
用于精准预测的人工蜂群聚类数据挖掘算法研究
2020-12-09 05:43金红军
数字技术与应用 2020年10期
金红军

摘要:为了提高数据挖掘算法的查全率,为精准预测工作提供更加精准的数据支持,利用人工蜂群聚类技术在传统数据挖掘算法的基础上进行优化设计。针对不同的精准预测任务准备对应的数据样本,并通过选择、预处理和数据转换三个步骤,实现对初始样本数据的处理。利用人工蜂群聚类技术分类样本数据,并剔除离群数据。在设置关联规则的约束下,得出数据挖掘结果。通过算法性能的测试对比实验得出结论:与传统的数据挖掘算法相比,人工蜂群聚类数据挖掘算法的查全率提高了1.3%,将其应用到精准预测工作中,可以有效的降低预测误差。
关键词:精准预测;人工蜂群;聚类数据;数据挖掘算法
中图分类号:TN929 文献标识码:A 文章编号:1007-9416(2020)10-0000-00
0 引言
预测是根据历史和当前已知因素,运用已有的知识、经验和科学方法,对未来环境进行预先估计,并对事物未来的发展趋势做出估计和评价。为了保证预测结果的精准度,在当前预测方法的基础上提出了精准预测方法,这种方法延续了传统预测方法的一般步骤,但在实际的预测过程中选择更加精准的历史和当前数据,在预测过程中严格控制预测误差,从而保证预测结果的精准度[1]。精准预测技术的正常运行要求提供精准的历史数据和当前数据,因此数据挖掘算法经常被应用到精准预测工作当中。数据挖掘是从大量的数据中自动搜索隐藏与其中的有着特殊关系性的信息的过程,数据挖掘算法的实现需要借助计算机设备,通过数据统计、在线分析、数据处理、情报检索、及其学习以及模式识别等多种方法来实现对目标数据的挖掘[2]。然而当前的数据挖掘算法存在挖掘结果精度低的问题,将其用于精准预测工作中会导致预测结果存在严重误差,为了解决上述问题,提出了人工蜂群聚类技术。人工蜂群聚类技术通过各人工蜂个体的局部寻优行为,最终在群体中使全局最优值凸显出来。而聚类技术以相似性为基础,将具有较高相似度的数据聚类在一起。通过人工蜂群聚类技术的有机结合并将其应用到数据的挖掘过程当中,可以挖掘出目标数据集当中的一系列最优数据集合,将数据挖掘结果应用到精准预测工作当中,便可以得出精准的预测结果。
1 人工蜂群聚类数据挖掘算法设计
1.1 数据准备与处理
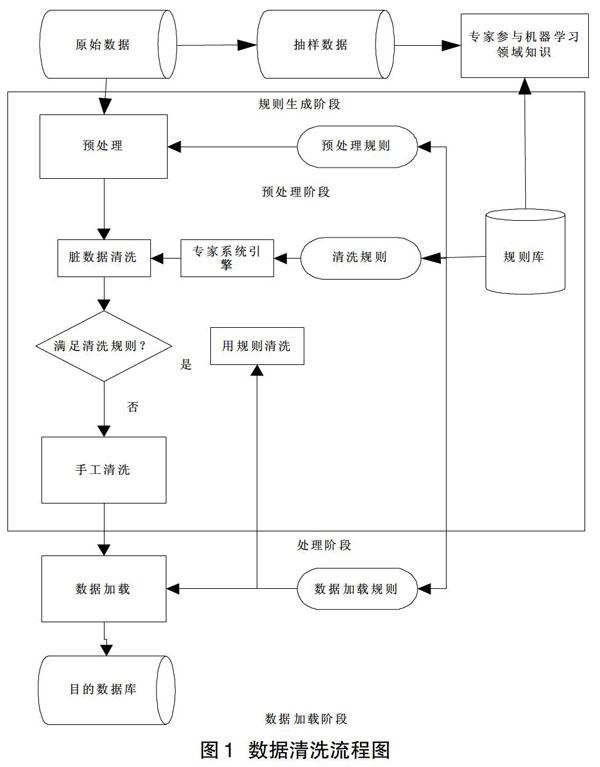
数据准备与处理的过程就是数据收集和预处理的过程,通过数据的选择、预处理和数据转换三个步骤得出初始数据的处理结果[3]。其中数据清洗处理的过程如图1所示。
从图1可以看出数据清洗分为四个处理阶段,分别为清洗规则的生成阶段、预处理阶段、处理阶段和数据加载阶段。通过数据的清洗可以检测出初始数据集合并解决单一数据源中或多数据源集成过程中存在的数据质量问题,直到样本数据满足数据的质量要求[4]。
1.2 利用人工蜂群聚类技术分类样本数据
人工蜂群算法模拟蜜蜂不同的分工,种群中主要分为采蜜蜂、观察蜂和侦查蜂三种类型,一个蜜源对应一个采蜜蜂,观察蜂通过观察采蜜蜂带来的蜜源信息,结合蜜源的数量和质量选择蜜源进行开采,加快算法的收敛[5]。而侦查蜂的作用是在整个区域范围内搜索可用的蜜源,从而提高全局的开采能力。假设人工蜂群蜜源表示的是目标函数的解,那么蜜源的质量能够反映出目标函数解的质量,该质量使用公式(1)表示的适应度函数来衡量。
结合人工蜂群的变异和交叉思想,分别通过采蜜蜂、观察蜂和侦查蜂三个角度执行人工蜂群算法[6]。在开始运行之前,首先需要对算法中的变量进行初始化处理,根据公式(1)开始迭代执行以下阶段,直到达到最大迭代次数。人工蜂群算法的采蜜蜂和观察蜂阶段可以表示为:
公式(2)(a)中在初始蜜源附近产生一个新的邻近蜜源,记为,表示的是此时对蜜源的第j维产生一个扰动。公式(2)(a)中为控制绕度幅度的随机数,j为常数参数[7]。在侦查蜂阶段,蜜源经过多次扰动后仍未更新,被判定为枯竭蜜源,重新搜索一个新的蜜源来代替初始蜜源,返回到采蜜阶段继续进行新一个循环迭代。结合上述人工蜂群算法进行初始样本数据的聚类处理,并诊断出源数据集合中的离群样本。定义初始数据样本集合为(公式(3)):
其中样本数据的维度为n,设置聚类中心,并得出相同类型样本数据与聚类中心之间的距离,距离计算如公式(4):
式(4)中表示的是设置的聚类中心,即为任意一个样本数据与其对应的聚类中心之间的距离,而J为各个样本达到对应聚类中心的距离综合[8]。遵循最邻近聚类法则,判断任意一个样本数据是否属于类型D,若满足公式(5)中的条件,即数据属于类型D。
由此便可以得出样本数据的分类结果。如果在样本数据中存在一个样本数据,该数据不属于任意一个聚类,则认定该数据为离群数据进行剔除处理[9]。
1.3 实现精准预测相关数据并行挖掘
为了提高数据挖掘的效率,在保证数据挖掘结果质量的同时提升数据挖掘的速度,以人工蜂群聚类技术下样本数据分类为基础,在关联规则的约束下,采用并行的方式实现对数据的精准挖掘,从而為精准预测工作提供更加准确的数据样本[10]。其中并行的两个部分分别为数据挖掘执行程序和人工蜂群聚类技术下的数据分类程序,以人工蜂群聚类分类结果为一个数据仓库得出符合关联规则的一组数据挖掘结果,为了保证两个并行程序的负载均衡,需要及时调整数据的挖掘误差,最终将输出的多组数据挖掘结果进行融合,得出的结果即为用于精准预测的数据挖掘结果[11]。
2 数据挖掘算法应用实验分析
2.1 实验目的与过程
此次实验的实验目的是为了证明设计的人工蜂群聚类数据挖掘算法的性能,数据挖掘算法的性能测试分为两个部分,分别为挖掘算法本身的查全率和算法的应用性能。实验中选择通信网络流量的精准预测作为实验环境,设置了传统的数据挖掘算法和文献[6]中提出的云计算下的数据挖掘算法作为此次实验的对比方法,分别将三种数据挖掘算法以相同的方式导入到实验环境中,保证实验变量的唯一性。
