
基于深度学习的卷烟牌号识别方法
2020-12-22 13:59陈智斌农英雄梁冬孙忱韦屹钟征燕
烟草科技 2020年12期
陈智斌,农英雄,梁冬,孙忱,韦屹,钟征燕
广西中烟工业有限责任公司信息中心,南宁市西乡塘区北湖南路28号530001
在烟草行业,卷烟零售数据是烟草企业非常重视的数据信息。通过采集和分析零售户的卷烟零售数据,可以获知零售户、片区的销售趋势,用于指导品牌规格投放,从而提高烟草企业经营管理水平。然而传统的卷烟零售数据采集技术,无论是依赖于市场人员到零售户处进行采集,还是布设POS系统要求零售户扫码记录,均容易出现漏报、瞒报等问题,准确性和覆盖性不强,进而导致卷烟零售数据质量欠佳,亟需建立卷烟零售数据自动化采集系统。自动化采集系统的核心是卷烟牌号的正确识别。为了在数据采集过程中不干扰传统购烟流程,因此需结合卷烟零售店实际场景设计一种能准确识别卷烟牌号的方法。目前,图像识别技术是物体识别的主流技术,能够实现较高的准确率,在烟草行业有较多的研究与应用。涂勇涛等[1]、翁迅等[2]、冯春等[3]、颜西斌[4]、曹冬梅等[5]均对条烟识别开展了研究,条烟识别的准确率和效率已取得较大提升,可基本满足工业化自动生产线的需求,但这些算法需要特殊的设备或者光源条件才能保证较好的识别准确率,而这种条件在实际零售场景中难以具备。王鹏[6]提出了一种基于OCR视觉技术的烟箱品牌识别技术,但该方法要求的识别条件过于严格,实际场景中识别效率不高。谢志峰等[7]提出一种烟码智能识别方法,可以实现烟码的快速识别,但其识别准确率易受烟码图像倾斜角度的影响,鲁棒性较弱。总体上看,现有算法难以满足卷烟零售场景下卷烟牌号识别的需求。近年来,深度学习技术在图像识别领域得到快速应用[8],其识别准确率、鲁棒性较传统的图像识别方法有较大提升,在各类图像识别的竞赛任务中均有优异表现。因此,提出了一种基于深度学习的卷烟牌号识别方法,以期满足卷烟零售数据自动化采集过程中准确识别卷烟牌号的需求。
1 总体设计
1.1 系统结构
卷烟牌号识别硬件系统主要由高清彩色摄像头和工控机组成,其中摄像头具备10倍变焦能力,可保证摄像头安装在4 m的高度内通过调节参数来获取清晰的图片;工控机配备1080 Ti显卡,满足深度学习算法对计算资源的需求。结合卷烟零售店实际场景,通过分析消费者的购烟流程可知,消费者的购烟过程离不开结算环节,而此环节发生在结算台位置区域。为了不改变原有购烟流程并减少摄像头对消费者的干扰,将摄像头安装在结算台正上方,把结算台作为卷烟牌号识别区域,当店员将卷烟放到结算台时进行卷烟牌号识别,系统结构见图1。
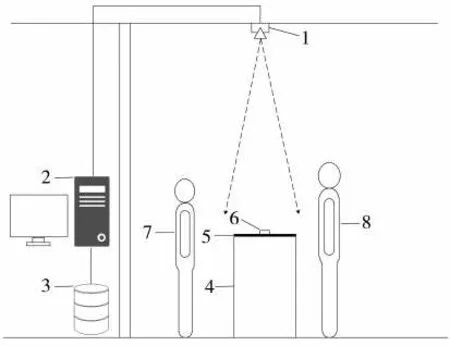
图1卷烟牌号识别系统结构图Fig.1 Structure of cigarette brand recognition system
1.2 技术路线
将卷烟牌号识别方法分成卷烟检测、卷烟姿态矫正、卷烟特征提取和卷烟特征检索4个部分,其中:卷烟检测算法是基于CenterNet思想设计的检测模型,负责检测卷烟在图像中的位置和姿态,其他物体都认为是背景;卷烟姿态矫正算法通过射影变换矫正卷烟姿态,生成卷烟的正向图像;卷烟特征提取算法采用Darknet53作为特征提取网络,负责提取卷烟正向图像的特征;卷烟特征检索算法通过欧式距离阈值从卷烟特征库中检索出与当前特征对应的卷烟特征和牌号信息,核心技术路线如图2所示。

图2卷烟牌号识别方法技术路线图Fig.2 Roadmap of cigarette brand recognition method
2 算法设计
2.1 卷烟检测
深度学习常用的目标检测框架有Faster RCNN、SSD系 列、YOLO系 列 和CenterNet等,其中Faster RCNN算法的优点是目标检测精确度高,但缺点是检测时间过长,难以满足实时性要求[9];SSD系列和YOLO系列都是端到端的目标检测算法,其检测速度相比Faster RCNN有较大提升,且精度下降较少,可以在精度和实时性之间实现较好的平衡[10-11];而CenterNet是新一代目标检测框架,其将目标检测任务视为一种关键点估计任务,并可用于3D检测和人体姿态估计等多种任务中,具备良好的通用性,且相比SSD和YOLO有更好的检测精度和实时性[12]。因此,为更好地实现卷烟的位置和姿态检测,基于CenterNet设计卷烟检测算法。
2.1.1 卷烟检测定义
卷烟检测任务包含卷烟的位置检测和姿态检测,其中位置检测输出卷烟的中心点位置pc(xc,yc)和卷烟包围框的高度h与宽度w;姿态检测输出每盒卷烟4个角点的位置,分别为p1(x1,y1),p2(x2,y2),p3(x3,y3),p4(x4,y4),其 中x1≥x2≥x3≥x4,卷 烟 检 测 实 例 如 图3a所示。在卷烟检测中,卷烟姿态信息具有重要作用,通过姿态矫正可以减少图像背景或者其他卷烟局部图像的干扰。如在图3b中,由于两盒卷烟靠得较近,如果只有卷烟位置检测,那么卷烟检测框中互相包含了相邻卷烟图像的一部分,将这些图像直接送入卷烟特征提取网络,易给卷烟特征提取网络带来二义性,不利于提升识别准确率。

图3卷烟检测实例Fig.3 Example of cigarette brand detection
2.1.2 卷烟检测算法设计
假设图像的输入为I∈RW×H×3,其中W和H是图像的宽度和高度。令为卷烟位置检测输出的卷烟中心点热力图,其中T是热力图的步长,此处采用表示在坐标(x,y)处检测到卷烟中心点,而则 表 示 背 景。对于每盒卷烟的Ground Truth中心点p∈R2,计算p在热力图的坐标点并采用高斯核Yxy=在热力图上生成所有中心点的高斯分布,以此作为Ground Truth热力图。其中σp是目标尺寸自适应的标准差,当1个坐标点有多个中心点产生的高斯分布值时,选择最大的值作为该点的值。中心点热力图的训练目标是实现像素级的逻辑回归,损失函数采用focal loss,其损失值Lk如式(1)所示。其中α和β是超参数,此处使用α=2,β=4,N为输入图像中含有的中心点数量。
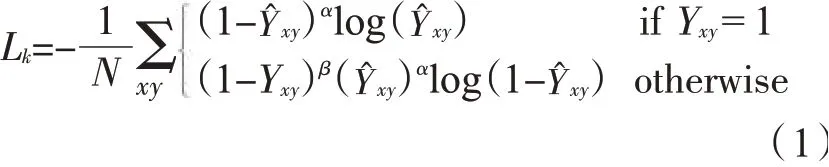
中心点坐标在下采样的过程中产生了离散误差,为弥补该离散误差,需另外预测每个中心点的局部偏移量损失函数采用L1,其损失值Loff如式(2)所示。其中为在中心点预测的局部偏移量为下采样时产生的真实离散误差。
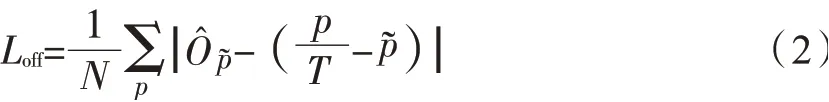

卷烟姿态检测将卷烟4个角点的位置估计转化成角点对中心点偏移量的估计。令为第k个卷烟的4个角点,中心点坐标为则4个角点相对中心点的偏移量在预测卷烟中心点位置的基础上,增加预测卷烟4个角点相对中心点的偏移量损失函数采用L1,其损失值Lc如式(4)所示。
为了更加精确定位卷烟角点的位置,可进一步预测卷烟角点的热力图和每个卷烟角点的局部偏移量与卷烟中心点预测方法类似,令卷烟角点热力图的损失值为Lk-c,角点局部偏移的损失值为Loff-c,则卷烟检测任务的总体损失值Ltotal如式(5)所示。其中λsize、λoff和λoff-c是权重参数。
卷烟检测任务的主干网络采用修改后的深层聚合模型DLA-34[13],其模型结构如图4所示。其中框内的数字是指相对原始图像的下采样系数,对于输入尺寸为512 px×512 px的图像,其输出尺寸为128 px×128 px。在主干网络提取卷烟图像的特征后,直接回归出卷烟的中心点热力图、卷烟中心点偏移量、卷烟包围框尺寸、卷烟角点相对中心点的偏移、卷烟角点热力图和卷烟角点局部偏移量这6类信息。对于卷烟角点热力图检测出来的角点,其每个角点互相独立,不属于具体的卷烟实例,而通过卷烟角点相对中心点的偏移量预测出来的卷烟角点则对应于具体的卷烟实例,将这些角点绑定到和其最近的独立卷烟角点上,完成独立卷烟角点和卷烟实例的关联,把绑定好的独立卷烟角点作为该卷烟实例的姿态检测结果。
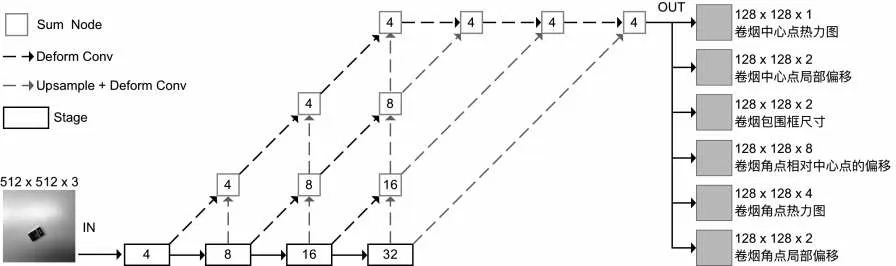
图4模型结构图Fig.4 Diagram of model architecture
2.1.3 数据处理与模型训练
卷烟检测训练集包含5 000张在真实卷烟零售店采集的图片,有1 920 px×1 080 px、1 080 px×1 080 px和640 px×480 px 3种像素尺寸。由于模型训练时输入图片的分辨率统一为512 px×512 px,为减少直接缩放图像导致的图像变形,在1 920 px×1 080 px的图像下方填充1 920 px×840 px的黑色图像,形成1 920 px×1 920 px正方形图像,同理填充640 px×480 px的图像形成640 px×640 px的图像。
模型训练时将学习率设置为1.25e-4,批处理大小为32。权重参数λsize设置为0.1,λoff=1和λoff-c=1[12]。在装备2个英伟达TITAN X GPU的服务器上训练320 epochs,并在100,200,300 epochs时将学习率缩放为原来的1/10。为提升模型训练效果,在训练过程中采用随机裁剪和随机缩放等数据增强方法,并采用Adam来优化总体的目标。
2.2 卷烟姿态矫正
卷烟的正向图像定义为由卷烟的4个角点形成的矩形图像,矩形图像与竖直方向的夹角为0°,且高度大于宽度。由于摄像头安装时可能存在一定偏转角,以及卷烟售卖过程中姿态各异,导致通过卷烟包围框截取出来的卷烟图像不是正向图像,可能包含较多的背景信息,这对卷烟识别带来不利影响,需利用卷烟姿态信息通过平面射影变换完成卷烟的姿态矫正,生成卷烟的正向图像。令p1,p2,p3是原始图像上3个共线的点,而是射影变换后的3个点,射影变换满足p'=Hp,如式(6)所示。
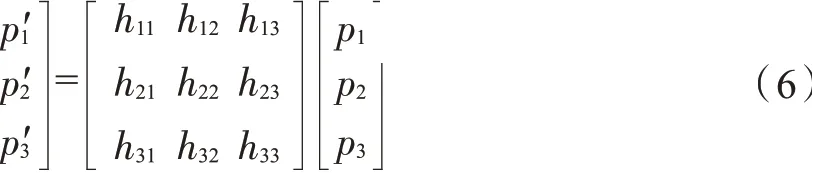
H是一个齐次矩阵,具备8个自由度,可通过变换前后的4对点求出矩阵的解。令卷烟检测输出的4角点p1(x1,y1),p2(x2,y2),p3(x3,y3),p4(x4,y4)为变换前的4个点,计算p1到p2距离的距离,则变换后对应的4个点按如下方式确定:
由射影变换前后的4对点求出矩阵的解H后,将原始卷烟图像进行射影变换,并截取变换后4个角点组成的矩形区域作为卷烟正向图像,卷烟姿态矫正实例如图5所示。

图5卷烟姿态矫正实例Fig.5 Example of cigarette pose correction
2.3 卷烟特征提取
优良的特征可以很好地表征一个物体的特性,从而获得较高的物体识别正确率。本研究中选择Darknet53模型作为卷烟特征的提取模型,该模型具备优良的特征提取能力,同时可以在运行速度和准确性之间实现平衡,具备非常灵活的特点[14]。
卷烟特征提取模型的训练集包含10 000张卷烟正向图片,由于卷烟存在正反面之分,而且某些牌号正反面的特征存在较大的差异。如果将卷烟的正反面都视为同一类别,将对模型训练的收敛带来不利影响,因此在训练卷烟特征提取网络时需要将卷烟正反面分成两种不同的类别。训练数据集在标注完成后,类别数量为210类。模型训练时统一将输入图片分辨率缩放成448 px×448 px。为提升模型训练效果,在训练过程中采用随机裁剪、随机翻转、图像色彩调整等数据增强方法。设置学习率为1.0e-3,动量设置为0.9,批处理大小为64,在装备2个英伟达TITAN X GPU的服务器上训练20 000次。
2.4 卷烟特征库构建
卷烟特征库是用于存放每个卷烟特征向量和对应牌号信息的云端数据库。实际应用中,选择Darknet53最后卷积层的输入作为卷烟的特征,该特征是1 024维的向量。为了提高识别的准确率,卷烟正反面可保存多个特征,因此一个卷烟牌号将对应多个特征,其对应关系见图6。

图6卷烟牌号和特征对应关系图Fig.6 Corresponding diagram of cigarette brand and features
根据卷烟牌号和特征的对应关系,在卷烟特征库建立数据表,见表1。在卷烟数据集中为每种卷烟牌号的正反面选择合适数量的正向图片,使用Darknet53特征提取模型对正向图片进行特征向量提取,并把特征向量和对应的卷烟牌号信息保存至数据表中,以完成卷烟的信息注册。待全部卷烟完成注册之后,卷烟特征库则构建完毕。对于卷烟新产品或新包装,采用以上相同方式完成卷烟的信息注册,即可具备对该卷烟的识别能力,无需重新训练卷烟特征提取模型。

表1卷烟牌号和特征数据表Tab.1 Data of cigarette brand and features
2.5 卷烟特征检索
卷烟特征检索是通过计算待识别特征和卷烟特征库中每个特征的欧氏距离,从中选出欧式距离最小的值,当该值小于指定的欧氏距离阈值时,则判定两个特征是同一牌号,否则不是同一牌号。由此在使用卷烟特征检索前,需要确定欧式距离的阈值。选取2 000张未经卷烟特征提取模型训练使用过的,且未在卷烟特征库注册过的卷烟正向图片,形成图片集P。使用卷烟特征提取网络对图片集P进行特征提取,生成F特征集,通过以下伪代码的方法确定出阈值:
对于在F特征集中的每一个特征fi:
计算fi与卷烟特征库里每一个特征的欧式距离,记录最小值时的特征fi'和距离值ei;
如果fi和fi'的牌号一致,则vi=1,否则vi=0;
将ei和vi形成键值对<ei,vi>加入到键值列表List中;
将List按照ei降序排序;
正确计数count=0;
对于在List中的每一个键值对<ek,vk>:
ifek<thresholdandvk=1,则正确计数count加1,否则不加;
索引index增加1;
threshold=List中索引为index的ei值。
3 应用效果
3.1 材料与方法
为了测试卷烟牌号识别方法的鲁棒性,在广西南宁市若干卷烟零售店按图1方式安装摄像头,采集不同店铺、不同卷烟牌号的图片,生成I1、I2、I3和I4测试集。其中测试集I1是包含有1 000张、105种卷烟牌号的图片集合,该测试集的卷烟牌号是全部在训练集中出现过的产品;测试集I2是包含有200张、20种卷烟牌号的图片集合,该测试集的卷烟牌号是未在训练集中出现过的新产品;测试集I3是由测试集I1真实的卷烟姿态矫正后生成的卷烟正向图片集,该测试集包含有1 896张图片,105种卷烟牌号;测试集I4是由测试集I2真实的卷烟姿态矫正后生成的卷烟正向图片集,该测试集包含有364张图片,20种卷烟牌号。测试工控机配置CPU型号为i7-8700,GPU型号为GTX1080Ti,Pytorch版本为1.1.0,CUDA版本为9.0,CUDNN版本为7.1。卷烟牌号识别方法的测试分为4个部分,分别为:
(1)卷烟检测模型测试。在测试工控机上采用I1和I2测试集对卷烟检测模型进行速度和精度测试,其中I1用于测试对已训练过的卷烟的泛化检测能力;I2用于测试对新卷烟产品的泛化检测能力。
(2)卷烟特征提取模型测试。在测试工控机上采用I3测试集对卷烟特征提取模型进行速度和准确率测试,通过识别准确率的高低来判断模型对卷烟特征提取能力的强弱。
(3)卷烟特征检索识别方法测试。卷烟特征检索识别方法指的是输入卷烟正向图像,采用卷烟特征提取模型提取该卷烟的特征,然后通过欧式距离阈值从卷烟特征库中检索出最符合条件的特征,并通过该特征获得对应的牌号。在测试工控机上采用I3和I4测试集对卷烟特征检索识别方法进行速度和准确率测试,其中I3用于测试对已训练过的卷烟的泛化检索识别能力;I4用于测试对新卷烟产品的泛化检索识别能力。需注意的是,为了具备对I3和I4测试集中各卷烟牌号的检索能力,已提前为每个卷烟牌号完成特征注册和欧式距离阈值的确定。注册过程为:先为每个卷烟牌号选择正反面图片各5张,然后通过卷烟特征提取模型提取各图片的特征,最后将特征和卷烟牌号保存到卷烟特征库中,注册完成后卷烟特征库的特征数量为1 250。欧式距离阈值按2.5节方式确定为
threshold=8.5。
(4)卷烟牌号识别方法整体测试。在测试工控机上采用I1和I2测试集对卷烟牌号识别方法进行准确率测试。测试时,记在正确位置标记正确的卷烟牌号为一个正确样例,在不正确位置标记牌号、在正确的位置漏标记牌号和在正确的位置标记错误牌号都记为错误样例,识别方法的正确率记为
3.2 测试结果分析
3.2.1 卷烟检测模型测试结果
在测试集I1和I2上完成卷烟检测模型的速度和精度测试。测试结果显示帧率为21.6帧/s,在测试集I1的位置检测单类平均精度(Average Precision,AP)为95.6%,姿态检测多类平均精度(mean Average Precision,mAP)为93.4%;在测试集I2的位置检测AP为94.9%,姿态检测mAP为93.1%。结果表明:卷烟检测模型在两个数据集上均表现出较高的精度,体现模型对训练过的卷烟和新卷烟产品都具备良好的检测性能。
3.2.2 卷烟特征提取模型测试结果
在测试集I3上完成卷烟特征提取模型的速度和准确率测试。测试结果显示帧率为35.7帧/s,准确率为99.7%。结果表明:卷烟特征提取模型对卷烟具备较强的特征提取能力,可提取出较准确的卷烟特征。
3.2.3 卷烟特征检索识别方法测试结果
在测试集I3和I4上完成卷烟特征检索识别方法的速度和准确率测试。测试结果显示帧率为33.6帧/s,测试集I3的准确率为99.3%,测试集I4的准确率为98.9%。结果表明:卷烟特征检索识别方法在两个数据集上均表现出较高的识别准确率,体现该方法对训练过的卷烟和新卷烟产品都具备良好的检索识别能力。
3.2.4 卷烟牌号识别方法整体测试结果
在测试集I1和I2上完成卷烟牌号识别方法的准确率测试。测试结果显示测试集I1的准确率为98.1%,在测试集I2的准确率为97.5%,综合I1和I2两个数据集的准确率为98.0%。结果表明:卷烟牌号识别方法对训练过的卷烟和新卷烟产品都具备较好的识别能力,总体的识别准确率达到98.0%,满足数据采集准确率90%的需求。图7为卷烟牌号识别方法的应用实例,烟盒图像区域上的蓝底字符串为识别结果,表明该方法可在复杂背景下实现卷烟牌号的准确识别。

图7卷烟牌号识别实例Fig.7 Example of cigarette brand recognition
4 结论
针对自动化采集卷烟零售数据中卷烟牌号识别的需求,提出一种基于深度学习的卷烟牌号识别方法,该方法首先采用卷烟检测算法检测卷烟在图像中的位置和姿态,其次通过卷烟姿态矫正生成卷烟的正向图像,然后使用卷烟特征提取模型提取卷烟正向图像的特征,最后通过欧式距离阈值从卷烟特征库检索出与该待识别特征最相符的卷烟特征,由卷烟特征和牌号的关系得到待识别特征的牌号。以在卷烟零售场景中采集的数据集为对象,对该方法进行了测试,结果表明:该方法的识别准确率达98.0%,满足数据采集的准确性要求。同时,对于新卷烟产品,只需将该卷烟注册到卷烟特征库中即可具备对其识别的能力,无需重新训练模型,具备良好的泛化性能。该方法的不足之处主要有:①需要在工控机上配备GPU,硬件成本较高;②要求卷烟烟盒具备4个角点,对其他形状烟盒(如圆角烟盒)的识别可能效果不佳;③要求把卷烟放在结算台识别区才可以完成识别。基于上述不足,如何降低成本、扩展烟盒适应性和实现动态场景识别等方面仍需进一步研究。
猜你喜欢
计算机应用与软件(2022年12期)2023-01-31
科技研究·理论版(2022年7期)2022-03-23
计算机仿真(2021年8期)2021-11-17
数学小灵通(1-2年级)(2018年9期)2018-11-19
电子技术与软件工程(2018年10期)2018-07-16
中国铸造装备与技术(2017年6期)2018-01-22
凿岩机械气动工具(2017年1期)2017-05-17
中国质量与标准导报(2014年10期)2014-02-28
自然资源遥感(2012年4期)2012-12-27
中国烟草学报(2012年4期)2012-04-09
