
基于k均值与SVM算法的学生综合评价及分类研究
2020-12-09 05:43彭琳钧吴其昌李诗敏周欣欣肖存涛
数字技术与应用 2020年10期
彭琳钧 吴其昌 李诗敏 周欣欣 肖存涛

摘要:随着高校招生规模扩大,对学生的考试成绩进行科学分析以便于专业分流和分级教学是目前高校管理工作中面临的一个重要问题。本文提出了一种基于k均值与SVM算法的半监督学习模型,首先利用因子分析提取学生的综合能力指标,然后通过k均值聚类对部分数据进行初步分类标注,最后利用训练得到的支持向量机模型对其他数据进行分类。模型验证结果表明本文构建的数学模型可以准确地区分不同特质的学生,高效地对大量学生做出合理的分类,对于高校管理和教学改革具有明确的指导意义。
关键词:半监督学习;聚类;因子分析;支持向量机;综合评价
中图分类号:TP391.41 文献标识码:A 文章编号:1007-9416(2020)10-0000-00
0引言
随著中国高等教育的发展,学校越来越注重对学生因材施教,而中国的应试教育使学生的能力评价指标仅仅局限于卷面总分,试卷上各个小题得分差异常常被忽视,而这些差异正是体现学生能力差异的重要指标。随着大类招生的发展,如何有效综合评价学生能力,有效地对大量学生进行合理分类,对学校的教学和管理工作至关重要。综合评价学生能力并批量进行学生分类系统的建立,一方面可以充分挖掘学生不同的能力特质,补齐缺陷,贯彻因材施教的思想;另一方面,能够实现对卷面成绩大数据分析的自动化,从而减轻教师对繁杂数据分析的负担;特别是针对当前高校大类招生的发展趋势,满足高校对大量学生进行专业分流以及教学改革的需求。
目前,国内有许多基于聚类分析模型在学生成绩评价方法的研究,如韦晓静基于k-means 模型的研究[1,2],这类研究虽然可以针对学生特质进行分类,但是教学改革是教师面向学生的改革,是人与人之间的活动,这中间有许多特殊因素,如学生特殊情况,教师教学习惯,学校资源情况等因素,无法单纯从数据中挖掘,那么这时候就需要教师针对实际情况对分类结果进行微调修正。就目前来看,高校一般一个行政班 30 人左右,人工修正尚可应付。但随着高校大类招生的发展,一个大类动辄百人,这时教师人工修正分类结果工作量巨大,极大地消耗了教师的精力。
本研究基于卷面各个小题得分数据,构建出聚类分析与SVM结合的半监督学习模型,依据模型分类结果对学生进行分类,以此为教师对学生分类管理,因材施教提供科学依据与便利。
1.1 模型构建思想
k?means 聚类是一种无监督学习模型,完全依赖数据上的差异进行分类,而教学改革是人与人之间的活动,数据无法体现的各种人文因素不可忽略;SVM 是一种监督学习模型,可以根据人工提供的标注训练模型,人工标注过程中则可以考虑种种人文因素调整标注,使 SVM 模型的分类可以把人文因素考虑在内,而在大类招生发展潮流中的教学改革,人工显然无法胜任如此大量的标注任务。
综合考虑两种模型利弊,本文提出基于 k?means 聚类结合 SVM 半监督学习模型的学生分类系统。通过 k?means 聚类对学生数据初步分类标注;教师基于已经初步分类的标注数据,综合考虑各种人文因素对分类标注进行调整;基于调整后的分类标注数据,SVM 对剩下大量未分类的学生进行分类。
如此,即可解决大类招生中学生分类的缺乏标注和标注任务量过大的问题,又可以充分考虑各方因素,减小教学改革工作量,使教学改革具备科学性与现实意义。
1.2 模型实现方法
1.2.1 数据预处理
本文选取某学期高等数学考试200个学生考试卷面各个小题的得分数据进行分析。借鉴了马晓悦在教学质量评估中多元统计方法的应用[3],使用 SPSS 工具,通过因子分析探索 27 道小题之间的潜在的相关关系,挖掘出八个能力因子系数,计算得出各个学生在这八个能力方面的得分情况如表1,这八个能力得分数据描述了200个学生在卷面上体现的各方面的综合能力。
这里挖掘出的八个能力因子具体指代的能力类型需要教改人员认真设计分析试卷小题特点,根据各小题在每个能力因子的系数确定每个能力具体类型,本文主要研究分类的模型,则以能力1,能力2... 来指代各能力类型;同理,学生分类的类别这里也以类别 1,类别 2,类别 3 指代。
1.2.2 训练集类别标注
通过 k?means 算法对数据初步分类,以此作为 SVM 的训练集。由于离群数据将大大影响 k?means 算法的聚类效果,对得到的每位学生的能力水平集合 D 进行利群数据的剔除。利用张甜等人对离群点预处理的处理方法[4], 当系数 c=0.3 时,样本集 D 中并没有需要剔除的离群数据。样本集 D 即为 k?means 算法的样本集 C。
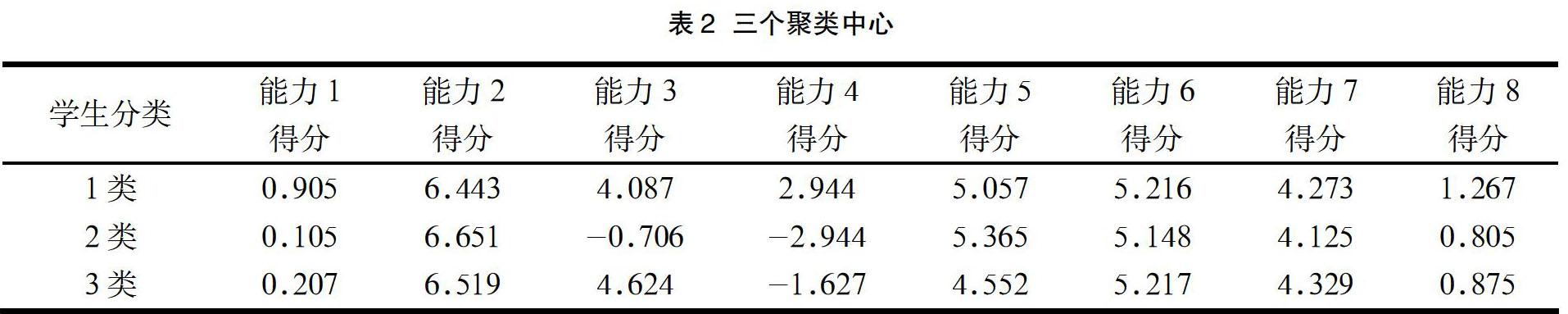
通过肘方法确定聚类中心个数。由于在开始选择聚类中心个数 k 时,我们尚不能知道将学生分为几类时分类效果最好,而手肘法是一种利用 SSE 和 K 值的关系图确认最优 k 值的方式,当聚类中心个数 k 增大时,样本的划分自然变得更加细致,SSE 也自然渐渐变小。当 k 小于聚类的真实情况时,k 值的增加会显著的增加每个类的聚合度,此时 SSE 下降速度较快。而当 k 值远远大于剧烈的真实情况时,SSE 变换会渐渐平缓。根据基于 K?means 的手肘法自动获取 K 值方法研究中提到的手肘法实现方法[5], 并结合学校资源和教师能力等因素,最终选择聚类中心个数为 k=3,聚类中心如表2所示。
基于学生在各个能力得分数据,通过 python3 根据模型原理编写程序实现聚类算法,得到每个学生的初步分类标注数据。
1.2.3 分类模型训练
以 k?means 模型计算得到的分类标记为基础,经过教改人员考虑其他人文因素微调后,将所得训练集对 SVM 模型进行训练。SVM 模型的构建,采用了 python3 中的 sklearn 模块,由于 sklearn 模块的 SVM 模型只能进行二分类,而根据聚类模型肘方法和学校资源现实情况,学生分为三类的情况最好,最符合实际。
本文采用多次分類的方法解决此问题。当聚类分类结果 yi = 1 或 2 时,令 yi = 1,当聚类分类结果为 3 时,令 yi = ?1,第二次应用 SVM 对 yi = 1 的样本再进行一次分类,即可实现多分类。根据学校师资等实际情况进行更多分类时也可以用此方法解决。
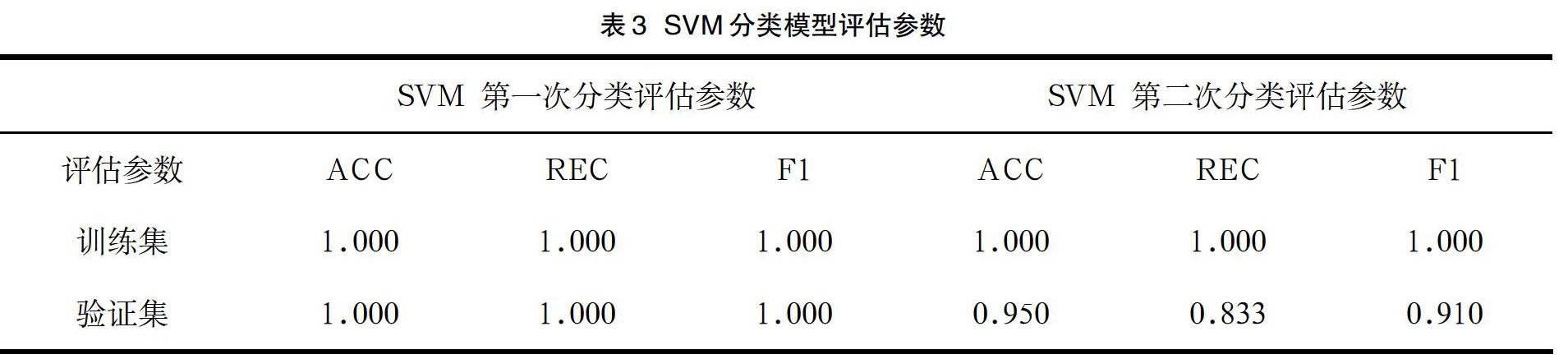
设置正则化参数 C(惩罚系数)为 20;参数 max_iter(最高迭代次数)为 43;取聚类分类完成后的 200 个学生的分类数据,由于正反例数据量相当(95﹕105),我们直接随机选取 160 个数据作为训练集,随机选取 40 个数据为验证集;采用了 ACC(准确率),REC(召回率)和 F1(精确率和召回率的加权平均值)三种参数来评估模型性能。第二次分类时参数设置与第一次分类相同。
1.3 模型实验结果与分析
基于各个学生在八个能力因子上的得分情况,通过聚类分析模型对学生进行了初步分类。如表 2可以看出三类学生的差异:第一类学生各方面的能力都较好;第二类学生能力三和能力四得分都较低;第三类学生能力四得分较低。这部分进行了初步分类的能力得分数据再以 8﹕2 的比例分别作为训练集和验证集对 SVM 模型进行训练和验证,最终得出如表 3中三个评估参数 (ACC,REC,F1)。由表 3中的数据可以看出,SVM 模型两次分类下来的准确率,精确率,召回率都较高,说明模型性能稳定,且准确、精确。
为了模拟教师在遇到特殊情况时需要修正分类结果的情况,我们在 200 个样本中修改了 20 个样本的分类结果。结果如表4所示,模型仍然可以保持较好的准确率,说明模型具有优秀的稳定性和泛化能力,可以适用于不同地域,不同教师教学习惯等情况下的学生分类工作。
2 结论
针对学生综合能力,契合当下高校大类招生和因材施教理念发展潮流的研究对教学改革和高校管理非常重要,而当下关于此课题缺鲜少研究。充分利用卷面数据,全面考虑人文因素,符合大类招生发展的需要,契合因材施教的理念,本研究通过聚类结合 SVM 的半监督学习分类器较好地解决了这些问题。
基于聚类?SVM 半监督学习模型的学生分类系统,首先通过 k?means 聚类分析,对数据进行初步分类,教师可以根据实际情况,充分考虑人文因素,对初步分类结果进行微调;这部分数据即可作为训练集,SVM 模型通过这个训练集进行学习,训练完成后的模型可以对剩余的大量学生数据进行分类。这样的聚类?SVM 半监督学习模型,即可以充分利用卷面数据根据学生能力进行分类,又可以避免数据以外的人文因素被忽略,同时还可以对逐渐发展成熟的大类招生产生的大量学生数据进行分类。
实验表明,基于聚类?SVM 半监督学习模型的学生分类系统有非常好的准确率和非常低的敏感度,泛化能力较好可以极大地降低教师的工作量,且为学生分类提供有力的数据基础,使教学改革更具科学性,具有现实意义。
参考文献
[1]韦晓静.基于聚类分析的学生成绩评定方法研究[J].智库时代,2020(11):203-204.
[2]孙吉贵,刘杰,赵连宇.聚类算法研究[J].软件学报,2008(1):48-61.
[3]马晓悦.高校数学教学质量评价中多元统计分析的应用[J].教育现代化,2018,5(19):231-233+252.
[4]张甜,尹长川,潘林,等.基于改进的聚类和关联规则挖掘的学生成绩分析[J].北京邮电大学学报(社会科学版),2018,20(2):91-96.
[5]吴广建,章剑林,袁丁.基于 K?means 的手肘法自动获取 K 值方法研究[J].软件,2019,40(5):167-170.
收稿日期:2020-09-07
基金项目:广东省信息物理融合系统重点实验室开放基金(2016B030301008),广东省高教厅教学改革项目,广东工业大学大学生创新创业训练计划项目。
作者简介:彭琳钧,男,广东茂名人,本科,研究方向:数据挖掘。[A1]
通信作者:肖存涛(1979—),男,山东阳信人,硕士,副教授,研究方向:机器学习、离散事件系统。
Research on Comprehensive Evaluation and Classification of Students Based on K-means Clustering and SVM Algorithms
PENG Lin-jun,WU Qi-chang, LI Shi-min, ZHOU Xin-xin, XIAO Cun-tao
(School of Applied Mathematics,Guangdong University of Technology, Guangzhou Guangdong 510520)
Abstract:With the expansion of college enrollment, scientific analysis of students' test scores is an important issue in the management of colleges and universities in order to facilitate professional diversification and hierarchical teaching. In this paper, a semi-supervised learning model based on k-means and SVM algorithms is proposed. Firstly, factor analysis is used to extract the comprehensive ability components of students, then k-means clustering is used to classify and label some data, and finally, the support vector machine model obtained by training is used to classify other data. The experiment shows that the model constructed in this paper can accurately distinguish students with different characteristics in high efficiency, which can guide the management and teaching reform of colleges and universities significantly.
Key words:Semi-supervised Learning;Clustering;Factor Analysis;Support Vector Machine;Comprehensive Assessment
猜你喜欢
科学与财富(2016年26期)2016-12-01
大学教育(2016年11期)2016-11-16
科学与财富(2016年28期)2016-10-14
