品jn和物品jm的用户总数填入相似度矩阵中,计算其物品相似度,如图5所示。
对于以上矩阵,可以根据喜欢电影的用户数量得出相似度公式:
(2)
式中:Simjnjm表示电影jn与jm的相似度;N(jn)表示喜欢电影jn的用户数;N(jm)表示喜欢电影jm的用户数;分子表示同时喜欢电影jn和电影jm的用户数。式(2)表示喜欢电影jn的用户中喜欢jm的用户比率。
但是对于式(2),当电影jn属于热门电影时,N(jn)与N(jm)的交集会有很大概率增大,使Simjnjm的值趋近于1,所以为了消除热门因素带来的影响,为上述公式分母加上电影jn的惩罚权重,如下:
(3)
由式(3)与movie_popular列表可以构建出用户相似度矩阵。
(3) 在(2)中的电影相似度公式构建中,仅仅针对用户高评分数据子集进行电影相似度计算,而每个人对电影的打分习惯不同,有人对电影评分3分对他来说就是“高分”,所以要针对数据集中的大量稀疏的评分数据,使用修正的余弦相似度公式计算相似电影:
(4)

(4) 当通过喜欢电影的共同用户数计算相似度后可能出现某个用户对相似度很高的A、B电影评分差距出现个体喜好性差异,所以本文采取集成基于共同喜欢的用户数计算物品相似度和基于所有物品评分计算的余弦相似度两种方式,并采用一个平衡因子ω来平衡两种方法的权重,生成电影p和电影q的相似性,如下:
(5)
式中:平衡因子ω∈(0,1),ω的取值在实验中具体说明。Sim(p,q)能够从整体上衡量物品之间的相似度。
2.5 模块实现
推荐系统包括离线计算模块和实时计算模块,本文将对以上两个模块部分作主要说明。两个模块的数据走向如图6所示。

图6 推荐系统数据走向图
2.5.1离线计算模块
本文的离线计算模块使用MovieLens中的评分数据集作为离线处理数据。随着系统运行,系统中的电影信息数量与用户数量不断增加,考虑采用基于Hadoop集群的分布式文件系统(HDFS)来存储离线数据,保证系统的性能与可扩展性,可以避免单机情况下的系统性能下降与服务器宕机后数据的丢失。
考虑到基于物品的协同过滤算法运算过程中需要大量的迭代计算,选用基于内存计算的Spark平台来对推荐算法模型进行迭代计算。其运行速度是传统计算框架Hadoop的十倍以上,并且带有Spark Streaming、Spark SQL、MLlib等一栈式开发组件,可以更简便地对离线系统模块进行搭建。
将离线数据存储于HDFS中后,需要对数据进行ETL进而在Hive数据仓库中建表,本文使用Spark SQL与Hive进行集成对离线数据清洗,将清洗的结果分表存放于Hive中供后续算法模型使用。
根据上文创建好的改进的基于物品的协同过滤算法模型,通过RMSE(均方根误差)以及MAE(平均绝对误差)[18]两种评测方式选取最好的推荐算法模型,将计算结果存入MySQL数据库中,供前后端系统调用。
2.5.2实时流计算模块
离线处理的数据大多是历史旧数据,一个好的推荐系统需要具有实时性,在对离线数据进行计算的同时也需要获取系统中用户的实时日志数据,进而对其进行计算产生推荐结果。实时流计算模块需要解决的问题是假设最近在上映某一电影的第四部,则有些用户突然想观看这一系列的其他电影来了解整个系列电影的故事线,离线数据计算模块就无法做到实时地为用户推荐最近想看的电影,而实时流计算模块可以根据用户近期的点击行为日志数据计算一些电影的相似度,将最相似的电影推荐给用户,达到实时推荐的效果。
在2.3节的隐式行为数据处理中,系统通过Flume采集实时生成的隐式行为日志文件,结合Kafka消息队列,最终使用Spark Streaming作为Kafka的消费者对日志数据进行消费,经过数据处理获得用户、电影、偏好度三元组,使用这个三元组数据进行实时推荐阶段的算法模型构建。
3 实验与分析
3.1 评价标准
一个推荐系统的好坏要看其准确度、覆盖率和新颖度[14]的高低,推荐系统的准确度衡量一般通过评分预测或TOP-N进行评判。本文使用评分预测方式对推荐系统准确度予以评判。评分预测的预测准确度方式包括RMSE和MAE,这两种计算方式通过计算算法中预测的评分与用户对项目的实际评分之间的偏差值来衡量预测的准确度。
本文实验使用均方根误差RMSE作为评价标准,其公式为:
(6)
式中:N代表项目的个数(即电影的数量);pi表示数据集中实际评分;ri表示算法模型的预测评分。(pi-ri)的值越小,整体RMSE的值越小,表明预测分数与实际分数的偏差越小,即推荐系统的精度越高。
3.2 数据集与实验环境
3.2.1数据集
本文使用数据集来自GroupLens的ML-20M数据集,该数据集中包括138 491位用户对30 106个不同种类电影的评分数据约2 000万条,在算法精度实验中使用它的精简数据集ML-100K、ML-1M与ML-10M进行对比实验,分别包括10万条评分数据、100万条评分数据与1 000万条评分数据。
3.2.2环境配置
本文系统集群环境使用的是实验中的三台普通PC机,由一个Master节点和两个Worker节点组成,分别命名为Spark01、Spark02和Spark03,三台机器使用的系统环境是Linux Centos 7.0,机器之间使用局域网进行网络连接,节点上同时搭建了Spark集群、Hadoop环境下的HDFS分布式文件系统、Kafka消息队列组件与Zookeeper分布式应用协调组件,同时在Spark03上安装MySQL数据库与Hive数据仓库工具,在Spark01上部署了Flume日志采集组件等。具体情况如表2所示。
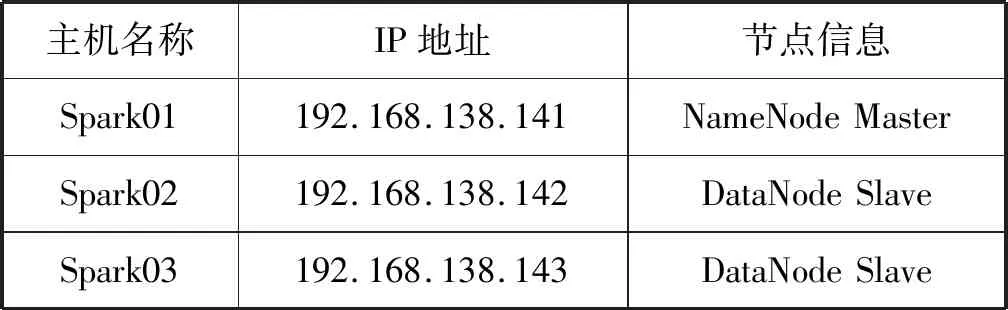
表2 Spark分布式集群配置表
3.3 结果分析
本文为验证改进算法的基本表现以及Spark平台的优势,进行以下几种对比实验:
实验一测试改进算法的准确性。在实验过程中使用评分稀疏度分别为5.88%的ML-100K数据集,其中包括6 040个用户对3 900部电影的1 000 204条评分数据,本次实验从数据集中选取1 000、2 000、4 000、6 000个用户,及其评分数据作为实验数据进行RMSE对比实验,ω的取值范围为0<ω<1,在实验中ω的值每次增加0.2,观察RMSE的值随ω与评分数据量的变化,如图7所示。
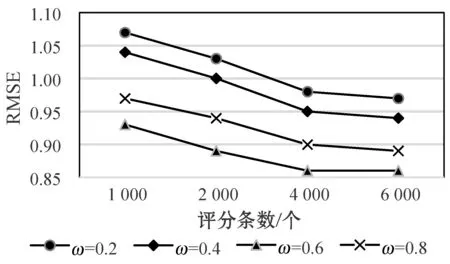
图7 ω对RMSE的影响
结果表明:算法的精度随着ω的变化而受到影响,ω值过大或者过小都会使最终效果不理想。在本实验中,ω取值为0.6时,所得的RMSE结果最小,随着测试数据样本逐渐增大,RMSE减小缓慢,算法精度趋于稳定。
实验二使用相同的数据集ML-100K在Hadoop集群与Spark集群中测试算法的运行速度,测试结果如图8所示。

图8 Hadoop平台与Spark平台运行效率对比
结果表明,Spark平台的计算速度远大于Hadoop平台的计算速度,运行速度提升36%左右,且随着节点的增加,运行速度呈线性下降趋势,表明使用Spark平台构建推荐系统的优越性。
实验三为验证本文改进算法的有效性,将本文使用算法与传统的基于改进后的余弦相似性的协同过滤及基于用户喜爱物品的物品协同过滤进行对比实验。本次实验使用相同数据集、Spark平台下相同节点进行RMSE值对比实验,所得实验结果如表3所示。

表3 对比实验结果
结果表明:本文提出的改进后的算法模型较基于改进后的余弦相似性的协同过滤和基于用户喜爱物品的物品协同过滤有较低的RMSE值,即算法精确度有所提升。在评分数据矩阵较为稀疏的数据集中,使用评分值大于4数据计算相似度,缩小推荐范围,一定程度上缓解数据的稀疏性,再结合余弦相似度计算去除无评分物品的物品相似度,整体算法相对于单个算法提升了推荐效果。
4 结 语
本文实现Spark平台下电影推荐系统的实时与离线系统的搭建与基于协同过滤的算法改进。使用基于Spark框架的推荐系统的运行速度相比传统的Hadoop集群模式的推荐系统提升36%左右,为不断增加数据量的推荐系统的运行效率提供保证。另外,在传统的基于物品的协同过滤推荐算法的基础上改为基于物品的协同过滤与电影相似度计算相融合的方式,提升用户个性推荐的准确率。
本系统以不同用户对物品的评分习惯作为出发点,尽可能降低个人习惯对推荐结果带来的影响,结果表明推荐结果有明显的提升效果。
下一步将针对有可能出现的“情怀”打分,即评价不高却评分较高的情况,尝试使用基于深度学习的自然语言处理技术对评价语义进行研究,以提高算法的准确度,优化系统计算模型,达到更好的效果。
猜你喜欢
电脑知识与技术(2022年15期)2022-07-02
北京航空航天大学学报(2022年6期)2022-07-02
小学生学习指导(低年级)(2022年5期)2022-05-31
新班主任(2022年4期)2022-04-27
防爆电机(2021年4期)2021-07-28
疯狂英语·初中天地(2021年11期)2021-02-16
电脑爱好者(2020年23期)2020-12-30
少年漫画(艺术创想)(2019年2期)2019-06-06
汽车观察(2019年2期)2019-03-15
民生周刊(2017年19期)2017-10-25
