
基于语义分割的火车车厢位置检测研究
2020-11-25 09:51卢进南单德兴
工程设计学报 2020年5期
卢进南,单德兴
(辽宁工程技术大学机械工程学院,辽宁阜新123000)
煤炭定量装车站的溜槽是煤炭进入火车车厢的关键部件,溜槽落煤点与提升点的准确性决定了定量装车站的装车效果。目前,溜槽的落煤点与提升点是操作人员通过观察车厢与溜槽之间的相对位置来进行判断的。然而,仅依靠人工判断会影响准确性,从而极大地影响煤炭定量装车站的装车效果。
本文拟采用基于语义分割的车厢上边框图像分割方法来检测煤炭定量装车站装车过程中火车车厢的位置,为溜槽的落煤、提升以及完成装车提供准确的触发信号。现有的车厢上边框图像分割方法主要面临以下几个挑战:1)图像中车厢上边框边缘处细小特征较多且形状不规则;2)图像中不同类别之间尺寸差异较大;3)受光照因素影响,图像中车厢上边框颜色与背景颜色相似,导致轮廓不清晰;4)装车过程中存在较多粉尘干扰,使图像中存在较多噪声。这些挑战会对车厢上边框图像的分割产生一定影响,而图像分割的准确性与可靠性直接影响后续位置检测的准确性与可靠性。因此,在保证分割速度的前提下,使用合适的语义分割方法对提升车厢上边框图像的语义分割精度具有重要意义。
目前,语义分割方法[1-2]逐渐趋于成熟,许多语义分割网络的框架是基于编码器-解码器结构设计的,其主要区别在于不同框架的编码器与解码器使用了不同机制,但目的都是恢复编码器降低图像分辨率时丢失的信息。例如伯克利提出的FCN(fully convolutional networks,全卷积神经网络)[3]是在编码器中使用池化层来逐渐缩减输入数据的空间维度,在解码器中通过反卷积将特征图恢复到原图尺寸,并且在不同深度层之间采用跳级链接结构,以融合不同尺度的特征,实现像素级分类。在FCN的基础上,SegNet[4]、U-Net[5]等相继被提出,其语义分割效果均较好。此外,DeepLabv3+模型[6]通过将深度可分卷积应用于空洞空间卷积池化金字塔模块和编码器-解码器结构来执行语义分割任务,以获取更多的边界信息和特征信息,提升模型的语义分割效果。综上可知,融合多尺度特征信息、减少空间信息与细节信息的丢失以及通过特定处理手段细化分割边界是语义分割方法的主要研究思路。
在很多语义分割网络中,常通过提取和融合多尺度特征来提升分割性能。由于图像中类别尺度较多,不同尺寸的特征图包含的语义信息和空间信息往往有所区别,采用融合多尺度特征的方式可以获取全面的图像特征信息,尤其是在提升对细小特征分割能力时具有较好的效果。常用语义分割网络中低层特征的分辨率较高,包含较多位置和细节信息,但感受野较小且语义信息较弱;高层特征的语义信息较强,感受野较大,但分辨率较低,细节信息不丰富。FPN(feature pyramid networks,特征金字塔网络)[7]通过将高层特征和低层特征进行自上而下的侧边连接来获得语义信息与空间信息丰富的多尺度特征图,其在目标检测领域和图像分割领域均具有很好的应用效果。例如Kirillov等人[8-9]提出的全景分割(panoptic segmentation)网络是在FPN的基础上添加一个简单的分支,结果表明其语义分割精度较高。
在计算机视觉领域,一些学者[10-12]常利用注意力机制获取长距离信息,使得每一个像素都可以捕获全局信息,从而识别有用信息和消除无关信息或冗余信息的影响,有效提升语义分割网络的分割性能。例如Li等人[13]提出的期望最大化(expectation maximization,EM)注意力网络通过EM算法迭代得到一组紧凑的数据基,并在这组数据基上运行注意力机制,不仅极大地减少了注意力机制的运算量,而且有效提升了语义分割网络的区分能力和边界分割精度。
基于此,笔者拟采用多尺度特征与注意力机制相结合的方式对车厢上边框图像进行分割,提升其边界的语义分割效果,以准确检测火车车厢位置。首先,通过FPN和ResNet101(residual network,残差网络)[14]提取并融合多尺度特征图,并将得到的多尺度特征图进行拼接,得到一组分辨率较高、语义信息丰富的特征图;然后,将得到的特征图输入基于EM算法的注意力机制模块中,以过滤特征图中的噪声和保护前景对象的边缘信息;接着,将原始特征图与注意力机制模块输出的特征图进行融合,得到用于分类的特征图;最后,对最终的特征图进行分类预测以得到语义分割结果,并将其用于火车车厢位置检测。
1 火车车厢位置检测模型设计
1.1 总体框架
基于语义分割的火车车厢位置检测模型主要包括多尺度特征提取与融合模块、注意力机制模块、分类模块和位置检测模块四部分,其总体框架如图1所示。首先,在多尺度特征提取与融合模块中,以FPN和ResNet101作为主干网络,将FPN中P2至P5层的特征图进行自上而下的侧边连接,融合后的特征图包含丰富的尺度信息、语义信息和细节信息。然后,将多尺度特征提取与融合模块生成的具有较强语义信息与较高分辨率的特征图输入基于EM算法的注意力机制模块中,产生多张注意力图(attention maps)与多个数据基;基于注意力图与数据基重新估计得到高维的、带有全局性信息的特征图,通过过滤图像噪声和保留边缘信息来提高边界的语义分割精度。接着,将通过重新估计得到的特征图与原始特征图融合后输入分类模块中,进行像素级分类预测,得到最终的语义分割结果。最后,在位置检测模块中,对车厢上边框图像语义分割结果进行分析计算,以获取车厢位置信息。
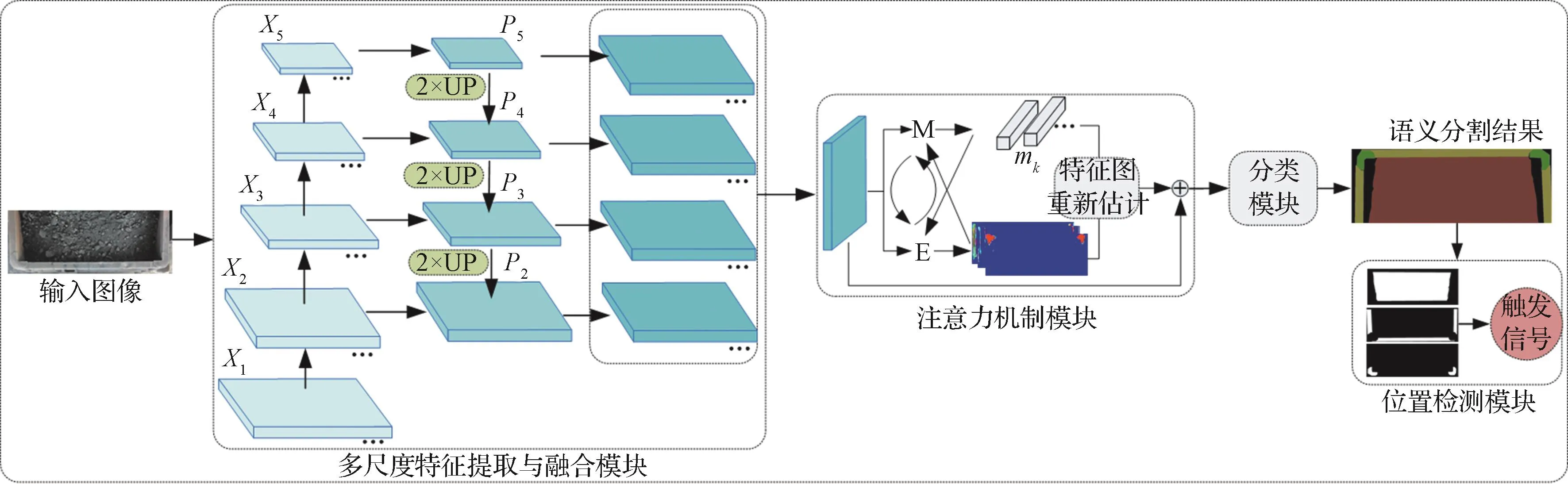
图1 基于语义分割的火车车厢位置检测模型总体框架Fig.1 Overall framework of railway carriage position detection model based on semantic segmentation
1.2 多尺度特征提取与融合模块
基于FPN构建多尺度特征提取与融合模块,其输入是像素为1 024×384的车厢上边框图像,共含车厢上边框(upper frame)、连接件(connector)、煤炭(coal)三种类别。
多尺度特征提取与融合模块的网络结构如图2所示。首先,对输入图像自下往上逐层进行特征提取,在ResNet101最后一层输出{X2,X3,X4,X5} ,输出图像的像素分别为原输入图像的1/4,1/8,1/16和1/32。然后,通过1×1卷积(Conv 1×1)来减少高层强语义特征图的通道数量(此处将特征通道数量统一为256),并上采样至前一层特征图的像素,并与前一层高分辨率的特征图进行融合后得到新的特征图,表示为{P2,P3,P4,P5} ,这既利用了高层特征图的强语义信息,又利用了低层特征图的高分辨率信息。接着,分别将P2至P5层的特征图上采样到原输入图像像素的1/4,并将通道数量减少至128。最后,将4个层级的特征图进行拼接得到Xp,其中每个上采样阶段均包括3×3卷积(Conv 3×3)、Group Norm、ReLU(激活函数)和2倍双线性内插值上采样。多尺度特征提取与融合模块通过融合高层的低分辨率、强语义信息特征图和低层的高分辨率、弱语义信息特征图,恢复了在编码过程中因降低分辨率而丢失的信息,提高了多尺度目标的语义分割精度。
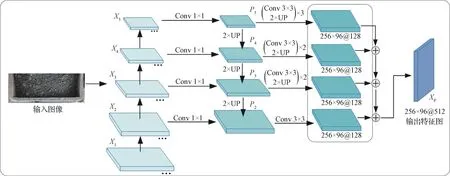
图2 多尺度特征提取与融合模块的网络结构Fig.2 Network structure of multi-scale feature extraction and fusion module
1.3 注意力机制模块
多尺度特征提取与融合模块输出的特征图虽分辨率较高、语义信息较强,但仍存在噪声和边界模糊等问题,且在图像融合过程中可能会出现一定的图像混叠现象。本文通过引入基于EM算法的注意力机制[14]来提升多尺度特征提取与融合模块输出的特征图的质量,起到过滤图像噪声和保留边缘信息的作用。
EM算法是一种常用的最大似然参数估计方法,可用于解决混合概率密度函数参数估计问题[15-18]。本文采用混合高斯模型作为EM算法学习的原型。基于EM算法的注意力机制由E步、M步组成,通过E步估计隐藏变量的期望值(即注意力图)[18],可表示为:

式中:aik表示第k个数据基对第i个像素的权责,共有K(K=32)个数据基;s(xi,mk)为点积模型,其中xi表示第i个像素对应的观测数据,mk表示第k个数据基(高斯参数)。
通过softmax函数来实现权责的迭代计算,其公式为:

式中:Xp表示输入注意力机制模块的特征图;λ表示超参数,控制at的分布;t表示迭代次数,t=1,2,…,T。
通过M步来更新数据基mk,其中初始数据基通过随机初始化产生,其余数据基根据分配的像素平均值进行更新[12],其公式为:

E步与M步交替执行,直至mk与αik收敛,在本文训练过程中仅需3步就可达到近似收敛效果[14]。图3为基于EM算法的注意力机制模块生成的注意力图。从标记的几幅注意力图中可以看出,不同的数据基会收敛到特定的语义类别,以保持类间差异和缩小类内差异,有助于提升车厢上边框语义分割模型对细小特征与类别边界的语义分割效果。
基于注意力图与数据基重新估计得到新的特征图,采用式(4)和式(5)将重新估计后得到的特征图与原始特征图进行融合,以得到噪声更少、边缘信息更加丰富的特征图。


式中:Xp'表示注意力机制模块重新估计后得到的特征图;aT表示T次迭代后最终的权责;mT表示T次迭代后的数据基;⊕表示逐像素点相加的融合方式;P表示注意力机制模块输出的特征图。
基于EM算法的注意力机制模块的FLOPs(floating-point operations per second,每秒浮点运算次数)仅相当于同样输入输出大小的3×3卷积的1/3,因此并不会增加过多的计算量[13]。由于车厢上边框图像包含的类别较少,为了减少冗余数据,注意力机制模块共生成32张注意力图和32个数据基。基于这些注意力图和数据基重新估计得到新的特征图,再将重新估计后得到的特征图通过1×1卷积与Batch-Norm(批量归一化)映射到原始特征图残差空间后进行融合,最终输出512张噪声更少、边缘信息更加丰富的特征图。
1.4 分类模块
分割图像的目的是为图像的每个像素分配一个离散标签,以将属于同一类别的像素定义为同一标签[18]。车厢上边框语义分割模型可将图像中的前景对象(车厢上边框、连接件、煤炭)与背景(地面、其他物体)进行分离,并识别出每个前景对象所属的类别。分类模块的网络结构如图4所示。

图4 分类模块的网络结构Fig.4 Network structure of classification module
在分类模块中,首先,使用3×3卷积操作将注意力机制模块输出的特征图的通道数量由512降至256,再使用1×1卷积将特征图的通道数量降至3;然后,通过4倍双线性内插值上采样操作,使得三通道特征图的像素与原输入图像一致;最后,对特征图中的每一像素位置进行通道维度最大化计算,最大化数值对应的是该像素的类别。
1.5 位置检测模块
通过人工经验判断车厢位置的方式来控制溜槽升降的效率低且准确性难以保证。本文利用位置检测模块来实现装车过程中溜槽触发时机控制,其检测原理如图5所示,当车厢位于溜槽落煤点、溜槽提升点和装车完成点三个位置时,溜槽会被触发。
位置检测模块通过对车厢上边框图像语义分割结果进行分析和计算,获取图像中各类别(车厢上边框、连接件、煤炭)的信息、车厢上边框与连接件的面积和及其占总面积的比例和车厢上边框外接矩形高度,用于车厢位置检测。其中,各类别的面积是根据像素计算的,应用到实际工程中时,通过拍摄距离与相机参数换算得到车厢上边框的尺寸信息[19]。

图5 位置检测模块的检测原理Fig.5 Detection principle of position detection moudle
在位置检测模块中,为区分颜色,将车厢上边框图像语义分割结果由RGB图像转换为HSV(hue,saturation,value,色调,饱和度,明度)图像,每一种颜色代表一种类别,即黄色代表车厢上边框(upper frame)、绿色代表连接件(connector)、红色代表煤炭(coal)、黑色代表背景(background)。车厢位置的判断流程如图6所示,其中判断依据为:1)车厢上边框外接矩形高度H不小于设定阈值Hs;2)车厢上边框与连接件的面积和At不小于设定阈值A;3)语义分割后的图像中有连接件;4)车厢上边框与连接件的面积和占总面积的比例Rt不小于设定阈值R。判断依据的优先级为:1)、2)、3)、4),当满足其中3个判断依据时,车厢位置检测模块判断出车厢到达的位置并将相应信息传输至溜槽控制器,作为溜槽控制触发信号。

图6 火车车厢位置判断流程Fig.6 Judgment process of railway carriage position
2 火车车厢位置检测试验与结果分析
2.1 车厢上边框图像数据集建立
在不改变图像类别的前提下,通过对原始图像进行上下与左右翻转、亮度随机变换和随机剪裁等来增加图像数据集的样本量。车厢上边框图像属于单图多类别图像,每张图像需要分割的类别有3个,分别为车厢上边框、连接件和煤炭。将连接件看作单独类别的原因是连接件均出现在车厢两端,可以作为位置检测的一个判断依据。车厢上边框图像的标注结果如图7(c)所示,图7(b)中掩码是指图像语义分割中像素级的类别标注,用于覆盖预测单个通道,表示图像中特定的类别区域。
对比图7(a)和图7(c)可知,车厢上边框图像中各类别的颜色与背景相似、不同类别间尺寸差异较大且细小特征较多,这给车厢上边框图像分割带来较大困难。

图7 车厢上边框图像的标注结果Fig.7 Annotation results of carriage upper frame image
2.2 语义分割模型训练
在Ubuntu18.0系统中,使用Nvidia GTX 1080Ti显卡对车厢上边框语义分割模型进行训练,设置迭代次数为40 000次,得到其损失函数值的变化曲线,如图8所示。从图8中可以看出,当训练迭代约25 000次时,车厢上边框语义分割模型的损失函数值趋于稳定;在前2 000次迭代过程中,模型的损失函数值减小较快,而后逐渐趋于平缓;当迭代30 000次时,模型的损失函数值基本收敛于0.3,在迭代35 000~40 000次时,模型的损失函数值稳定在0.2附近且基本保持不变。由此可知,当迭代40 000次后,车厢上边框语义分割模型完成训练。

图8 车厢上边框语义分割模型的损失函数值变化曲线Fig.8 Change curve of loss function value of semantic segmentation model of carriage upper frame
2.3 评估指标选择
在物体位置检测中,常用IoU(mean intersection over union,交并比)来表征真实像素区域和预测像素区域之间的相关度,IoU越高表示两区域的相关度越高。由于本文车厢上边框语义分割模型涉及3种类别,采用mIoU(mean intersection over union,均交并比)作为该模型的评估指标,其计算式为:

式中:C表示类别数量;puu表示类别u被正确预测的像素数量;puv(pvu)表示类别u(v)被预测为类别v(u)的像素数量。
同时,采用mPA(mean pixel accuracy,平均像素精度)作为车厢上边框语义分割模型的另一个评估指标,其计算式如下:

2.4 测试结果分析
在测试集上对FPN语义分割模型(FPN Semantic)和引入注意力机制的FPN语义分割模型(FPN Semantic+Attention)进行测试,2个语义分割模型在测试集上的测试效果如表1所示。从表1中可以看出,FPN Semantic+Attention的mIoU为81.21%,mPA为88.64%,相比于FPN Semantic提升了3.91%和7.44%。由此说明,FPN Semantic+Attention的分割性能比FPN Semantic的更好。

表1 不同语义分割模型的测试结果Table 1 Testresultsofdifferentsemantic segmentation models
基于不同语义分割模型的车厢上边框图像的语义分割测试结果如图9所示。从图9中可发现,2种语义分割模型对煤炭的分割效果都较好,这是因为煤炭的尺度大、形状比较规范,可以被准确分割。但在车厢上边框边界处与含细小特征位置处,2种语义分割模型的分割效果存在较大差异,FPN Semantic对车厢上边框转角处细小特征及连接件和车厢上边框边界的分割不准确,影响了车厢上边框与连接件的面积和以及车厢上边框外接矩形高度的计算精度,存在较大的误差;而FPN Semantic+Attention对车厢与连接件相邻位置的细小特征及车厢上边框边界的语义分割效果均较好,可准确计算车厢上边框与连接件的面积和以及车厢上边框外接矩形高度。但是,FPN Semantic+Attention的语义分割性能仍有待提升,由于车厢与连接件相邻位置的尺寸很小,该模型无法准确分类,但由于该部分面积占车厢上边框面积的比例较小,对车厢上边框外接矩形高度的计算没有直接影响。
2.5 现场试验分析
为了验证基于语义分割的火车车厢位置检测模型的有效性,在煤炭定量装车站工作现场进行试验。图像采集装置的安装情况如图10所示,采用130万像素的工业相机,其拍摄图像的有效像素为1 280×1 024,镜头与火车车厢上边框之间的垂直距离为3.15 m,使用相机的ROI(area of interest,兴趣区域)功能将采集图像的像素设为1 024×192。图像中每一个像素对应的实际物理尺寸与相机镜头参数、拍摄焦距以及镜头与车厢上边框间距离等有关,需要通过尺寸标定实验对其进行标定。以C70型火车车厢为实验对象,通过尺寸标定实验得到车厢上边框图像的每个像素对应的长度为3.125 mm,每一个像素块对应的面积为9.765 6 mm2。

图9 基于不同语义分割模型的车厢上边框图像语义分割测试结果Fig.9 Semantic segmentation test results of carriage upper frame image based on different semantic segmentation models

图10 图像采集装置安装情况Fig.10 Installation status of image acquisition device
根据煤炭定量装车站的装车工艺和操作经验,设定溜槽落煤点、溜槽提升点和装车完成点三个位置的判断依据所对应的阈值和条件,如表2所示。表中“√”表示语义分割后的图像中存在连接件。
利用训练好的车厢上边框语义分割模型对工业相机实时采集的原始车厢上边框图像进行语义分割。图11为对煤炭定量装车站装车现场C70型火车车厢上边框图像的语义分割结果。

表2 火车车厢位置判断依据设置Table 2 Judgment basis setting of railway carriage position

图11 C70型火车车厢上边框图像语义分割结果Fig.11 Semantic segmentation results of upper frame image of C70 railway carriage
由图11可知,本文构建的车厢上边框语义分割模型通过采用多尺度特征和引入注意力机制来提高对图像的语义分割精度,但仍存在一定误差,主要因素有2个:1)在语义分割过程中,模型不能对车厢上边框转角处细小特征进行正确归类;2)车厢上边框图像中的水泥地面与车厢上边框的颜色十分接近,导致图像边界模糊,在一定程度上影响了图像边界的语义分割精度。
利用基于语义分割的火车车厢位置检测模型连续对10节火车车厢进行位置检测。在煤炭定量装车站装车过程中,火车的行驶速度为0.2 m/s,车厢每行驶13.33 mm进行一次位置检测,即车厢位置检测速度为15次/s。当所得结果满足判断依据时,记录原始的车厢上边框图像与相应的语义分割结果。对满足条件的图像进行统计分析,并计算检测误差,结果如图12所示。由图12可知,车厢上边框与连接件的面积和的平均检测精度为87.47%,最大误差为75 234 mm2;车厢上边框外接矩形高度的平均检测精度为91.72%,最大误差为32 mm。对比分析煤炭定量装车站的装车工艺要求和试验结果可知:基于语义分割的火车车厢位置检测模型的检测精度较高且稳定性较强,检测得到的车厢上边框与连接件的面积和及车厢上边框外接矩形高度与实际值之间的误差在允许范围内。综上所述,所提出的火车车厢位置检测模型符合煤炭定量装车站对车厢位置检测精度的要求,可以为溜槽控制提供准确的触发信号。

图12 基于语义分割的火车车厢位置检测模型的检测误差Fig.12 Detection error of railway carriage position detection model based on semantic segmentation
3 结 论
本文针对火车车厢位置检测展开研究,结合FPN和基于EM算法的注意力机制,构建车厢上边框语义分割模型,首次将语义分割模型应用于火车车厢位置检测。针对车厢上边框图像的特点,采用FPN和ResNet101提取并融合多尺度特征图,之后将特征图输入到基于EM算法的注意力机制模块,消除特征图中的噪声和保留边缘信息,提高图像边界的语义分割精度。设计位置检测模块对语义分割结果进行分析,提取车厢上边框与连接件的面积和及其占总面积的比例和车厢上边框外接矩形高度,将其作为车厢位置信息,为煤炭定量装车站溜槽的升降提供准确的触发信号。结果表明,基于语义分割的火车车厢位置检测模型的检测精度满足煤炭定量装车站装车过程中对车厢位置的检测要求,具有较高的工程应用价值,可为实现煤炭定量装车系统的智能化提供参考。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
四川文学(2020年11期)2020-02-06
摄影之友(影像视觉)(2018年1期)2018-03-22
摄影之友(影像视觉)(2017年11期)2017-11-27
小雪花·成长指南(2016年9期)2016-10-12
中国社会历史评论(2016年2期)2016-06-27
中国照明(2016年6期)2016-06-15
现代语文(2016年21期)2016-05-25
长江学术(2016年4期)2016-03-11
专用汽车(2016年9期)2016-03-01
