
基于卷积神经网络和光谱特征的孵前种鸭蛋受精信息无损检测
2020-12-04 13:25李庆旭王巧华马美湖
光谱学与光谱分析 2020年12期
李庆旭,王巧华,2*,顾 伟,高 升,马美湖
1. 华中农业大学工学院,湖北 武汉 430070 2. 农业部长江中下游农业装备重点实验室,湖北 武汉 430070 3. 国家蛋品加工技术研发分中心 ,湖北 武汉 430070
引 言
我国是鸭蛋与鸭肉生产和消费大国,为此每年需要孵化大量雏鸭才能满足鸭肉和鸭蛋生产需要。 由于无精蛋无法孵化出雏鸭,随着孵化时间推移会变质且对受精蛋会造成污染,因此尽可能早地剔除出无精蛋,可以有效地减少资源的浪费,提高鸭蛋孵化业和种鸭养殖业的经济效益。 目前国内鸭蛋孵化行业去除无精蛋的方法依然是在种鸭蛋孵化7天以后进行人工照蛋,效率低下且挑选出的无精蛋已失去食用价值,造成资源的巨大浪费。 在孵化之前鉴别出来无精蛋是目前禽蛋孵化产业需要解决的老大难问题,因此研究入孵前种鸭蛋的受精信息无损检测技术,将会拥有广阔的应用空间。
针对禽蛋孵化,国内外学者做了相关的研究,研究人员尝试使用了生物电[1]、机器视觉[2]、光谱、高光谱成像[3]等技术手段实现了禽蛋入孵前及孵化早期受精信息的无损判别。 但大都针对的是鸡蛋孵化,针对鸭蛋孵化的研究很少,由于种鸭蛋品种差异大、表面脏污多、蛋壳厚度差异大,故与种鸡蛋相比种鸭蛋的检测难度更大。 张伟等[4]提出利用机器视觉与敲击振动相结合的方法实现了对孵化5 d的种鸭蛋受精信息检测,这种使用敲击振动装置部署到实际生产难度较大。 Dong等[5]提出了利用可见-近红外光谱技术初步实现了对入孵前种鸭蛋受精信息的无损判别,但是要求种鸭蛋颜色和尺寸一致,此研究证明了运用可见-近红外光谱技术对入孵前种鸭蛋受精信息无损检测的可行性,但还不适于实际应用。
可见-近红外光谱由有机物的含氢基团振动的合频与倍频组成,谱图中含有大量能够反映物质差异的信息,具有快速、无损、简单的特点,目前被广泛应用于农产品无损检测。 文献[6]研究结果表明可见-近红外光谱可以穿透禽蛋的表面,并将禽蛋的内部物质信息在光谱图中反映出来。 深度学习中的卷积神经网络(convolutional neural networks,CNN)目前被广泛应用于农产品分类检测中,卷积神经网络含有更多的隐含层,通过卷积和非线性变换操作自动提取数据本身的大量特征可用于拟合复杂模型[7]。 近年有学者利用光谱信息与卷积神经网络相结合检测夏威夷果、烟叶、花椒等,但是利用两者结合起来检测禽蛋尚未有文献记载。 本文利用可见-近红外透射光谱技术与深度学习相结合对入孵前种鸭蛋受精信息进行无损检测,探索一种更符合实际生产的区分入孵前无精鸭蛋和受精鸭蛋的鉴别技术。
1 实验部分
1.1 仪器与材料
实验样品为499枚缙云麻鸭种蛋,均为新鲜生产的种蛋。 采购于湖北神丹种鸭场。 对种鸭蛋表面使用酒精进行清理消毒并编号。
种鸭蛋光谱采集系统如图1,由Maya2000Pro光纤光谱仪、暗箱、光源、光纤探头等组成。 光谱仪能够采集的波长范围在200~1 100 nm之间,光谱仪的最小采样间隔为0.5 nm,光源为100 W卤素灯。 另外还有智能孵化器1台。
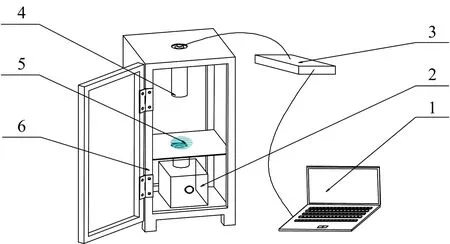
图1 光谱采集系统1: 计算机; 2: 光源; 3: Maya2000Pro光纤光谱仪; 4: 光纤探头; 5: 鸭蛋; 6: 暗箱Fig.1 Spectrum acquisition system1: Computer; 2: Light source; 3: Maya2000Pro fiber optic spectrometer; 4: Fiber optic probe; 5: Duck eggs; 6: Dark box
1.2 方法
1.2.1 光谱采集
使用可见-近红外透射光谱采集系统对清洗消毒后的入孵前种鸭蛋进行透射光谱采集,采集光谱时将种蛋竖直放置,大头向上。 考虑到模型后续将部署到生产中,将光谱仪的采集积分时间设置为100 ms,扫描次数设置为3。
1.2.2 受精结果的人工判别
将智能孵化箱预热1 h,把采集数据后的499枚种蛋同时放入智能孵化箱中。 设置智能孵化箱模式为“鸭”,智能孵化箱会根据模式自动调节适用于鸭蛋孵化的最佳温湿度。 鸭蛋入孵后7 d对其进行破壳处理,蛋壳含有血丝为受精蛋,得到准确的受精结果。
1.3 数据处理与建模
1.3.1 样本集划分
为了避免样本分布不均匀,利用了Kennard-Stone法对样本集进行划分,将变量空间中的相对欧式距离差异较大的样本划入训练集,其余样本划入测试集[8]。 为了更好地验证模型的泛化能力,从测试集样本中再划出一个验证集。 本实验共采集499个入孵前种鸭蛋样本,按照7∶2∶1的比例对应划分出训练集、测试集和验证集样本。 其中训练集样本数量为350个(无精197个,受精153个),测试集样本数量为100个(受精54个,无精46个),验证集样本数量为49个(受精27个,无精22个)。
1.3.2 谱区选择与光谱预处理
谱区选择对光谱信息分析十分重要,若选取范围较大会带入大量噪声和冗余信息导致后续建模出现过拟合现象,反之选取范围较小会丢失大量信息导致后续建模出现欠拟合现象。 采集得到的入孵前种鸭蛋原始谱图如图2所示,由于谱图两端的噪音较大无法有效地反映出种鸭蛋内部真实的物质信息,故截取400~1 000 nm范围内的透射光谱信息用于后续的分析与处理,选择的谱区范围如图3所示。
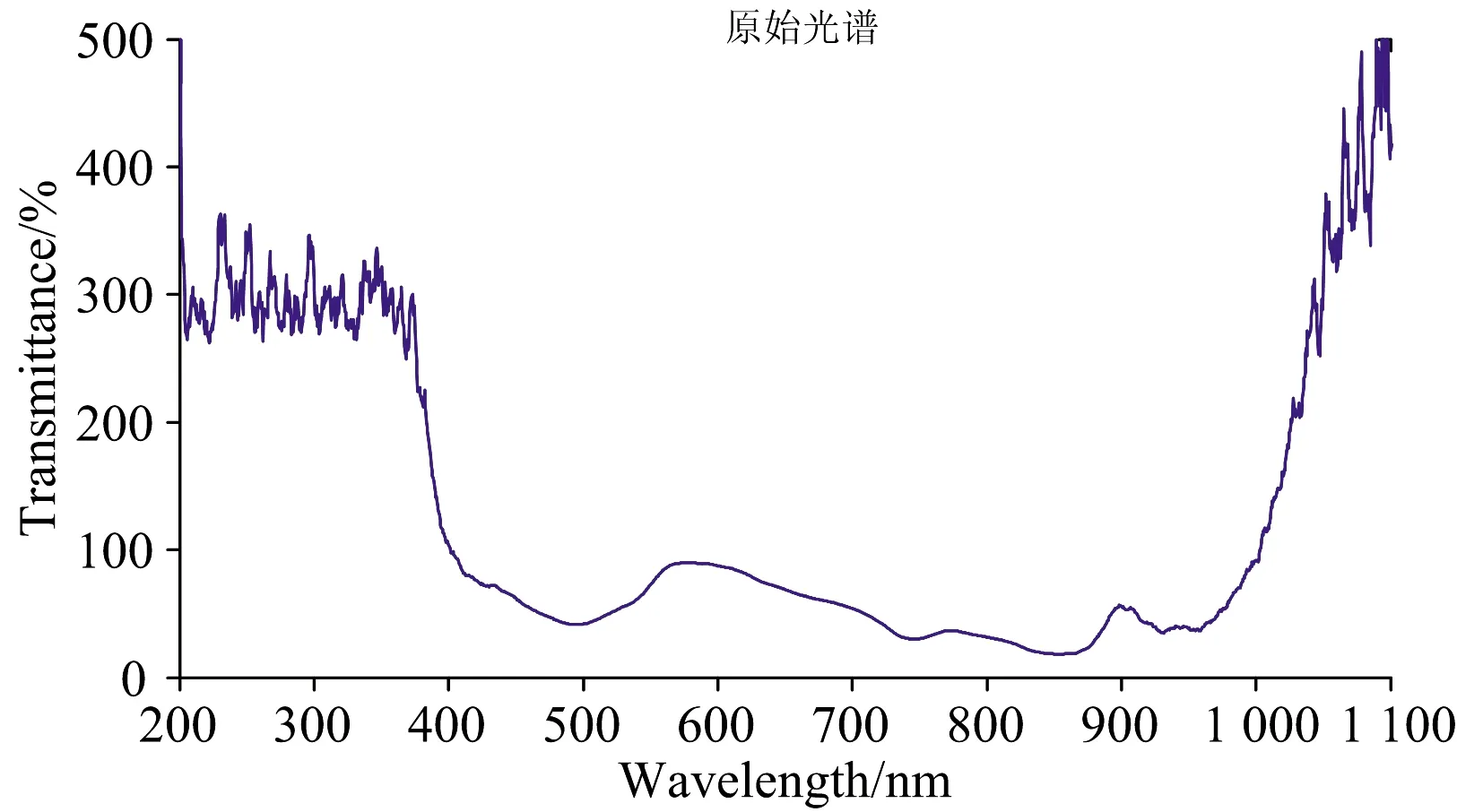
图2 入孵前种鸭蛋原始光谱图Fig.2 Original spectrum of duck eggs before hachted

图3 入孵前种鸭蛋400~1 000 nm光谱图Fig.3 400~1 000 nm spectrum of duck eggs before hachted
由于仪器操作、温度变化和杂散光的原因会使采集得到的原始光谱数据引入噪声与无关信息,选取的400~1 000 nm范围内的透射原始光谱依然含有较为明显的噪声(光谱信号中含有杂波)。 为此,采用SG卷积平滑处理对截取后的种鸭蛋光谱进行预处理。 经反复尝试,本实验使用窗口宽度为9的2阶微分进行平滑处理。 平滑后的曲线如图4所示,可以看出SG平滑处理后消除了杂波干扰,光谱曲线变得更加平滑[12]。

图4 入孵前种鸭蛋SG平滑后光谱图Fig.4 SG smoothed spectrum of duck eggs before hachted
1.3.3 光谱特征波段选择
预处理后的光谱信息依然高达1 361维,部分波段依然存在很强的相关性,高维光谱信息中不仅含有反映内部物质差异的信息还包含大量冗余信息,若直接使用高维光谱信息建立种鸭蛋受精信息判别模型会导致模型出现过拟合现象,进而导致模型的泛化能力变差。 同时考虑将光谱信息输入给卷积神经网络,若光谱波段存在很强的相关性则不利于卷积神经网络自动学习光谱的有效特征,从而导致网络过拟合现象的出现,且数据维数太高会大大降低网络的训练速度,不利于后期模型的部署。 因此对预处理后的光谱数据进行特征波长选取,降低光谱数据的维数显得十分重要。 本文使用了CARS与SPA这两种较为常用的特征波长筛选算法,筛选出能够反映受精蛋与无精蛋差异的关键波长点。
(1)竞争性自适应重加权(CARS)算法利用自适应重加权采样手段选出PLS模型中回归系数绝对值相对较大的波长点,去除权重相对较小的波长点,并使用交叉验证来选择RMSECV值最低的子集,可以有效地寻找到变量的最优组合[9]。 对预处理后的训练集光谱数据使用CARS进行特征波长选择,选取入孵前种鸭蛋受精信息预测最优波长组合过程如下: 经反复尝试,本实验将蒙特卡罗采样次数设定为50,采用10折交叉验证。 由图5(a)可知,随着取样运行次数的增加,选取变量的数量逐步递减 。 由图5(b)可知,RMSECV值先缓慢递减后递增,RMSECV值递减,说明种鸭蛋光谱数据中部分无用的信息被剔除,RMSECV值递增,说明种鸭蛋光谱数据中有部分重要信息被剔除。 当RMSECV值达到最小时,各变量的回归系数如图5(c)中竖线处,此时的采样运行次数是35,CARS提取的最优波长点数量为15。
(2)连续投影算法(SPA)是使向量空间的共线性最小化的前向变量选择算法,能够从原始光谱信息中将冗余信息去除,从而解决共线性问题。 对于处理后的训练集光谱数据使用SPA选择特征波长,由SPA的原理可知,利用均方根误差(RMSE)最小化的原则,选出均方根误差的导数变小的过渡点,在过渡点之前冗余信息被剔除,过渡值之后冗余信息已基本被剔除[10]。 SPA选取入孵前种鸭蛋受精信息预测最优波长组合如图6(a,b)所示,SPA选取的特征波长数为11。

图5 (a)取样变量数; (b)RMSECV; (c)回归系数路径Fig.5 (a) Number of sampling variables; (b) RMSECV; (c) Regression coefficient path

图6 (a)RMSE; (b)选取的最优波长编号索引Fig.6 (a) RMSE; (b) Selected optimal wavelengthnumber index
2 结果与讨论
2.1 卷积神经网络搭建
经过CARS或SPA提取特征波长后,数据维数已经降到较低维度,若继续对其进行降维处理可能会导致光谱有用信息的丢失。 针对分类问题,一般使用机器学习或者深度学习进行建模。 本研究先使用逻辑回归(logistic regression, LR)和支持向量机(support vector machines, SVM)两种常用的机器学习算法并使用十折交叉验证对CARS和SPA提取的特征波长建立入孵前种鸭蛋受精信息判别模型。 为方便起见,此处KS划分的测试集和验证集合并为测试集,判别结果如表1,不难发现LR和SVM模型不能完全拟合光谱数据导致模型效果不佳,但证明了使用CARS或SPA提取的特征波长建立区分无精蛋和受精蛋的可行性。 由于机器学习模型对较为复杂的模型拟合效果不佳,往往会产生过拟合或欠拟合的现象,本研究两种机器学习模型则是出现了轻微欠拟合现象。 卷积神经网络引入了局部连接和权值共享的机制,使其能含有更多的隐层,这种机制使得卷积神经网络在拟合复杂模型时具有明显的优势,故考虑使用卷积神经网络对入孵前种鸭蛋是否受精进行判别。

表1 CARS和SPA提取的特征波长建模结果Table 1 Characteristic wavelength modelingresults of CARS and SPA extraction
卷积神经网络主要用于图像的分类与识别,图像数据一般为2维或3维矩阵,而本研究使用CARS或SPA提取的特征波长数据为1维数据。 因此需要将一维光谱数据转换为二维光谱信息矩阵,转换公式如式(1)
S=XTX
(1)
式(1)中,X为一维光谱数据,XT为一维光谱数据的转置。 二维光谱信息矩阵包含了一维光谱数据的原有信息,体现了样本的方差和协方差,同时适用卷积神经网络的输入结构。 以SPA提取的种鸭蛋光谱特征矩阵为例,单个种鸭蛋样本的一维光谱数据为x=[x1,x2, …,x11]二维光谱信息矩阵如式(2)
(2)
卷积神经网络通常由卷积、池化与全连接等层构成。 卷积(conv2d)层用于提取大量特征; 池化层可以减小卷积层提取的特征的维数,从而能够加速神经网络收敛; 全连接层可将网络前端输出的特征还原给输出层,最后由输出层输出分类结果。 考虑到运用CARS和SPA提取的二维光谱信息矩阵尺寸较小,SPA提取的二维矩阵大小为11×11、CARS为15×15,若搭建的网络层数过深,容易出现过拟合现象。 结合入孵前种鸭蛋二维光谱信息矩阵的特点,搭建了4层的卷积神经网络,包括了3个卷积层和1个全连接层,网络的结构如图7所示,具体实现过程如下,其网络参数如表2所示(以CARS提取的入孵前种鸭蛋特征波长为例,SPA与之结构相同):
(1) 输入层: 将CARS提取的入孵前种鸭蛋特征波长使用式(1)转换为二维光谱信息矩阵作为输入层,输入层尺寸为15×15;
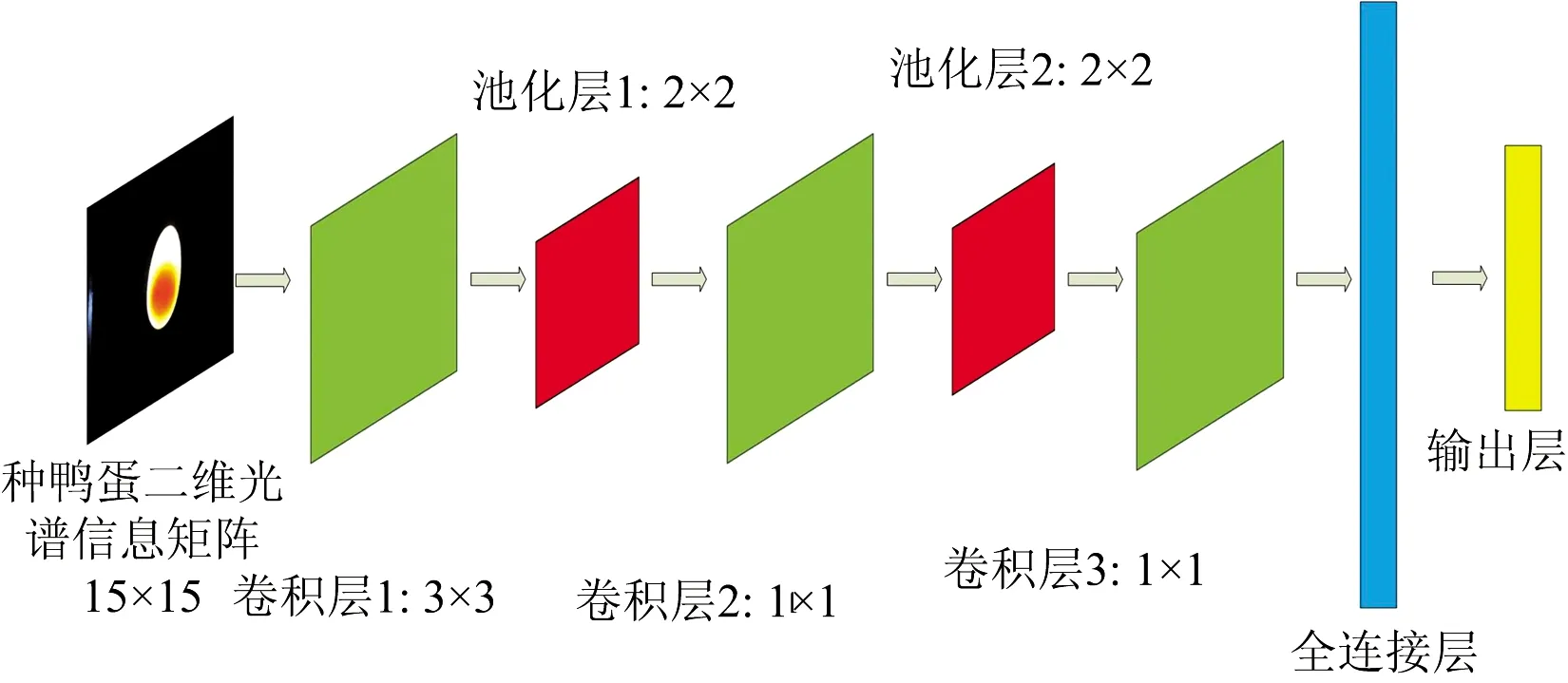
图7 入孵前种鸭蛋网络结构Fig.7 Pre-incubation duck egg network structure

表2 入孵前种鸭蛋网络参数Table 2 Network parameters of duck eggs before hatching
(2) 卷积层1: 考虑到输入的种鸭蛋二维光谱信息矩阵尺寸较小,conv操作的核尺寸与步长不宜设置过大,将卷积核尺寸设定为3×3,卷积核数量设定为64,步长设定为1。 输入层经过卷积操作后使用ReLU函数进行激活(可使种鸭蛋光谱矩阵变得更加稀疏),ReLU函数的实现公式如式(3)

(3)
ReLU函数具有加速模型收敛的作用。 为了提高模型的性能,在ReLU激活后的光谱特征矩阵执行局部响应归一化(LRN)操作,卷积操作可以提取光谱矩阵中的大量信息,种鸭蛋二维光谱信息矩阵经过卷积操作之后输出特征矩阵尺寸为15×15×64;
(3) 池化层1: 将卷积层1的输出特征矩阵进行降维操作,能够提高模型的收敛速度。 池化核的尺寸和步长均设置为2,池化(pool)处理后的输出特征矩阵尺寸为8×8×64;
(4) 卷积层2: 设置卷积核的尺寸为1×1,卷积核的数目设置为192,并将步长设置为1。 池化层1的输出经过卷积后,加入ReLU和LRN操作,输出尺寸为8×8×192;
(5) 池化层2: 池化核的尺寸和步长均设置为2,卷积层2的输出特征矩阵经过池化操作后,输出尺寸为4×4×192;
(6) 卷积层3: 卷积内核的尺寸设置为1×1,卷积内核的数量设置为384,步长设定为1。 池化层2的输出经过卷积后,加入ReLU和LRN操作后输出尺寸为4×4×384;
(7) 全连接层: 全连接层(FC)的神经元个数设置512,通过将卷积层3输出的光谱特征矩阵转换为1×6 144的数据,输入给512个全连接的神经元后输出512个权值,为了防止模型出现过拟合现象,在输出之前使用dropout层随机失活部分神经元。
(8) 输出层: 将全连接层的512个权值经过softmax函数得到一个二维得分矩阵,分别是受精蛋和无精蛋的得分系数。
2.2 卷积神经网络训练与测试
针对入孵前种鸭蛋光谱信息的卷积神经网络搭建完成后开始对其进行训练,虽然卷积神经网络要求有大量数据进行训练,本实验共采集499个入孵前种鸭蛋光谱信息样本做二分类,针对光谱信息分类问题样本数量已经足够。 卷积神经网络训练的核心思想是通过反向传播连续的迭代,使得模型的预测值不断地与实际值接近。 以CARS选取的特征波长进行训练为例,使用Adam优化器选择训练过程中最佳梯度下降方向,可加速模型的收敛。 使用均值平方差作为损失(loss)函数用来计算预测值与实际值的差值。 学习率(learning rate)初始化为0.00001,每次抽选8个样本进行训练(BatchSize=8),dropout设置为0.5,迭代次数设置为20 000后开始训练。 训练过程中的损失函数变化趋势如图8,可以发现分类损失loss在训练的前6000次一直处于快速下降状态,迭代到10 000次之后loss一直维持在较低水平,说明模型达到收敛。
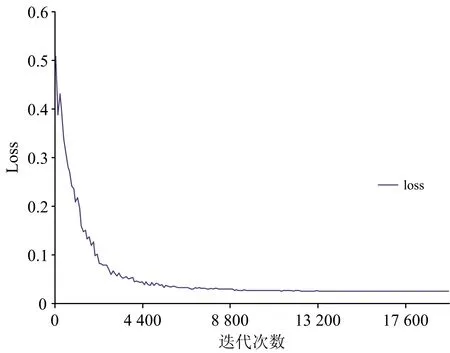
图8 损失函数变化趋势Fig.8 Trend of loss function
模型训练20 000次后对其进行保存,然后将训练集、测试集、验证集共499个种鸭蛋二维光谱信息矩阵输入到训练好的模型进行测试,验证模型的性能。 SPA提取的种鸭蛋光谱特征矩阵进行卷积操作与CARS类似,网络的结构完全相同。 模型测试结果如表3,从测试结果可以看出,SPA和CARS提取的特征波长转换为二维信息矩阵后,使用搭建的4层卷积神经网络建立入孵前种鸭蛋受精信息判别模型,从验证集和测试集的效果来看,模型未出现过拟合或者欠拟合现象,模型性能取得理想效果。

表3 模型测试结果Table 3 Model test results
3 结 论
利用可见-近红外透射光谱技术及深度学习研究了种鸭蛋孵化前受精信息的无损检测技术,通过研究分析获得如下结论:
(1)通过对种鸭蛋孵化前光谱信息的分析,发现其特征波长点主要分布在可见-近红外波段(400~1 000 nm)范围内; 经过SG预处理后,使用CARS选取的孵前种鸭蛋特征波长分别建立了逻辑回归、SVM、CNN判别模型,三者的测试集准确率分别为78.52%,79.94%,97.41%; 使用SPA选取的孵前种鸭蛋特征波长分别建立了逻辑回归、SVM、CNN判别模型,三者的测试集准确率分别为72.48%,87.39%和97.41%。 无论使用CARS还是SPA选取特征波长后,使用卷积神经网络建立判别模型都取得了最佳的效果,与传统的机器学习方法相比性能提升明显;
(2)光谱数据经过预处理和特征波长选取后,将一维光谱数据转换为二维光谱信息矩阵,实现了将卷积神经网络与光谱数据相结合,建立了种鸭蛋受精信息判别模型。 可以避免将1 361维数据直接用卷积神经网络训练带来的维数爆炸问题,大大加快了模型训练与测试的速度;
(3)采用3个卷积层和1个全连接层组成的神经网络结构,对入孵前种鸭蛋光谱数据的分析取得了较好的效果。 为使用卷积神经网络方法对禽蛋光谱数据进行分析提供了参考;
研究结果利用可见-近红外透射光谱结合卷积神经网络对种鸭蛋入孵前受精信息无损检测具有可行性,使用CARS和SPA选取的特征波长建立的卷积神经网络模型验证集准确率均为97.44%和98.29%,可以满足部署到实际生产的精度要求,为后续相应装置的研发提供了模型支持。 但模型仍有再提高之处,使用的实验样本仅为缙云麻鸭种蛋,后续需要采集其他地区鸭品种的种蛋光谱数据来提高模型的通用性。
猜你喜欢
小学生学习指导(中年级)(2022年6期)2022-11-23
江苏农业科学(2019年6期)2019-09-25
绿色科技(2017年20期)2017-11-10
中国管理信息化(2017年5期)2017-06-22
红领巾·萌芽(2017年3期)2017-05-03
科技知识动漫(2017年4期)2017-04-15
中南大学学报(自然科学版)(2016年2期)2017-01-19
中国照明(2016年4期)2016-05-17
软件导刊(2015年1期)2015-03-02
中国当代医药(2015年26期)2015-03-01
