
一种面向Kubernetes集群的网络流量弹性管理方法
2020-11-17 12:05靳芳,龙娟
北京交通大学学报 2020年5期
靳 芳,龙 娟
(1.数字广西集团有限公司,南宁 570000;2.广西财经学院,南宁 541004)
近年来,随着云计算应用和用户规模的快速增长,以及各类新型服务模式与技术的不断涌现,云平台从服务模式、资源组织、管理方式等方面都发生了巨大的变化,这些变化给云平台的服务质量(Quality of Service,QoS)管理带来很多新的问题和挑战[1-2].云平台的网络服务质量管理需保障网络传输带宽、传输时延、数据丢包率以及时延抖动等符合服务质量规范[3].由于接入的传输带宽不断提升,同时大量用户以及应用的迁入,使得传统粗粒度的拥塞控制和网络流量调度方案难以提供满足各类场景需求的网络传输性能.此外,由于资源使用的独占性特点,当某一资源(如CPU、网络、内存等)分配给某一实例后,同样的资源无法再分配给其他实例使用,因而当实例的资源利用率相对较低时容易造成资源分配不合理及资源浪费.如何从优先级与公平性等角度出发,针对不同服务质量管理需求,面向容器集群平台提供对各类型资源(如CPU、内存、网络带宽、存储等)的细粒度服务质量管理功能,是实现资源高效分配和调度,提升资源利用率的关键.
得益于其轻量级和标准化实现,Docker[4-5]已成为容器级云平台的事实标准,以Docker容器技术为基础,出现了大量支持大规模应用服务运行的容器集群实践方案.在网络资源方面,Docker使用Linux 网络命名空间作为其虚拟化网络实现的基础.网络命名空间提供了关于网络资源(如网络设备、IPv4和IPv6协议栈、IP路由表、防火墙等)的隔离功能.Docker的网络虚拟化实现主要有Linux网桥和Macvlan两种方式.此外,为实现对容器的网络流量管理,需借助Linux操作系统内核iproute2包中的流量控制(Traffic Control,TC)模块[6],它利用队列规则(qdisck)建立处理数据包的队列,并定义队列终端数据包发送方式,实现对网络输入(Ingress)流量和网络输出(Egress)流量两部分的控制.Kubernetes是目前主流的容器集群管理系统,实现在平台层面将资源分配给相关部署单元(Pod)使用[7-8].Kubernetes官方提供的网络资源服务质量管理只支持对目标Pod配置出向及入向的访问控制规则,不支持对网络带宽资源进行管理.CNI(容器网络接口)提供了一种容器网络操作规范,在容器创建时分配网络资源,并在删除容器时删除分配的资源.基于CNI,思科实现并开源了一种可用于Kubernetes容器集群网络解决方案Contiv[9],它底层使用OpenvSwitch实现流量控制,通过对OpenvSwitch中的Ingress向流量设置流量rate和burst,当超过设置的速率限制时,对数据包进行简单的丢弃处理.在Contiv的当前实现中,其只支持Ingress单向流量控制,对于Egress向的流量管理无法提供支持.为实现针对Docker容器网络的流量控制,文献[10]提出了一种基于TC的Docker容器网络带宽控制机制,通过虚拟文件系统将网络流量控制参数在Docker容器创建时传递给Linux内核的TC模块,实现上下行带宽控制.该方法的局限在于只为docker0建了一个ifb设备,难以实现对每个容器细粒度的流量控制, 不适用于集群场景,另外流量控制规则只发生在容器创建时,难以根据应用需求动态在线调整流量控制规则.此外,该方法只支持Docker默认的网桥(bridge)模式,对于Docker容器网络的Veth pair和Macvlan实现支持不足.
云计算平台中各节点的网络流量由于用户访问习惯的不同而随时间变化,建立准确高效的网络流量预测模型对异常流量的检测、网络资源的动态调度等都具有重要的意义.一般而言,网络流量预测模型一般包括线性模型和非线性模型两种.其中线性模型主要包括基于短相关特性的自回归滑动平均模型[11]、自回归综合滑动平均模型[12]以及基于长相关特性的差分自回归滑动平均模型等[13].非线性预测模型主要包括支持向量机、小波预测模型[14]、神经网络[15]、可加回归模型(Prophet)等.例如,文献[16]提出了一种基于深度信任网络和高斯模型的融合模型.首先,使用小波变换将原始网络流量数据分解为一组近似数据和多组细节数据,然后使用DBNG去处理近似数据,同时对看似噪音的细节数据使用高斯模型去拟合.实验结果证明,在文中数据集上DBNG的预测结果优于当时已有的模型.文献[17]开源了一套时序预测工具Prophet.与传统的时序预测模型不同,Prophet本质是对时间序列数据的曲线拟合,对数据中的节日效应和趋势变化点具有优秀的拟合能力,对缺失值、趋势转变和异常值具有较好的鲁棒性,在时间序列数据的预测中也有较好的应用[18-19].
本文作者针对Kubernetes容器云平台的网络质量管理需求,提出了一种面向Kubernetes集群网络的流量弹性管理方法,通过实时采集各节点流量监控数据,建立网络流量预测模型,依据预测结果和扩缩容配置,对节点网络带宽进行实时的扩缩容操作,实现对集群中实例的细粒度流量管理.
1 Kubernetes集群网络流量控制方法
1.1 系统架构
网络流量弹性管理需要实时采集各个节点的网络流量数据,并基于采集的数据建立节点网络流量预测模型,在预测结果的基础上根据预先设定的节点网络流量管理规则对节点网络带宽进行动态调节.如何实时获取各节点网络流量信息,预测其网络流量变化,并基于预测结果对各节点的网络带宽进行动态扩缩容,是实现最大限度避免网络拥塞,优化网络资源利用效率的关键.
本文提出的Kubernetes网络流量弹性管理方法主要由监控数据采集模块、扩缩容管理模块以及流量控制模块3部分组成如图1所示.
1.2 监控数据获取
为实现对Kubernetes集群中节点的动态监控,采用Prometheus[20]作为节点监控数据获取的工具.Prometheus是一个开源的服务监控系统和时间序列数据库,具有灵活的类 SQL查询语法,支持多维数据模型.Node Exporter是Prometheus 提供的一种工具,主要用于采集主机关键度量指标.在Kubernetes集群中,每一台宿主机上安装Node Exporter,用于监控宿主机的具体工作状态.Prometheus服务的工作机制为主动从Exporter中获取监控指标.监控管理服务的功能架构见图2.
工作流程如下:
1)启动多个Prometheus实例,并进行选举,得到多个实例的Master角色节点.Prometheus实例间的选举功能通过Kubernetes集群中的Endpoint资源来保证选举结果的唯一性.
2)Master角色的Prometheus服务节点主动收集监控指标,Slave角色的实例只提供数据读取接口.
3)PrometheusMaster节点将采集到的监控数据存储到ElasticSearch集群中,用以实现监控数据的持久化.
1.3 流量预测及动态扩缩容
扩缩容管理模块根据收集的网络流量数据,计算实际网络带宽使用率,同时建立节点网络流量预测模型,并根据预测结果对节点的网络带宽进行动态扩缩容.图3展示了扩缩容管理模块具体工作流程,根据实际情况进行自动带宽扩缩容操作,包括以下两种情况:
1)动态扩容操作,当该实例的网络带宽监控数据值接近配置的网络带宽限制值时,根据预测模型计算未来的带宽使用量,并根据未来带宽使用量减去当前带宽使用量获得需要扩容的网络带宽值,并动态调整实例的网络带宽值.
2)动态缩容操作,当实例网络带宽执行过扩容操作后,根据预测模型对实时的监控数据进行预测值计算,当预测值小于配置的阈值时,对实例的网络带宽限制进行缩容操作,缩容后的最小值为用户配置的网络带宽限制值.
1.3.1 流量预测模型
大多数网络应用的网络流量由于其用户的访问习惯而呈现明显的趋势性、周期性与事件驱动性,如购物类型的网站在周末的访问量大于工作日,而线上购物节之类的活动会使得网站的流量呈现明显的事件驱动爆发式增长.为更准确的刻画云平台中不同应用网络流量的趋势性、周期性及突发性这些特性,本文选取可加回归模型Prophet作为流量预测模型.Prophet是一个基于自加性的预测时间序列数据的模型,模型整体由趋势项、周期项、节日项三部分叠加而成,基本形式如下
y(t)=g(t)+s(t)+h(t)+εt
(1)
式中:g(t)是趋势项;s(t)是周期项;h(t)是节假日项;εt是服从正态分布的误差项,表示模型未预测到的波动.趋势模型是Prophet的核心组成部分,主要用于拟合时间序列中的非周期性变化.趋势模型g(t)包括饱和增长模型(Saturating growth model)和分段线性模型(Piecewise linear model)两种.两种模型都包含了不同程度的假设和光滑度调节参数,并通过选择变化点(Change points)来预测趋势变化.其中饱和增长模型为
(2)
式中:C表示模型容量;k表示增长率;b代表偏移量.随着t增加,g(t)趋近于C.
(3)
式中:s(t)是周期模型,用于表示时间序列数据中的周期性变化特征,通过傅里叶级数(Fourier series)近似表达周期分量;T表示某个固定的周期;n表示期望在模型中使用周期的个数;an、bn为不同余弦或正弦周期上的傅里叶系数.
h(t)=Z(t)κ,
κ~Normal(0,ν2),
Z(t)=[1(t∈D1),…,1(t∈DL)]
(4)
式中:h(t)是节日模型,用于表示时间序列数据中突发事件或节假日的变化特征,通过将每个事件或节假日在不同时刻下的影响视作独立模型来表达其影响;κ表示窗口期中节假日对预测值的影响;Di表示第i个虚拟变量(节假日变量),若时间变量t属于虚拟变量所表示的时间范围,则虚拟变量Di值为1,否则为0.
1.3.2 扩缩容处理
扩缩容模块主要根据期望的网络带宽使用率,对节点进行动态扩缩容操作.首先用户配置网络带宽限制值与期望的带宽使用率,然后从监控服务中获取对应实例的当前网络流量数据,计算实例当前的网络带宽使用率.基于预测模型给出的网络带宽预测值,当预测值大于用户指定期望的网络带宽使用率时,进行网络带宽动态扩容操作,否则,进行网络带宽缩容操作.节点在某一时刻t的网络带宽限制值Lt是根据预测的使用率与期望使用率来计算网络带宽的缩放值,计算公式为
(5)
(6)
式中:n为网络带宽扩缩容乘数;ut+1为预测的实例网络带宽使用率;u′为期望的网络带宽使用率,由用户配置;at+1为预测的网络带宽流量.当实例网络流量使用率大于期望的网络带宽使用率时,会触发扩容操作.当配置的期望值较大时,触发的扩缩容操作次数较少,适用于同一节点上的多个实例共享带宽的场景.当配置的期望值较小时,触发的扩缩容次数较多,适用于实例独享带宽的场景.例如,当前网络带宽扩缩容乘数n为15,假设预测指标为80 MB,带宽限制值为100 MB,期望的网络带宽使用率为50%,因此,需要扩容的值为(0.8-0.5) ×15×0.8/0.5=7.2,即为实例新增7.2 MB带宽值,扩容后的带宽限制值为107.2 MB.需要指出的是,网络带宽的扩缩容是一个逐步累积的过程,扩缩容模块会根据预测值与当前观测值逐步调整网络带宽,以适应最终的网络流量.在实际扩容过程中,需将计算出的网络带宽扩缩容值乘以扩缩容乘数,实现放大/缩小网络带宽扩容值的效果,避免出现当实例网络流量数据波动过大时,导致过于频繁的执行扩容操作的问题.使用固定扩缩容乘数来进行操作时,扩缩容的时间效率更优,但是可能导致网络带宽资源闲置的问题,因此,在不同的场景中,需要选取不同的扩缩容乘数值.
1.4 流量控制
本文实现的Kubernetes集群网络流量控制方法采用Linux内核支持的流量控制模块来实现.基于Linux内核模块可以减少对外部模块的依赖.
要实现具有普遍适应性的Kubernetes集群网络的服务质量管理,需要同时支持基于网桥和Macvlan两种网络虚拟化实现.本文所采取的方案中,针对不同的容器网络实现,分别采用不同的配置实现方式.具体来说,对Veth pair和Macvlan[21]两种容器网络虚拟化实现方式,流量控制的规则配置基本一致,底层都是采用Linux内核的TC模块来进行流量管理操作.区别在于流量管理发生的位置不一样.Veth pair的流量控制规则配置在Veth pair中靠近宿主机一端的接口上,而Macvlan的流量控制规则配置在容器端.本文方法的工作示意见图4.
针对基于Macvlan的容器网络实现,本文将节点上指定的通信网卡拆分成子接口,并将子接口放入到容器的Network Namespace中.针对Macvlan的流量控制规则在容器端执行,宿主机端无需配置相关流量控制规则.对于基于Veth pair的容器网络实现,将流量控制规则配置在宿主机一端.容器的流量控制通过Veth Pair中管理主机侧的接口实现.在Veth pair中,Veth1的Egress流量连接容器的Ingress流量,Veth1的Ingress流量连接容器的Egress流量.
1.4.1 网络流量控制实现分析
以Veth pair为例分析实现原理及流程分析,外部主机与Container通信时,Ingress/Egress流量流向如图5所示.流量经过Veth pair在节点/网桥中的一端后,发往Pod中的另一端.对Pod进行流量控制在Veth Pair中连接到主机这一端的接口上实现(即在图5中的Veth1上配置流量控制规则).
新增ifb设备,通过设置Ingressqdisc将Veth1接口输入方向的数据包重定向到虚拟设备ifb,在ifb的输出方向配置qdisc,即可实现对输入方向的流量做队列调度.具体流程如图6所示.
Pod网络接口Veth2在Ingress/Egress方向限流与TC配置规则对应关系说明:
1)Pod入向流量(Veth2 Ingress):流量控制规则配置在Veth1接口的Egress方向.
2)Pod出向流量(Veth2 Egress):流量发送到Veth1的Ingress方向,并转发到ifb设备,在ifb设备的Egress方向应用TC规则.ifb设备将流量转发回Veth1接口.
1.4.2 流量控制接口
图7展示了Kubernetes网络流量控制模块的总体架构.在Kubernetes从节点上,当Kubelet服务创建Pod时,会调用CNI网络插件为Pod的网络容器配置网络接口、路由条目、流量控制规则等.CNI网络插件初始化Pod网络容器时(Veth Pair网络或Macvlan网络),会根据Pod的网络类型,在不同的Network Namespace中下发不同的网络流量控制配置.对于使用Veth pair类型的Pod网络,CNI插件会在K8s从节点的Network Namespace中创建ifb设备(一个Pod对应一个ifb设备),然后在ifb设备与Veth1接口上应用Pod网络流量控制规则.对于使用Macvlan类型的Pod网络,因为Pod中的eth0.1接口是K8s从节点上物理网卡eth0的子接口,因此,CNI网络插件会切换到Pod的Network Namespace中,并且在Pod中创建ifb设备,然后在Pod中的eth0.1接口与ifb设备上应用网络流量控制规则.
表1实现的流量控制调用接口参数说明,接口可以实现对Pod的Ingess和Egress向流量进行细粒度管理.

表1 流量控制调用接口参数设置
2 实验与结果分析
2.1 流量控制带宽变化
为验证方法在Kubernetes集群网络流量控制上的有效性,在实际的物理环境中对本文方法进行测试.网络拓扑采用图7所示架构,Pod A、Pod B的Ingress和Egress向初始带宽分别为100、 50 MB.为验证流量控制模块对Kubernetes集群网络流量的动态管理功能,在Pod的生命周期中通过调用流量控制API对其带宽进行动态管理,即在两个不同时刻,分别对Pod A和Pod B的Ingress向和Egress向带宽进行管理,并通过网络带宽监测工具查看具体的网络带宽变化.
具体而言,基于表1提供的流量控制接口,在第55 s分别对Pod A和Pod B的Egress向流量进行管理(Pod A的Egress向带宽从100 MB降至256 KB,Pod B的Egress向带宽从50 MB升至100 MB).在第65 s分别对Pod A和Pod B的Ingress向流量进行管理(Pod A的Ingress向带宽从100 MB降至256 KB,Pod B的Ingress向带宽从50 MB升至100 MB).基于此接口调用生成了对应Pod的流量控制规则.对应55 s时,作用于Pod A上的流控规则序列如下:
1)ip link add type ifb ifb0
2)ip link set ifb0 mtu 1 500 up
3)tc qdisc add dev veth1 handle ffff:ingress
4)tc filter add dev veth1 parent ffff:protocol ip u32 match u32 0 0 action mirred egress redirect dev ifb0
5)tc qdisc add dev ifb0 root tbf rate 256 kbit burst 30 000 latency 50 ms
Ingress向的流量控制参数设置与此类似,在此不再赘述.图8展示了Pod A和Pod B在实验过程中的带宽变化情况.可以看出,当对应的时间点上通过API调用对Pod的带宽进行管理后,两个Pod的网络带宽都迅速发生了改变,且与设置的目标值保持一致.
2.2 预测模型比较
为验证不同时间序列预测算法应用于网络流量控制场景的预测性能与计算开销,本文选取了具有代表性的时间序列预测算法进行比较,主要包括线性模型:自回归滑动平均模型(ARMA)、差分整合滑动平均自回归模型(ARIMA),以及非线性模型Prophet(未选取流行的神经网络预测模型主要原因在于其在线推理时需要GPU资源支持,目前尚未有成熟的GPU资源细粒度虚拟化方法,因而在处理大规模并发流控管理请求时,GPU硬件资源容易成为瓶颈).首先,构造一组包含趋势特征、周期特征、突发访问事件特征及随机白噪声的模拟数据,然后依据模拟数据序列利用网络流量压测工具iperf对目标Pod进行网络访问模拟,同时通过Prometheus插件从目标Pod端收集实际发生的网络流量.在Pod端收集到的网络流量数据与模拟数据相比基本形态一致,但由于叠加了真实网络环境的影响,在网络延迟、网络流量突发性等方面更接近真实情况.Prometheus端每5 s采集一次数据,共采集1 200个数据点形成待预测的序列数据集.在产生的数据集上,选取前1 000个数据样本作为训练集,后200个数据样本作为测试集对候选算法进行验证(图9展示了相关数据集,其中黑色点表示训练数据,灰色点表示测试数据).在实际应用过程中,由于预测算法的计算开销,需要在预测精准度和计算延迟之间进行折衷,为此选取了不同的预测步长进行测试,步长N表示每间隔N个数据进行一次预测,且预测未来N个数据值.表2展示了3种算法在测试集上的预测结果均方根误差值(RMSE).
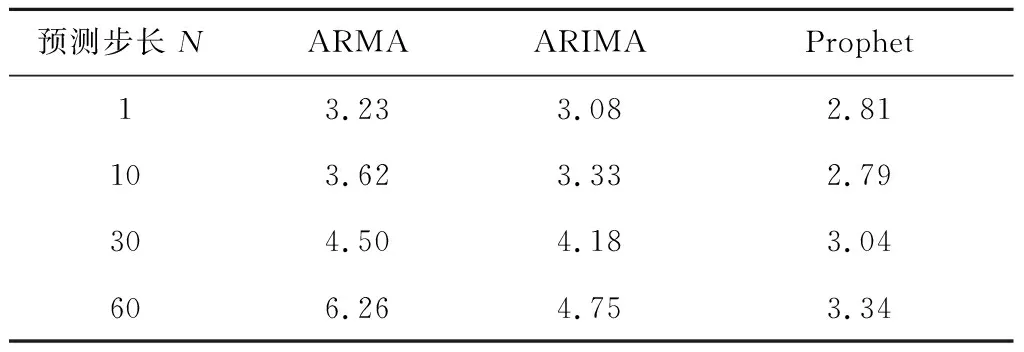
表2 不同算法预测结果RMSE对比
可以看出,相比于ARMA模型而言,ARIMA有较优的预测性能,而在3个模型中,Prophet模型在各组预测步长下均能取得最优的RMSE误差.随着预测步长的增大,3个模型的RMSE误差均呈现上升趋势,表明增大预测时间跨度将导致预测性能下降.图9的后半段(时间段5 000—6 000 s)为预测步长N=30时结果.
此外,为衡量三类算法的计算开销,计算了预测模型的平均耗时.结果表明,预测时间步长对模型的计算开销未见明显影响(即表2中预测未来N=1与N=60个数据的时间开销相近).在1核心4 GB内存实例上,3个模型平均单次预测耗时分别为ARMA(0.375 s),ARIMA(0.035 s)、Prophet(1.94 s).这说明Prophet模型虽然具有更优的预测性能,但计算开销相较于ARMA与ARIMA有明显增大.
2.3 动态扩缩容
为验证本文所提方法在节点网络带宽动态扩缩容方面的实际效果,在测试环境中对方法进行验证.图10展示了网络流量预测及带宽动态扩缩容处理的结果.测试环境包括两个Kubernetes节点,通过流量控制模块为每个节点预先配置出向带宽限制为100 Mbit/s.监控数据采集模块实时收集节点的网络流量信息,并提交给流量预测模型.动态扩缩容模块根据预测结果,结合动态扩缩容配置信息对节点的出向带宽进行动态调整.其中节点的扩缩容配置按照式(5)进行计算,期望的网络使用率α设置为50%(选取[50%,60%,70%,80%,90%]5组期望网络使用率参数,通过对比实验发现只有在α=50%时,能满足图10中的突发访问流量请求),扩容乘数n设置为15(通过评估历史网络流量数据的变化速率与扩缩容操作频率得到,既满足扩缩容操作不过于频繁,且能及时响应网络流量动态变化).流量监控数据为通过Prometheus实时采集的网络流量数据,由iperf工具压测产生.带宽限制值序列表示节点的实际带宽上限值,可通过网络带宽动态扩缩容模块进行调节.在实验的动态扩缩容配置参数中,期望的带宽使用率为50%,因此从图10中可以看出,节点的实际带宽值高于节点的实时流量,通过这样的冗余设置,有利于避免突发流量导致的网络拥塞(图10中展现的两处突发流量都较好的得到了处理).拟合值序列为流量预测模块基于采集到的实时流量监控数据拟合得到,而预测值为预测模块基于历史数据预测得到(图10中红色虚线左侧为拟合值,右侧为预测值).在实验中,预测步长N为10,模型预测值与实际监测流量的RMSE值为3.25 MBit/s,表明预测模型能有效的对网络流量变化进行动态追踪,从而为动态扩缩容模块提供准确的预测值.
2.4 大规模网络流量管理性能分析
Kubernetes集群在实际应用场景中管理的节点数往往规模庞大,为提升本文方法处理大规模Kubernetes集群网络流量管理能力,本文实现了基于restful接口的网络流量控制服务并发访问,并借助Kubernetes平台接口实现服务的高可用负载均衡.整体架构示意如图11所示.其中,带宽调度服务通过高可用集群提供的虚拟IP访问流量控制服务实例,实现服务高可用功能.流量控制服务运行于负载均衡池中,根据配置的请求调度算法,将请求分发到不同的流量控制服务实例上,实现负载均衡的效果.在此基础上,结合Kubernetes提供的水平自动扩缩容(Horizontal Pod Autoscaler,HPA)功能,实时监控流量控制服务实例的资源使用情况,根据其资源使用情况,进行水平扩缩容的操作.当并发请求数过大时,增大实例数,反之则减少服务实例数,实现满足大规模网络场景下并发请求需求的同时,提高资源利用率.
为验证本文方法处理大规模Kubernetes集群网络流量管理的能力,在实验环境进行了测试.实验运行的集群配置包括4台高性能服务器,每台配备80线程CPU、256 GB内存,节点间采用万兆以太网互联.在物理集群上,建立了一个包含100个测试Pod实例的Kubernetes集群,其中每个Pod配置2核CPU,4 GB内存.每个流量控制服务实例分配8核CPU,16 GB内存.为模拟实时网络访问流量,采用iperf软件从10个客户端节点对Kubernetes集群中的100个Pod实例进行访问,单个Pod的峰值访问流量不超过100 Mb/s.预测模型采用Prophet,预测间隔为30 s,监控数据采集频率为每5 s一次,测试结果表明:单次流量控制管理服务请求响应延迟为(1.960.01)s.由于采用Prophet作为流量控制管理服务的预测模型,其计算延迟为流量控制服务响应延迟的主要组成部分.此外,对流量控制服务实例访问接口进行压力测试,数据表明,在响应延迟不超过2 s的情况下,单个流控服务实例响应的并发处理请求数在40左右,即满足100个Pod节点的Kubernetes集群网络流量管理需要配置3个网络流控管理服务实例.
3 结论
1)针对Kubernetes容器网络的两种主流参考实现Veth pair和Macvlan,提出了一种Kubernetes集群中的容器网络流量弹性管理方法,通过在集群中部署Prometheus监控软件,获取各节点实时流量数据,建立网络流量预测模型,捕获节点流量中的趋势特征、周期特征以及突发事件特征.
2)在预测模型的基础上,结合网络带宽扩缩容规则,将扩缩容需求转译为流量控制模块可执行的流量控制规则,进而实现动态、细粒度的网络流量控制.
3)Kubernetes插件以服务的方式响应外部流量控制请求,对外屏蔽了底层Docker网络的具体实现方式,支持流量控制请求的实时响应,为动态、弹性的集群网络流量管理提供了便捷的实现方案.实验结果表明:本文方法能实现在线、高效的细粒度Kubernetes容器集群网络服务质量管理.
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
计算机应用与软件(2022年2期)2022-02-19
读者·校园版(2019年24期)2019-12-10
现代电子技术(2016年24期)2017-01-19
考试周刊(2016年82期)2016-11-01
小朋友·聪明学堂(2015年8期)2015-11-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
现代电子技术(2009年8期)2009-06-25
