
面向微博文本的自杀风险识别模型①
2020-11-24 05:46赵宝奇孙军梅葛青青
计算机系统应用 2020年11期
章 宣,赵宝奇,孙军梅,葛青青,肖 蕾,尉 飞
1(杭州师范大学 信息科学与工程学院,杭州 311121)
2(福建省软件测评工程技术研究中心,厦门 361024)
在过去的几年中,深度卷积网络在自然语言处理领域中表现优于现有技术.虽然卷积网络已经存在很长时间,但由于可用训练集的大小和所考虑网络的大小,其表现存在很多限制.短文本分类是自然语言处理领域的重要任务,包括情感分析、问答、对话管理等.
伴随Web 2.0 时代的到来,社交媒体平台得到快速发展.而在众多网络社交媒体平台中,微博以其独有的特点受到广大网民的关注和青睐,已然成为最受欢迎的社交媒体之一.据中国互联网络信息中心发布的第43 次《中国互联网络发展状况统计报告》[1]显示,截至2018年12月,我国的网络用户规模已达到8.29 亿,其中很大一部分的用户使用微博平台进行日常的沟通交流、信息分享.人们可以自由、便捷、实时地在微博平台上抒发自己的情感、观点或评论,但也由此产生了大量冗余无用的短文本内容.因此,通过微博文本的分类提取这些信息中的有价值信息是非常有必要的,将有价值信息整合分析,可应用于实际问题的探索.
微博短文本与其他形式的短文本不同,具有长度短小,信息含量较少,数据庞大,实时更新快,语言表述不规范等鲜明的特性.同时,作为线上文本,微博网站中的文本同线下文本一样,也能够显露出个体的身份、所处的社会关系、情感表达等重要信息.Barak和Miron 的研究表明自杀意念的人群撰写的线上与线下文本在特征上存在很高的一致性[2],因而通过线上文本分析开展自杀风险评估工作具有研究基础和可行性.有研究表明,微博等网络社交媒体已经成为探索发现自杀者的新平台[3].现有的一些研究也已把从微博提取与自杀相关的想法和行为数据作为自杀风险识别的分析依据[4].
因此,利用微博平台进行自杀风险识别研究是非常有意义且可行的.本研究将建立一个基于微博文本的自杀风险识别模型,用于从微博社交平台上主动地、高效地挖掘出潜在的具有自杀风险的用户.在本文中,我们针对微博短文本提出了一种混合架构的神经网络模型nC-BiLSTM,有效的解决了当前神经网络单一结构在预测精度上的瓶颈问题,分类的准确性得到了提高.因为识别过程是计算机程序自己完成的,速度和准确率优于人工识别方式,也为相关机构和人员早期进行自杀干预提供技术保障.
1 研究现状
研究人员从上世纪50年代起就已经开始了对短文本分类的研究.Kaljahi 等[5]提出了Any-gram 核方法,用于提取短文本的N-gram[6]特征,采用双向长短时记忆网路(Bidirectional Long Short-Term Memory network,Bi-LSTM)进行分类,在基于主题和句子级的情感分析任务中取得了一定的提升.Kim 等[7]将卷积神经网络(Convolutional Neural Networks,CNN)用于解决句子分类问题.Zhou 等[8]将二维最大池化操作引入到双向短时记忆网络,在时间维度和特征维度上对文本的特征进行提取,完成文本分类任务.牛雪莹等[9]将Word2Vec、TF-IDF和SVM 结合对微博文本进行分类.随着对微博短文本分类应用领域的广泛研究,国内外有学者认识到基于微博文本开展基于网络的心理健康状态乃至于自杀风险研究的前景,并且进行了一些积极的尝试.张金伟[10]利用情感词典、关键词识别算法等技术针对微博文本开展了网民心理健康评估的研究.Wang 等[11]根据语言规则创建词库分析单条微博的潜在抑郁倾向,再通过用户语言、行为方面的特征建立抑郁症检测模型,实验验证模型准确率可达80%左右.Jshinsky 等[12]通过对大量Twitter 文本进行分析来评估文本的自杀风险因素,锁定有自杀风险的用户群,将他们的分布同地理划分区域内自杀发生率进行匹配,发现两者具有较好的相关性.香港大学的Li 等[13]通过分析一名15 岁自杀男孩的193 条新浪微博数据,发现其在一些特定词语类别上的使用与其他用户不同(例如第一人称单数使用频率更高).中国科学院心理研究所的田玮等[14]采用专家分析法筛选出有自杀倾向的微博数据660 条,分别使用多层神经网络、朴素贝叶斯及随机森林算法建立自杀风险识别模型,预测结果表明基于多层神经网络的算法模型可更有效地对微博用户的自杀风险进行预测.
目前在微博短文本的特征提取过程中,未能较好地考虑词语在语义表示中的重要程度,容易出现重点词被忽略,而非重点词被重视等情况,导致分类效果不是很好,且当微博短文本分类应用于自杀风险识别领域时,研究采用的主要是人工抽取特征和机器学习算法相结合构建自杀风险识别模型,导致系统适应性较差.而神经网络模型通过对数据多层建模来自动提取数据的特征,避免了繁琐且代价极高的人工特征提取方式,并具备良好的泛化能力.但是目前单一的神经网络结构只是通过加深层数才能实现精度的提升,而一味的加深网络的层数会导致训练过程难以收敛,并产生梯度消失的现象,所以导致其在精度提升上遭遇瓶颈.针对上述问题,本文提出了改进的nC-BiLSTM 模型,并将其用以进行微博文本自杀风险识别,该模型结合了并行结构的卷积神经网络(CNN)以及双向长短期记忆网络(Bi-LSTM)两种模型的优点.
2 模型提出与架构设计
2.1 模型提出
微博文本具有长度不定、短小、文本包含的词汇量有限、存在较为严重的特征稀疏问题,且对于较长的文本又需要对其上下文语义信息进行捕捉等特点.
针对以上的问题,本文提出了一种基于神经网络混合架构的分类模型,该模型很好的利用了多路并行CNN 和Bi-LSTM 的优势,较已有的分类模型的准确率有显著提高.下面对该模型的提出思路进行详细介绍.
CNN 是一个层次结构,局部特征提取能力很强.它可以通过特定的卷积核来提取文本的特定位置的局部特征,进而会有池化层将该局部特征进行筛选从而得到更高层的全局特征,但是显然这些全局特征也是基于特定局部特征选择出来的,故造成了使用单一卷积层的CNN 提取的特征会呈现局部性.为了进一步加强特征提取的效果,当前的CNN 在应用中主要以串行叠加方式实现,但是层数叠加到一定层时就无法继续提升模型效果,且会使训练时间过长,还易产生梯度消失,最终降低模型效果,所以该方式在精度提升上遇到了瓶颈.CNN 还存在另一个缺陷,经过卷积层提取的特征向量经过池化、全连接层处理后无法体现特征之间的相互联系,所以CNN 无法学习到文本内容中蕴含的上下文语义特征.
相较于CNN,长短期记忆网络(Long Short-Term Memory,LSTM)对局部特征的提取效果不佳,但它是一个顺序结构,可以提取出上下文语义特征,所以LSTM 在处理序列数据时往往会取得不错的效果.由于本研究是个句子级的分类任务,所以考虑上下文信息是十分有必要的.但是在标准的LSTM 网络中,状态的传输一直是从前往后单向的,它只考虑到了一个方向,然而文本序列中各个元素与前后元素都有关联,所以当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关.这造成了LSTM 对文本的深层特征的提取能力具有局限性[15].所以可采用Bi-LSTM[16]来进一步挖掘文本的深层上下文语义特征.Bi-LSTM 网络通过引入第二层网络结构来扩展单向的LSTM 网络,而隐藏的连接在相反的时间顺序流动.所以,Bi-LSTM可以综合考虑前后文的信息,保证了在时间序列上前面和后面的信息都能考虑到.
综合上述CNN 和Bi-LSTM 的特点,本文考虑使用多个并行CNN,且卷积层使用多个不同尺寸的卷积核.这样可以分别提取文本数据中不同宽度视野下的局部特征,使获得的特征向量包含的信息更全面,模型效果也会更好.同时为了进一步挖掘微博文本的深层上下文语义特征,本研究考虑通过模型组合的方式将上述的多个并行CNN 和Bi-LSTM 结合起来,这样既可以提取文本数据的各局部特征,又可提取出文本的上下文语义关联信息.综上所述,本研究提出一种基于多并行CNN、Bi-LSTM 的微博文本自杀风险识别模型nC-BiLSTM (其中n 表示CNN 并行路数).该模型主要由两部分组成,选择多路并行的CNN 作为文本局部特征信息的提取器,将时间序列模型Bi-LSTM作为上下文序列特征的提取器,将前者的输出特征向量拼接融合后输入后者,最后特征全部提取完毕进行分类.
2.2 模型架构设计
本文提出的nC-BiLSTM 模型架构设计如图1所示.模型主要分为4 个层次,分别为词嵌入层、多路并行CNN 层、Bi-LSTM 层和全连接层,其中多路并行CNN 层内含卷积层和池化层,下面对各层进行详细介绍.
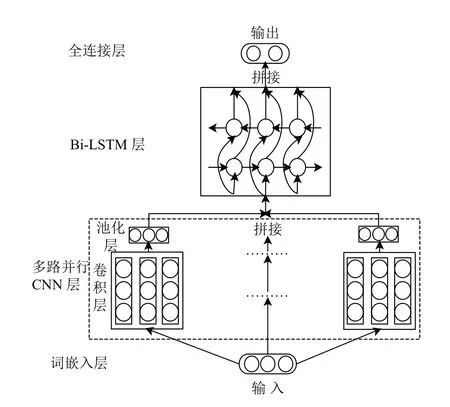
图1 nC-BiLSTM 模型架构
词嵌入层:本层作为模型的第一层,它的作用是将序列中的每一个字词映射为一个具有固定长度且较短的连续实向量.也就是把原先字词所在空间嵌入到一个新的向量空间中去,每个词向量在该空间内的距离表示它们之间的相似度,这样就保留了文本的语义特征.
首先输入数字序列形式的微博文本语料.根据去停用词后语料包含的字词数目最大值x,这里将序列的长度统一设为x,长度不足x的通过零值来补齐长度.设模型的输入序列为Xi=[i1,i2,i3,···,ix],ix∈D,且0≤x≤|D|,D为语料库中所有不同词构成的词典,|D|表示词典中词的数目.
在词嵌入层中存在一个权重矩阵T,它随机初始化后再通过训练不断更新,通过T能够将每个数字化的字词转换为其所对应的词向量:T[ik]=Ek.其中Ek代表得到的词向量.则词嵌入层的输出为E=[E1,E2,E3,···,Ex],Ek=T[ik]
多路并行CNN 层:本层由多个卷积核尺寸不一的CNN 并行组成,每个CNN 通路由一个卷积层和一个池化层叠加组成.经过词嵌入层后,文本数据被表示成序列化的数据形式,所以此处均采用一维卷积的方式.
卷积层的作用是从词嵌入层的输出E中提取出序列的特征向量.卷积操作涉及一个过滤器Wc∈Rd×h,d表示字符向量的维度大小,h表示过滤器移动的窗口大小.一个过滤器卷积生成特征向量可通过式(1)计算.

其中,f表示非线性的激活函数,conv表示卷积过程,表示的是偏置向量,c表示生成的特征向量.在这里设置了多个并行的卷积层,并且每个卷积层的卷积核尺寸不同,通过设置不同的h来实现.
然后需要将每一组特征向量输入池化层进行操作,池化层又叫采样层,其用以对数据进行降维,输出局部最优特征,减少模型复杂度.通常的做法是在卷积层提取出的局部特征上,在一个固定大小的区域上通过某种方法采样一个点,作为下一层网络的输入.这里使用的采样方法是最大池化,因为最大池化能够提取出最有效的特征信息,还能减少下一层的计算量.进行最大池化操作后生成的序列的特征向量见式(2).
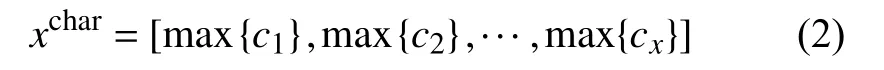
这里最后还需要将多个通路的输出特征向量做拼接处理,如式(3)所示:
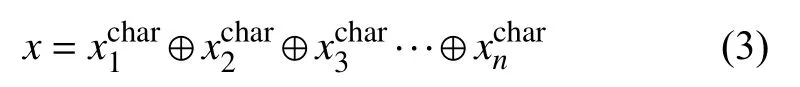
Bi-LSTM 层:本层的输入为多路并行CNN 的输出特征向量x,本层的内部结构如图2所示,通过组合两个方向相反的LSTM 来实现Bi-LSTM 层,这里将两个方向相反的LSTM 分别记做前向LSTM 和后向LSTM.
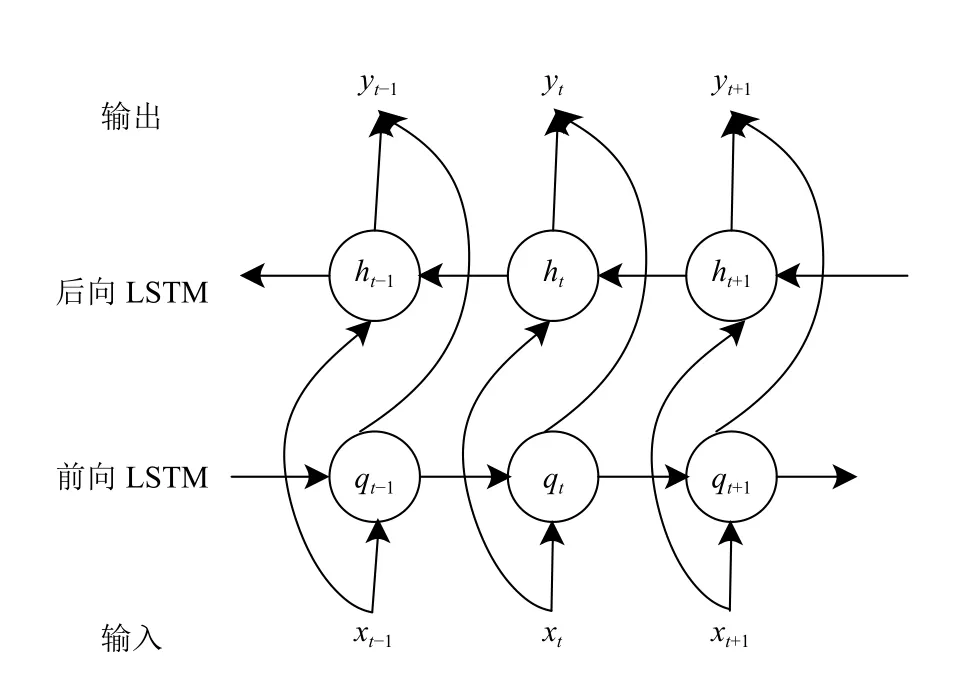
图2 Bi-LSTM 层内部结构
前向LSTM 的输出Q表示如式(4)所示:

后向LSTM 的输出H表示如式(5)所示:

Bi-LSTM 的输出Y表示如式(6)所示:

其中,符号 ⊕表示向量拼接.
全连接层:本层用于生成更高阶的特征表示,使之更容易分离成我们想要区分的不同类.本层的输入为Bi-LSTM 的输出向量Y=[y1,y2,y3,···,yn],采用反向传播算法对网络模型中的参数进行梯度更新.本文数据类别分为无自杀风险语料和有自杀风险语料两类,且特征差异较明显.据此特点,这里使用Sigmoid 分类器输出自杀风险判定的结果,因为它可以将任意一个实数映射到[0,1]区间范围内,适合用来做二分类,而且其在特征差异比较大时效果比较好.输出表示如式(7)所示.
其中,Sigmoidx代表分类器,Wx和bx为Sigmoid 分类器的参数,下标x代表迭代处于第x轮,result表示自杀风险识别的结果,result∈{有自杀风险,无自杀风险}.
3 实验及分析
3.1 样本人群与数据采集
自杀死亡样本人群:自杀死亡样本人群的收集工作主要依靠新浪微博专业人士的帮助.本研究通过与新浪微博名人账号“逝者如斯夫dead”(关注逝者的微博账号,专门通过发微博的形式介绍逝者的基本信息及死亡原因等)取得联系,在其同意的情况下,从他的微博中筛选出被描述为自杀死亡的微博用户账号.在每一个疑似自杀死亡帐号的微博主页中,我们又从其它微博用户的留言内容再次确认该帐号所有者是因自杀死亡.以这样的方法,截止到2019年8月,本研究共检阅并收集网络识别自杀死亡新浪微博用户帐号49 个.
正常样本人群:发送微博超过5 页内容并且最近7日内仍然有发微博的账号确定为正常样本,通过随机选取的方式收集正常新浪微博账号90 个.
数据采集:本研究通过搭建基于Python 爬虫的微博语料采集系统来定向爬取收集的微博账号文本数据.最终,采集系统一共收集7817 条微博语料,其中网络识别自杀死亡用户群体的语料共3827 条,将它们标注为有自杀风险语料,网络识别未自杀死亡用户群体的语料共3990 条,将它们标注为无自杀风险语料.
3.2 实验流程
本实验环境为Anaconda,是Python 专用于科学计算的发行版.实验使用Keras 深度学习框架,它是一个高度模块化的神经网络库,程序大致可分为以下3 个步骤:
(1)读取样本:加载数据预处理后得到的结构化xls 格式的数据文件.
(2)文本预处理:由于微博文本的特点导致其含有大量的噪声,为了提升模型分类效果,在采集得到微博文本后,先要对其进行预处理操作.文本预处理包括无效数据过滤、繁体字转换、文本分词、停用词去除等.文本预处理的目标是将文本转变成结构化的数据形式,用特征项向量表示或者文本向量化表示.
(3)模型训练:设定参数,分别调用Keras 中的相应算法库以进行模型的训练,并通过参数调整提高模型预测准确率.
3.3 评价标准
本研究中的语料分为有自杀风险和无自杀风险两类,模型测试结果共分为4 种,如表1所示.

表1 模型测试结果及其解释
本文采用二分类问题中的3 个常用指标作为模型性能评价标准:
(1)精准率(Precision):又称查准率,它描述了分类的准确程度,即分类结果中有多少是正确的.其计算公式如式(8)所示:
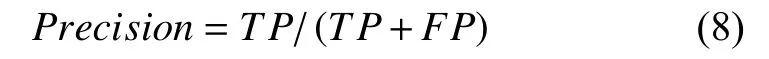
(2)召回率(Recall):又称查全率,它描述了正确分类的能力,即已知的文本中,有多少被正确分类.其计算公式如式(9)所示:
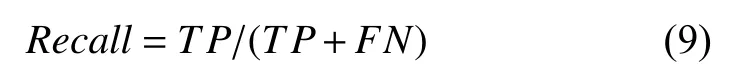
(3)F值(F-measure):F-measure是由Precision和Recall加权调和平均计算得出,其大小反映了分类器的综合性能,F值越大就表示分类器的综合性能越好,文本分类的效果越理想,其计算公式如式(10)所示:
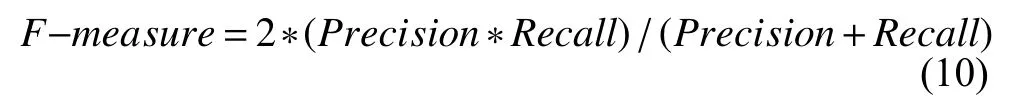
3.4 参数设置
本实验的基本流程如图3所示,训练过程中模型部分参数需要通过反复尝试寻找最佳值,待最佳参数确定好之后,再通过训练生成最佳模型.同时为了寻找nC-BiLSTM 模型并行CNN 路数的最佳设置,本文分别做了1 到5 路并行CNN 的模型训练,即并行路数n分别取值{1,2,3,4,5}.
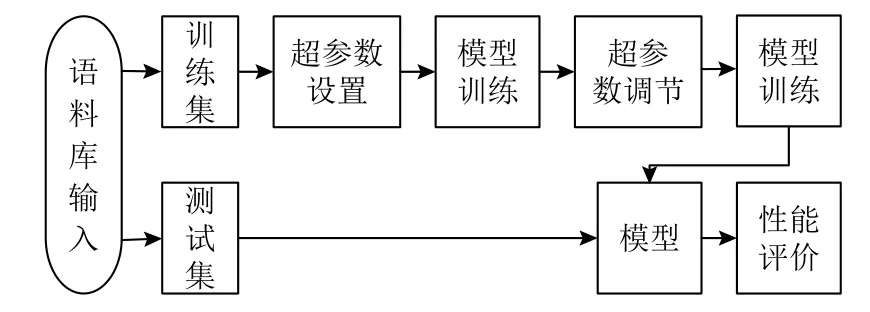
图3 实验基本流程
模型超参数指的是模型外部的配置变量,恰当的超参数设置对于生成一个性能优良的神经网络模型是至关重要的.本文研究中主要通过数据和经验来确定部分超参数,另有部分超参数需要通过实验来确定.
本模型嵌入层主要涉及的参数是词向量维度,卷积层主要涉及的参数有:滑动窗口大小、卷积核数;池化层涉及的参数有:采用窗口大小、丢弃率(dropout);Bi-LSTM 层主要涉及的参数有:节点数、丢弃率.全连接层的参数有:节点数、激活函数.本文模型超参数初始设置如表2所示.
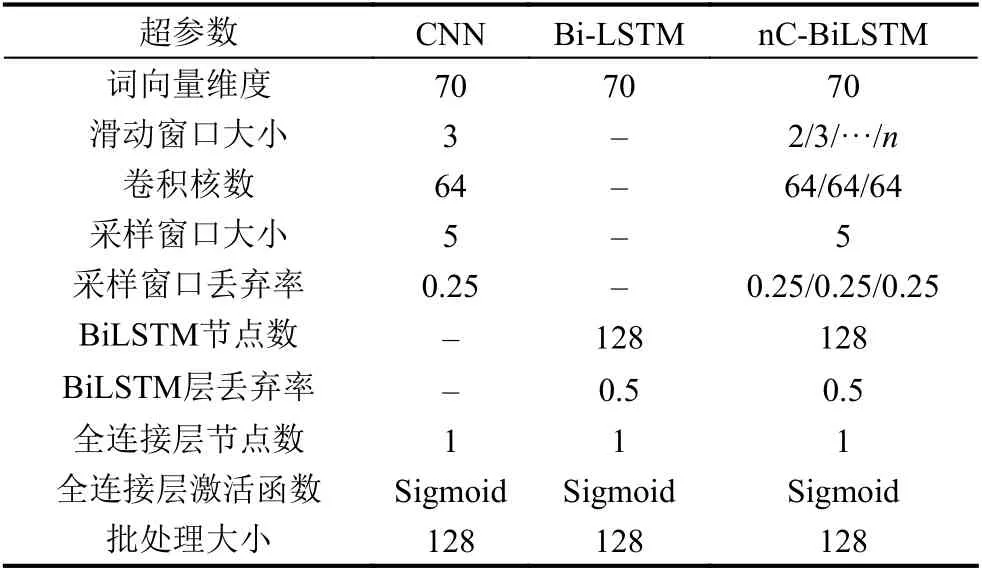
表2 超参数设置
3.5 实验结果
本文首先进行了基于nC-BiLSTM 的微博文本自杀风险识别模型的训练,分别测试了几种不同并行CNN路数的模型性能,从图4可得出当并行CNN 为3 路时,即3C-BiLSTM 模型的效果最佳.根据CNN 的原理,原因应为一开始随着并行路数的增加,特征提取效果越好,模型性能也随之增强,但是超过3 路后模型出现了过拟合,导致模型性能的下降.
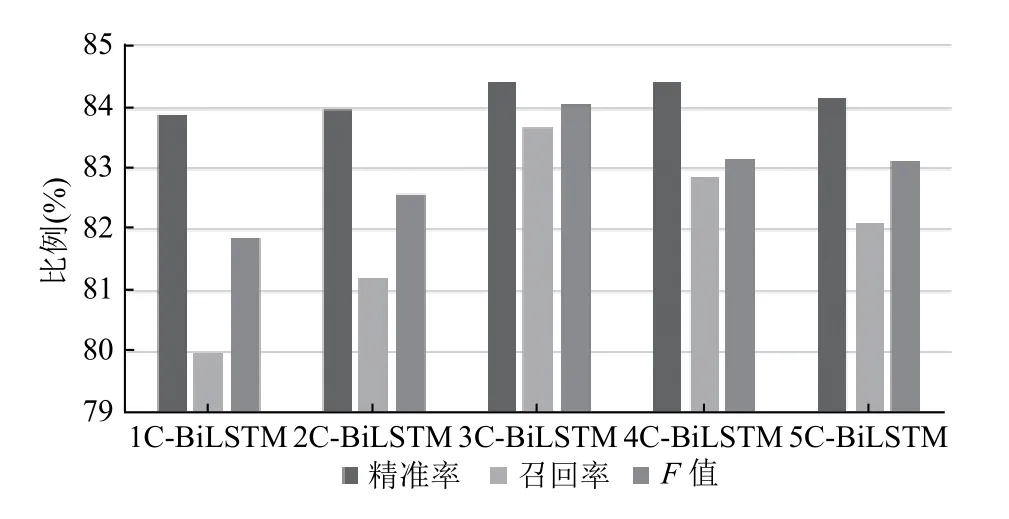
图4 不同并行CNN 路数的模型性能测试结果
3.6 性能评价
为了验证模型的有效性和准确性,我们通过实验分别与朴素贝叶斯模型、CNN 模型,以及BiLSTM模型进行了性能比较.
实验结果如图5所示.从图中首先可以看出深度神经网络模型的识别准确率相对于朴素贝叶斯模型有较大的优势.原因为朴素贝叶斯是一种词袋模型,它的基本思想是假设词与词之间是相互独立的,所以其无法提取文本的上下文语义联系.而深度神经网络模型的结构决定了它可以提取到很多词袋模型无法提取出的特征.

图5 模型自杀风险识别效果对比
从图5中可看出本文提出的模型3C-BiLSTM 的识别精准率、召回率、F值均高于其它对比模型,说明本文提出的模型有效地提升了自杀风险的识别效果.
4 结论
结果表明,社交媒体中的自然语言可以作为标记来区分自杀高风险人群和普通人群.相较于传统寻求医生或精神卫生专业人员的帮助,基于深度学习的文本分类模型可以更加准确和及时地预测个体自杀风险,这显著减少了寻求帮助所需的时间、精力和金钱,为个人、家庭、社会都带来了极大的益处.因而本模型是一种识别文本自杀风险的有效方法.
虽然研究工作取得了一定的成果,但仍存在一些需要继续改进的地方.未来的研究可以考虑通过继续提升文本数据量,增强模型可靠性或者过滤与情绪表达无关的微博来达到使模型的识别效果得以提升的目的.
猜你喜欢
保定学院学报(2022年2期)2022-04-07
作文大王·低年级(2022年3期)2022-03-19
现代计算机(2021年33期)2022-01-21
中学生理科应试(2021年11期)2021-12-09
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
数学学习与研究(2018年15期)2018-11-12
小学生作文·小学低年级适用(2018年12期)2018-04-11
校园英语·下旬(2016年2期)2016-03-18
教学与管理(理论版)(2009年9期)2009-11-04
