
基于改进的YOLOv3及其在遥感图像中的检测
2020-12-10 10:05张孙杰王永雄
小型微型计算机系统 2020年11期
陈 磊,张孙杰,王永雄
(上海理工大学 光电信息与计算机工程学院,上海 200093)
1 引 言
近年来,目标检测已成为计算机视觉的研究热点,其广泛应用于机器人导航[1,2]、智能视频监控[3-5]、工业检测[6,7]、航空航天[8,9]等诸多领域,其不仅需要确定目标在图像中的类别,还需给出其精确位置.遥感图像中的目标呈现低分辨率,特征不明显的特点,导致识别率不高.因此,小目标检测仍是一项挑战[10].
在过去的几年中,研究者们发现设计深度卷积神经网络可以大大提高图像分类和目标检测的性能[11],因为它不仅可以从图像中提取出目标的强语义高级特征,而且将特征提取、特征选择和特征分类融合到一个模型中,通过端到端的训练,从整体上进行功能优化,增强了特征的可分性.当前用于目标检测的卷积神经网络主要分为以下两类:
1)两阶段检测算法,该类算法首先生成一系列的候选区域,然后再精确地分类,这类典型的算法代表有Fast R-CNN[12]、Faster R-CNN[13]、Mask R-CNN[14]等,然而以上方法不适用于实时的场景检测;
2)相反,单阶段检测器直接从原始图像直接进行目标预测,比较典型的算法有YOLO[15-17]三个版本、SSD[18]和Retina-Net[19]等.因此,单步检测算法同时具有更高的检测精度和更快的检测速度.
2 相关工作
图像分类可以预测图像中单个目标的类别,目标检测有其自身的挑战,需要在单个图像中预测多个目标类别和相应的位置.为了解决这个问题,以多尺度表示目标特征层的金字塔特征方法被提出,特征金字塔(feature pyramid network)[20]是生成用于目标检测的金字塔特征表示的代表性模型架构之一.它采用自顶向下、横向连接组合主干网络模型中两个相邻特征层的方式来构建特征金字塔,生成高分辨率、强语义的特征.近期文献[21]和文献[22]提出了各种跨尺度连接或操作,以组合特征的方式生成金字塔特征.YOLOv3借鉴了以上特征金字塔模型的思想,如图1所示.其是基于Darknet53的主干网络模型,共有75个卷积层,5个残差块,进行5次降采样,其分别利用主干模型输出的8倍、16倍、32倍降采样特征图作目标的预测.用深层提供的强语义信息预测大目标.通过自顶向下、横向连接的方式与包含更多空间位置信息的浅层特征相融合,用于预测小目标.因此,该模型能够很好地兼顾大、中、小三种不同尺寸的目标检测.
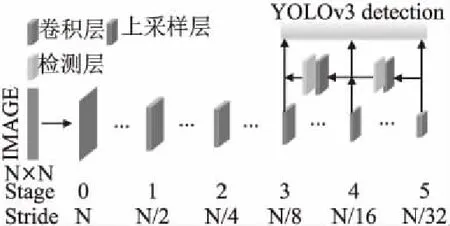
图1 YOLOv3网络结构图Fig.1 YOLOv3 network structure
受文献[20-22]启发,本文提出了双向金字塔特征融合的体系结构.以单阶段目标检测算法YOLOv3为基础,提出在FPN模块上添加额外的自底向上、横向连接的路径改善低分辨率特征的性能,对YOLOv3的网络架构作改进.首先,将网络的最后一层的卷积层特征输出与相邻上一层的卷积层特征输出相融合,构成自顶向下的金字塔特征层.还考虑将浅层的卷积层特征输出与相邻下一层的卷积层特征输出相结合,构成自底向上的金字塔特征层,融合双向结合的金字塔特征.这不仅结合了深层特征的全局语义信息,还加入了浅层卷积的细节局部纹理信息.并将原网络的第一个降采样层改为两个3×3的卷积层,使得网络在初始阶段可以保留更多的小目标位置特征信息.最后,为了提高网络的检测速度,采用1×1的卷积减小网络模型的维度.在遥感图像VEDAI[23]和NWPU VHR[24]公开数据集上与目前最先进的目标检测网络YOLOv3相比,改进的网络对小目标的识别率有了明显的提升,且检测速度几乎保持不变.
3 改进的YOLOv3检测网络
YOLOv3中使用的先验框对遥感图像数据集不太适用.因此,首先利用k-means++聚类算法对遥感图像数据集的目标框个数和宽高比进行聚类,然后修改网络的架构,最后对数据集进行训练与检测.
3.1 先验框聚类分析
YOLOv3借鉴了Faster R-CNN中使用先验框的思想.先验框是一组宽高固定的初始预测框,不同的数据集聚类出的先验框的个数和宽高不同.YOLOv3使用了k-means聚类算法对数据集的目标框进行聚类分析.本文采用了k-means++聚类算法对遥感图像数据集进行了聚类分析,与k-means聚类算法相比,它采用初始中心点彼此尽可能远离的策略作为目标聚类平均重叠度的度量,使得聚类结果不受随机选择初始聚类中心点距离的影响,聚类出的先验框更贴近数据集的目标框.聚类的Avg IOU目标函数如下:
(1)
式中,B表示目标的真值.C表示簇的中心,nk表示第k个聚类中心样本数,n表示总样本数.

图2 k-means++聚类分析Fig.2 K-means++ cluster analysis
本文对遥感图像VEDAI和NWPU VHR公开数据集进行聚类.如图2所示,k分别取19时,对数据集进行聚类分析,到k与Avg IOU之间的曲线走势.随着k值的增大,曲线开始变得平缓,拐点处k=3时,既可以加快损失函数的收敛,又可以消除候选框带来的误差,在公开数据集VEDAI上得到的3组宽和高的预测框分别为(9,18)、(18,8)、(18,17);相应地,在NWPU VHR-10的车辆数据集上对应的3组宽和高的预测框分别为(16,23)、(18,35)、(29,26).

图3 改进的YOLOv3网络结构Fig.3 Improved YOLOv3 network structure
3.2 改进的YOLOv3网络架构
YOLOv3使用主干网络输出的8倍降采样特征图来检测小目标,当遥感图像中目标分辨率低于8pixel×8pixel时,被检测目标的特征在输出的特征图中几乎没有了,为了使网络能够获取更多小目标的位置信息,如图3所示,本文将网络的第一个降采样层改为两个3×3的卷积层,以保留更多的小目标位置特征信息.此外,本文将网络最后一层的卷积层特征输出与相邻上一层的卷积层特征输出相融合,构成自顶向下的金字塔特征层,还考虑将浅层的卷积层特征输出与相邻下一层的卷积层特征输出相融合,构成自底向上的金字塔特征层,融合双向结合的金字塔特征.其不仅利用了深层特征的全局语义信息,还加入了浅层卷积的细节局部纹理信息,使得中间层对小目标的检测更加准确,最后采用1×1的卷积减小网络模型的维度,提高网络的检度速度.
4 实验结果与分析
4.1 数据集介绍与分析
分别使用遥感影像VEDAI和NWPU VHR-10公开数据集来训练和检测网络识别性能,VEDAI数据集包含可见光和红外两种图像,包含各种车辆和复杂背景,图像中除包含很小的车辆外,还表现出不同的可变性,例如多个方向,光照、阴影的变化和遮挡,是典型应用于监视侦察的场景.为了使目标的检测更富有挑战性,两个数据集图像都被缩放或裁剪为512pixel×512pixel和416pixel×416pixel.VEDAI数据集包含九类车辆对象,即“car、truck、pickup、tractor、campingcar、boat、van、other and airplane”.平均每张图像包含5.5个车辆目标,约占图像总像素的0.7%.该数据集中的目标尺寸大小在11.5pixel×11.5pixel到24.1pixel×24.1pixel之间.NWPU VHR-10数据集是一个公开的10级地理空间物体检测的航空影像数据集,包含“airplane、ship、storage tank、baseballdiamond、tennis court、basketball court、ground track field、harbor、bridge and vehicle”10个类别.由于数据集中大多数目标类别尺寸偏大,例如“tennis court、basketball court、ground track field”,因此选取“vehicle”作为单类检测的目标.每张图像平均包含11个目标,约是VEDAI数据集的两倍多,该数据集的目标尺寸在19pixel×19pixel到94pixel×94pixel之间.YOLOv3在大、中、小3种不同尺度上对目标作预测,提高了遥感图像的小目标识别率.因此,本文与YOLOv3目标检测算法进行对比实验.
4.2 实验平台
为验证本文改进后网络的识别性能,本文与YOLOv3网络模型进行比对,实验采用512pixel×512pixel和416pixel×416pixel两种尺寸的图像作为输入,在CPU为2.10GHz,显存为16GB的1080GPU工作站上进行训练和测试,深度学习框架为Pytorch,利用图像旋转、裁剪等方法对数据集进行增强和扩充.在VEDAI数据上:批尺寸为8,初始学习率为0.001,动量项系数β=0.9,分别在迭代到45000步和60000步时,学习率降为0.0001和0.00001.在NWPU VHR数据集上,批尺寸为8,初始学习率为0.001,动量项系数设置为β=0.9,分别在迭代到30000步和45000步时,学习率降为0.0001和0.00001.
4.3 定量与定性分析
实验1.
表1是在VEDAI数据集上测试的模型检测结果,在输入为416pixel×416pixel分辨率图像上,检测精度和速度分别为47.7%和42.3F/S,相较原先的YOLOv3模型,检测精度被提高了5%,检测速度几乎保持不变.在输入为512pixel×512pixel分辨率图像上,检测精度和速度分别为66.8%和38.4F/S,相较原先的YOLOv3模型,检测精度被提高的12.8%,检测速度几乎保持不变.
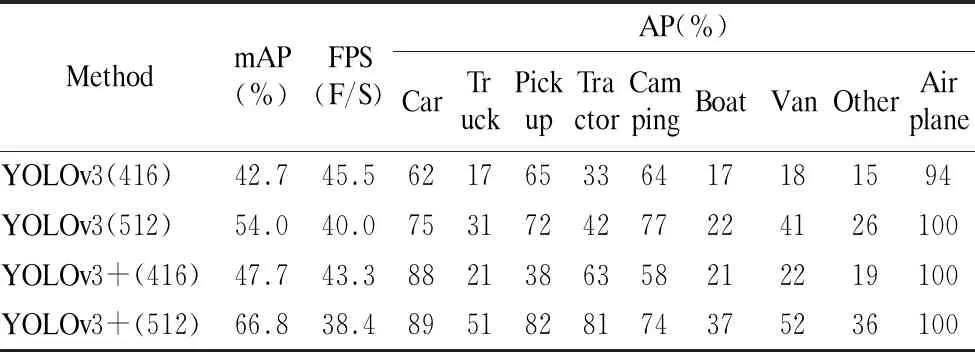
表1 在VEDAI数据集上的检测性能对比Table 1 Comparison of detection performance on VEDAI dataset
实验2.
表2是在NWPU VHR的单类数据集VEDAI上的模型检测结果,在输入为416pixel×416pixel分辨率图像上,检测精度和速度分别为和75.5%和19.2F/S,相较原先的YOLOv3模型,检测精度提高的1.1%,检测速度几乎保持不变.在输入为512pixel×512pixel分辨率图像上,检测精度和速度分别为88.3%和40.0F/S,比较原先的YOLOv3模型,检测精度被提高的3.2%,检测速度几乎保持不变.
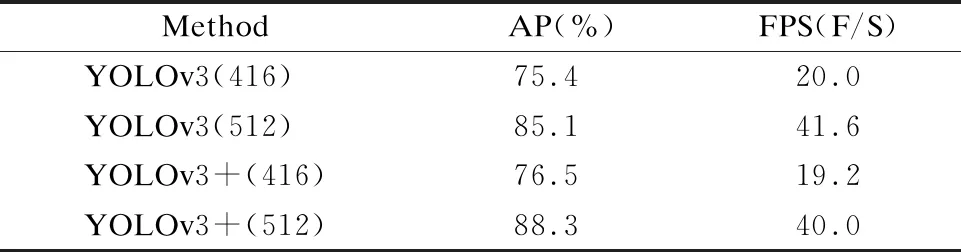
表2 在NWPU VHR数据集上的检测性能对比Table 2 Comparison of detection performance on NWPU VHR dataset

图4 改进YOLOv3与原网络的检测结果对比(VEDAI)Fig.4 Results comparison of between improved YOLOv3 and original network on VEDAI datasets

图5 改进YOLOv3与原网络的检测结果对比(NWPU VHR)Fig.5 Results comparison of between improved YOLOv3 and original network on NWPU VHR datasets
图4和图5为512pixel×512pixel输入尺寸的检测结果图,第1行为原图,第2行为原网络检测图,第3行为改进的YOLOv3检测图.从纵向看:(a)组实验中改进后的网络可以解决原网络出现的漏检问题,(b)组实验说明改进后网络可以解决原网络出现的错检问题,(c)组实验表明改进后的网络可以使得预测框定位更加准确,改进后的网络提高了遥感图像的小目标识别率.
5 结 语
本文提出了在FPN模块上添加额外的自底向上、横向连接的路径改善低分辨率特征的性能,构造自顶向下和自底向上的特征金字塔网络,融合双向结合的金字塔特征层,并应用于遥感图像的目标检测,对网络的主要改进如下:首先网络层的第1个下采样层不利于保留更多的小目标位置信息,将第1个降采样层改为两个3×3的卷积层.其次,将YOLOv3三个不同尺度输出改为针对小目标输出的特征图,双向金字塔融合高低层次的特征用以检测小目标.然后采用1×1的卷积减少网络模型的维度,提高网络的检测速度.在VEDAI和NWPU VHR遥感车辆数据集上和最先进的YOLOv3网络做了定量和定性对比分析.结果表明,改进后的网络检测性能比原网络有了明显提高,网络的检测速度几乎没有改变.
猜你喜欢
环球时报(2022-09-19)2022-09-19
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
计算机应用与软件(2021年7期)2021-07-16
考试与评价·七年级版(2020年4期)2020-10-23
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
