
基于PSO-LSSVM和特征波长提取的羊肉掺假检测方法
2020-12-07 08:41成甜甜王克俭韩宪忠
食品与机械 2020年11期
成甜甜 王克俭 韩宪忠 李 师 王 媛
(1. 河北农业大学,河北 保定 071000; 2. 国家羊肉加工技术研发专业中心〔衡水志豪畜牧科技有限公司〕,河北 衡水 053000)
羊肉肉质细腻鲜嫩,蛋白质含量高,较其他肉类的脂肪、胆固醇含量低[1],具有丰富的营养价值,不仅温脾养胃,还有补肝、益血、明目的功效,但由于羊肉价格较高,加工企业多且散乱难以管理,市场上一些不法商贩向羊肉掺入其他动物肉类以谋求暴利,严重损害消费者的利益甚至健康。传统用于检测掺假的方法大多是基于化学或物理的方法,例如酶联免疫吸附法(Enzyme Linked Immunosorbent Assay,ELISA)、聚合酶链反应(Polymerase Chain Reaction,PCR)和电子鼻技术等,但是这些方法操作复杂、灵敏度不高,甚至会破坏样品的完整性[2]。
光谱仪可以获取物体的光谱数据信息,如光谱吸收、透射率、反射率、颜色等。将光谱数据与计算机技术结合,可以对肉类进行无损、快速检测。王飞翔[3]建立偏最小二乘(PLS)模型,对调理肉在熟化过程中的水分含量进行预测,开发了基于多光谱成像技术的调理肉在线检测系统。范卉[4]应用多光谱技术结合光学层析分析技术,对芝麻油、菜籽油、花生油、调和油、猪油、餐厨废弃油和花生煎炸油7类油进行甄别,为食用油和地沟油的鉴别提供了可靠方法。郝广等[5-6]采用主成分分析法(Principal Component Analysis,PCA)、偏最小二乘法、最小二乘支持向量机(LSSVM)和反向传播神经网络(BPNN)建立定量模型,实现了多光谱成像技术在番茄酱中蔗糖掺假的快速检测。Ropodi等[7]针对肉类掺假的问题,提出利用多光谱成像技术对掺假牛肉进行检测,并建立了判别模型将所有样品正确分类。刘友华等[8]针对羊肉掺假浓度检测问题,采用竞争性自适应重加权法(CARS)法建立特征波长预测模型,模型的预测集决定系数为0.940 0,均方根误差为0.076 6。白京等[9]采用竞争性自适应重加权法提取特征波长并建立偏最小二乘模型,测定羊肉卷中猪肉掺假比例,其测试集的决定系数为0.972 5,均方根误差为0.057 7,相较于全波长模型结果有所提升。此外,还有一些学者[10-13]对肉类的含水率和掺假量进行了预测。
目前中国利用多光谱成像技术对肉类掺假检测的研究较少,多数为对算法模型的简单应用,且未对模型进行改进以提高其预测能力,预测结果的准确度不高。为提高掺假肉检测准确度,试验拟将羊肉掺入不同比例的猪肉,利用多光谱系统提取样品表面的反射率,将掺假羊肉的反射率与羊肉掺入猪肉的浓度建立定量预测模型,对羊肉中猪肉的掺假浓度预测,并对模型进行优化,提升模型预测能力。进一步提取特征波长,简化模型。为掺假羊肉的快速无损识别提供切实可行的方法。
1 材料与方法
1.1 仪器
试验所用多光谱检测系统由电脑、光谱仪、可交换狭缝、WS-1漫反射标准白板、海洋光学配套软件Ocean View、光纤和探头等装置组成。光谱仪(上海蔚海光学仪器有限公司)型号为海洋光学(Ocean Optics)的USB2000+,波长范围在350~1 100 nm,共有2 048个光谱像素数。
1.2 样品制备
于保定市场购买的新鲜生肉,选取羊肉里脊和猪肉里脊各1 kg。将羊肉和猪肉中的肥肉去掉,使用榨汁机将两种肉分别搅碎1 min,直至羊肉和猪肉呈肉糜状,再分别按照m羊肉∶m猪肉分别为1∶9,2∶8,3∶7,4∶6,5∶5,6∶4,7∶3,8∶2,9∶1均匀混合并分装在玻璃培养皿中,另外准备一份纯羊肉和一份纯猪肉的样本,共11份试验样本,每个样本30 g。
1.3 多光谱数据采集与异常数据剔除
光谱仪的积分时间设置为2.85 s,扫描次数为100次,滑动平均宽度设为3,试验环境温度为20 ℃。采集光谱数据时,数据结果容易受到外界光源或环境的干扰而产生噪声,令试验结果产生误差,使得模型效果变差,因此为系统设计了一个暗箱,保证环境无可见光的干扰,并且在采集光谱数据前,需要使用海洋光学光谱设备配套的WS-1漫反射标准白板进行白板校正,以此来减弱外界环境对数据的影响。采集光谱数据时,将探头垂直置于距样本1 cm的位置,对样本进行多次扫描。得到波长范围350~1 100 nm的反射光谱数据。
对采集到的原始光谱数据进行筛选和归一化处理,剔除明显偏高或偏低的异常样本,尽量选取反射率无交叉,有明显区分度的区域作为分析数据。选出可用波段后,将试验数据分为两部分,训练集用于建立判别模型,测试集用于检验模型的准确度。
1.4 基于粒子群优化的最小二乘支持向量机模型(PSO-LSSVM)
最小二乘支持向量机方法结合粒子群算法,利用PSO对LSSVM的两个参数进行最优搜索,建立了一种用于羊肉掺假定量检测的粒子群优化最小二乘支持向量机的模型,并将该优化模型的预测结果与现有模型的预测结果进行对比分析。
1.4.1 最小二乘支持向量机 最小二乘支持向量机将支持向量机(SVM)优化问题的不等式约束替换为等式约束,对于给定的m组样本(xi,yi),样本数i=1,2,…,m,xi为n维输入向量,yi为输出向量。LSSVM在回归时用超平面对m组数据进行拟合。
(1)
约束条件为:
yi=wTφ(xi)+b+ei,
(2)
式中:
w——超平面权重向量;
b——超平面偏差向量;
e——训练点的误差;
γ——惩罚系数。
式(2)中的γ越高代表对误差的容忍度越小,γ越低代表对误差的容忍度越大,合理取值可以提高模型的预测能力。
构造拉格朗日(Lagrange)函数求解:
(3)
式中:
ai——xi对应的拉格朗日乘子。
求解过程中引入高斯核函数K(x,xi):
(4)
高斯核函数中σ决定数据映射到新的特征空间后的分布,σ越大支持向量越少,σ越小支持向量越多。支持向量的个数与预测的速度有关。
推导最终得到LSSVM回归函数:
(5)
1.4.2 粒子群优化算法 粒子群算法是通过模拟鸟类飞行觅食而设计出的一种群体智能优化算法。已知在一个区域内有一块食物,鸟群知道当前位置离食物还有多远,找到食物最简单有效的方法就是搜索离食物最近的鸟的周围区域。采用粒子群算法优化最小二乘支持向量机的两个参数γ和σ,在问题中,每一个解都是空间中的一只鸟,称为粒子,代表两个参数的不同组合,食物代表最优的参数组合,粒子通过迭代搜索调整自己的位置和速度寻找到最优解。
(1) 对粒子群中粒子i的位置zi=(γi,σi)和速度vi随机初始化,生成大小为n的粒子种群。
(2) 将每个粒子代入LSSVM模型对训练集数据拟合,得到模型的预测值f(xi)与期望输出yi,训练结果的均方根误差决定每个粒子的适应度值(fitness)。
(6)
(3) 每个微粒根据适应度值更新自己的个体最优值(pbesti)和群体最优值(gbesti)。
pbesti=(pbesti1,pbesti2,…,pbestin),
(7)
gbesti=(gbesti1,gbesti2,…,gbestin)。
(8)
(4) 根据适应度值对粒子的速度和位置进行更新。
vi=vi+c1×rand()×(gbesti-zi)+c2×rand()×(gbesti-zi),
(9)
zi=zi+vi,
(10)
式中:
c1、c2——学习因子。
在粒子群算法中,学习因子的取值一般为2,rand()为0和1之间的随机数。
(5) 通过终止条件判断是否结束迭代,得到粒子的最优位置。
1.5 特征波长提取
提取特征波长不仅可以简化模型,还能剔除无关变量,提升模型性能和预测能力,增强稳定性。试验分别采用随机青蛙算(RF)[14]、无信息变量消除法(UVE)[15-16]、竞争性自适应重加权法[17]提取特征波长,以提取出的波长作为输入变量建立偏最小二乘特征波长模型,对比预测结果,得到最优的特征提取算法。
2 结果与讨论
2.1 原始光谱
利用多光谱检测系统对样本提取反射率,图1为样本在350~1 100 nm波段下的反射率。由图1可知,相同波段下不同掺假比例的样本反射率走势相同,在某些波段下有明显区分。样本中有一条数据反射率明显偏低,考虑是由于试验误操作引起,可以剔除。数据两侧的噪声较多不平滑,走势密集不易区分,不宜选用,故选取波段中间500~650 nm下427个波长点的反射率作为可用数据。由于数据的量纲不同,并且数据尺度不统一时对预测模型的结果影响很大,故需要对光谱数据作归一化处理,将数据映射在-1和1之间,结果如图2所示。
2.2 全波长模型
选取了可用波段的数据后,将32组数据按照2∶1分为训练集和测试集,有21组训练集数据(xi,yi)(i=1,2,…,21),xi为427维输入向量,代表427个波点数,yi为羊肉掺入猪肉的浓度。
利用粒子群优化算法,对最小二乘支持向量机的两个参数γ和σ进行寻优,初始化粒子群的种群大小、学习因子、位置、速度、搜索范围和迭代次数。将粒子i的位置zi=(γi,σi)代入LSSVM模型对训练集数据进行拟合,模型预测结果的均方根误差作为粒子群算法的适应度值,每个粒子根据自身适应度值,得到pbest和gbest,计算更新粒子的速度vi和zi,直到迭代结束得到全局最优的位置,即为粒子群算法优化所得两参数γ和σ。
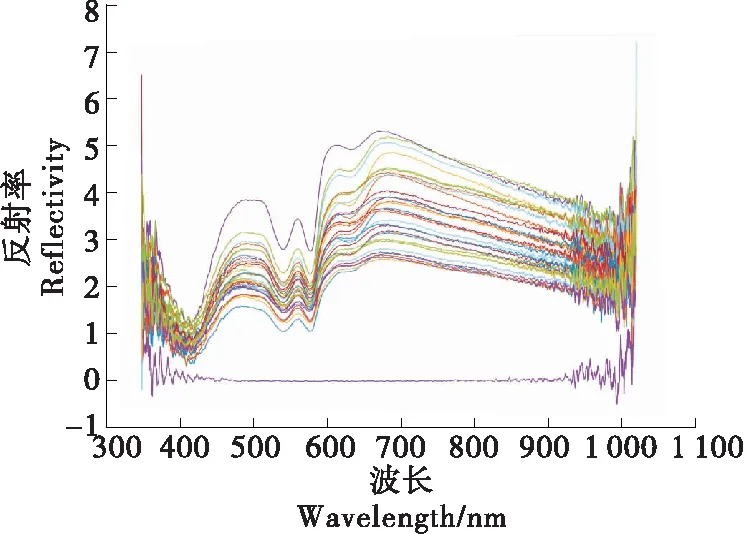
图1 原始光谱图像

图2 归一化后的光谱图像

2.3 特征波长提取和特征波长模型
2.3.1 随机青蛙 采用随机青蛙算法在对500~650 nm波段下的32组数据提取特征波长,为减少算法中随机因素的影响,将算法运行1 000次并以选择概率平均值作为波长选择的依据,结果如图4。选择概率越大说明该变量对模型越重要,由图4可知,只有小部分的波长选择概率较大,最终选出前10个概率最大的波长作为特征波长,分别为588.944,560.757,618.225,639.282,512.897,620.650,524.040,536.212,500.265,621.689 nm。
2.3.2 无信息变量消除法 UVE将变量回归系数和标准偏差的比作为评判变量稳定性的值,稳定性绝对值越大,证明该变量的可靠性越高。对所有波长点计算稳定性后结果见图5。选择稳定性大于4的17条波长:504.963,536.927,578.408,579.815,582.979,583.330,584.032,584.383,584.735,611.630,612.325,612.673,613.020,513.367,615.450,615.797,633.087 nm。
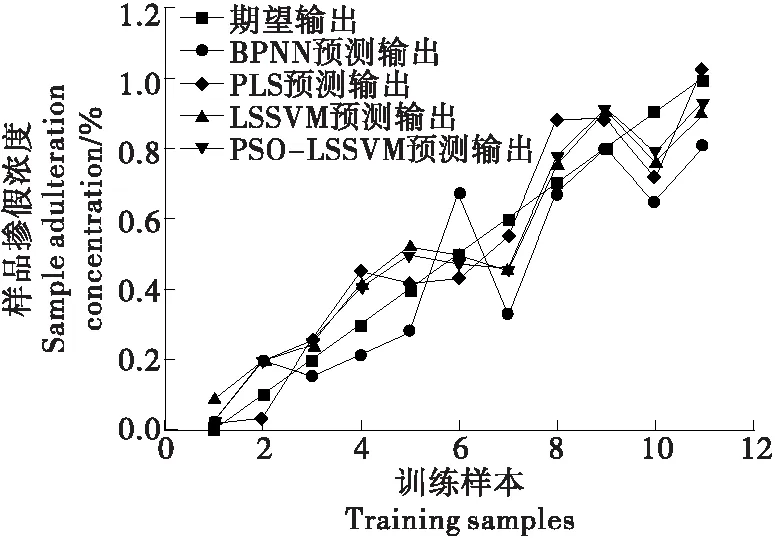
图3 模型预测输出
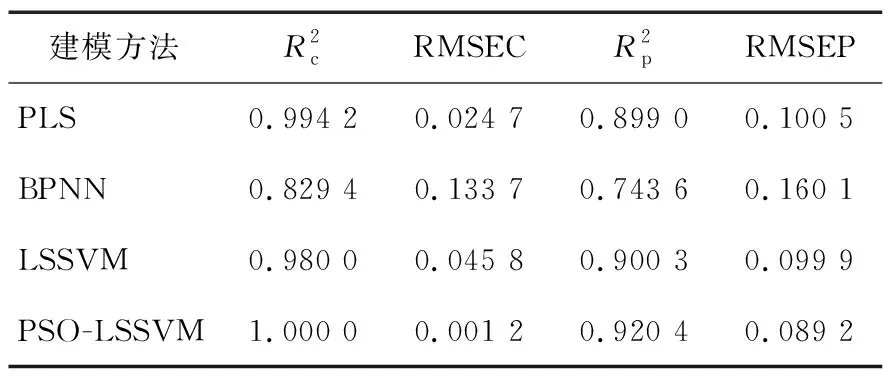
表1 不同模型的预测效果
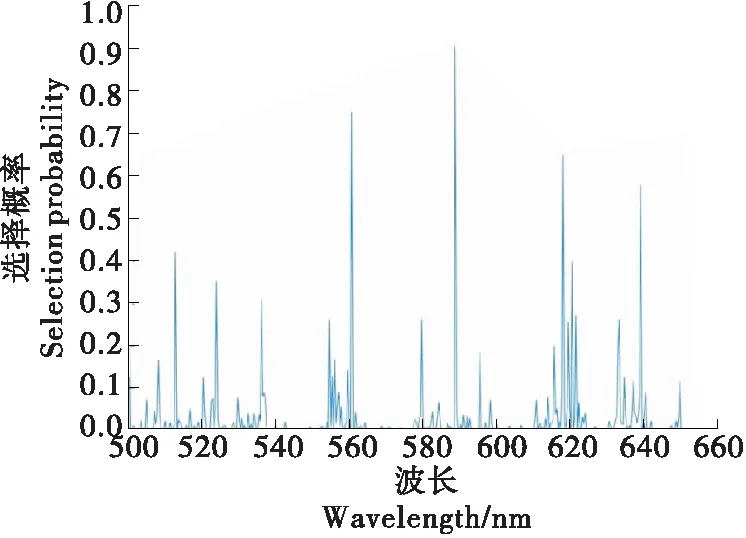
图4 随机青蛙平均概率
2.3.3 竞争性自适应重加权法 通过自适应重加权采样法去掉PLS模型中回归系数绝对值权重较小的波长点,得到的结果见图6,从427个波长点中提取出了20个波长点,分别为500.265,513.977,523.681,557.213,560.757,568.184,584.383,588.944,596.644,606.064,610.935,614.409,618.225,619.957,621.342,635.153,637.563,639.282,641.687,649.574 nm。
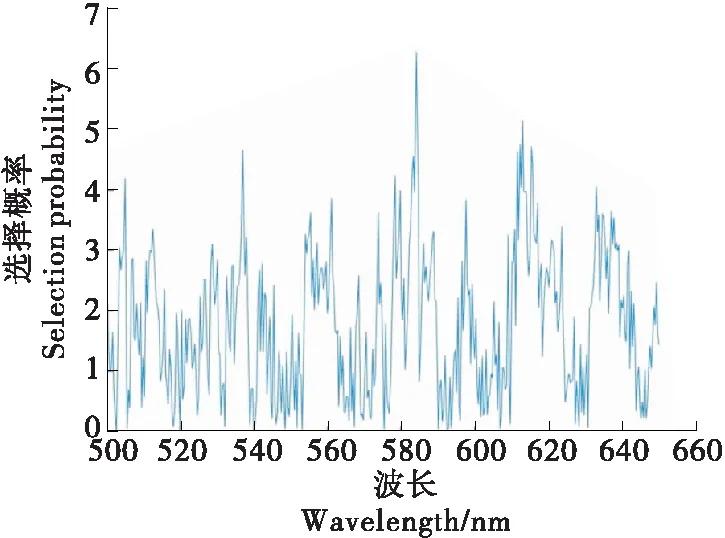
图5 UVE对样品稳定性值的计算结果

图6 CARS特征波长分布
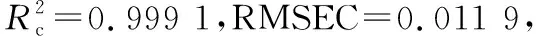

表2 不同特征波长提取方法下的模型预测效果
3 结论
应用多光谱图像技术获取羊肉和掺假羊肉在350~1 100 nm 波段下的反射率,建立偏最小二乘、BP神经网络、最小二乘支持向量机3种定量判别模型,并通过粒子群算法算法对最小二乘支持向量机的两个参数进行优化后建立模型,通过比较预测结果可知,最小二乘支持向量机在3种常用模型中的预测结果最优,使用粒子群算法优化最小二乘支持向量机后,模型预测效果显著提升。采用随机青蛙、无信息变量消除法、竞争性自适应重加权法对500~650 nm波段下的数据提取特征波长后建立偏最小二乘模型,结果显示模型预测效果整体提升,其中基于无信息变量消除法提取特征波长建立的模型预测结果最好。
试验还需进一步完善,扩充样本数量,对羊肉不同部位的肉作进一步研究和区分,增加不同种类动物的肉与羊肉掺杂,扩大模型的应用范围。
猜你喜欢
冶金能源(2022年5期)2022-10-14
环球时报(2022-09-28)2022-09-28
——缺陷度的算法研究
条码与信息系统(2022年3期)2022-07-05
汽车电器(2022年6期)2022-07-02
杭州电子科技大学学报(自然科学版)(2022年3期)2022-06-08
阅读(科学探秘)(2021年8期)2021-09-01
美食(2019年2期)2019-09-10
海峡姐妹(2019年1期)2019-03-23
汽车文摘(2018年2期)2018-11-27
小猕猴智力画刊(2016年12期)2017-01-05
