
基于网络爬虫机制的文献资源可用性监测技术
2020-11-30 09:05闵磊
科技资讯 2020年27期
闵磊
摘 要:在信息化的时代背景下,对电子文献资源库的可用性进行监测,是科研及教学的一项重要保障。该文对基于网络爬虫机制的文献资源监测技术进行了研究,重点探讨了技术选型、HTML文档抓取以及DOM树解析等内容,并对文献资源特征和系统架构展开了分析。该技术以Web服务器访问端口为数据输入源,因而具有较强的平台无关性,能适应网络多样化的特点。
关键词:网络爬虫 电子资源 可用性监测 HTML解析
中图分类号:G647 文献标识码:A 文章编号:1672-3791(2020)09(c)-0005-03
Abstract: In the era of information technology, availability monitoring of electronic literature resources is important for scientific research and teaching. In this paper, we study the monitoring technology based on web crawler mechanism. We focus on technology selection, HTML document capturing, DOM parsing and analyzing the system architecture. This technology takes web services as data source, so it has strong platform independence and is adaptable for complex networks.
Key Words: Web crawler; Literature resources; Availability monitoring; HTML parser
文献是开展科研及教学活动的重要资源,是传播知识的关键载体。在信息技术高速发展的背景下,文献资源的电子化已成为一种必然的趋势。为了向广大科研人员和师生提供丰富的学术资源,各高校以及科研机构目前都在积极引进各类电子文献资源数据库。
为了保障电子文献资源的正常访问,管理人员需要对其进行定期监测。目前,常用的监测手段有手动访问、利用程序对服务器的连通性进行扫描的方式等。手动访问方式虽然准确但较为耗时,随着文献资源数据库数量的增多,这种人工监测的手段必将逐渐被淘汰。而通过程序扫描服务器连通性的方式,尽管具有较高效率,但它仅仅只能探测到资源库前端服务器的连通性,对后台资源的可用性和访问权限不能很好地检测。
针对当前电子文献资源可用性监测技术的不足,该文研究了基于网络爬虫机制的资源监测方法。该方法对电子文献资源库的可访问性、可下载性及访问权限的可用性等能进行高效检测。并且由于采用了爬虫机制,该方法还对资源服务器的平台和数据库类型不敏感,具有较强的通用性。
1 需求特点及技术选型
1.1 文献资源平台的多样性
开放性是学术交流的一个典型特征,文献资源库作为学术资源的载体同样也具有明显的开放性。在这种开放的环境下,各资源供应商就可能采用不同的技术来架构资源服务平臺。例如,在操作系统方面可采用Linux、Unix、Window等,在数据库方面可采用MySQL、MSSQL Serve、Oracle等,前端Web服务器可采用IIS、Tomcat、Nginx等。面对多样化的架构和技术,很难找到一种各平台均兼容的方式对其可用性进行检测。
1.2 访问故障的复杂性
从用户到文献资源的服务器端,中间需要经过用户主机、用户本地网络、互联网、资源服务器等诸多环节。在用户使用过程中,其中任何一处出现异常都可能造成电子资源访问的失败。对于管理员而言,不管这种故障发生在何处,都需要向用户提供技术支持。而这种故障的复杂性,使其管理工作变得极为繁琐。
1.3 技术选型
平台的多样性和访问故障的复杂性,是电子文献资源的固有特性,在对资源的可用性进行监测时必须对此加以考虑。对于B/S结构的资源服务,不管服务器端采用何种技术或何种平台,最终在用户层面都体现为能够访问的网页或下载的文件,而浏览器可以对此进行统一的处理。如果能对浏览器的行为进行模拟,那么就可以通过程序的手段按一致的方式对资源可用性进行监测。
目前模拟浏览器的方式有两类:一类是对浏览器控件进行调用,在操作层面模拟;另一类是通过网络爬虫的方式,在数据包层面进行模拟。考虑到不同资源平台对于浏览器控件兼容性的问题,该文采用网络爬虫的方式模拟浏览器进行监测。
此外,为了更为方便地对访问故障进行定位,监测程序的部署位置也较为重要。如果将其部署在本地普通客户端,那么仅能检测出是否发生了故障,而无法对故障的大致位置进行判断。因此,监测程序理想的部署位置应处于内外网络的交界处,此处的节点将网络路径分割为两段。如果用户对资源访问失败,但检测程序访问成功,那么就明显能排除外网和资源服务器的故障;而如果两者均访问失败,就需要考虑是否为外网或者资源服务器的问题了。
2 系统架构
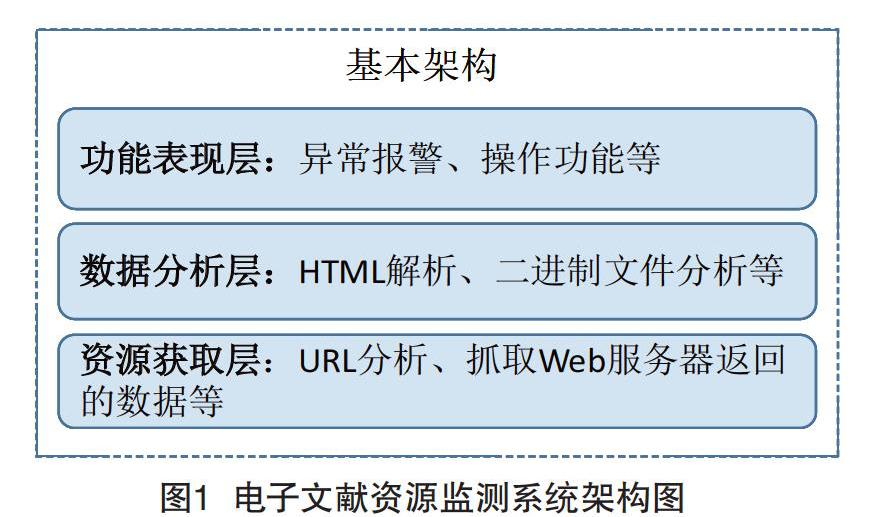
在利用网络爬虫对电子文献资源进行监测时,资源若被判断为可用,则必须具备两个条件:第一,爬虫程序要能与服务器取得链接;第二,爬虫程序从服务器抓取的数据需要符合正确的模式。这种模式既要满足Web文档的有效形式,也必须满足应用层面的权限要求,如IP访问许可等。此外,对于检测出的异常结果和一些常规的操作,也需要设计相应的功能。因此,系统从逻辑上可以分为3个层次:资源获取层、数据分析层和功能表现层,如图1所示。
(1)资源获取层。与服务器建立链接,分析URL地址,以及通过HTTP的Response来获取Web服务返回的HTML及二进制数据。若未能与服务器成功建立链接,则直接判断访问失败。若服务器的HTTP返回码为404或405等未成功代码,也判断访问失败。需要注意的是,对于资源访问权限的检测既可能直接通过403返回码来表示,也可能通过正常的页面提示来表示。如果是前者,则在该层中判断对资源无访问权限,反之则需要在数据分析层通过HTML解析判断。
(2)数据分析层。进行HTML解析,判断返回的文档是否与正常权限下的预期文档一致,或者进行二进制分析,对下载的文件与预存档文件进行二进制对比。如果从资源获取层得到的数据是HTML文档,则将其转换为DOM树后进行内容分析,此时采用XPath抓取一段特征码进行文本对比。如果得到的是PDF、DOC等文件,则与预先存档的文件进行二进制对比。
(3)功能表现层。将资源获取层和数据分析层判断的异常结果进行汇总,并通过报警窗口或电子邮件的方式进行异常报警。此外,此层中还包含参数设置、功能操作等常用功能。
3 关键技术分析
该文所述功能采用C#语言编码实现,使用HtmlAgilityPack库进行HTML解析。此外在利用爬虫功能抓取数据时,为提高效率并避免程序假死,使用了多线程技术。该系统所涉及的主要技术如下。
3.1 基于HTTP的爬虫技术
在进行数据抓取时,采用System.Net.HttpWebRequest类的静态Create方法来创建HttpWebRequest对象,创建该对象时传入URL地址作为参数。然后通过该对象的GetResponse方法从远端服务器中得到传回的数据,该数据包含于HttpWebResponse对象中。
对于HttpWebRequest对象,需要传入相应的参数。包括模仿浏览器配置的UserAgent、设置数据请求方式的Method、设置超时时长的Timeout、是否允许自动重定向的AllowAutoRedirect等。
如果需要对服务器提交表格数据,则Method属性需要设置为Post。此时通过HttpWebRequest.GetRequestStream()创建一个数据流,并将数据流形式的Post参数写入该流。对于其他仅是请求返回数据的情况,则设置Method参数为Get。
需要注意的是,有些网站在打开页面时,涉及到一系列HTTP请求,这些请求可能存在登录和功能现实相分离的现象。此时就需要对登录时建立的Cookie数据进行保留,并将其传入所有的后续HTTP请求参数中,该参数通过Http Web Request.Cookie Container进行填充。
3.2 HTML解析技术
以HTTP爬虫方式得到的文档数据为字符串形式的HTML,为了能方便地对其进行处理,需要将其转换为具有逻辑结构的DOM树并进行解析,该文使用HtmlAgilityPack库实现此功能。HtmlAgilityPack是一个基于.net的第三方解析库,可以无缝兼容C#。
HtmlAgilityPack利用该库中的HtmlDocument.LoadHtml()加载字符串形式的HTML,并将其转换为DOM树。为了能对HTML中的某一段特征码进行对比分析,需要快速定位该特征码所在路径。此功能通过HtmlDocument的DocumentNode.SelectSingleNode(_xpath)来实现,方法的参数xPath是用于定位的HTML结构路径。
3.3 多线程技术
由于网络爬取操作较为耗时,为了提高监控效率并避免程序出现假死现象,需要采用多线程技术。在该系统中,设置一个队列用于存储需要爬取资源的任务。系统使用System.Threading.Thread来构建线程对象,对于每个线程对象,依次从队列中取出任务来执行爬取操作。为了避免出现操作冲突,需要将队列的进队和出队代码设置临界区,这里使用lock锁来实现该功能。
4 结语
电子文献是高校开展科研和教学活动的重要保障,对其资源库的可用性进行监控具有明显的现实意义。该文利用网络爬虫的原理,对电子文献资源库可用性监控的相关技术展开了研究。该类监控技术具有良好的平台无关性,可适用于各类B/S结构的资源服务器。我们相信,随着互联网及文献信息化的发展,电子文献资源监测技术将会发挥出更大的作用。
参考文献
[1] 王思敏,尹伊秋,宣静雯,等.基于网络爬虫技术的数字资源检测软件的设计与实现[J].现代电子技术,2019,42(10):132-135.
[2] 何征强.电子资源使用监测系统实例研究[J].大学图书情报学刊,2017,35(2):105-108.
[3] 李海燕,宓永迪.公共图书馆数字资源故障自动检测系统设计与实现——以浙江图书馆为例[J].内蒙古科技与经济,2015(18):62-63,66.
[4] 鲁丰玲.基于Scrapy的招聘信息爬虫设计与实现[J].科技资讯,2019,17(20):7-10.
[5] 侯洁茹,吕继续.基于Python的天猫商品爬蟲技术[J].科技资讯,2019,17(32):10,12.
[6] 单文远.分布式主题网络爬虫研究与设计[D].电子科技大学,2020.
猜你喜欢
中国新通信(2016年21期)2017-01-06
青年时代(2016年21期)2017-01-04
现代情报(2016年10期)2016-12-15
科教导刊(2016年29期)2016-12-12
科技视界(2016年20期)2016-09-29
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技视界(2016年11期)2016-05-23
电脑知识与技术(2016年7期)2016-05-19
