
毫米波网络中基于Q-Learning的阻塞感知功率分配
2020-12-16 02:42孙长印
计算机工程 2020年12期
施 钊,孙长印,江 帆
(西安邮电大学 通信与信息工程学院,西安 710121)
0 概述
在移动通信领域,频谱资源是承载无线业务的基础,是推动产业发展的核心资源。目前低于6 GHz的频谱几乎已经被分配殆尽,而6 GHz以上的频谱资源非常丰富,由于其业务划分与使用相对简单,能够提供连续的大带宽频带,因此已成为一种具有前景的替代方案[1]。其中,高频段的毫米波(millimeter-Wave,mm-Wave)通信更被认为是一种有效解决无线电频谱稀缺问题的方法,将会为未来无线蜂窝网络提供显著的容量增益[2-4]。
目前,毫米波频段将用于5G移动通信网络已成为全球共识。在毫米波频率下可提供的大带宽有可能将网络吞吐量提高10倍[3]。但是其面临的信号衰耗大、覆盖距离短和通信链路对阻塞敏感等问题也不可忽视[5]。克服这些问题的一种有效方法是增加接入点的密度[6-7],但是随着接入点密度的增加,当所有毫米波基站重用相同的时频资源时,小区间干扰会越来越严重,网络管理的复杂度也越来越高[8-9],这将极大地限制毫米波小区的系统容量。对于毫米波信号衰耗大、覆盖距离短的问题,可以通过波束成形技术进行最优波束对准,提高系统和速率。对于毫米波通信链路高阻塞问题,现场测量结果[3]表明,由于各种因素(如基站与其服务用户之间的距离远近、不同障碍物阻挡等)引起的阻塞,毫米波链路的可用性可能是高度间歇性的,这进一步恶化了超密集网络由于复杂干扰导致的无线环境,对保证用户业务质量带来严重挑战。
针对上述问题,研究者提出较多解决方案。文献[8]通过使用Q-Learning算法,提出一种基于簇的分布式功率分配方案(Cluster based Distributed Power allocation using Q-Learning,CDP-Q)。该算法提升了系统容量,可满足所有用户所需的服务质量(Quality of Service,QoS),但未考虑毫米波通信的链路阻塞问题。文献[10]方法通过协作Q-Learning算法来最大化毫微微蜂窝总容量,同时保证宏蜂窝用户的容量水平。文献[11]提出一种基于Q-Learning的下行链路容量优化资源调度方案,在保持宏小区用户和毫微微小区用户之间公平性的同时,提高小区边缘用户的吞吐量。然而,在文献[10-11]中,毫微微用户的QoS均未被考虑。文献[12]考虑了毫米波多跳通信以克服链路阻塞,在直视路径被障碍物阻断时,通过中继器绕开障碍物来提高可靠性,但这需要足够高的节点密度以确保有合适的中继节点可用。文献[13]提出一种用于链路和中继选择的联合优化算法。考虑到包括反射路径的链接的阻塞概率,该算法选择的链接将预期的交付时间最小化,但并未考虑多路径的联合使用,并且在基站用户随机分布机制下,一条路径被阻塞时则需切换路径,这种切换机制会引入额外的等待时间。文献[14]建立一种基于波束的模型来评估毫米波覆盖概率,其不仅考虑视距传输,而且还考虑了一阶反射径的影响。在非视距情况下,反射径能够显著提高覆盖率,但该模型未考虑系统容量的影响。
本文针对毫米波通信链路高阻塞可能引起中断的问题,提出一种基于Q-Learning算法的功率分配方案。通过对链路阻塞问题进行分析,指出链路阻塞造成的影响有利有弊,因为链路阻塞有可能中断有用信号,同时也可能会中断干扰信号,其与基站、用户的随机分布以及周围环境等因素有关。在此基础上,将链路阻塞因素引入最优功率分配问题求解模型,借助利己利他策略[15]对利弊情况区别对待,并利用Q-Learning算法学习训练利己利他最佳策略,从而减小干扰,提升系统总容量,同时为用户提供所需QoS。
1 单智能体的Q-Learning算法
本节通过简单案例介绍Q-Learning算法的基本概念[16]。Q-Learning是一种无模型的强化学习方法,其主要解决的问题是:一个能够感知环境的智能体,通过与环境的交互反复学习,以状态为行,以行为为列构建一张Q表来存储Q值,根据Q值选取能够获得最大收益的动作。本文将此问题模型看作是马尔科夫决策过程(Markov Decision Process,MDP)[17-18]。将MDP记为(A,S,Rt,St+1)元组,其包含以下元素:
1)智能体:执行学习行为并与环境交互的行为主体。
2)A={a1,a2,…,an}:一组智能体可能采取的有限的动作集合。
3)S={s1,s2,…,sn}:一组有限的状态集合。基于t时刻的状态st,智能体选择动作at∈A。
4)Rt=r(st,at):智能体在t时刻、状态st下执行特定动作at后的回报值函数,反映该动作的好坏,从而确定下一状态St+1=Φ(st,at)。
5)St+1:奖励被反馈给智能体,从而确定下一状态St+1,并重复该过程,直至Q表不再有更新或者达到设定的收敛条件。
首先假定智能体处在某一环境下,并且它可以感知周边的环境。其中,元素Q(st,at)就是在t时刻、st(st∈S)状态下采取动作at(at∈A)所得到的最大累积回报值。
显然,策略的好坏不是由一次学习过程的回报值所决定的,而是由长时间累积的回报值来决定,因此,定义评估函数为:
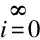
(1)
式(1)表示的是从初始状态st不断通过执行策略π进行学习获得的累积回报值,其中,γ是折扣因子,γ∈[0,1],通过调节γ,可以控制后续回报值对累积回报值的影响,γ接近0表示智能体只在乎眼前的利益,做出的行为是为了最大化眼前的奖励,γ接近1时表示智能体更看重长远的利益,目的是使Vπ(st)最大化。
根据式(1)可以得出最佳策略π*为:
(2)
式(2)表示对于所有的状态集合,使用策略π*可使累积回报值Vπ(s)达到最大。但在实际系统中,直接学习最佳策略π*是不切实际的[19]。使用评估函数来判断动作的优劣更切合实际,评估函数定义如下:
Q(s,a)=r(s,a)+γV*(Φ(s,a))
(3)
由Vπ*(s)的定义和式(2)、式(3)可以得出:
(4)
将式(4)代入式(3)可得:

(5)


(6)
为控制之前学习效果对整体的影响,引入学习因子α(α∈[0,1]),其值接近0时表示几乎不再进行新的学习,而接近1时表示更看重当前的学习效果,而且学习因子会影响Q-Learning算法收敛的速度。因此,Q函数更新为:

γ(Φ(s,a),a′)-Q(s,a)}=
(1-α)Q(s,a)+α{r(s,a)+
γ(Φ(s,a),a′)}
(7)
文献[16]证明了这种更新规则在某些条件下可以收敛到最优Q值,其中一个条件是每个状态-动作对必须进行无限次访问。如上所述,Q-Learning在学习中获得奖励Rt,更新自己的Q值,并利用当前Q值来指导下一步的行动,在下一步的行动获得回馈值之后再更新Q值,不断重复迭代直至收敛。在此过程中,在已得到当前Q表的情况下,如何选择下一步的行为对完善当前Q表最有利,即如何对探索和利用进行折中最为重要。为此,本文引入一个随机因子ε来调节智能体进行学习的折中考虑,从而搜索到全局最优值并快速达到收敛。
由上述背景介绍可知,单智能体强化学习所在环境是稳定不变的,通常使用MDP来建模求解。然而,在多智能体系统中[20],每个智能体通过与环境进行交互获取奖励值来学习改善自己的决策,从而获得该环境下的最优策略。在多智能体强化学习中,环境是复杂的、动态的,这给学习过程带来很大困难。相比之下,对于单智能体面临的维度爆炸、目标奖励确定困难及不稳定性等问题,通常使用随机博弈来建模求解。本文考虑这两种方案的特点,针对网络模型随机分布即适合分布式解决方案的特性,选择单智能体解决方案。
2 系统模型与问题描述
2.1 系统模型
本文基于5G典型场景之一的密集室外城市场景,考虑密集部署的毫米波基站下行链路。在网络结构上,假设毫米波基站位置遵循基于密度λBS的泊松簇过程(Poisson Cluster Process,PCP)[21-22]。PCP在实践中也被称为父子建模过程,其包含一个父过程和一个子过程,父过程形成簇的中心,子过程围绕父过程分布在簇中心一定的范围。本文假设共有M个簇,每个簇有N个毫米波基站,每个基站仅服务一个用户,用户以基站为中心、以h为半径随机抛洒,且每个基站天线数为NT、用户天线数为NR。假设单个小区边缘用户与其相关联基站之间的距离大于设定界点距离d时有一定的概率会导致中断,此时用户的QoS会受影响,同时假定目标用户在整个操作过程中保持静止。
假设本文基站和用户之间的信道模型为毫米波信道,基站i和用户k之间的信道可以记为:Ii,k(d)×Hi,k。其中,Ii,k(d)是0-1布尔变量,表示基站i和用户k之间的通信链路是否正常[23],d为设定的毫米波动态链路高阻塞引起链路中断概率的界点距离。用PI(x)表示Ii,k(d)链路是否正常的概率。将毫米波基站与其相关联用户之间基于2D距离x的可视线概率记为PI(x),其由3GPP城市微街道峡谷模型[24]获得,如式(8)所示:
(8)
其中,xi,k为当前毫米波基站i与其关联用户k之间的2D距离,当x≤d时,表示一定可视,链路无阻塞;当x>d时,表示有概率不可视,链路有概率被阻塞。
Li,k表示基站i和用户k之间的路径损耗,路径损耗Li,k如式(9)所示:
Li,k=β1+10β2lgxi,k+Xζ
(9)
其中,β1和β2是用于实现最佳拟合信道测量因子,xi,k为当前毫米波基站i与其关联用户k之间的2D距离,Xζ~Ν(0,ζ2)表示对数阴影衰落因子。
此时第k个用户的信干噪比(Signal to Interference plus Noise Ratio,SINR)为:
(10)
Pk=10(Pk′-Lk,k)/10
(11)
其中,Pk为第k个基站发送到其服务用户k的实际功率,Pk′为Q-Learning算法中基站k选定某一状态所执行的行为(功率),Lk,k为基站k到用户k之间的路损,Dk为干扰基站的集合,σ2表示加性高斯白噪声方差。因此,第Pk(Pk=Pk′-Lk,k)个用户的归一化容量为:
Ck=lb(1+SINRk)
(12)
2.2 问题描述
本文旨在毫米波基站之间寻找最优功率分配,为此,首先建立最大化问题模型,然后通过问题求解使系统总容量最大化,同时满足所有用户的QoS和功率约束。本文优化问题(P1)可以表述为:
(13)
s.t.
Pk≤Pmax,k=1,2,…,N
(14)
SINRk≥qk,k=1,2,…,N
(15)
其中:目标函数(式(13))表示最大化网络总容量;M为系统模型中划分簇的个数;N表示划分的每个簇内的毫米波基站的数量;约束条件(式(14))指的是每个毫米波基站的功率限制,表示从每个毫米波基站分配给用户的功率不能超过最大功率Pmax;式(15)中的qk表示第k个用户所需的最小SINR值,称为阈值。P1优化问题为:在使整个系统总容量最大的同时要满足每个用户所需的QoS。
由于P1优化问题中SINR项的分母包含干扰项,而在毫米波通信网络中,干扰复杂不可忽略,因此,究其本质为一个耦合问题,此类优化问题是一个非凹函数,无法直接求解。传统的启发式方案所求得的仅为次优策略,与最优解误差较大。而本文所要解决的是一个耦合问题,再加上考虑到毫米波链路阻塞特性导致的0-1布尔问题,使得P1更加难以解决,因此,本文考虑使用Q-Learning算法来解决此问题。
本文设计的P1的解决方案还具有以下特征:
1)由于设定场景为密集室外城市场景,毫米波基站和用户数量众多,干扰复杂多样,没有行之有效的中心管理机构,因此本文以分布式结构来处理。
2)毫米波通信虽然带来了显著的容量增益,但其信号衰耗大、辐射范围有限,因此,合理假设只有距离接近的毫米波基站彼此干扰。可使用聚类机制将设定场景中的基站划分为多个集群,其中一个集群的干扰对其他集群的用户来说可以忽略不计。
3 PPCP-Q分配方案
本节介绍PCP网络模型下基于Q-Learning算法的功率分配方案PPCP-Q。与其他强化学习算法相比,Q-Learning算法在复杂系统中具有非常好的学习性能。同时PCP还具有叠加性、稀释性和映象性[19]等特性,非常适应毫米波网络的复杂结构以及网络环境的动态变化,因此,本文采用PPCP-Q方案进行功率分配。PPCP-Q算法分为PCP聚类和基于Q-Learning的分布式功率分配两个部分。
3.1 毫米波基站的泊松簇过程
本文考虑系统模型具有分布式特性以及毫米波通信信号损耗大和覆盖范围较小的特性,假定在应用场景中只有距离靠近的毫米波基站之间彼此干扰。本文基于PCP假设将毫米波基站划分为簇,PCP过程是一种分布式聚类方法,并可生成非重叠簇。为具体说明其过程,给出以下定义:
1)簇头。基于PCP产生簇头,在本文中,被选定为簇头的毫米波基站与簇内其余毫米波基站之间没有优先级之分。
2)入簇(In Cluster,IC)和簇外(Out Cluster,OC)节点。在PCP中,将IC距离定义为100 m,这是强干扰的表示。OC距离定义为200 m,其表示簇头周围簇的边缘覆盖范围。若a点距某一簇头在100 m范围之内则定义为IC;若a点处于此簇的OC距离(即大于100 m小于200 m的范围),而此时又不属于任何其他簇的IC距离,则将a点作为OC节点加入此簇;若a点距离多个簇头的距离相同,此时随机选择一个簇加入即可。
3.2 基于Q-Learning的分布式功率分配
Q-Learning算法是强化学习的典型方法之一,已被证明具有收敛性。在PPCP-Q算法中,毫米波基站被认为是Q-Learning算法的智能体。PPCP-Q是一种分布式方法,其中多个智能体旨在通过反复与环境交互来发现最佳策略(功率)以最大化网络容量。
在多智能体的学习中,智能体可以合作学习(Cooperative Learning,CL)或独立学习(Independent learning,IL)。在CL中,当前智能体与其他合作智能体共享其Q表。在IL中,每个智能体独立于其他智能体学习(即将其他智能体视为环境的一部分,忽略其行为),虽然这可能导致算法收敛时间变长,但与CL相比,智能体之间没有通信开销,因此,本文选择IL。PPCP-Q算法描述如下:
算法1PPCP-Q算法
输入状态集合,动作集合,学习因子α,折扣因子γ
输出Q表
2.基于3.1节泊松簇过程对系统模型进行分簇
3.for所有簇
4.for每一个簇内智能体(毫米波基站)
5.for每一个智能体的训练次数episode
7.生成一个0~1之间的随机数sigma
8.if sigma<ε
9.ε=ε×0.99
11.else

13.end
16.根据式(7)更新Q表
18.end for
19.end for
20.end for
Q-Learning算法的输出为分配的功率,被表示为Q函数,智能体的Q函数被称为Q表,其中行是状态,列是行为(功率)。在Q-Learning算法中,行为、状态和回报函数定义如下:
1)行为。每个智能体可执行的动作是簇内毫米波基站可以使用的一组可能的功率。在仿真中,行为(分配的功率)集合A定义为A={a1,a2,…,an},它均匀地覆盖了最小功率(a1=Pmin)和最大功率(an=Pmax)之间的范围,步长为1 dBm。

(16)
其中,i,k=1,2,…,N。xi,k小于等于设定的界点距离d表示链路正常通信,此时为状态0;xi,k大于d表示有概率导致链路中断,此时为状态1。
选择一个簇,即A1、A2,利己利他策略应用示意图如图1所示。

图1 利己利他策略示意图Fig.1 Schematic diagram of egoistic and altruistic strategy
根据基站i与用户k之间的2D距离xi,k,智能体在时刻t的状态可分为以下3种情况:
情况1基站1与服务用户1链路阻塞,基站1与被干扰用户2、用户3链路正常,即有用信号发生阻塞,用户1考虑利他功率分配策略,此时应最小化发射功率,避免对其他用户干扰。
情况2基站2及其服务用户2链路正常,基站2与用户1链路正常,与用户3链路中断,即部分被干扰用户链路阻塞,此时应考虑利己利他功率分配策略,即按功率等级适量发射功率,均衡干扰同时提升系统容量。
情况3基站3及其服务用户3链路正常,基站3与用户1、用户2链路中断,即用户3所产生干扰信号完全阻塞,此时应考虑利己功率分配策略,最大化发射功率,提升系统容量。
(17)
其中,k=1,2,…,N,A1和A2分别为10 dBm和5 dBm。
3)回报函数。本文优化问题P1旨在最大化系统总容量,同时满足用户所需的QoS。回报函数的设计基于优化目标,反映环境对智能体选择动作的满意程度。回报函数定义如下:
(18)

(19)

回报函数的基本原理如下:
1)只有当环境中毫米波基站最小和速率gt大于等于G倍的阈值时,才能得到一个正的回报值,否则回报值为负值。
2)因为(Ct-Glb(1+qk))/Ct<1,并且Ct越大,该值越大,所以系统吞吐量越大,对应回报值也越大。
此外,在学习过程中,需要设置一个随机因子ε来调节智能体进行随机学习的比例,本文假设随机因子ε的初值为0.9,且智能体每进行一次随机学习,该值就更新为原值的0.99倍。基于此设置,智能体在初始学习时会频繁地进行随机学习,随着学习次数的增加和学习经验的累积,随机因子的值会逐渐趋近于0,此时智能体会进行经验学习,选择每一步的最优策略并快速达到收敛。
4 仿真与结果分析
本节对构建的系统模型进行系统级仿真,仿真程序在Matlab环境下实现,以证明本文方案的有效性。
4.1 仿真环境与参数设置
考虑密集部署的毫米波基站的下行链路网络,在1 km2的区域内分布2个~16个簇。簇头基于泊松过程生成,每个簇内基于半径R范围随机分布N(N=5)个成员基站,依据成员基站与簇头距离再划分成员基站不重叠簇的归属。簇头与簇内成员之间没有优先级之分,且簇与簇之间相互独立。簇内每个基站基于半径h随机抛洒一个用户,即每个基站支持一个用户。用户的QoS被定义为支持用户服务所需的最低SINR,所有用户均考虑阈值qk=10 dB。在Q-Learning算法中,学习率为α,折扣因子为γ,最大迭代次数被设置为50 000次。其他仿真参数如表1所示。

表1 仿真参数Table 1 Simulation parameters
4.2 结果分析
本文基于PCP设定的系统模型基站和用户的分布情况如图2所示,图中以不同形状分别表示簇头、簇内毫米波基站和相关联的用户。

图2 PCP模型基站与用户分布Fig.2 BSs and users distribution of PCP model
图3所示为本文方案某个智能体在学习动作上的收敛情况。由于PPCP-Q方案考虑阻塞概率,使系统更加动态化,因此引入随机因子ε对探索和利用进行折中考量,调节智能体进行随机学习的比例,选择集体最优而非单次最优的一串最优动作。随着ε的值逐渐趋近于0,智能体会进行经验学习,加快收敛速度。从图3中可以看出,在前3 000次学习中,智能体进行了大量的随机动作选择,但是随着迭代次数的增加,设定的随机因子在逐渐减小,在3 000次~9 000次学习过程中随机的动作次数逐渐减小,在9 000次学习之后,智能体在学习过程中动作的选择逐渐达到收敛状态。

图3 Q-Learning算法动作收敛情况Fig.3 Action convergence of Q-Learning algorithm
将本文PPCP-Q方案与文献[8]的CDP-Q方案进行比较,如图4所示。可以看出,对于多种可能簇的大小,2种方案在系统总容量上的取值均超过阈值,均满足用户所需的QoS。图5为PPCP-Q与CDP-Q两种方案系统容量的CDF曲线对比。可以看出,PPCP-Q方案相较于CDP-Q方案提供了较为明显的系统容量增益。增益机理分析如下:PPCP-Q方案考虑到毫米波链路可用性是高间歇性的,同时在Q-Learning算法状态和回报函数设计中加入利己利他策略来求解目标函数,对有利有害情况区别对待并加以利用,在减小干扰的同时合理分配功率以最大化系统容量,同时满足用户的QoS。而文献[8]的CDP-Q方案基于Q-Learning算法来训练智能体分配功率,其采用利己分配策略,但未根据毫米波通信链路阻塞特性施加不同功率分配策略,所以在系统性能角度上,其增益受到限制。总体而言,本文方案显著提升了系统容量,而且随着簇的个数增多,性能优势更为明显。

图4 多簇情况下两种方案的系统总容量对比Fig.4 Comparison of the total capacity of two schemesin the case of multiple clusters

图5 两种方案的系统容量CDF曲线对比Fig.5 Comparison of system capacity CDF curve of two schemes
5 结束语
随着多媒体应用的不断发展和移动流量的爆炸式增长,5G网络中基站部署日趋密集,使毫米波通信在解决频谱资源短缺和提升系统性能的同时也面临高阻塞、大衰落和干扰复杂多变等问题,影响了毫米波链路的可用性,而且基站用户随机分布,无规律可循,使得功率分配问题更为复杂。对此,本文提出一种基于Q-Learning的功率分配方案。以毫米波基站为智能体,在状态和回报函数设计中加入利己利他策略,考虑多种可能的链路阻塞情况,充分利用功率资源以最大化系统容量,同时保证用户的QoS。仿真结果表明,本文方案能够提升系统性能,实现优化目标。由于Q-Learning算法在状态和行为设计上维度有限,因此下一步将考虑利用深度神经网络改进该方案,并通过添加更多指标,同时实现多个系统优化目标,提升系统的整体性能。
猜你喜欢
移动通信(2021年5期)2021-10-25
发明与创新·小学生(2020年4期)2020-08-14
空间科学学报(2020年3期)2020-07-24
学生天地(2017年19期)2017-11-06
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
发明与创新·小学生(2016年4期)2016-08-04
中国交通信息化(2016年8期)2016-06-06
移动通信(2015年17期)2015-08-24
中国交通信息化(2014年3期)2014-06-05
