
基于语句结构信息的方面级情感分类①
2020-11-24 05:46李梦磊赵梦凡
计算机系统应用 2020年11期
李梦磊,刘 新,赵梦凡,李 聪
(湘潭大学 信息工程学院,湘潭 411105)
在自然语言处理(NLP)领域中,情感分析任务一直都备受关注,其通过挖掘文本中的信息来分析人们所表达的情感.情感分析任务本质上是一种情感分类,通过对语句中的信息进行建模与分析,从中提取句子的情感倾向(积极,消极,中立).但是当句子中有多个目标词汇时,往往不能准确的表达出句子的情感极性.
目前,方面级情感分析任务的处理方法主要分为基于机器学习和基于神经网络两类.基于机器学习的方法主要是对文本进行手动构建特征信息,再使用机器学习分类器将特征信息进行分类,常用的特征分类器有支持向量机(Support Vector Machine,SVM)、朴素贝叶斯等.基于神经网络的方法则是对文本进行深度语义特征向量表示,之后根据给定方面来预测情感极性.相比于手动构建特征信息,使用神经网络进行提取可以更全面,并且其本身可以从数据中学习到目标特征表示而不需要进行特征工程.常用的神经网络有循环神经网络(Recurrent Neural Network,RNN)、长短期记忆网络(Long Short-Term Memory,LSTM)等.
本文提出了一种基于语句结构信息的语义表示方法,用于方面级情感分析任务.该方法从多方面融合了句子的语义信息和结构信息,分别从句子的语义序列和词性序列中提取特征向量,之后采用后文提出的3 种方法进行特征向量整合.采用基于语句结构信息的语义表示方法,有助于提升方面级情感分析结果的准确性.
1 相关工作
1.1 方面级情感分析
方面级情感分析是情感分析的一个子任务,目的是分析目标方面在语句中的情感倾向.方面级情感分析的处理方法主要分为基于机器学习的处理方法和基于深度学习的处理方法.基于机器学习的方法,通过将手动构造的特征送入机器学习分类器来处理方面级情感分析.基于深度学习的方法是将词和词组表示为词向量后送入神经网络学习特征用来分类.常用的词向量模型有文献[1]的CBOW 和Skip-Gram.近年来,用于处理方面级情感分类任务的神经网络主要是RNN网络及其变种.在此基础上,文献[2]和文献[3]将注意力机制首次成功应用到图像领域和自然语言处理领域,注意力机制开始在各项任务中大放异彩.文献[4]将目标方面与上下文相结合,通过基于句子的语法结构创建多个与目标相关的特征来改善与目标相关的情感分类.文献[5]提出了一种Attention-based Long Short-Term Memory Network,当以不同的方面作为输入时,使用注意力机制可以注意到语句的不同的部分.文献[6]提出对语句和目标方面分别进行建模再进行处理的方法.目前的大部分方法都是以语句作为为输入,神经网络的输出作为语句表述,这种方法主要提取到语句在语义上的信息,一定程度上忽略了词语在句型结构上的依赖型.但是语句结构信息包含可以确定与目标方面情感相关词汇的位置信息.在本文中,我们尝试从文本词性序列中学习到语句结构信息,并将这些语句结构信息与语义信息融合构建成基于语句结构信息的语义表示用于处理方面级情感分析任务.
1.2 双向长短期记忆神经网络
双向长短期记忆神经网络,简称Bi-LSTM,是在长短期记忆神经网络的基础上发展而来的.双向长短期记忆神经网络是由一个前向的长短期记忆神经网络和一个反向的长短期记忆神经网络所组成,旨在从两个方向对目标序列进行提取特征.文献[7]长短期记忆神经网络,简称LSTM 是循环神经网络的一个变种,它因克服了循环神经网络存在的梯度消失和梯度爆炸的问题而倍受喜爱.LSTM 在循环神经网络的基础上添加了遗忘门,输入门和输出门.LSTM 神经元结构如图1所示.
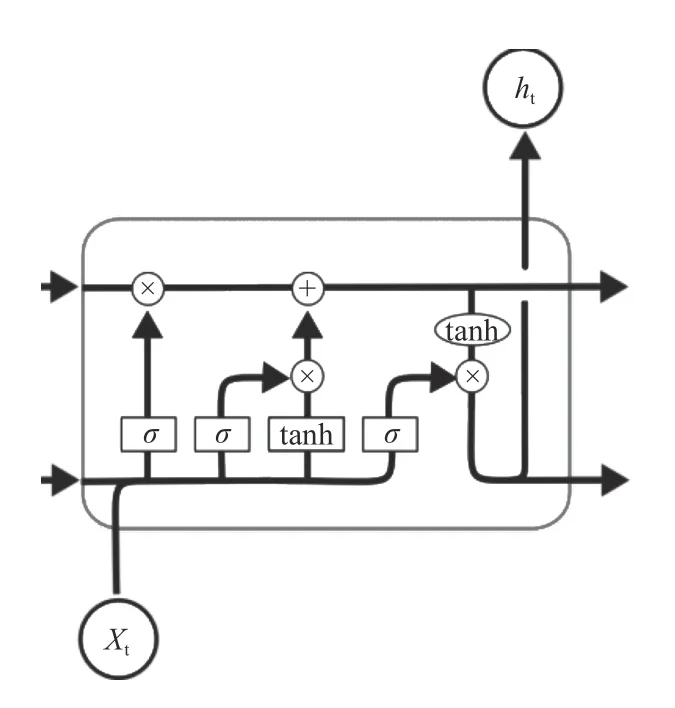
图1 LSTM 神经元结构图
遗忘门通过把上一序列隐藏状态与本神经元的输入送到激活函数决定神经元遗忘或者保留哪些信息.
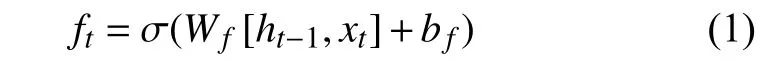
输入门决定神经元中更新哪些新信息,使用Sigmoid 函数决定神经元中哪些部分被更新,然后与通过tanh 函数的上一序列隐藏状态和本神经元的输入相乘得到新的细胞状态.
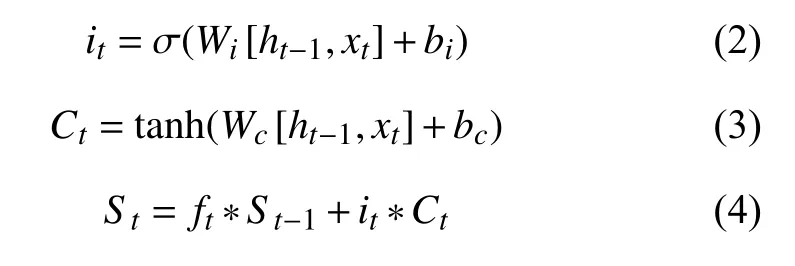
输出门决定神经元的哪些信息会被输出,首先使用Sigmoid 函数决定神经元中哪些部分需要输出,然后与通过tanh 函数的细胞状态相乘得到输出的信息.

2 基于语句结构信息的表示方法
本文假设语句结构信息由语句词性序列和位置信息所组成,并试图使用Bi-LSTM 提取语句结构特征.模型框架如图2所示,模型的输入有3 个部分文本序列,文本词性序列和给定的目标方面.模型框架的流程为:首先,将文本序列和文本词性序列进行嵌入表示成向量后分别送入到两个Bi-LSTM 从两个方向进行学习语义特征表示和语句结构特征表示.接着,将学习到的语义特征表示和语句结构特征表示进行融合构建成为基于语句结构信息的语义表示.然后将目标方面的嵌入表示与基于语句结构信息的语义表示相结合得到最终的基于目标方面的语句表示,最终将语句表示送入到Softmax 分类器中得到该方面的情感分类.

图2 基于语句结构信息的语义表示模型框架图
2.1 语义表示和语句结构表示
(1)词性嵌入
对于给定一条长度为n的语句s=[w1,w2,···,wn]和一组长度为m的目标方面t=[wi,wi+1,···,wi+m-1],将单词在语句中的词性标注映射到一个向量空间中,我们称其为词性嵌入.例如,对于每一个单词wi的词性,可从MV×dw中得到vi属于Rd.其中V是一个词性表的大小,dw是embedding 维度.在嵌入查找工作完成后,可以得到语句s的词性序列表示和目标方面t的词性序列表示.
(2)Bi-LSTM 编码的语义表示和语句结构表示
在这一节中,我们使用两个Bi-LSTM 分别提取语义特征和语句结构特征.输入词向量序列s[w1,w2,···,wn]到Bi-LSTM 中,Bi-LSTM 将从两个方向(从前往后和从后往前)提取语义特征.Bi-LSTM 的隐藏单元将生成一个隐藏的状态序列h作为由Bi-LSTM 编码的语义表示.相同的,通过将词性向量序列pos[w1,w2,···,wn]输入到Bi-LSTM 中学习到语句结构特征表示.
2.2 基于语句结构信息的语义表示
通过将词向量序列和词性向量序列送入两个Bi-LSTM 中,我们将得到语句的语义表示(表示为s)和语句结构特征的表示(表示为ss).接下来,我们通过将语义表示向量和语句结构表示向量进行融合从而构建基于语句结构信息的语义表示.在此,本文提出了3 种将语义表示向量和语句结构表示向量进行融合的方法.
(1)后注意力机制表示
将得到的语义表示向量hs和语句结构向量hss进行拼接得到向量h,并对拼接后的向量使用注意力机制,计算出语义信息关于语句结构的注意力权重分布α和基于语句结构信息的语义表示γ.
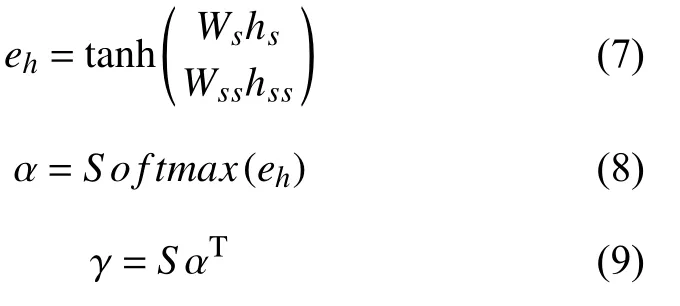
其中,hs是由Bi-LSTM 编码的语义表示,hss为由Bi-LSTM 编码的语句结构表示,Ws与Wss是线性变换函数中的参数,α是注意力权重分布,γ是基于语句结构信息的语义表示.
(2)先注意力机制表示
对语义表示向量hs使用自注意力机制,以进一步加强词与词在语义上的相关性,得到向量表述γs.相同的,对语句结构表示也使用自注意力机制,增强词与词在语句结构上的相关性,得到向量表述γss.注意力机制的使用可以使得语句在词与词之间在语义和语句结构上的相关性进一步加强,最终将两个向量进行拼接得到基于语句结构信息的语义表示γ.
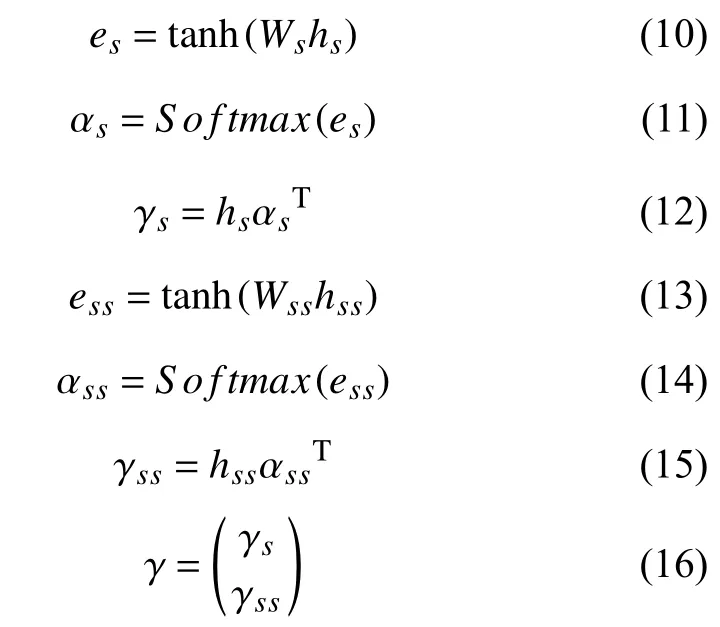
其中,hs是由Bi-LSTM 编码的语义表示,Ws是线性变换函数中的参数,αs是语义表示中词与词之间的注意力权重,γs是基于注意力机制的语义表示,hss为由Bi-LSTM 编码的语句结构表示,Wss是线性变换函数中的参数,αss是语义表示中词与词之间的注意力权重,γss是基于注意力机制的语句结构表示,γ是基于语句结构信息的语义表示.
(3) Attention-Over-Attention (AOA)表示
受到文献[8]的启发,文献[8]使用AOA 模块计算出目标方面和语义上的互信息,最终由目标方面关于语义的注意力权重和语义关于目标方面的注意力权重计算出基于目标方面的语句表述.在此,我们一样使用AOA 模块将语义表示和语句结构表示进行点乘计算出互信息矩阵M,再对矩阵M使用逐行注意力机制和逐列注意力机制,得到语义关于语句结构的注意力权重和语句结构关于语义信息的注意力权重,根据权重信息计算出基于语句结构信息的语义表示γ.AOA模块使得语句结构特征和语义特征更加充分的融合,即语句结构特征可以关注到与结构相关的语义特征,也可以使得语义特征关注到与语义相关语句结构特征.
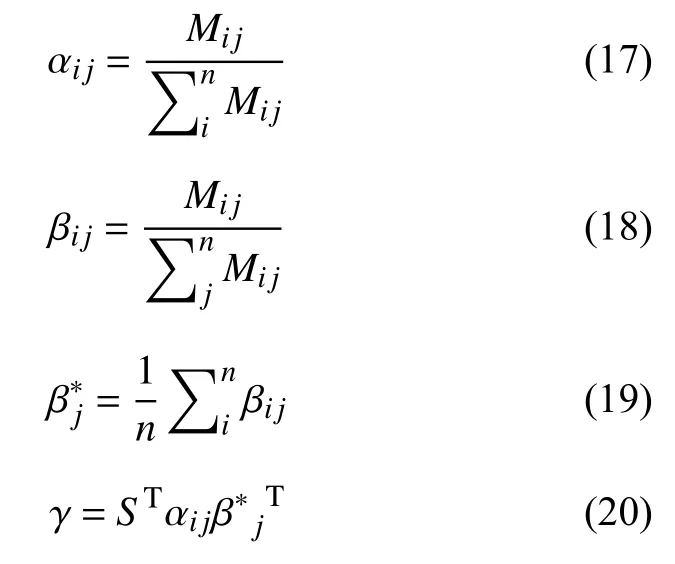
其中,α是语句结构关于语义的注意力权重,β是语义关于语句结构的注意力权重,β*是语义关于语句结构的注意力权重的平均值,γ是基于结构信息的语义表示.
2.3 带有方面嵌入的语句表示
由于基于语句结构信息的语义表述γ不能够充分利用目标方面的信息,如果对基于结构信息的语义表示直接分类,得出的结果近似于语句的情感分类.因此,我们利用注意力机制计算出目标方面在语句描述γ上的注意力分布β,并根据该注意力分布β得到可以用于分类的带有方面嵌入的语句表示h*.

其中,γ是基于语句结构信息的语义表示,tasp是目标方面的嵌入表示,easp是将目标方面嵌入到语义信息中每个单词的向量表示中,αasp是γ关于给定方面的注意力权重分布,h*是带有方面嵌入的基于语句结构的语义表示.
带有方面嵌入的基于语句结构的语义表示就是本文所提取的最终用于情感分类的语句表示.我们使用线性层把该语句表示从语句空间转化到情感分类的类别空间中后使用Softmax函数将其转换成各个类别的概率.
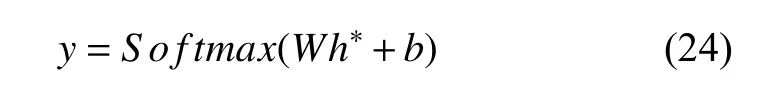
其中,概率最大的就是关于目标方面的情感分类类别.
2.4 模型训练
由于任务为分类任务,所以模型的损失函数采用交叉熵损失函数,模型使用反向传播算法通过端到端的方式进行训练.损失函数如下,
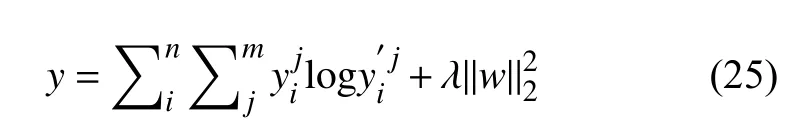
其中,y为目标函数,n是语句的数目,i为语句的索引值,m为类别数,j为类别的索引,y为第i条语句关于目标方面的真实类别,y`为第i条语句预测的为第j个类别的概率,为损失函数的正则项用以降低过拟合现象的发生,提高模型的泛化能力,λ为正则化系数.模型通过最小化损失函数进行更新训练.
3 实验分析
3.1 实验数据集
实验的数据集来自文献[9],本数据集是方面级情感分析任务研究中经常使用的数据集.本数据集含有手提电脑评论和餐厅评论两个领域的子数据集.数据集中已经标注好了每个语句中的方面和目标方面所呈现的情感倾向.任务目标是预测出给定方面在本条语句中的情感倾向.数据集中数据的分布在表1中给出.
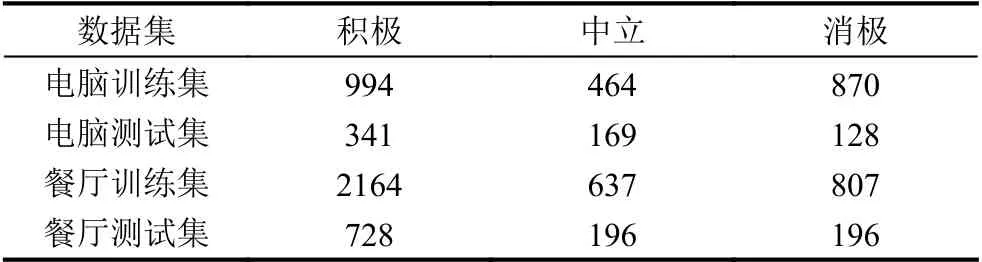
表1 SemEval 2014 Task 4 数据集分布
3.2 超参数设置
在实验中,词向量由文献[10]中的Glove1 进行初始化,每个词向量维度为300.我们使用Batch size 为25,初始化学习率为0.01 的Adam 优化器来训练模型.其他模型参数采用随机初始化,初始化的概率分布服从均匀分布.实验中,Bi-LSTM 的隐藏单元大小维度为150 维.
3.3 词性嵌入维度实验
词性的表示与词性的嵌入维度息息相关,一般来说,向量维度的大小决定了向量所包含信息量的多少.所以词性嵌入的维度过小不足以完全表示词性的信息,但是词性向量维度过多会使网络中含有过多的冗余信息干扰,使得模型效果不佳.因此,我们以先注意力机制表示模型作为标准,使用对比实验来证明哪种词性嵌入维度最适合模型.由于词向量维度等其他网络参数的限制,将词性的嵌入维度设定为50,100,150,200,250,300.Batch size 设置为25,模型运行10 个epoch的实验结果来进行对比.
从表2以看出将词性嵌入维度可以在一定程度上影响模型的效果,当词性嵌入维度较小时,模型的效果会随着词性维度的增大而逐渐增大,但是当词性嵌入维度变得过大时,模型的效果甚至出现了下降的趋势.因此,为了词性嵌入表示更多的信息同时又兼顾模型的效果,本文将词性嵌入维度设置为150.
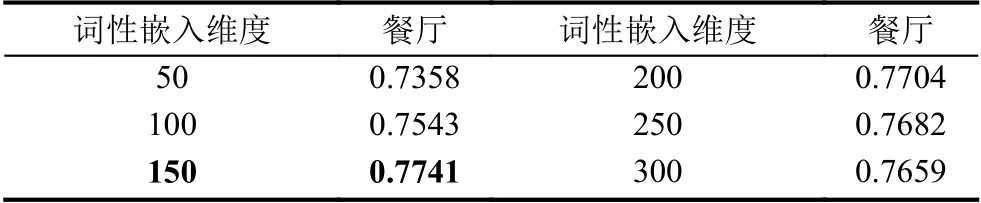
表2 词性嵌入维度对比实验
3.4 融合表示向量对比实验
本文通过将语义表示向量和语句结构表示向量进行融合构建出基于语句结构的语义表示向量,并将该向量与方面嵌入结合后用于最终的情感分类.为了证明本文所提出的3 种融合方法对本模型情感分类的结果的贡献程度.因此本节设置对比实验,将使用3 种融合方法网络模型与不使用3 种融合方法的网络模型(即使用语义表示向量和语句结构表示向量简单堆叠后的向量作为基于语句结构的语义表示向量,其余模块不做任何变动) 进行对比,以证明3 种方法的有效性.对比结果如表3所示,对比实验选用餐厅子数据集,词性嵌入维度为150,其余超参数设置与3.2 节中描述相同.

表3 融合表示向量对比实验
由表3可知,语义表示与语句结构表示的融合方法会很大程度上影响模型的效果.其中,不使用任何融合方法,直接将语义表示向量和语句结构表示向量简单堆叠后作为基于语句结构的语义表示向量,这种方法最为简单,但是同时模型的效果也很一般.这主要是由于语义信息与语句信息没有充分融合所导致的.而在其余3 种融合向量构建方法中,基于AOA 的融合表示效果最佳,AOA 可以从语句结构与语义信息的互信息中提取相关性较强的特征,因此可以使得模型效果更好一些.
3.5 对比实验与分析
将本文提出的模型与未使用语句结构信息的基线模型进行比较以证明本文模型结构的有效性.待比较的模型包括:LSTM,TD-LSTM,ATAE-LSTM.我们使用准确度和F1 值作为衡量模型的指标.
SVM[11]:使用N-gram 特征,解析特征等信息使用SVM 分类器进行情感分类.
LSTM[5]:把文本数据送入到LSTM 网络中,使用LSTM 的输出作为文本的语句表示,然后直接使用该语句表示进行情感分类.
TD-LSTM[12]:根据目标方面把原始语句分为前后两个语句,使用两个LSTM 分别对前后语句进行建模,最终将两个LSTM 的输出拼接起来进行最后情感分类.
ATAE-LSTM[5]:用LSTM 对输出的语句进行建模得到语句表示,然后将语句表示和方面嵌入表示结合后使用注意力机制得到带有方面嵌入的语句表示,最后根据该语句表示进行情感分类器.
Memnet[13]:在词嵌入的基础上多次应用注意力机制,最终选择最顶层的语句表示进行情感分类.
IAN[6]:使用两个LSTM 网络对语句和方面进行建模,分别使用两个LSTM 的隐藏状态生成注意力向量,最终基于这两个向量生成语句表示和方面表示实现最后的分类.
由表4中数据可知,与基线模型相比,本文的模型在该数据集上的表现更佳一些.在本文提出的3 种关于语义表示与语句结构表示的融合方法中,使用AOA方法的效果更佳些,这可能是由于AOA 模型分别考虑了语句结构关于语义信息的特征和语义信息关于语句结构的特征,使得语句结构特征与语义信息能够充分融合.因此,带有语句结构信息的网络模型比不带有语句结构信息的网络模型表现更佳.
3.6 样例分析
在图3中列举了测试集中的部分样例,为了分析每个单词对于目标方面情感分类的重要程度,本文将最终的带有方面嵌入的语句表示进行可视化.图中x轴方向为语句中的每个单词,y轴方向为目标方面,颜色的深浅代表了本单词对于目标方面最终分类的重要程度,单词对于最终分类影响程度越大,则颜色越深.例如:在“The food is good but the price is so expensive.”这条语句中,一共有“food”和“price”两个方面,而且在本条语句中这两个方面呈现了相反的情感极性.但在图3中,可以看到当给定的目标方面为“food”时,本文的网络模型会关注到“good”而不是“expensive”,当给定目标方面为“price”时,网络模型关注到“expensive”,从而给出正确的情感极性判断.这一个特点得益于在语句结构中“good”用来修饰“food”而不是“price”,本文的网络模型通过学习这一个特点来给出正确的情感极性判断.因此,本文的网络模型在给出不同的方面时,可以关注到语句中与目标方面相关的部分而不会被其他无关词语干扰.

表4 模型对比实验结果

图3 最终语句表示的注意力权重分布图
4 结论与展望
在本文中,我们提出了一种基于语句结构的语义表示来解决方面级的情感分析任务.本文提出了一种从词性序列提取语句结构特征的新方法以及3 种关于语句结构特征和语义特征相融合的方法,最终通过基于语句结构特征的语义表示去预测目标方面的情感倾向.实验证明,带有语句结构信息的模型比不带有语句结构信息的模型效果更好一些.在接下来的工作中,可以进一步的完善词性嵌入的表示来完善文本结构信息的提取.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
长江学术(2015年1期)2015-02-27
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
小雪花·初中高分作文(2009年8期)2009-11-16
