
基于变分模态分解和极限学习机的滚动轴承早期故障诊断
2020-11-25 01:55
矿山机械 2020年11期
河南科技大学机电工程学院 河南洛阳 471000
滚动轴承在中小型及特大型机械设备中均有重要应用,涉及领域广泛,因此,对滚动轴承制造过程中的质量管理及使用过程中的状态监测十分重要。滚动轴承早期产生微弱损伤之后,会产生与损伤部件相关联的低频周期振幅信号即时域脉冲[1],时域脉冲会引起滚动轴承各部件的高频固有振动并与其发生调制现象,但由于滚动轴承早期故障特征信号微弱极易被噪声信号淹没,因此对其进行有效提取十分重要。
变分模态分解因其非递归、能有效抑制噪声、自适应等特性而被广泛应用于轴承故障诊断之中。相较经验模态分解(EMD)、局域值分解(LMD)等时频算法而言,其具有完整的数学推论和试验验证,因此具有更高的可靠性和可分析性[2]。郑小霞等人[3]通过粒子群算法优化 VMD 的二次惩罚因子,并通过各分量相关系数求得模态个数K,完成了轴承振动特征信号的提取。李志农等人[4]通过将 VMD 算法应用到转子不同碰摩严重程度的故障数据分析试验中,成功区分了碰摩故障的严重程度。
自信息论之父香农提出了信息熵[5]的概念之后,在此基础之上许多学者提出了新的熵值理论,例如排列熵、近似熵、样本熵等,并得到了广泛应用。许多学者将熵理论和轴承故障诊断相结合并取得了有效进展。例如张建财等人[6]通过求得最佳变分模态分解分量,利用各分量构建多尺度排列熵特征向量,利用优化后的概率神经网络进行故障识别,使得轴承故障分辨率得到提升。
笔者通过分析 VMD 算法主要影响因素及分类指标,使用改进后的 AFSA 算法对 VMD 算法进行优化,并采用双层极限学习机进行故障分类。
1 VMD-ELM 故障诊断
滚动轴承振动数据通过 VMD 算法进行优化分解,可以在去除随机噪声的同时将振动信号分解为一系列调幅调频信号的叠加,而不同故障类型的滚动轴承振动信号 VMD 分解后具有不同的时域序列分布,样本熵、峭度和均方根等特征值能够从不同的角度衡量振动信号序列的复杂度。基于此,通过分析这 3 种特征值的分布情况,将其作为双层极限学习机的特征输入,进行轴承故障的分类。
VMD 算法的影响参数主要有分解个数K、二次惩罚因子α、噪声容限τ和收敛误差限ε。其具体实现步骤见文献[2]和文献[4]。分解个数和二次惩罚因子对于 VMD 分解的影响呈现不规律性,不同的信号序列会有不同的最优参数值且参数选取与信号本身无较大关联性[7-8],选取不当会造成模态混叠和过分解现象。相较K和α而言,τ和ε对分解影响较小,可采用文献[2]中的设定值。
AFSA 由李晓磊[9-10]提出,通过模拟鱼类的活动,依据鱼群周围的食物浓度和种群规模为其构建觅食、聚群、追尾、随机等行为特性,将其应用于寻优运算之中。针对 VMD 算法中K和α选取的不规律性,笔者对传统人工鱼群算法进行改进,提出了自适应 AFSA 算法,将其应用于滚动轴承 VMD 运算的寻优处理之中。采用自适应 AFSA 优化 VMD 并对滚动轴承振动数据进行有效分解之后,可以对其最优 IMF分量进行希尔伯特包络解调,将其与故障特征频率对应起来从而确定故障类型,但由于噪声干扰,往往会出现无法对应的现象,因此通过考察滚动轴承 VMD分解后最优分量的样本熵、峭度、均方根值等特征值,对其进行基于 ELM 的轴承故障识别,以消除噪声的干扰,提高故障识别率。
ELM 由 Huang G B 等人[11]提出,其输入层和隐含层的输入权重随机指定,相较反向传播算法(BP),大幅提升了运算速度。而隐含层和输出层的权重由公式推导而得,因此,在参数设定上也大幅简化。
采用西储大学轴承振动数据集,选取功率为 1.5 kW 的电动机,驱动端轴承型号为 SKF6205-2RS,采用电火花加工单点损伤,损伤直径为 0.177 8 mm,数据记录仪采样频率为 12 kHz,测试负载为 0 N。对 4种不同故障类型采用优化后的 AFSA 对其进行 VMD分解,统计 100 组最优 IMF 分量的样本熵、峭度、均方根值的均值。滚动轴承不同故障类型特征均值如表1 所列。
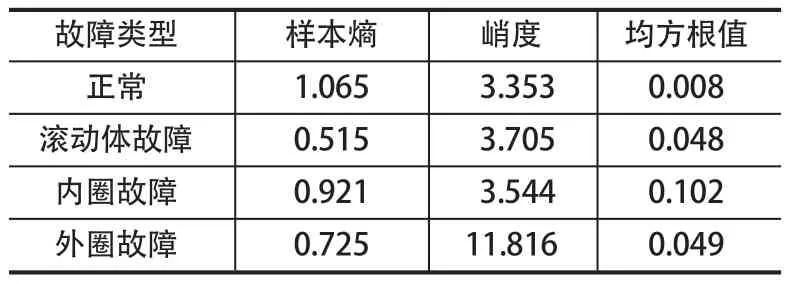
表1 滚动轴承不同故障类型特征均值Tab.1 Characteristic mean value of various faults of rolling bearing
样本熵是一种衡量时间序列复杂度的重要指标,且样本熵对数据长度依赖性小。样本熵值需要确定数据维数m和误差容限r,笔者选择推荐值m=2,r=0.2(std(x))[12]。通过试验发现,轴承原始数据样本熵值由于噪声干扰差别并不明显,但经过 VMD 分解有效提取故障信号波形后,熵值出现区分,因此样本熵可以反映轴承的故障特征。峭度是一种反映数据分布特性的统计学指标,它能够反映出数据分布相较正态分布曲线的误差值,值越大,说明故障程度越大。均方根值反映了一组数据的有效值,能够反映数据的重复冲击幅值大小。
由于峭度和均方根值受噪声和大幅冲击幅值影响较大,因此其只能用来识别轴承故障状态而不能识别故障类型,且通过观察100 组数据可以发现,正常峭度值82% 都在3±8% 范围内浮动,均方根值92% 都小于 0.01。因此,第1 层 ELM 用来区分故障轴承和正常轴承,构造[峭度、均方根值、样本熵值]特征向量进行训练,构造多维特征值提高其识别率。内圈故障样本熵值100 组数据会有波动,且会和外圈故障数据距离较近,因此选取包络熵倒数最大值前3 个 IMF分量,构造多维样本熵特征值,送入第2 层 ELM 进行训练,以减少内圈识别为外圈故障错误率。
综合前述内容,笔者提出的 VMD-ELM 滚动轴承故障诊断方法具体步骤如图1 所示。
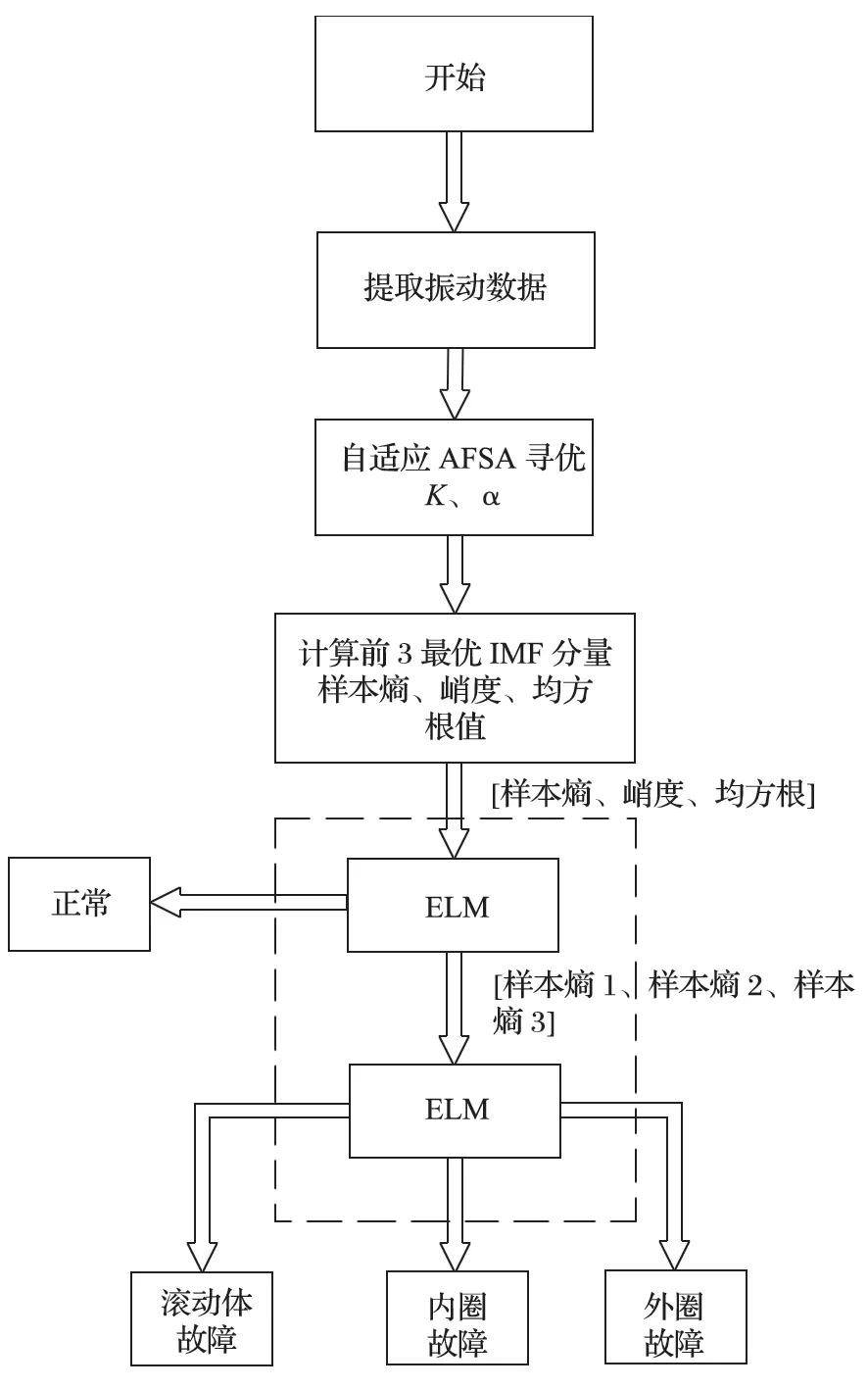
图1 滚动轴承故障识别流程Fig.1 Process flow of fault identification for rolling bearing
2 试验验证
2.1 自适应 AFSA 算法
传统 AFSA 算法通过初始化固定鱼群数目,让其固定执行觅食、聚群、追尾、随机行为进行寻优。在各种行为之中采用固定移动步长,其中种群规模决定了算法的寻优精度,但规模过大会导致寻优过程过长,影响运算速度。觅食行为提供了寻找局部最优解的能力,聚群行为和随机行为为鱼群提供了跳出局部最优解的途径,从而使算法寻优精度变高。
由于传统 AFSA 的移动步长采用固定值,使得移动速度固定,效率较低。笔者为步长增加比例因子β,β与迭代次数成比例,使人工鱼的移动随迭代次数而变化。在人工鱼的 4 种行为中,随机行为虽然能够增加鱼群的移动规模,但由于其随机性,使得系统并不稳定,因此去除此行为,并将初始人工鱼个数增加。
利用 AFSA 算法对 VMD 2 个参数进行寻优时,确定食物浓度函数尤为重要。包络熵对于衡量周期时间序列具有很重要的应用价值,其计算值与轴承振动信号的包络曲线有关,且包络熵值越小,则证明振动信号规律性越好,从而 VMD 分解效果也越好。因此以包络熵的倒数最大值作为食物浓度函数。其具体实现步骤如下。
(1)步骤1 固定 VMD 参数K=3,对二次惩罚因子α从1~3 000 进行寻优。初始化人工鱼群个数N=50,固定步长d=10,视野范围V=60,迭代次数R=50,拥挤度因子δ=0.6,设定步长函数

(2)步骤2 为每条人工鱼执行觅食、聚群、追尾行为。如果到达尝试次数仍未找到,则此人工鱼不再参与以后迭代觅食行为,仅执行聚群和追尾行为,并为其更新包络熵倒数即食物浓度函数值。
(3)步骤3 更新最优值至公告牌,判断是否达到迭代次数,如未达到重复步骤2。
(4)步骤4 将步骤1 的K值更改为 4~8,重复步骤1 至步骤3,并比较最优值至公告牌。
自适应人工鱼群分解算法相较原始鱼群算法而言,具有如下优点:①去除随机行为,增加了系统稳定性;②改变了移动步长,增加了运算后期跳出局部最优值能力。
改变人工鱼固定行为模式,加快收敛速度。以外圈K=5 为例,在二次惩罚因子取值 1~3 000 范围内,寻找包络熵倒数最大值。采用传统 AFSA 和自适应 AFSA 分别对滚动轴承 VMD 分解,其收敛曲线如图2 所示。
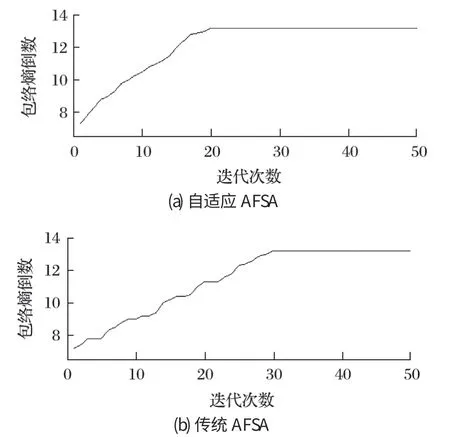
图2 传统 AFSA 和自适应 AFSA 运算对比Fig.2 Comparison of traditional AFSA and self-adaptive AFSA in calculation
由图2 可以发现,采用自适应 AFSA 算法,达到稳定值迭代次数变少,收敛速度变快。
为了对轴承故障类型进行判定以验证自适应AFSA 分解效果,对最优 IMF 分量进行 Hilbert 包络解调,从而寻找滚动轴承故障特征频率,以此确定轴承故障类型。采用 SKF6205-2RS 轴承外圈、内圈、滚动体故障振动数据,其故障信号分解如图3 所示。其分解个数K和二次惩罚因子α以及最优 IMF 分量包络熵倒数值如表2 所列。
由图3 及表2 可知,内圈故障类型在转频fr=30 Hz、故障特征频率一倍频ft=161.73 Hz、二倍频 2ft=323.46 Hz 处均出现明显谱峰;并且在故障特征频率一倍频处峰值最高,其他类故障类型均有此类谱峰出现。因此可以证明经过改进 AFSA 优化过后的 VMD分解是有效的。
2.2 VMD-ELM 滚动轴承故障诊断
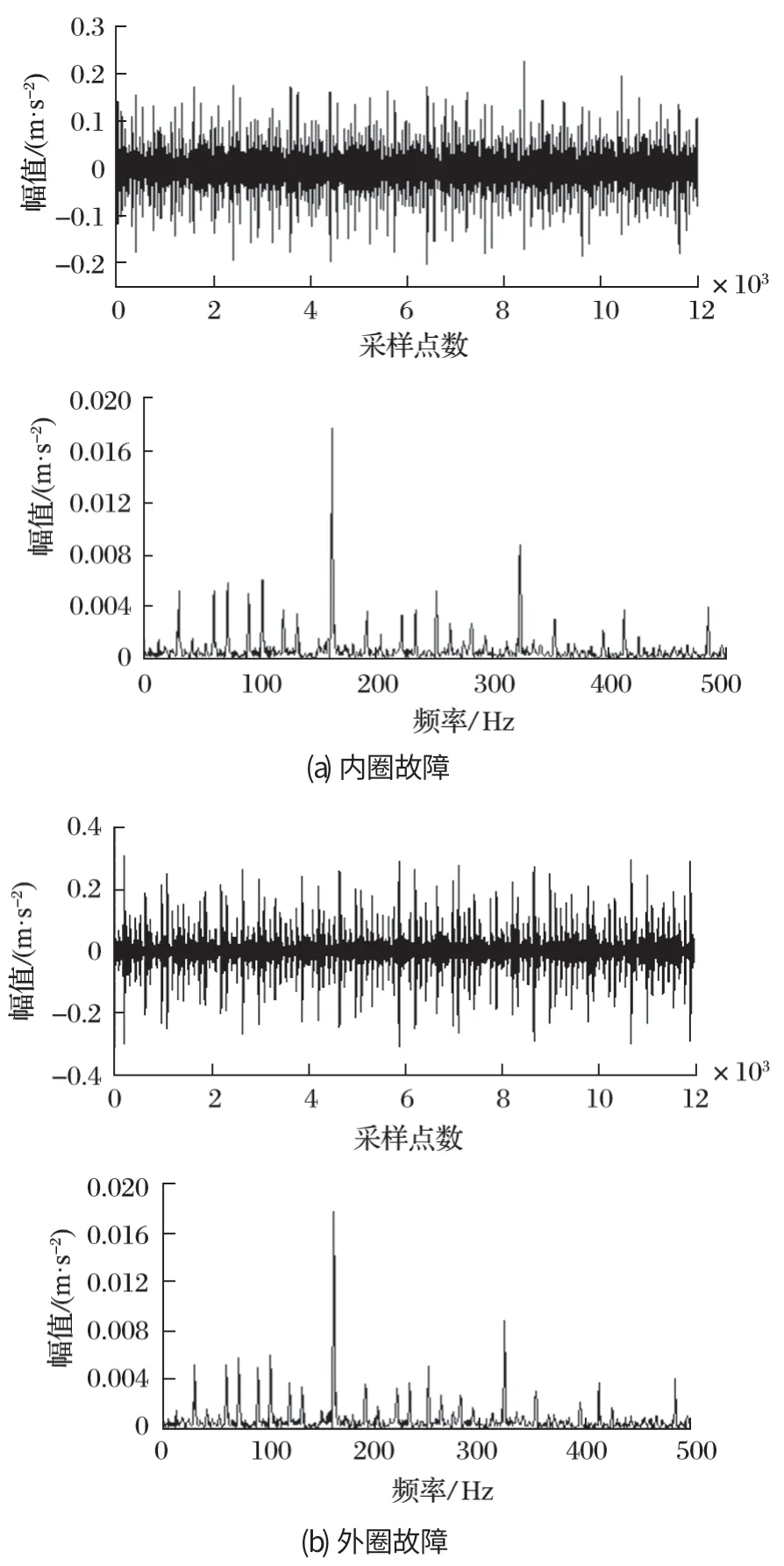
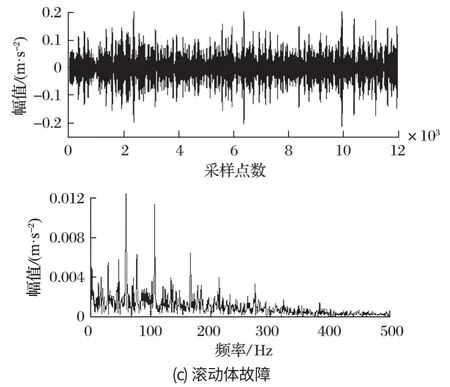
图3 参数优化 VMD 对滚动体早期故障信号分解Fig.3 Decomposition of early fault signals of rolling body with parameter optimization VMD
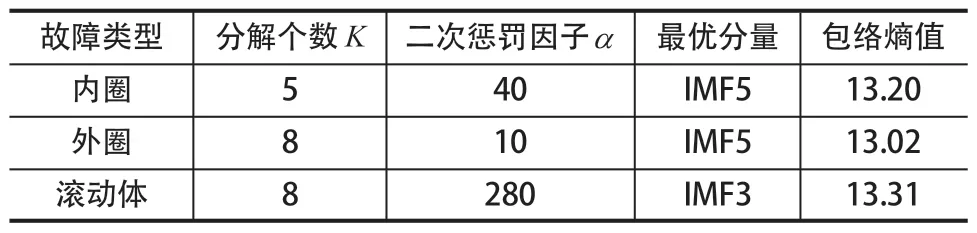
表2 优化 AFSA 寻优 VMD 各参数值Tab.2 Optimization of various parameters of VMD with optimized AFSA
采取西储大学振动数据集,选取内圈故障、外圈故障、滚动体故障、正常轴承 VMD 分解最优模态分量数据各 100 组,以轴承 3 圈数据为 1 组,对其按照图1 步骤进行测试。选取其中 60 组送入双层 ELM 进行训练,40 组进行测试,测试结果如图4 所示。
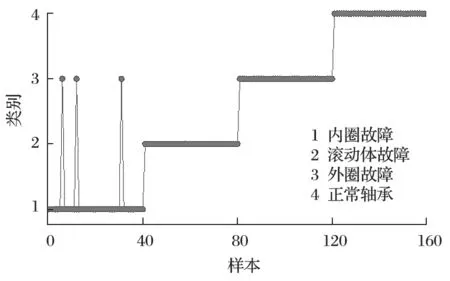
图4 双层 ELM 分类测试结果Fig.4 Classification test results with double-layer ELM
由图4 可以发现,其故障识别率达到了 98%,为对优化后的算法进行比较,对所用西储大学振动数据集的 100 组数据进行不同识别算法的分类试验,并统计滚动轴承每种状态和总体的正确识别率。其中单层 ELM 为将分解后的最优分量样本熵值直接用于分类;双层 ELM 先将正常轴承和故障轴承进行区分,再选取最优分量样本熵值进行二次分类。固定 VMD采用分解个数K=4,二次惩罚因子α=2 000 进行分解试验,其识别结果如表3 所列。
通过对比试验数据可以发现,相较 EMD、VMD算法而言,采用双层 ELM 相较单层正常轴承识别率大幅上升。总体识别率 EMD 上升了 15% 左右,VMD 上升了 10% 左右。说明采用双层 ELM 结构对于分离出正常和故障轴承是十分有效的。采用优化VMD+ 双层 ELM 算法,正常轴承和故障轴承识别率均接近 100%,虽然采用多维度样本熵内圈故障识别率有所下降,但滚动体故障识别率均上升了 40% 以上,总体识别率上升 10% 以上,对于整体分类效果更好。
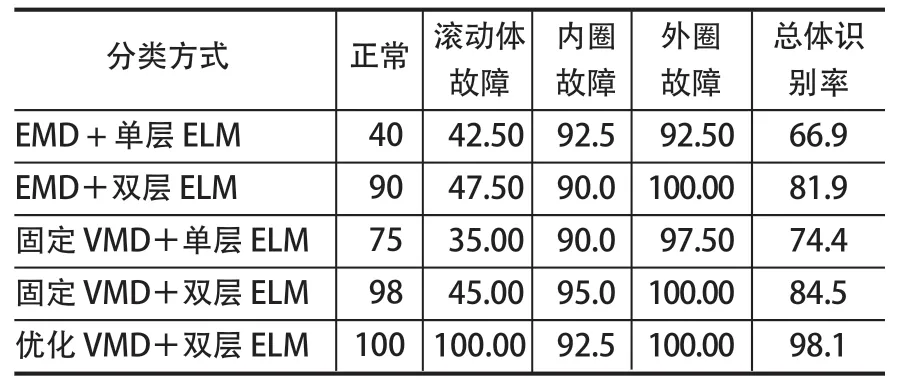
表3 振动数据集不同方式识别结果Tab.3 Recognition results of vibration data set with various ways %
3 结论
VMD 算法的分解效果与分解个数K和二次惩罚因子α密切相关。采用改进后的 AFSA 算法优化 VMD参数,有效提取轴承故障特征,通过西储大学振动数据集验证,其分解是有效的。由于对滚动轴承振动数据进行 VMD 分解之后,并不能完全去除噪声的影响,直接对其进行希尔伯特包络解调并不能保证每次均能进行有效识别。因此,在 VMD 分解基础之上,考察滚动轴承振动数据的 3 种故障特征值,构造双层ELM 并采用多维特征进行分类识别,以削弱噪声带来的影响,故障识别率得到有效提升。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
哈尔滨轴承(2022年1期)2022-05-23
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
读者·校园版(2020年19期)2020-09-16
当代陕西(2019年19期)2019-11-23
智族GQ(2019年9期)2019-10-28
中国听力语言康复科学杂志(2019年3期)2019-06-24
英美文学研究论丛(2018年1期)2018-08-16
中国高新技术企业(2017年5期)2017-05-05
