
融合深度网络的改进快速生成超像素算法*
2020-12-15 08:13盛家川王佳媛李玉芝
计算机与生活 2020年12期
盛家川,王佳媛,李玉芝,王 君
1.天津财经大学理工学院,天津300222
2.天津财经大学管理科学与工程学院,天津300222
1 引言
超像素作为取代像素应用于视觉、图像处理等诸多领域的基本单元,一方面,使图像更易理解和分析,有利于图像在不同领域的后续研究;另一方面,通过给所有像素贴标签,使相同标签的像素组成的区域块具有相同的视觉效果,保护了图像的有效信息,且一般不会破坏图像中物体的边界信息。超像素不仅能降低将其作为特征向量和图元的各种图像分析以及计算机视觉任务中[1-4]的计算复杂度,而且由于超像素是通过对图像像素进行分组而生成的图像区域,因此可以计算图像的局部特征,减少后续图像处理所需图像原语的数量,提高计算效率。
计算超像素的算法主要有两大类,即基于图的方法和基于聚类的方法。其中基于图的方法将超像素分割公式化为图分割问题,但由于离散优化涉及离散变量,因此优化目标通常是不可微的,在基于图的方法中难以利用深度网络。而基于聚类的超像素算法最早是Achanta等人[5]基于Lloyd算法[6]提出的简单线性迭代聚类(simple linear iterative clustering,SLIC)算法,该算法利用CIELab颜色空间和像素位置组成的5维特征,将图像中的像素点通过聚类生成超像素。相比基于图的算法,SLIC能在较短时间内生成紧凑性和规则性相对较好的超像素。
受SLIC算法的启发,使用线性光谱聚类的超像素分割算法(superpixel segmentation using linear spectral clustering,LSC)[7]、优化加权核K-means聚类初始中心点的SLIC算法(SLIC algorithm based on optimizing initial center point of weighted kernelK-means clustering,WKK-SLIC)[8]等改变SLIC中像素的特征表示实现超像素分割。Wang等人[9]提出基于测地距离的结构敏感超像素(structure-sensitive superpixels,SSS)算法,该算法考虑了图像中的结构信息,利用几何流计算测地距离,但测地距离的高计算成本导致SSS算法效率低下。Liu等人[10]改进SLIC算法来计算内容敏感的超像素,但由于其映射、拆分和合并过程的成本导致运行速度不及SLIC。为解决以上问题,Zhao等人[11]提出快速线性迭代聚类(fast linear iterative clustering with active search,FLIC)算法,该算法时间成本低,但生成的超像素规则性相对较差。以上算法进行超像素分割时,均依赖手工提取的像素特征,导致算法的效率低、过程繁杂。为此,本文引入深度网络来提取更具代表性的深度像素特征。
目前,利用深度网络提取特征已被大量研究和应用[12]。例如Weimer等人[13]提出了用于工业检测中自动提取特征的深度卷积神经网络架构。张伟等人[14]通过深度卷积神经网络对中分辨率遥感影像进行特征提取和分类。最近,Jampani等人[15]充分利用深度网络提取的像素特征,提出超像素采样网络(superpixel sampling networks,SSN)算法。
由于现有的超像素算法主要基于手工提取的特征,所有直接将深层特征与现有的超像素算法结合在一起并不能获得更好的性能。为此,本文提出了融合深度网络的改进快速线性迭代聚类算法来实现超像素分割。主要贡献包括:(1)为了提高像素特征的提取效率,不同于现有超像素分割算法采用的手工提取的像素特征,本文提出将深度网络嵌入到超像素生成过程中,利用含多隐含层的深度网络进行像素特征的提取;(2)改进快速生成超像素算法[11]的初始种子点计算过程,以改善超像素分割结果。
2 相关工作
2.1 SLIC算法
SLIC算法对图像像素在五维空间中执行K-means聚类。相较于标准K-means算法的搜索范围,SLIC搜索种子点的2G×2G范围内的像素点进行距离的计算,其中,N为像素点个数。图像中任意两像素pi、pj的距离由颜色距离dc和空间距离ds共同决定,dc、ds计算如下:

其中,颜色空间由三维CIELab(li,ai,bi)值决定,ds由二维空间(xi,yi)值决定。
SLIC算法的时间复杂度仅为O(n),在处理高分辨率图像时可以减少时间复杂度,且分割的数目和边缘贴合度是可控的。但基于SLIC改进的算法大多忽略了相邻像素之间的关联性,且像素的分配和更新步骤分步执行,这导致像素标签更改的反馈延迟,所需的迭代次数较多。
2.2 卷积神经网络
近年来,深度学习已广泛应用于各种计算机视觉领域。目前大多文献将深度网络与已经生成的超像素结合进行研究。文献[16]提出了利用双边过滤器在不同比例上的加权组合BI(bilateral inception)模块的超像素卷积网络。文献[17]提出了用于显著目标检测的超像素卷积神经网络。文献[18]提出了一种用于像素语义场景标记的深度前馈神经网络架构。但是,现有文献没有将深度网络直接应用于超像素的生成过程当中,这主要有两大原因:一是构成大多数深度网络结构基础的标准卷积运算通常在规则的网格上进行定义,而在不规则的超像素网格上进行处理时效率低下;二是现有的超像素算法是不可微的,因此在深层网络中使用超像素会在端到端可训练网络体系结构中引入不可微模块。
3 融合深度网络的改进快速生成超像素算法
本文融合深度网络的改进快速生成超像素的算法过程如图1所示,主要由三大步骤组成:(1)深度网络提取图像像素的深度特征。本文使用卷积神经网络(convolutional neural networks,CNN)的局部连接性高效地提取图像像素特征,利用含有多隐含层的深度网络能够对原始输入数据做出更加深刻和本质的刻画,从而学习到更高级的数据特征。(2)K-means聚类计算初始种子点位置。以均匀生成的K个种子点为基础,执行一步K-means聚类,将更新后得到的一组新的种子点当作初始种子点。通过计算种子点与像素之间的距离确定像素标签,使每个种子中包含几乎相似的像素,即将具有相同特征的像素点包含在同一个超像素块内。(3)主动搜索确定像素标签。利用相邻像素点之间具有相邻连续性的特点,将像素标签的最终决定权由种子点决定改变为由像素点自主决定,以确保每个像素的标签正确。
3.1 深度网络提取图像像素的深度特征
为了能使从图像中提取的像素特征保留更多的边界信息,本文采用由一系列卷积层组成的CNN网络对图像中的像素进行特征提取。经过深度网络提取n-5维像素特征,结合输入图像像素的XYLab 5维像素特征,将最终所得n维像素特征传递给改进的快速线性迭代聚类算法以生成超像素。
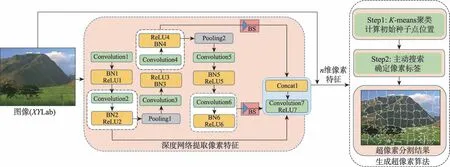
Fig.1 Overview of proposed algorithm图1 本文算法概述
图1所示深度网络中,加入批归一化层(batch normalization,BN)和ReLU(rectified linear units)激活函数以加快训练收敛的速度;在网络的第2层和第4层后加入最大池化层,以降低数据维度和过拟合概率,提升特征提取的鲁棒性;在整个过程中,BS(bilinear sampling)表示对第4和第6卷积层的输出进行双线性采样,白色框表示将第2、4、6卷积层的结果一起传递给蓝色框所示的最后一层卷积层;在每个卷积层上,使用3×3的卷积滤波器,除最后一层网络的输出通道数为n-5个以外,其余每层的输出通道数均设置为64,将得到的n-5个通道的输出与输入图像像素的XYLab 5维特征结合在一起,得到给定图像的n维像素特征。
在深度网络提取特征时,图像的位置和颜色特征权重分别用λpos和λcolor表示,其中λcolor与超像素的数量无关,本文默认设置为0.26;λpos受到超像素个数的影响,计算如下:
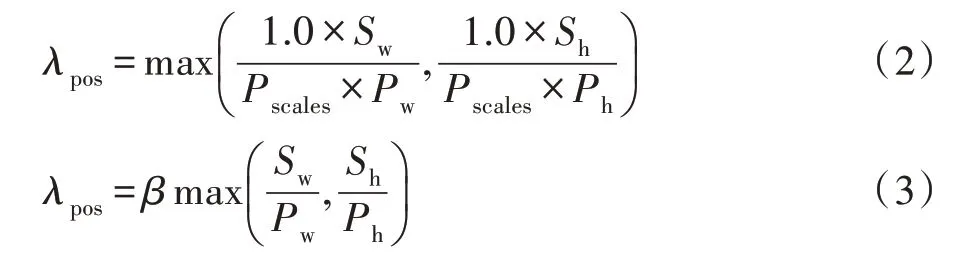
其中,本文实验取像素尺度Pscales=0.40,Sw和Sh分别表示沿着图像的宽度和高度方向所存在的超像素数量,Pw和Ph分别代表图像的宽度和高度,由式(2)可得参数,因此单个训练的深度网络模型可利用式(3)通过输入的位置特征λpos值,估计Sw、Sh所代表的图像的宽度和高度方向所存在的超像素的数量。在深度网络训练过程中,训练样本使用尺寸为201×201的图像且取超像素个数K为100。在对BSDS500[19]数据集进行数据扩充时,本文采用左右翻转以及对图像进行随机缩放的方式。训练过程均采用批量数为8,学习率为0.000 1的Adam随机优化[20]。对于训练模型,进行500 000次迭代,并根据验证精度选择最终训练模型。
3.2 改进的快速生成超像素算法
3.2.1 K -means聚类计算初始种子点位置
初始种子点的位置对超像素的分割结果有很大影响。本文改进FLIC算法[11],基于一步K-means聚类计算初始种子点位置。包含N个像素点的图像,每个像素pi=(li,ai,bi,xi,yi,Ni),其中(li,ai,bi)是CIELab颜色空间中的像素颜色向量,(xi,yi)是像素的坐标位置,Ni=[ni1ni2…niT]是从深层网络中提取的特征,T=n-5。首先在图像上均匀生成K个种子点,即图像被分割成包含K个元素的规则网格,步长为;基于K个均匀分布的种子点,执行一步K-means操作:为了避免均匀分布的种子点落在梯度较大的轮廓边界上,计算其3×3邻域内所有像素点的梯度值,将种子点移到该邻域内梯度最小的位置,然后在种子点的2G×2G范围内,指定像素pi的初始标签。再使用加权欧氏距离计算像素与种子点的距离,计算如下:
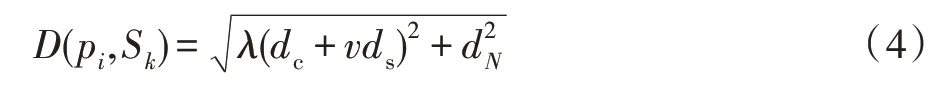
其中,Sk为种子点,dc和ds由式(1)计算所得,λ是控制图像像素初始XYLab特征的权重值,其取值介于0到1之间;v是控制空间距离权重的变量且,m为决定超像素紧凑性的变量,dN表示提取的深度像素特征的距离,计算如下:

每个像素点取最小距离对应的种子点作为该像素点的聚类中心,所有像素都归类完后重新得到K个超像素块,根据每个超像素块内包含的像素点重新计算种子点并更新种子点位置,以此获得本文算法的初始种子点。
本文算法中像素点的遍历顺序起着重要的作用,适当的扫描顺序可能会导致视觉上更好的分割。在确定种子点位置时,本文借鉴PatchMatch[21]提出的前后遍历顺序,对像素的处理也采用前后遍历的方法,即对一个超像素块,先从左至右在超像素块的上半部分进行扫描,此时超像素块顶部及其周围像素信息决定了像素的标签。同理再从右至左扫描超像素块的下半部分。前后遍历,使得后处理的像素受益于先处理的像素,对像素点周围的信息考虑更加全面,提高了计算效率,从而产生更好的超像素块。此外,由于在迭代过程中,每次生成的超像素块的形状并非完全规整,为了简化操作,将所有的超像素块补全为一块规整的最小矩形框,对最小矩形框内的所有像素进行遍历,若发生像素点的重新分配,则更新所对应超像素块的最小边界框,反之则不变。
3.2.2 主动搜索确定像素标签
在大多数自然图像中,相邻像素往往共享相同标签,即相邻像素具有自然连续性。因此,本文对像素点pi考虑相邻像素之间的关联信息,选择与该像素点近邻的4个像素,当近邻像素点中有与pi本身标签不同的,则计算pi与标签不同的像素所在种子点的距离,比较距离大小获取最短距离,确定新的标签。在这个过程中,每个像素点都是主动去寻找自己所属的超像素块,给自己赋予该超像素块所属的标签。如图2所示,Qi包含了像素pi及4个邻近像素点pi1、pi2、pi3、pi4。pi2和pi4的种子点为,pi1和pi3的种子点为。两个虚线框代表标签为Li和Lj的超像素块。d(i)为pi与自己所在超像素块种子点的距离,D为pi与不同标签的种子点的距离。对于每个像素pi,最终的标签是唯一的,即:

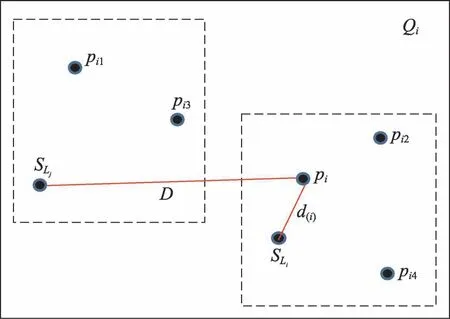
Fig.2 Active search to determine pixel labels图2 主动搜索确定像素标签
由于每个像素只能被分配给其至少一个邻近的超像素块中。因此,根据相邻像素可以直接确定该像素的标签,避免了额外计算与其他种子点的距离。选择邻近像素点有3个优点:(1)考虑到了相邻像素点的局部连续性,充分利用了先验信息,有助于后续操作的像素点在分配过程中做出更好的选择;(2)加快了确定像素标签的速度;(3)保证了超像素块的数量,在一定程度上可以避免大量孤立区域的产生。像素点在主动搜索所属标签过程中,超像素种子点也在自适应地进行位置变动。值得注意的是,超像素块内部像素的邻域通常共享相同的标签,因此不再需要处理它们。这一事实促使非常迅速地处理每个超像素块。
在确定像素标签时,如果像素的标签发生改变,则需要对像素重新分配标签以及信息的更新操作。分配和更新的分步进行通常需要5次以上的迭代次数,这成为快速收敛的瓶颈。因此本文基于式(6)所示的分配原则,采用将分配与更新操作“捆绑式”进行的方法,通过实验发现,本文算法在2次迭代之后就能达到收敛。“捆绑式”操作指像素pi的标签从Li变为Lj后,紧接着要进行更新操作,即对进行如下更新:

其中,|ψLi|表示超像素ψ里的像素数量。对也进行更新,如下:

4 实验结果与分析
4.1 实验平台、数据集和评估指标
实验平台:本文算法运行的操作系统为Windows 10,Intel®Core™i5-3210M,4.0 GHz。本文编程环境包括VS2013、Anaconda2(Python2.7),实验使用带Python接口的caffe框架。
数据集:本文所使用的数据集为公开的Berkeley图像分割BSDS500基准数据集,包括500幅321×481的自然图像,其中有200幅训练图像,100幅验证图像以及200幅测试图像。每个图像都用来自多个注释器的GT(ground-truth)段进行注释。
评估指标:本文对不同算法在三方面进行了对比:其一为对于固定比例数据集的最佳F-measure(optimal dataset scale,ODS);其二为数据集上的F-measure,以获得每个图像的最佳比例(optimal image scale,OIS);其三为全召回范围内的平均精度(average precision,AP)。图3显示了在BSDS500数据集上不同超像素分割算法的Precision-Recall曲线,其中弧线代表Iso-F曲线,,圆点表示人手工标定的GT的平均值。

Fig.3 Precision-Recall curves of algorithms on BSDS500 dataset图3 BSDS500数据集上算法的Precision-Recall曲线
4.2 相关参数设置
本文方法在初始需要设置3个参数:其一是期望的超像素数量K。基于聚类的超像素分割算法的一个共同优点是通过设置聚类参数K,可以直接获得期望的超像素数。其二为最大迭代次数itr,本文采用分配与更新“捆绑式”操作的方法,打破了执行分开操作时通常超过5次迭代的瓶颈,通过实验发现,本文算法在2次迭代后就能达到收敛,因此本文设置itr=2为默认值。其三是空间距离权重m,其取值范围在[1,40]之间。
4.3 实验结果
本文算法将与LSC[7]、FLIC[11]、SSN[15]进行比较。其中LSC基于均匀生成的K个初始种子点,改变像素的特征表示实现超像素分割;FLIC在SLIC算法的初始种子点的基础上进行了主动搜索操作以提高生成超像素的效率;而本文是在均匀生成的K个种子点基础上,执行一步K-means聚类得到本文算法的初始种子点,并且在此基础上进行主动搜索操作。如表1所示为不同算法在BSDS500数据集上所得结果的ODS、OIS、AP值。对比其他算法,本文算法生成的区域边界与GT匹配程度优于其他算法。
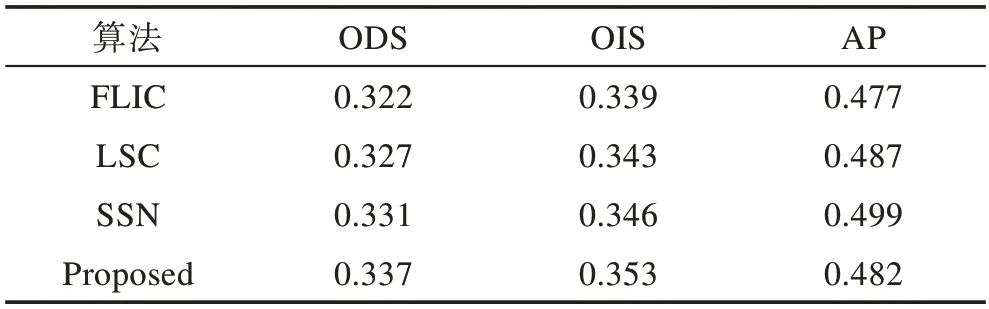
Table 1 Comparison on BSDS500 dataset表1 BSDS500数据集上的比较
如图4所示为不同算法得到的超像素分割结果,与其他算法相比,本文算法所得超像素分割结果表现良好,在保持良好边界性的同时产生形状更规则的超像素。而在计算机视觉任务中恰好需要的是具有良好边界的超像素。此外,图5、图6展示了对参数取不同值时的超像素分割结果。图5为不同算法在K取200情况下,m分别取5,10,20得到的超像素分割结果,参数m影响超像素的平滑性和紧凑性,当m取值较小的时候,超像素的规则性较差但同时超像素对边界的粘附性较强;当m取值偏大时,超像素变得更加紧凑、规则。图6为不同算法取m=20时,超像素个数K分别为100,200,400的超像素结果,由此所得的超像素很好地粘附在区域边界上。

Fig.4 Superpixel segmentation results of different algorithms(K=100, m=10)图4 不同算法超像素分割结果(K=100,m=10)

Fig.5 Superpixel segmentation results of different algorithms(K=200,m=5,10,20)图5 不同算法超像素分割结果(K=200,m=5,10,20)
5 结束语
本文提出了一种融合深度网络的改进快速生成超像素算法。该算法将深度网络嵌入到超像素生成过程当中,基于深度学习网络对图像进行像素的深度特征提取;优化初始种子点位置的计算过程,以改善超像素分割结果。一方面,相比依赖手工提取的图像像素特征,CNN架构高效且使用CNN网络提取到的像素特征进行后续的超像素分割有助于超像素分割结果在紧凑性、规则性等方面得到提升;另一方面,采用改进的快速线性迭代聚类算法,减少了主动搜索的计算量,且充分利用局部连续性,使复杂的低对比度图像也能具有良好的边界灵敏度,从而提高了图像的分割性能。
超像素被广泛应用在计算机视觉以及图像处理领域。高效地生成超像素在视觉和图像处理研究中具有重要的应用价值,因此本文研究成果有助于视觉和图像处理领域的研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
现代电子技术(2021年1期)2021-01-17
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
红领巾·萌芽(2019年8期)2019-08-27
现代电子技术(2018年18期)2018-09-12
电脑知识与技术(2018年35期)2018-02-27
科学家(2017年12期)2017-08-10
