
基于深度学习的人手视觉追踪机器人①
2020-11-24 05:46林粤伟
计算机系统应用 2020年11期
林粤伟,牟 森
1(青岛科技大学 信息科学技术学院,青岛 266061)
2(海尔集团博士后工作站,青岛 266000)
智能机器人的开发是科学研究、大学生科技创新大赛的热点,基于计算机视觉的目标检测技术在智能小车、无人机、机械臂等领域得到了广泛应用.在企业界,零度智控公司开发了Dobby (多比)、大疆公司开发了Mavic 等,研发出了具有视觉人体追踪与拍摄功能的家用小四轴自拍无人机.在学术界,文献[1] 从检测、跟踪与识别三方面对基于计算机视觉的手势识别的发展现状进行了梳理与总结;文献[2]基于传统的机器学习方法-半监督学习和路威机器人平台实现了视觉追踪智能小车;文献[3]基于微软Kinect 平台完成了视觉追踪移动机器人控制系统的设计;文献[4]对服务机器人视觉追踪过程中的运动目标检测与跟踪算法进行研究并在ROS (Robot Operating System,机器人操作系统)机器人平台进行实现.
上述视觉追踪功能的实现大多采用传统的目标检测方法,基于图像特征和机器学习,且所采用平台成本相对较高.近年随着大数据与人工智能技术的兴起,利用深度学习直接将分类标记好的图像数据集输入深度卷积神经网络大大提升了图像分类、目标检测的精确度.国内外基于Faster R-CNN (Faster Region-Convolutional Neural Network,更快的区域卷积神经网络)、YOLO (You Only Look Once,一种single-stage 目标检测算法)、SSD (Single Shot multibox Detector,单步多框检测器)等模型的深度学习算法得到广泛应用,如文献[5]将改进的深度学习算法应用于中国手语识别.本文基于深度学习[6]技术,在低成本树莓派[7]平台上设计实现了视觉追踪智能机器人(小车),小车能够通过摄像头识别人手并自动追踪跟随人手.与现有研究的主要不同之处在于使用了更为经济的低成本树莓派作为机器人平台,并且在目标检测的算法上使用了基于TensorFlow[8]深度学习框架的SSD 模型,而不是基于传统的图像特征和机器学习算法.
1 关键技术
1.1 系统架构
如图1,整个系统分为机器人小车(下位机)和主控电脑(上位机)两部分.上位机基于深度学习卷积神经网络做出预测,下位机负责机器人的行进以及视频数据采集与传输,两者之间通过WiFi 通信.其中,小车主控板为开源的树莓派3 代B 开发板,CPU (ARM 芯片)主频1.2 GHz,运行有树莓派定制的嵌入式Linux操作系统,配以板载WiFi 模块、CSI 接口摄像头、底盘构成下位机部分.上位机操作运行事先训练好的SSD 模型[9].小车摄像头采集图像数据,将其通过WiFi传输给上位机,并作为SSD 模型的输入.SSD 模型如果从输入的图像中检测到人手,会得到人手在图像中的位置,据此决定小车的运动方向和距离(需要保持人手在图像中央),进而向小车发送控制命令,指示运动方向和距离.小车收到上位机发来的远程控制命令后,做出前进、转向等跟踪人手的动作.智能小车和主控电脑两端皆运行用Python[10]编写的脚本程序.
1.2 深度学习SSD 模型
SSD 模型全名为Single Shot multibox Detector[9],是一种基于深度学习的one stage (一次)目标检测模型.SSD 模型由一个基础网络(base network)的输出级后串行连接几种不同的辅助网络构成,如图2所示.不同于之前two stage 的Region CNN[11],SSD 模型是一个one stage 模型,即只需在一个网络中即可完成目标检测,效率更高.
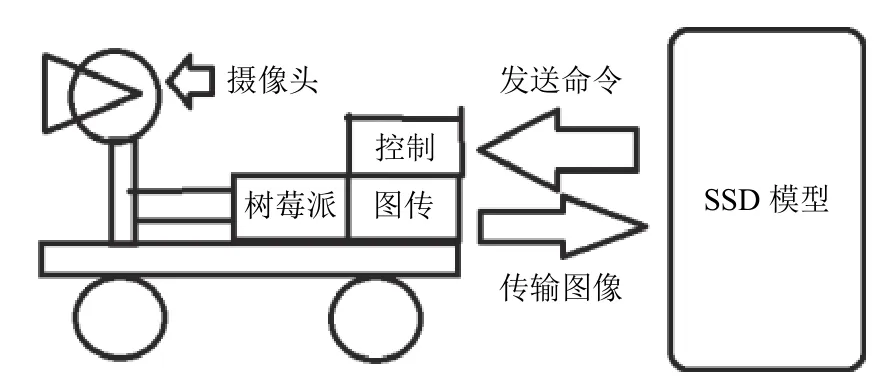
图1 智能机器人系统架构
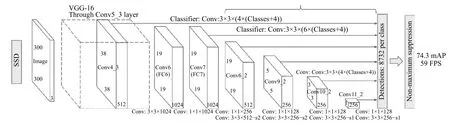
图2 SSD 模型
SSD 模型采用多尺度特征预测的方法得到多个不同尺寸的特征图[9].假设模型检测时采用m层特征图,则得到第k个特征图的默认框比例公式如式(1):
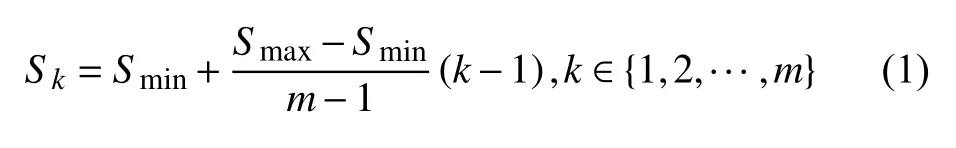
其中,Sk表示特征图上的默认框大小相对于输入原图的比例(scale).一般取Smin=0.2,Smax=0.9.m为特征图个数.
SSD 模型的损失函数定义为位置损失与置信度损失的加权和[9],如式(2)所示:
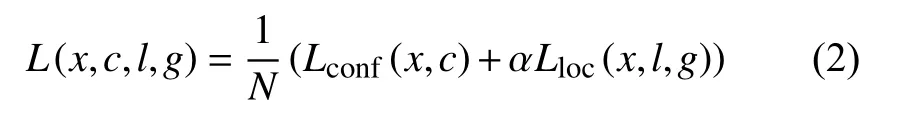
其中,N表示与真实物体框相匹配的默认框数量;c是预测框的置信度;l为预测框的位置信息;g是真实框的位置信息;α是一个权重参数,将它设为1;Lloc(x,l,g)位置损失是预测框与真实框的Smooth L1 损失函数;Lconf(x,c)是置信度损失,这里采用交叉熵损失函数.
1.3 TensorFlow 平台
使用谷歌TensorFlow 深度学习框架对SSD 模型进行训练.TensorFlow 能够将复杂的数据结构传输至人工智能神经网络中进行学习和预测,近年广泛应用于图像分类、机器翻译等领域.TensorFlow 有着强大的Python API 函数,而本文实现的智能小车和主控电脑端运行的程序皆为Python 脚本,可以方便的调用Python API 函数.
2 设计与实现
系统主程序软件流程如图3所示.上位机运行自行编写的Python 脚本作为主程序,接收下位机发来的图像,并将其输入到事先训练好的深度学习SSD 模型中,以检测人手目标.若检测到人手,则产生、发送控制命令至下位机.下位机运行两个自行编写的Python脚本,其中一个脚本基于开源的mjpg-streamer 软件采集、传输图像至上位机,另一个接收来自上位机的控制命令并通过GPIO 端口控制车轮运动.
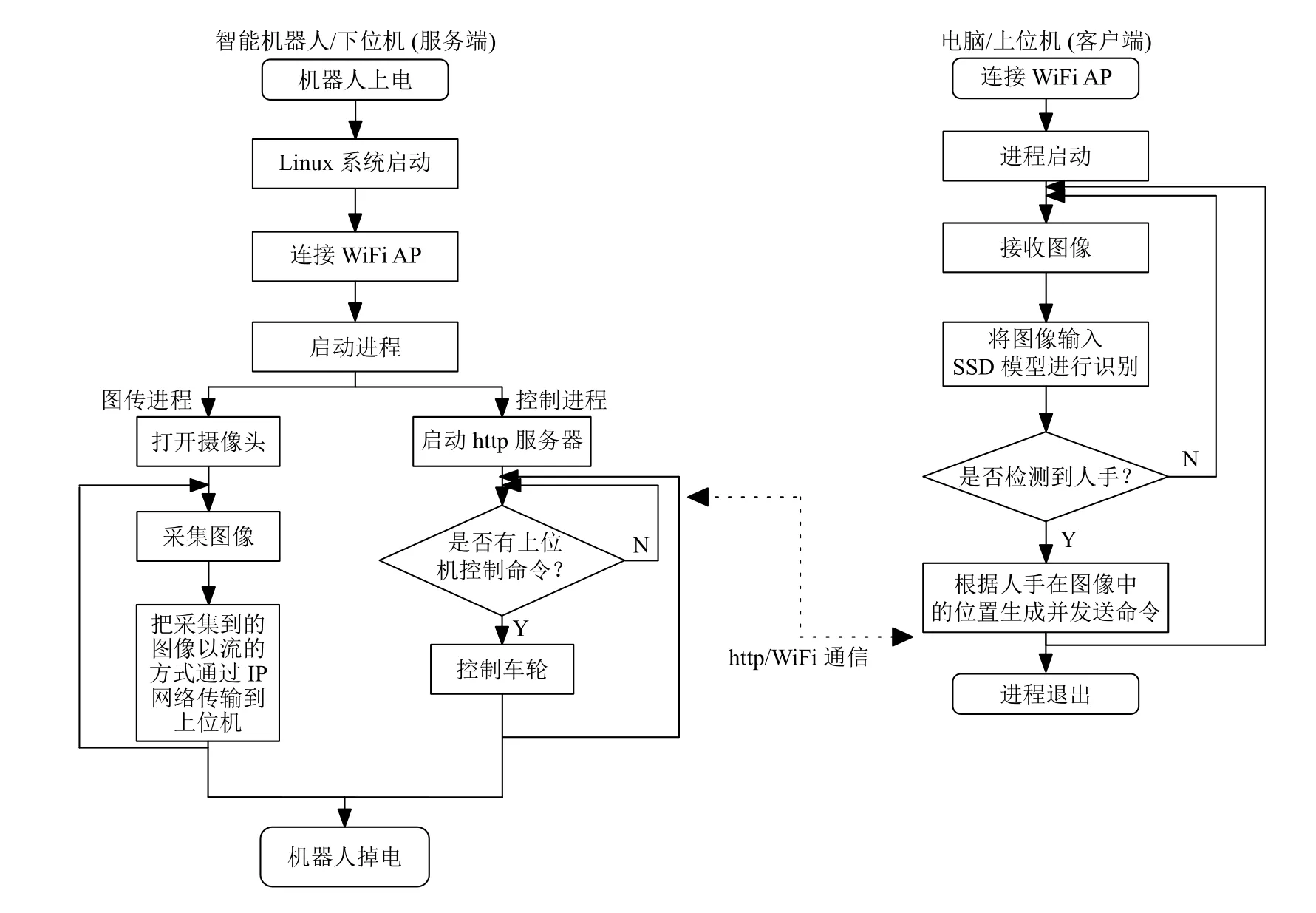
图3 主程序软件流程
2.1 深度学习SSD 模型训练
上位机电脑和CPU 型号为联想Thinkpad E540 酷睿i5 (第4 代),操作系统为Ubuntu 16.04 LTS 64 位,TensorFlow 版本为v1.4.0,采用TensorFlow Object Detection API 的SSD MobileNet V1 模型.训练数据直接使用了美国印第安纳大学计算机视觉实验室公开的EgoHands 数据集,该数据集是一个向外界开放下载的1.2 GB 的已经标注好的数据集,用谷歌眼镜采集第一视角下的人手图像数据,例如玩牌、下棋等场景下人手的姿态.首先对数据集进行数据整理,将其转换为TensorFlow 专有的TF Record 数据集格式文件,然后修改TensorFlow 目标检测训练配置文件ssd_mobilenet_v1_coco.config.训练全程在电脑上由通用CPU 运行,共运行26 小时.结束训练后将protobuf 格式的二进制文件(真正的SSD 模型)保存下来以便下文介绍的上位机Python 主程序调用.
2.2 上位机设计
考虑到小车回传视频的帧数比较高,且深度学习神经网络的计算也是一件耗时的任务,在上位机主程序(Python 脚本)中建立了两个队列,一个输入队列用来存储下位机传来的原始图像,一个输出队列用来存储经神经网络运算处理之后带有标注结果的图像.上位机通过开源软件OpenCV 的cv2.videoCapture 类用文件的方式读取视频信息.运行SSD 目标检测模型进行人手识别时,会得到目标的标注矩形框中心,当中心落到整幅图像的左侧并超出一定距离时,产生turnleft左转指令;当中心落到整幅图像右侧且超出一定距离的时,产生turnright 右转指令;当中心落到图像的上半部分并超过一定距离时,产生forward 前进指令.距离值默认设定为60 个像素,该参数可修改.预测小车行进方向功能的伪代码如算法1 所示.

算法1.上位机预测行进方向伪代码Require:距离阈值(默认为60 像素)while 全部程序就绪 do if 没有识别到目标:Continue;else if 识别到目标:if 识别到目标面积过大,目标离摄像头太近:Send(“stop”);else:if 目标中心 x<640/2-距离阈值:Send(“turnleft”);if 目标中心 x>640/2+距离阈值:Send(“turnright”);else:Send(“forward”);end while
2.3 下位机设计
下位机基于低成本树莓派平台实现,使用开源软件Bottle 部署了一个多线程的HTTP 服务器,该服务器接收上位机发出的HTTP POST 请求,提取其中的控制命令进行运动控制.使用开源软件mjpg-streamer 控制网络摄像头采集图像,并将图像数据以视频流的方式通过IP 网络传输到上位机客户端.
3 测试结果与评估
搭建局域网环境(也支持广域网),使上位机和下位机接入同一无线路由器.当摄像头采集到的画面右侧出现人手时,如图4所示的实时图像中,标注方框标记出了检测到的人手的位置,同时控制台输出turnright(右转)控制命令,此时小车向右侧做出移动.当屏幕中没有人手时,画面上面没有用彩色画出的区域,上位机的终端也不打印输出任何控制命令.
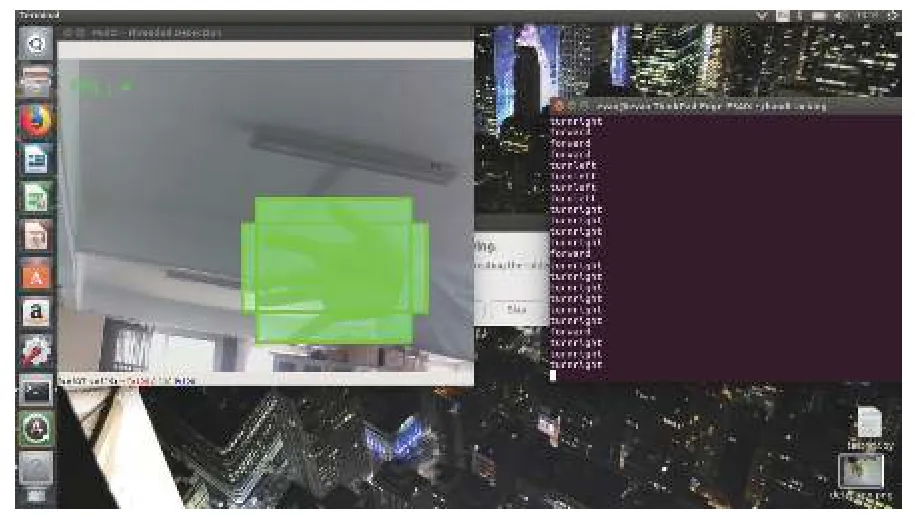
图4 人手目标检测功能测试结果
功能方面,针对人手在小车视野的不同位置情况进行所研制小车人手视觉追踪的功能测试.比如,当人手在小车前方且完整出现时,上位机应发出forward(前进)命令,进而小车收到该命令后向前行进.当小车视野里没有或只有部分人手时,应当无命令输出,小车原地不动.功能测试用例如表1所示,测试结果均为预期的正常结果.性能方面,所采用基于深度学习SSD模型的人手目标检测算法的准确性与实时性较好,算法的mAP (平均精准度) 为74%,检测速率40 fps 左右,可以较好的满足系统要求.

表1 人手视觉功能测试结果
小车(机器人平台)外观如图5所示.另外,由于动态视频文件无法在论文中展示,这里展示的是录制好的测试视频中2 个帧的截图,如图6所示,从小车的位置变化可以看出其可以追踪人手.

图5 机器人外观

图6 追踪人手
4 结论
本文利用深度学习SSD 目标检测模型对目标进行识别,将识别的结果用于修正智能小车机器人的行进路线,满足了智能机器人的视觉追踪功能需求.其特色主要在于采用了低成本树莓派,以及深度学习而非传统的神经网络识别算法,省去了设置特征的步骤.系统暂时只能用来识别人手,小车能够跟随人手移动,功能稳定性与性能良好.若要识别追踪其他物体,可以使用其他自己制作或第三方数据集对SSD 模型进行训练,以把网络的识别对象训练成拟追踪的目标类型.未来也可应用5G 通信模块,进行更为稳定低时延的视频传输与控制.
猜你喜欢
智族GQ(2019年9期)2019-10-28
幼儿教育·父母孩子版(2019年5期)2019-10-18
儿童故事画报(2019年5期)2019-05-26
文苑(2018年22期)2018-11-19
新少年(2017年1期)2017-03-15
汽车观察(2015年10期)2016-04-06
环球时报(2014-01-06)2014-01-06
现代电子技术(2009年6期)2009-05-31
中学科技(2008年7期)2008-08-14
