
基于演化博弈模型的群智感知网络激励机制*
2021-01-08 09:44赵宇红包凤莲
内蒙古科技大学学报 2020年4期
赵宇红,包凤莲,2
(1.内蒙古科技大学 信息工程学院,内蒙古 包头 014010;2.包钢集团第三职工医院,内蒙古 包头 014010)
随着移动群智感知[1]技术的出现,人们利用智能终端感知周围环境信息.在参与者参与感知任务时,若由于智能终端设备自身资源及其持有者的个人意愿,终端参与者不积极主动参与感知任务及数据内容的共享,将导致无法向服务平台上传已经整合高质量的数据.为解决上述问题,构建有效的激励模型[2],促使尽可能多的用户参与到感知活动中,确保感知任务按时按需完成并分享高质量的数据.本文将演化博弈中“适者生存”的基本思想应用到移动群智感知中,激励用户积极参与协作、分享数据,最终达到均衡及系统稳定状态.
1 相关工作
目前,常用移动群智感知激励机制主要分为基于报酬和非报酬2种形式.基于报酬激励机制主要通过服务平台向提供感知服务的参与者支付报酬;非报酬的激励机制又可分为信誉值激励[3-6]、游戏娱乐形式激励[7,8]、虚拟货币激励[9-11]等.REDDY S等[12]定义了一套指标来评估激励措施的有效性,通过鼓励数据收集过程来完成竞争支付,但其在空间和时间上需要设计合理地支付而导致其在具体应用中具有一定的局限性.ZHAN Y等[13]利用博弈论的知识将参与者和服务平台的交互行为视为博弈过程,求出非对称博弈纳什均衡,收集感知数据.邢春晓[14]提出一种基于博弈论的群智感知技术,其利用演化博弈论的基本思想,分析参与者的不同收益,筛选、学习参与者行为策略.ZHAO D等[15]提出一种在线拍卖类型的激励机制来鼓励移动用户参与移动人群的感知,使我们能够有效地收集众多新颖的数据,该激励机制考虑了用户向平台竞价的场景,使用户在各个时刻选择合适子集情况下达到平台最大化效用.殷丽华等[16]分别提出以平台和用户为中心的激励机制,为最大化平台效用而计算斯塔克尔伯格均衡,以用户为中心的激励模型采用逆向拍卖模型,提升用户主动性.ZHANG X等[17]设计众包激励机制,但需要服务提供商的合作才能完成工作.方法考虑了单请求单出价模型和多请求多出价模型,并为每种模型设计了一种激励机制,且验证了这些激励机制的合理性.
现有激励机制研究更多关注服务平台收益而没有优先考虑参与者的收益,在移动群智感知中的激励效果不明显.另外,机制主要以参与者直接将数据提交到服务器平台的方式,而没有考虑参与者之间数据集成,提高参与者数据间的交互并得到高质量的数据,进而参与者间为获取更多收益而向服务平台上传高质量的集成数据.基于以上问题,本文提出一种基于演化博弈的移动群智感知激励机制(Incentive Mechanism Based on Evolutionary Game Theory, IMEG).
2 分析博弈模型及收益矩阵
目前,本文设置如下假设条件:
(1)有限理性:参与移动群智感知的所有参与人V={i,j,k…},存在一定程度的理性.
(2)任意参与者i与j之间的博弈策略有{共享(S),不共享(US)}2种.
(3)在演化博弈模型中,c为参与者的博弈成本,s为无论是共享还是不共享数据,参与者从服务平台获得的收益值,Δs为通过信息共享、交互获得的收益值增量.
下面分析博弈过程中参与者的收益情况.若参与者i与j都选择共享数据,那么i和j都获得了对方的感知数据,参与者间将共享数据、融合处理,得到更多精确数据,因此,将融合数据上传到服务平台可获得更多的收益s+Δs.若j采取共享策略,而i采用不共享策略,即i得到j的数据,i经过数据间融合可获得较高收益s+Δs,但j没有获得服务平台给与的更多回报,即j的收益大小为s,此时i与j的收益分别为(s+Δs-c,s-c).相反,若i采取共享策略,但j采用不共享策略,对应收益为(s+Δs-c,s-c).最后,i与j都在博弈中采用不共享策略,收益为(s-c,s-c).参与人在不同策略下收益情况如表1所示.

表1 博弈收益矩阵数
运用博弈论相关知识对表1分析可知,当节点j选择数据共享时,节点i将获得j的共享数据;节点i会通过j的共享而获得精确的感知数据,此时,节点i会获取更多的收益.相反,节点j却消耗资源而没获取更多收益;此时会影响j采取共享策略的积极性.
为解决上述问题,提出了一种基于演化博弈激励机制,利用演化博弈中“适者生存”的基本思想,每个参与者在博弈过程中更新、学习来更改自身的行为策略.根据不同参与者的合作度来调节博弈中不同策略收益值,进而调整下一轮演化中参与者的博弈次数,服务平台调整参与者收益来控制整个演化博弈过程,通过更新策略、筛选学习对象来完成整个演化博弈过程,促进参与者间进行合作、共享数据.
3 基于演化博弈的激励机制
激励机制的核心构建演化博弈模型、更新行为策略,筛选学习对象.
3.1 构建演化博弈模型
演化博弈模型可表示为一个三元组,∏={P,S,u},其中博弈参与人集合为P={i,j},i,j为网络中任意的两个参与者;节点的策略空间为S={Si,Sj};节点的效用函数为u={ui,uj}.
本文将参与者间的合作度[18]引入演化博弈模型,将合作度作为惩戒因子来激励参与者行为.合作度的高低会影响参与者间的博弈成本,模型根据参与者间的不同惩戒因子来动态调整博弈成本.假设当前时间段内有w轮博弈过程,则每轮博弈合作度可表示{x1,x2,x3,…,xw},那么最近一段时间合作度如式(1)所示:
(1)
式中:y(k)∈[0,1]为衰减函数;α为博弈成本c的调整系数,如式(2)所示:
α=1+η-z.
(2)
式中:η为节点未来期望的大小,0<η<1;当z=1时,博弈成本αc=ηc;当z=0时,此时博弈成本最大αc=(1+η)c.
由于参与者的收益值为服务感知平台向参与者支付的报酬,即服务平台的总支出即为所有参与者的总收益和.但是实际应用场景中的服务平台预算并不是无限的,所以定义β来调整收益(s+Δs)并控制平台支付的收益,收益调整系数β为式(3):
(3)
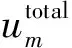
分析演化博弈模型,可以得到其收益矩阵,如表2所示.

表2 初始化条件方法间的错误关联系数
根据演化博弈论中“适者生存”的基本思想来设置博弈的基本过程,也就是说应鼓励数据共享的演化行为,而对参与者间不共享数据的行为加以惩罚.演化博弈模型在经过一轮演化博弈后,计算各个参与者收益;节点是否进入下一轮博弈收到平均收益的影响.其计算方法如式(4)所示.
(4)
式中:fi,m为第m轮博弈中参与者间的博弈次数;ui,m为第m轮博弈参与者的收益值;um为参与者的平均收益;nm为参与者数量.其计算方式为式(5);
(5)
若群智感知网络中的某一参与者长时间不与其他参与者共享数据,导致其无法获取更多的收益,此时节点将会被孤立、参加博弈次数会减少,那么该参与者将会改变自身行为策略.下面介绍参与者间的策略更新和对象学习的过程.
3.2 更新行为策略
在现实生活中,若当前参与者的收益明显高于邻居平均收益,则参与者改变自身行为策略的动力较小.相反,参与者则会为获取更多博弈收益而尽快改变行为策略.参与者可以根据参加博弈过程获取收益值的大小来确定是否更新自身策略.本文根据费米规则[19]定义了参与者更新策略规则pi,如式(6)所示:
Pi(Si→Sj)=
(6)
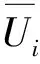
我们认为当前参与者对于其他参与者的不共享数据行为具有一定程度的容忍,参与者受博弈收益的影响而改变自身策略的概率为prepi,计算如式(7)所示.
(7)
式中:ri为参与者i被其他参与者拒绝的次数;Ni为参与者i对拒绝次数的容忍程度.γ,ε分别为收益和被拒绝次数的影响因子,γ∈[0,1],ε∈[0,1],在群智感知网络中,根据相关研究认为被拒绝次数是参与者改变自身策略的主因,在文中根据群智感知网络中参与者和感知平台的具体情况来设置相应的值.
3.3 学习对象筛选方法
当参与者确认修改策略后,其需要筛选学习对象.首先,对所有参与者的合作度进行排序,每个邻居被选中的概率与其自身的合作度相关,之后,选择所有符合要求的参与者作为学习对象的集合.在某个时刻t参与者i选择邻居进入其学习对象集合{qi(t)}的计算方法,如式(8)所示.
(8)
假设系统中参与者的总数为n;初始收益矩阵中的收入s+Δs和博弈成本c为正整数;初始博弈次数为f.基于演化博弈的群智感知激励机制步骤如下:
(1)初始化博弈次数f,演化博弈轮数j=1;
(2)在感知平台中,参与者间博弈f次;

(4)调整收入s+Δs→β(s+Δs),c→αc,调整每个参与者在下一轮的博弈次数f→fi,j+1;
(5)确认更改行为策略后,根据式(6)选择更改对象集合并从中随机选择一个对象,更新策略集合;
(6)博弈轮数j=j+1,重复步骤(3)至(6),直至系统稳定.
4 仿真实验分析
本实验采用MATLAB对所提模型进行仿真.首先,测试系统的基本性能,其次,将所提出的模型与其他模型在用户平均效用、任务覆盖率和平台效用[20]这3个方面进行比较.假设该系统中共有m个参与者,γ和ε的值分别设置为0.25和0.75;期望收益因子η=0.3;初始合作度z=0.5;初始博弈次数f=150.为了验证本文所提IMEG机制的性能,将其分别与文献[17]中的TRAC机制及文献[19]中的IMC-SS机制进行对比.
4.1 系统稳定性
图1在m=500,uth=1×106和uth=1.5×106的情况下,用户总收益同迭代次数的曲线图.当前期平台的总支出小于预算值时,博弈收益值随着博弈次数而增加,因此前期总收益也渐增.相反,参与者总收益降低.最终平台预算范围内用户总收益达到最大值,并趋于稳定.
4.2 参与者平均效用
图2显示不同激励机制下参与者平均效用对比图.在图2(a)中随着任务数的增多,用户平均效用趋于稳定.主要是由于感知平台初期发布的任务数较少,导致参与者间存在较强的竞争关系,感知平台为较少参与者支付报酬.因此参与者平均效用较高.相反,参与者平均效用降低.在图2(b)中用户平均效用随着任务总额的增加而升高;用户平均效用随着参与者数量的增加而提高;随着用户任务数的饱和,用户平均效用趋于稳定.TRAC和IMC-SS收益值受到竞价和任务数影响.由于IMEG收益受到支付累加效应的影响,所有其积极性相对较高.
4.3 任务覆盖率
图3中显示群智感知网络中,任务数和用户数对任务覆盖率的影响.通过分析图3(a),3(b)可以发现,IMC-SS较IMEG机制任务覆盖率低.而TRAC任务覆盖率较低的主要原因是当用户数接近任务数量时,TRAC只选竞价低、上报任务数多的用户.综合分析各种激励机制,IMEG激励机制下任务覆盖率较高.
4.4 平台效用
从图4(a)中可以看出,IMEG和IMC-SS机制下的平台效用呈递增趋势.但IMEG平台效用相对较低,主要原因为IMEG动态调整平台的剩余收益.TRAC模型中平台效用随任务数的增加而先增后减.
在图4(b)中3种激励机制,群智感知网络中的平台效用均为先递增后趋于平衡,出现此现象的主要原因为平台效用是随着参与者数量的的增多而提高;当参与者完成已经发布的感知任务时,其感知平台效用趋于稳定.
5 结论
针对移动群智感知网络中用户参与感知活动积极性不高及用户间数据共享性问题,提出在群智感知网络中基于演化博弈的激励机制.该模型利用演化博弈的理论,对每个参与者在博弈过程中更新、学习来更改策略.根据参与者合作度调整用户收益值;调整下轮演化博弈的次数;调整用户收益控制演化博弈过程;更新策略、筛选学习对象,完成整个演化博弈过程,促进参与者协作,共享数据.实验表明,本文的激励机制可使平台在一定的成本预算约束的情况下获得较高的任务覆盖率,有效提高用户效用和平台效用,激励参与者间合作、数据共享.
猜你喜欢
小型微型计算机系统(2022年10期)2022-10-15
体育科技文献通报(2022年3期)2022-05-23
南京理工大学学报(2022年1期)2022-03-17
大众投资指南(2021年23期)2021-12-06
建材发展导向(2021年7期)2021-07-16
中国药学药品知识仓库(2021年18期)2021-02-28
少先队活动(2018年10期)2018-12-29
冰雪运动(2018年3期)2018-12-29
华人时刊(2016年13期)2016-04-05
现代企业(2015年8期)2015-02-28
