
基于混沌遗传算法优化的LS- SVM 边坡位移预测
2020-11-12 09:32杨念江樊方涛
湖南水利水电 2020年5期
杨念江,樊方涛
(湖南省水利水电勘测设计研究总院,湖南 长沙 410007)
引 言
边坡稳定性预测是工程研究领域的热点问题,边坡稳定性受自身物质组成、沉积形成过程和外界环境多种因素的影响,一般很难通过确定性的数学模型来表达[1]。位移作为边坡岩土体在变形破坏演化过程中反馈出的重要信息,通过实际监测的边坡位移序列来预测边坡未来变形,便可以判断边坡的稳定性。目前用于边坡位移预测的方法很多,主要有时间序列模型[2~3]、灰色模型[4~5]、神经网络模型[6~7]等方法。但这些方法都存在着理论或应用上的不足,如时间序列分析法的应用前提是假设监测数据为非平稳时间序列,灰色理论则需要假设时间序列中与历史时序吻合的模式,即假定在数据系列中该模式可以在时间上再现,然而这种假设往往与时间不符;而人工神经网络也存在着一定的缺陷,在学习样本数量有限时,精度难以保证,当学习样本的维数很高时,其高维空间中往往存在众多差异较大的局部极值,会使学习结果呈现出较大的随机性[8]。
近年来,支持向量机[9](support vector machine,SVM)被广大学者应用于边坡的稳定性评价中[10~12]。支持向量机是以结构风险最小化原理为基础的算法,具有良好的数学性能,如解的唯一性、不依赖输入空间的维数等。而最小二乘支持向量机[13](LS-SVM)是支持向量机的一个变种,解决了大样本训练过程中计算速度变慢的问题。和其他学习算法一样,其性能依赖于学习机的参数,然而到目前为止,还没有指导LS-SVM 参数选择的系统方法。
本文采用混沌遗传算法参数优化应用于LS-SVM预测模型,将混沌运动的遍历性和遗传算法的高效并行计算能力相结合,并随着寻优次数的增长动态缩减寻优区间,在一定程度上克服了传统寻优方法存在早熟收敛、非全局收敛以及收敛速度慢的弱点。并将之应用于实际工程的分析与预测,以验证这种变尺度混沌遗传算法参数优化的LS-SVM 模型在边坡变形预测领域应用的效果。
1 最小二乘支持向量机
最小二乘支持向量机(LS-SVM)是Suykens 等提出的一种改进的SVM 算法。LS-SVM 将标准SVM 中的不等式约束改为等式约束,以误差平方和作为训练样本的损失函数,从而将2 次规划问题转化为求解线性方程组问题。
训练集可以表示为:(xi,yi)li=1,其中yi是目标值,xi是输入向量,l 为样本个数,对于线性回归问题采用线性函数f(x)=ω·x+b 来拟合,函数估计问题可以描述为求解以下问题:

约束条件:
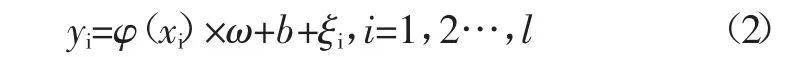
其中φ(xi):Rn→Rnh是核空间映射函数,权矢量ω∈Rnh,误差变量ξi∈R,b 是偏差量,γ 是惩罚参数。核函数可以将原始空间中的样本映射为高维特征空间中的一个向量,以解决线性不可分的问题,用拉格朗日法求解这个优化问题:

其中φ(·):Rn→Rnh,αi,i=1,2…l,是拉格朗日乘子。根据优化条件:


可得:

其中x=[x1,…xl],y=[y1,…yl],α=[α1,…αl],核函数K(xk,x1)=Φ(xk)TΦ(xl),是满足Mercer 条件的对称函数。
最小二乘支持向量机回归估计为:
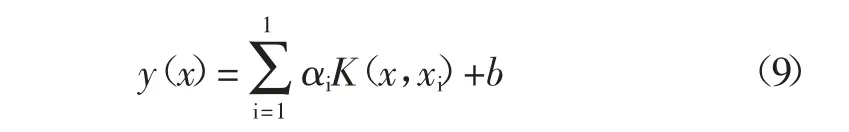
通常情况下,最小二乘支持向量机的核函数选用高斯核函数。定义为:

其中惩罚参数γ 和高斯核参数σ 直接影响到LSSVM 模型的预测效果。
为了提高LS-SVM 模型的预测准确率,本文采用变尺度混沌遗传算法对LS-SVM 中的参数σ 和惩罚参数γ 进行优化。
2 变尺度混沌遗传算法的参数优化
目前,关于LSSVM 的参数优化的方法,主要有混沌优化[14]、遗传算法[15]和粒子群算法[16]等。但这些方法都存在一定的不足。例如,混沌优化算法因为其遍历性,其寻优速度相对较慢,遗传算法和粒子群算法存在早熟及局部收敛的问题。为了弥补其不足,本文将混沌优化和遗传算法结合起来。混沌运动的遍历性避免了遗传算法的早熟及局部收敛的不足,遗传算法的并行处理方法弥补了混沌遍历所需时间。该改进算法具有收敛速度快,不易陷入局部最值点的特点。本文采用常用的一维logistic 映射[17]为:

其中,0≤x1≤1;k 是迭代次数,k=1,2,…;μ 是控制参量,当μ=4 时系统完全处于混沌状态,此时xk在[0,1]的范围内变化。
其主要步骤如下:
1)初始化LS-SVM 参数并对其进行二进制编码,产生遗传算法的初始群体,选择样本均方根误差(RMSE)作为适应度函数值。LS-SVM 模型需要优化的参数为σ 与γ,其优化区间分别为[a1,b1]、[a2,b2],码串中包括两个参数的二进制码。
2)将长为m 的位串按照参数σ 与γ 分成两段,分别映射到[0,1]的区间,如
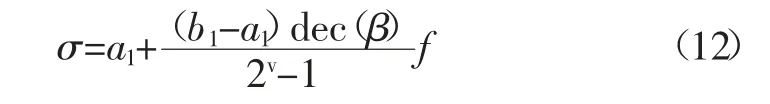
其中,dec(β)是二进制位串β 的十进制数值;v 是位串β 的长度。
3)利用式(11)迭代得到两个[0,1]区间的新值,分别将其逆映射为长度是p、q 的位串,组合成长度为m的新二进制位串,产生一组新的种群。并利用训练集运行LS-SVM 算法,计算适应值f1(σ,γ)。
4)按照遗传算法对参数映射种群进行选择操作。
5)按照遗传算法对参数映射种群以概率pc进行交叉操作。
6)按照遗传算法对参数映射种群以概率pm进行变异操作。
7)利用变异后的个体计算新的适应值f2(σ,γ),如果f2(σ,γ)<f1(σ,γ),则根据遗传算法对参数映射种群进行复制运算接受新个体,并标记性能最好的个体。
8)重复步骤(2~6)的操作,如果种群最优值在一定步数内保持不变,则将最优个体记做pi*(i=1,2)。
9)进行变尺度操作,缩小变量搜索范围,如

其中,λ∈(0,0.5),r 是缩小搜索方位的操作次数。为使变量落入正确取值区间内,做出以下界定:若air+1<air,则令air+1取值air;若bir+1>bir,则bir+1取值bir。
10)按照缩小了的搜索范围内产生新种群,执行步骤(2~8)。若最优值在若干次内保持不变,则结束寻优操作。得到的pi*(i=1,2)对应于参数σ 与γ 优化值。
解空间的搜索空间越大,优化方法的搜索精度越低,且失效的可能性越大,且在相同区间内盲目的重复搜索,会降低优化效率。该优化算法首先在较大范围内进行粗搜索,确定参数的次优值,然后利用变尺度混沌优化方法缩小搜索范围,在其缩小的范围内进行细搜索以确定参数的最优值,加快了搜索速度和精度。
本文采用Matlab 语言编制了基于混沌遗传算法参数优化的最小二乘支持向量机边坡位移预测程序,为本文研究作为基础。
3 工程应用
将该模型应用于某水利水电工程左岸岩质边坡EL1885~EL1960 的位移观测点中,以2007 年10 月18日到2008 年07 月03 日时间段实测监测数据作为模型的训练数据和检验数据,共40 个监测数据,如表1所示,前30 个数据用于对边坡变形监测时序进行回归建模,后10 个数据用于预测验证。

表1 用于构建训练数据集的实测位移
本文首先对数据进行归一化处理,以将数据控制在(0,1)的范围。这样可以有效减小预测误差,所用归一化公式如下:

选择均方根误差(RMSE)作为适应度函数值:

利用建立起来的LS-SVM 模型对后10 个时间段的位移数据进行预测,并与使用标准遗传算法对LSSVM 参数优化预测模型做个比较,详细结果如表2 所示,可以看出基于CAG 优化的LS-SVM 模型的预测值均方根误差为0.21,最大相对误差为0.057,明显小于基于SGA 优化的模型预测的0.32 和0.076。从表2 可以更加直观的看到基于CAG 优化的LS-SVM 模型具备更好的预测性能,且预测效果令人满意。

图1 LS-SVM 模型的两种参数优化算法的收敛性比较

表2 两组参数优化LS-SVM 模型的预测结果
4 结 论
1)针对工程边坡位移变化的复杂性,采用最小二乘支持向量机(LS-SVM)建立边坡位移预测模型,对边坡位移进行短期预测,考虑到参数选择对模型预测的重要影响,提出了基于变尺度混沌遗传算法的联合优化的模型方法(CGA-LSSVM)。
2)采用混沌遗传算法(CGA)对LS-SVM 的参数进行优化,其参数寻优速度比普通遗传算法(SGA)有了明显的提高,同时在一定程度上克服了遗传算法易陷于局部最优的缺陷,加强了对最优解的局部搜索能力,因此搜索效率及其预测精度都有了进一步的提高。
3)将其模型应用到某水利水电工程左岸岩质边坡体边坡位移时间序列的预测中,显示了良好的预测效果,表明本文提出的CGA-LSSVM 模型在边坡非线性时间序列预测中有较好的普适性和实用价值。
猜你喜欢
今日农业(2022年15期)2022-09-20
建材发展导向(2022年4期)2022-03-16
有色金属(矿山部分)(2021年4期)2021-08-30
科学与财富(2021年36期)2021-05-10
湖南电力(2021年1期)2021-04-13
汽车工程(2021年12期)2021-03-08
水电站设计(2020年4期)2020-07-16
电子制作(2019年24期)2019-02-23
中学生物学(2018年8期)2018-03-01
中央民族大学学报(自然科学版)(2017年1期)2017-06-11
