
基于迁移学习的信用评分预测①
2020-11-24 05:46魏千程吴开超
计算机系统应用 2020年11期
魏千程,吴开超,刘 莹
1(中国科学院 计算机网络信息中心,北京 100190)
2(中国科学院大学,北京 100049)
对客户进行信用评分是金融机构开展业务的重要保证,是金融机构长期关注的核心问题.一个好的信用评分模型,能帮助金融机构对客户进行准确识别,继而规避可能发生的风险,获得更高的利润.
随着互联网时代的来临,互联网金融信贷业务也得到了广泛的发展.互联网金融机构在开展信贷业务的同时,也面临着一些客户由于主观恶意欺诈或者其他客观原因无法及时还款而带来的风险问题,因此对信贷业务进行风控建模是必不可少的.互联网金融机构通常会开展多项不同的信贷业务,其中一些新开展的业务由于缺少相应的客户数据而存在无法利用传统机器学习方法进行有效建模的 “冷启动” 问题.如何根据互联网金融机构已开展的拥有一定数量客户信息的信贷业务帮助新开展的业务进行建模是一个既有应用价值又值得广泛探究的领域.
本文针对互联网金融机构实际业务中存在的样本数量少以及模型 “冷启动” 问题,并根据实际数据情况(大量已有业务数据及少量新开展业务数据),提出了一种基于迁移学习的信用评分模型.首先引入Triplet-Loss表征学习[1]网络结构对数据进行重新编码,再加入领域适配模块[2]以进一步拉近两类业务数据在特征空间内的距离,而后通过fine-tune 技术实现了不同业务数据之间的知识迁移.相较于单独利用新开展业务数据进行建模,利用本文模型在信用评分预测效果上得到了一定的提升,在一定程度上解决了该问题.
1 相关工作
1.1 信用评分模型
信用评分模型经历了3 个阶段的发展:分别是定性分析、描述性统计分析以及数据挖掘分析[3].定性分析是早期的信用评分方法,而后基于描述性统计分析的方法被引入到信用评分中.随着计算机性能的提高和人工智能技术的发展,利用数据挖掘手段进行信用评分逐渐成为主流方法,通过对客户行为特征、资产能力以及其他属性信息进行深度挖掘,提炼出大量反应客户还款能力的特征,并将各种特征信息进行综合,从而对客户的信用表现进行预测.如贾中明等基于梯度提升决策树模型进行信用风险评测[4];都红雯等基于SVM 和Logistic 组合模型建立的风险评估模型[5].
1.2 迁移学习
迁移学习作为机器学习的一个研究方向已经得到了长足的发展,其基本思想是将已学习到的知识应用于新的任务当中,使得新任务在样本数量少的情况下能够获得更好的建模效果,正适用于本文提出的问题.迁移学习中的数据分为源领域数据以及目标领域数据,其中源领域数据即为已有大量样本的数据,目标领域数据为目标任务所用的数据.迁移学习的核心目标就是找到源领域数据和目标领域数据之间共通的知识特性,缩小两个领域数据的差距,利用源领域数据的知识提高目标领域数据在目标任务中的表现.
迁移学习方法可分为4 类:基于实例的迁移学习、基于特征的迁移学习、基于模型的迁移学习以及基于关系的迁移学习[6].基于实例的迁移学习通过权重重用,加大源领域数据中与目标领域数据相似的样本并将其填充到目标领域中,实现对目标领域数据扩展.基于特征的迁移学习是将源领域数据和目标领域数据的特征通过变换,映射到同一空间中,使它们更加相似.基于模型的迁移学习主要用于神经网络中,利用源领域数据先训练好一个模型,再将目标领域数据直接输入该模型.基于关系的迁移学习是利用不同领域数据的关系类比,不适用于本文提出的问题.
随着深度学习的方法的兴起,利用深度神经网络进行迁移学习的研究也越来越多的被研究人员所关注.来自康奈尔大学的Yosinski 等[7]率先进行了深度神经网络可迁移性的研究并证明了神经网络的可迁移性.深度迁移学习具有可以自动化提取表现力更好的特征等优势,可以实现基于特征和基于模型的迁移学习.
2 基于迁移学习的信用评分模型
本文的建模场景是借助样本数量多的信贷业务数据提升样本数量少的信贷业务的建模效果.Razavian等做过由卷积神经网络提取特征作为SVM 分类器输入的研究,显著提高了图像分类的效果[8].借鉴Razavian利用神经网络提取特征再输入分类器的研究思想,本实验整体结构也分为两部分,第1 部分神经网络实现特征提取,第2 部分为XGBoost 分类器.针对数据特性和任务需求,构建如图1所示信用评分模型.
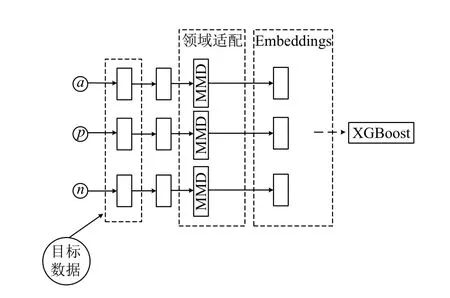
图1 信用评分模型
模型整个流程可分为Triplet-loss 表征学习、领域适配、模型fine-tune、分类器预测等步骤.其中表征学习、领域适配以及模型fine-tune 等深度学习方法实现了对样本的重新编码,之后将重新编码后样本数据输入XGBboost 进行分类.前3 个步骤的深度学习方法详细过程如下:模型通过Triplet-loss 实现对数据的表征学习,使数据特征变为更易于分类的编码形式;在领域适配步骤,首先计算源领域数据和目标领域数据的数据分布距离,再以该距离作为优化目标,不断缩小两类数据之间的分布距离;将源领域数据经过网络训练后得到的模型保存,通过fine-tune 技术(在此过程中,预训练模型的自适应层会被删除)实现将源领域数据中学习知识迁移到目标领域数据中.
2.1 Triplet-loss 表征学习
Triplet-loss 最早提出是为了解决人脸识别领域的问题,由谷歌公司的Schroff 等提出,是对样本进行新的编码表示的过程,目的是让数据中类别相同的样本在新的编码空间中距离更近,类别不同的样本在新的编码空间中距离更远.本文实验本质是一个二分类的任务,故选用Triplet-loss 使样本根据类别不同而以更易于分类的特征编码表示出来.
Triplet-loss 基于Triplet Network[9]的网络结构,并提出了新的损失函数.其网络结构是由3 个参数共享的网络模块组成,如图2所示.
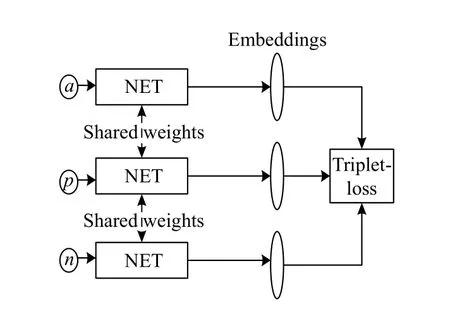
图2 Triplet-Loss 网络结构
Triplet-loss 原理如下:
(1)输入一个三元组
(2)三元组分别经过三个网络模块后得到各自的Embedding 向量表示.
(3)计算Triplet-loss 损失函数并进行反向传播.
Triplet-loss 公式为:
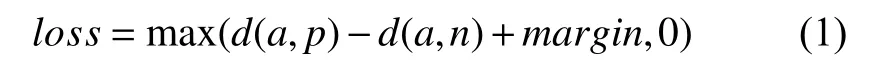
其中,loss为损失函数,d(a,p)代表目标样本a和正例样本p的之间距离,d(a,n)代表目标样本a和负例样本n之间的距离,margin是自定义超参数,代表两类距离的最小差值.
(4)通过最小化上述损失函数,实现d(a,p)=0以及d(a,n)>d(a,p)+margin.达到缩小同类样本特征距离的,加大不同类别样本特征距离的目的.
2.2 领域适配
领域适配即数据分布自适应,是最常用的一类迁移学习方法.其基本思想是,针对源域数据与目标域数据的数据概率分布不同问题,通过一些变换拉近两类数据分布的距离,使它们的数据分布趋于相同.在构建本文模型时,虽然两类数据存在业务上的联系,但是他们的数据分布并不相同,因此在对源领域数据进行训练时加入领域适配工作,将源领域数据的数据分布向目标领域数据拉近,以期使源领域数据面对目标领域数据有更好的知识表达,更好的发挥迁移学习的作用.
在本文的实现中,在Triplet 网络中间加入领域自适应计算,实现领域适配的目的.在加入自适应层之后,网络的损失函数为:

其中,loss为损失函数,Ds指源领域数据,ys指目标领域标签,Dt指目标领域数据,lc(Ds,ys)表示源领域数据的常规损失函数,即式(1)所示损失函数,lA(Ds,Dt)网络的自适应损失函数,如式(3)所示.后一部分是传统深度学习中所不具有的部分,表示源领域数据与目标领域数据的分布距离损失函数.λ是超参数,用来衡量两部分损失函数的权重比值.
深度网络自适应包括两个主要方面:一方面是上面提到的自适应层选取,决定网络的学习程度,加州大学伯克利分校的 Tzeng 实验[10]得出自适应层放在网络倒数第二层取得的效果最优;另一方面是采用什么样的自适应方法(度量准则),决定网络的泛化能力.
最大均值差异MMD 度量是由Borgwardt 等[11]提出的判断两类样本是否属于同一个总体分布的指标.它是一种核学习方法,度量在再生希尔伯特空间中两个分布的距离.MMD 是领域适配方法中常用的度量准则,被很多学者应用在迁移学习领域.本文也选用MMD方法作为领域适配过程的度量准则.训练源领域数据模型时,在Triplet-Loss 网络后面添加领域自适应层,计算源领域数据和目标领域数据之间数据分布的距离,并将该距离作为网络总损失函数的一部分,从而实现领域适配.两个随机变量的MMD 平方距离为:

其中,MMD2(X,Y)表示两个随机变量的MMD 平方距离,n1和n2分 别表示源领域数据集和目标领域数据集,xi和yj代表源领域数据集和目标领域数据集中的样本,φ(·)用于把原变量映射到再生和希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS),希尔伯特空间表示为H.
2.3 Fine-tune
Fine-tune 也是深度学习在迁移学习应用中的重要概念.具体方法是利用已经训练好的网络模型,针对自己的任务进行相应调整,从而实现在目标数据较少或者训练成本较高时,提高模型的效果或训练效率.本文实验中,先对源领域数据进行特征编码表示训练之后删除领域适配层网络并保持其他参数不变,之后采用fine-tune 技术,将目标领域数据输入到模型中,对模型进行调整.
图3所示为fine-tune 示意图,该网络结构分为输入层、隐藏层和输出层,其中fine-tune 过程是针对隐藏层网络的.具体原理如下:
(1)将已训练网络模型的参数作为目标任务的初始化参数.
(2)根据目标任务和数据,对已训练网络模型隐藏层从前往后择取适当的层数进行参数冻结保持不变.
(3)剩余部分隐藏层网络作为迁移层,用目标数据对迁移层参数重新训练.
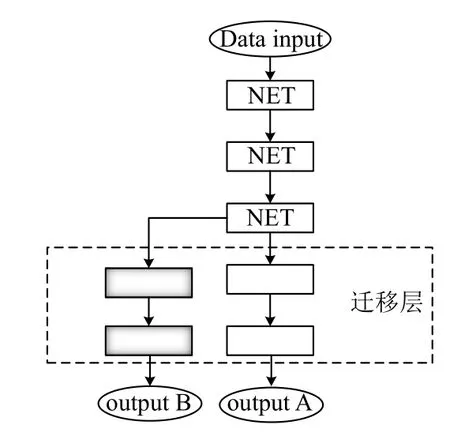
图3 Fine-tune 过程图
2.4 XGBoost 算法
XGBoost 是一种梯度提升决策树算法,它在残差拟合的过程中会生成多个弱分类器,再通过boosting 将多个弱分类器进行集成得到一个强分类器[12].XGBoost通过对损失函数二阶泰勒展开从而引入二阶导数信息的方法进行优化,以使得模型训练能够更快的得到收敛.XGBoost 额外引入正则项防止过拟合现象的出现.
XGBoost 具有模型可解释性、输入数据不变性、易于调参等特点,适用于表格数据.同时由于良好的内存优化、缓存机制等因素,XGBoost 的计算速度也非常快,有良好的性能.
3 实验与分析
3.1 实验数据及实验参数
本实验采用的数据集为前海征信 “好信杯” 大数据算法大赛公开的脱敏数据集.数据集分为两类,分别是4 万条信用贷A 数据和4 千条现金贷业务B 数据.A 数据是借款人凭借自己的信誉获得贷款批准发放,无需提供抵押物品.B 数据是发薪日贷款有额度小、周期短、无抵押、流程快、利率高等5 个特点.本实验就是利用业务A 和业务B 之间的关联性,通过将业务A 数据学习到相关知识并迁移到业务B 任务中,提高业务B 的信用评分模型水平.数据样本类别分布如表1所示.

表1 数据集样本分布表
两类数据集拥有过相同的字段,主要包括业务产品特征、用户是否具有某些网络行为以及用户自身属性等三类样本特征.其中产品特征与网络行为特征是类别特征,用户自身属性既有类别特征也有数值特征.
参数设置上,我们设置了具有4 个隐藏层的全连接神经网络,其中每层的维度分别为256、256、128和64,使用tanh 激活函数;为了抑制过拟合,加入了dropout 层,比率为0.5;调整MMD 损失权重的λ参数设置为0.2;XGBoost 部分,设置最大深度为5,迭代10 轮,树的数目为100.
3.2 评估指标
因实验数据集样本存在数据不平衡的问题,故选用F1 值作为模型性能的评价指标.F1 值兼顾精确率和召回率,同时让两个指标达到相对的最高值,是一个平衡的评价指标.F1 值的公式如下:

3.3 实验结果
首先进行消融实验来确定我们提出模型中的每个组件的重要性.
(1) Our:包含本模型所有组件.
(2) Our-t:Triplet-loss 起到对原始数据重新编码,拉近同类数据类内距离,拉大异类数据类间距离的作用.该模型验证Triplet-loss 表征学习对迁移性能的影响.作为对比实验,保持模型其他部分不变,将Triplet-loss部分网络结构替换为全连接层神经网络.
(3) Our-m:领域适配迁移学习思想的体现,起到缩小源领域数据与目标领域数据整体数据分布的作用.本实验验证领域适配对迁移性能的影响.作为对比实验,保持模型其他部分不变,单独去除适配层网络.
表2上面部分显示了该消融实验的结果.可以看到Our 方法比Our-t 方法的F1 值高2.2%,证明了Tripletloss 表征学习的有效性.同时Our 方法比Our-m 方法的F1 值高1.2%,证明了领域适配的有效性.
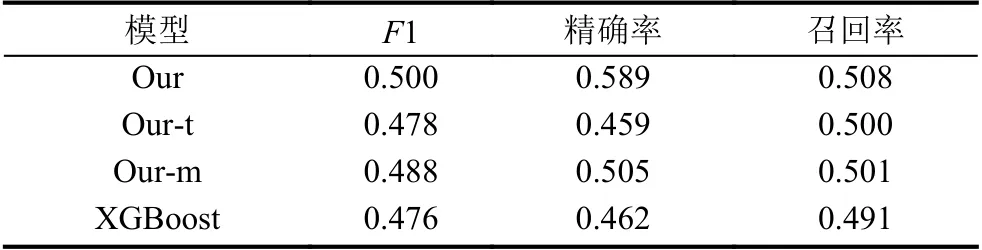
表2 实验结果F1 对照表
其次将提出的模型与传统非迁移学习建模基准方法[13]进行比较,直接将目标领域数据放入XGBoost 模型中做分类预测.
表2最后一行显示显示了比较的结果.我们可以看到Our 方法优于已有基准方法.具体来说,该模型比XGBoost 的F1 值提高了2.4%,证明了运用迁移学习的模型比未进行迁移学习的模型效果更好.
4 结语
本文针对互联网信贷中常见的模型 “冷启动” 问题进行了利用迁移学习去解决的相关探索,并提出了基于迁移学习的信用评分模型.我们的模型相较传统非迁移学习方法有一定的提升效果,为解决相关问题提供了一定帮助.在模型方面,我们应用了图像识别领域的Triplet-loss 表征学习,并验证了该方法的有效性;在预训练源领域数据时进行了领域适配工作,使源领域数据从数据分布上更接近目标领域数据,对该方法的有效性也进行了验证,实现了基于模型迁移和基于特征迁移两个方面的探索.
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年2期)2022-03-29
中国注册会计师(2021年9期)2021-10-14
中国药学药品知识仓库(2021年18期)2021-02-28
人大建设(2019年7期)2019-10-08
武术研究(2019年11期)2019-04-20
领导决策信息(2018年16期)2018-09-27
金桥(2018年9期)2018-09-25
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
