
MLU100智能加速卡的地面无人平台应用研究
2021-01-12 02:54安旭阳苏治宝杜志岐李兆冬
兵器装备工程学报 2020年12期
安旭阳, 苏治宝, 杜志岐, 李兆冬
(中国北方车辆研究所, 北京 100072)
地面无人平台在实际作战环境中,要求能够检测人员或装甲车辆目标信息。传统目标检测算法主要以手工设计的特征描述子对目标外观建模,利用SVM对候选目标分类,常用的特征描述子有SIFT[1]、HOG[2]和LBP[3]。与传统算法相比,深度学习算法不需要手动选择特征,具备良好的特征提取能力,检测精度显著提高。2014年,Grishick等[4]首次将 CNN引入目标检测任务,提出R-CNN网络,采用选择性搜索算法提取图像的候选框,利用AlexNet网络[5]对候选框进行特征提取,最后通过SVM和回归确定目标位置和种类,速度为0.03 fps。双阶段目标检测算法检测精度较高,但检测速度较低,主要有SSP-Net[6]、Fast R-CNN[7]、Mask R-CNN[8]等。2016年,Redmon等[9]提出YOLO系列网络,在CNN中实现候选框生成、特征提取、回归,简化模型复杂度,速度可达45fps。Liu等[10]提出SSD网络,以VGG作为骨干网络,新增卷积层在3个不同尺度上进行检测,平衡检测速度和精度。单阶段目标检测算法通常具有较高的实时性,但检测精度有待提高,主要有YOLO系列[9,11,12]、SSD系列[10]、CornerNet[13]、CenterNet[14]等。
地面无人平台的智能化除需要强大的软件算法支撑,也需要能够承载庞大运算量的硬件平台。国外特斯拉的FSD芯片算力144TOPS,典型功耗72 W,主要用于自己的量产车型。英伟达Xavier算力30TOPS,典型功耗30 W。国内地平线的征程二代芯片算力4TOPS,典型功耗2 W,可用于道路检测。寒武纪的MLU100芯片,算力高达128TOPS,典型功耗20 W,具有“高性能”、“低功耗”特点,可用于图像识别等。
随着地面无人作战平台关键技术的不断突破,开展装备型号研制是必然趋势和预期。为此,本文以装备国产化自主可控需求和要求为牵引与驱动,开展了寒武纪智能加速卡在地面无人平台上的应用研究,完成目标检测算法YOLOv3/SSD在寒武纪架构MLUv01的移植部署,通过实车实验测试和验证智能加速卡的性能,为未来装备型号研制提供支撑。为此,本研究重点解决以下问题:① 目标检测算法环境适配;② 相机/激光雷达数据融合;③ 评价指标体系的构建。
1 MLU100智能加速卡
1.1 MLU100
MLU100智能加速卡是中科院寒武纪公司推出的第一款智能处理板卡,采用1H8/1H16混合多核架构,内存集成了相应的图形计算单元和片上缓存结构。相比其他GPU产品,采用针对深度学习算法特点定制的指令集和体系架构,具有高性能、低功耗优势,支持图像识别、自然语言处理等人工智能技术应用[15]。
1.2 运行模式
寒武纪加速卡支持在线模式和离线模式运行,如图1所示。其中,在线模式依赖第三方深度学习框架,如Caffe、TensorFlow和MXNet等,部署前需要调用机器学习库CNML(Cambricon Neuware Machine Learning Library)解析、编译生成模型数据文件,算法调试比较方便;而离线模式基于寒武纪开发的底层API,即运行时库CNRT(Cambricon Neuware Runtime Library),部署时直接调用离线模型文件,省略解析、编译过程,算法执行效率更高。

图1 MLU100运行模式框图
1.3 硬件结构与特性
寒武纪智能加速卡采用多核架构,本文使用的MLU100 D2加速卡共有4个核。程序运行可以调用单个或多个核进行推理计算,根据调用的方式不同,可分为数据并行和模型并行,两者可以独立运行也可同时运行。
数据并行度是指将图片数据集拆分到不同核上进行并行推理计算,每个核共享目标识别算法的模型和权重,即一次处理多张图片,如图2所示。此外,数据并行度可以在程序运行时进行设置。
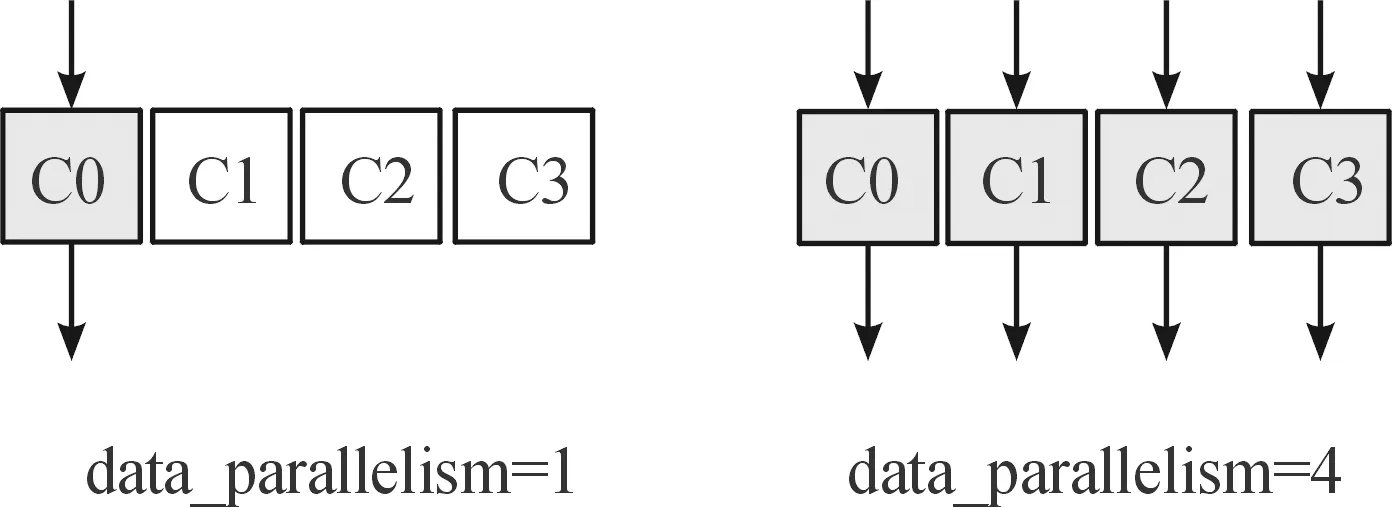
图2 数据并行度示意图
模型并行度是指将目标识别算法模型拆分到不同核上进行推理计算,模型并行度在生成离线模型时进行指定,程序运行时不能改变,如图3所示。生成离线模型时,CNML能够将通用服务器训练成功的SSD/YOLOv3模型的拓扑结构、输入输出、模型参数进行多尺度拆分,执行程序在多核上并行执行,并且保证每个核之间的数据同步。
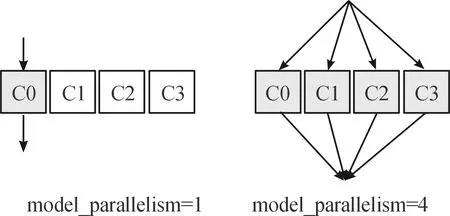
图3 模型并行度示意图
数据并行度能够提高数据吞吐量,适用于批量图片处理,如图片列表;而模型并行度能够加快推理速度,适用于单帧图片处理。但是两者满足条件式(1):
data_para×model_para≤4
(1)
本研究选用CONTEC CONPRO-H9320工业控制计算机作为宿主机,搭建国产智能加速卡。计算机的CPU通过PCIe x16总线与智能加速卡进行信息交互,目标识别算法的前处理和后处理模块在CPU上执行,模型推理模块在智能加速卡上执行,体系架构框图如图4所示。

图4 智能计算机架构框图
2 SSD/YOLOv3测试用例生成
将VOC2007、VOC2012数据集与自制数据集进行结合,形成21类样本数据库,构成训练SSD/YOLOv3识别模型的训练与测试数据,其中的80%用于训练,20%用于测试,共计22316张图片。
2.1 SSD测试用例
SSD(Single Shot MultiBox Detector)算法是Wei Liu在ECCV 2016上提出的一种目标检测算法[10],网络结构如图5所示。相比Faster R-CNN,SSD算法首先通过区域生成网络得到目标的候选框,然后再进行分类与回归,具有明显的速度优势。相比YOLO算法在全连接层后进行目标检测,SSD算法采用卷积神经网络来直接进行目标检测。

图5 SSD网络结构框图
在通用服务器的Caffe框架下进行模型训练,设置迭代次数为 100 000 次,初始学习率在保证训练不发散的情况下尽量取大以保证训练过程具有较高的收敛速度,这里选为0.001。为适当的加速收敛,将冲量设置为0.9,损失曲线如图6。训练使用的GPU为3块基于Pascal架构的Nvidia Titan X显卡。

图6 SSD算法损失曲线
2.2 YOLOv3测试用例
YOLOv3算法是Redmoz改进YOLO(You Only Look Once)的第3个版本,主要提高了小目标的识别精度[16],网络结构如图7所示。相比先前两个版本算法,YOLOv3在多尺度上进行预测(类似图像金字塔网络);使用ResNet网络,将v2的daet19提升到darknet53,加深网络结构;取消池化层和全连接层,通过改变卷积核步长进行张量变换。YOLOv3在保证实时性的基础上尽可能提高识别准确度。

图7 YOLOv3网路结构框图
在通用服务器的Darknet53框架下进行模型训练。设置初始学习率0.001,遗忘因子0.9,冲量设置0.9。为防止训练中过拟合,加入权值衰减参数0.000 5。设置迭代次数为50 000次,训练过程中通过平均准确率曲线调整训练参数,当准确率不明显上升时将学习率适当减小,损失曲线如图8。

图8 YOLOv3算法损失曲线
3 SSD/YOLOv3测试用例移植
当进行目标检测算法SSD/YOLOv3移植时,需要调用寒武纪公司开发的CNRT和CNML两个动态库。CNRT库是用户层面向寒武纪加速卡底层的接口,所有软件的运行都得调用CNRT,与并行计算、内存管理有关。CNML是用于加速机器学习或深度学习算法而编写的算子,具有基本算子和融合算子两种。基本算子是单个运算,如矩阵乘法、矩阵加法、卷积、池化等。融合算子可以对各种基本算子进行有效结合,提高运算效率。考虑到地面无人平台更关注目标检测算法的实时性,本文仅对寒武纪智能加速卡的离线模型进行介绍。
3.1 SSD测试用例移植
为满足寒武纪架构下运行,本文对通用服务器Caffe框架下训练后的SSD模型和权重进行适应性改造,首先在卷积层引入RGB三通道均值,然后将基本算子或融合算子、MLU核版本、权重、输入/输出数据尺寸、参数信息、模型版本和MLU指令等集成到模型中,使得目标检测算法彻底脱离CNML机器学习库和深度学习框架运行,通用型较好,效率高。最后开发运行程序(主要包括前处理、后处理、推理部分)加载SSD算法离线模型和图片帧,通过CNRT和驱动交给MLU100智能加速卡进行推理识别,如图9所示。

图9 离线模型运行流程框图
3.2 YOLOv3测试用例移植
首先需要将通用服务器Darknet框架下训练后的YOLOv3模型和权重转换为Caffe框架下的模型和权重,并设置图片输入形状为{1,3,416,416},采用插值方法进行上采样,然后集成基本算子和融合算子等生成MLU100支持的离线模型。最后,加载YOLOv3模型进行图片推理检测,与SSD移植方法类似。
4 MLU100智能加速卡测试
为了充分测试MLU100的性能,在实验室开展了静态测试,在室外开展了实车动态测试。
4.1 静态测试
测试方法如下:
1) 在Ubuntu16.04操作系统上部署MLU 100智能加速卡开发环境;
2) 设计相机实时读取接口,利用移植后的YOLOv3/SSD模型进行实验室场景下的数据采集与推理识别;
3) 记录MLU 100运行目标检测算法时的识别帧数、物理内存、温度、功率、占有率、频率等;
4) 根据测试数据,对加速卡性能进行评价。
测试设备主要有CONTEC工控机1台、笔记本1台、交换机1个、速腾32线激光雷达一个、大恒相机1个,如图10所示。

图10 实验室测试场景
4.1.1YOLOv3测试
本文将目标检测算法YOLOv3离线模型的模型并行度分别设置为1、2、4,并分别采用半精度浮点运算和整数运算进行试验测试,如图11、图12、图13所示。

图11 识别帧数、物理内存与模型并行度

图12 功率、温度与模型并行度
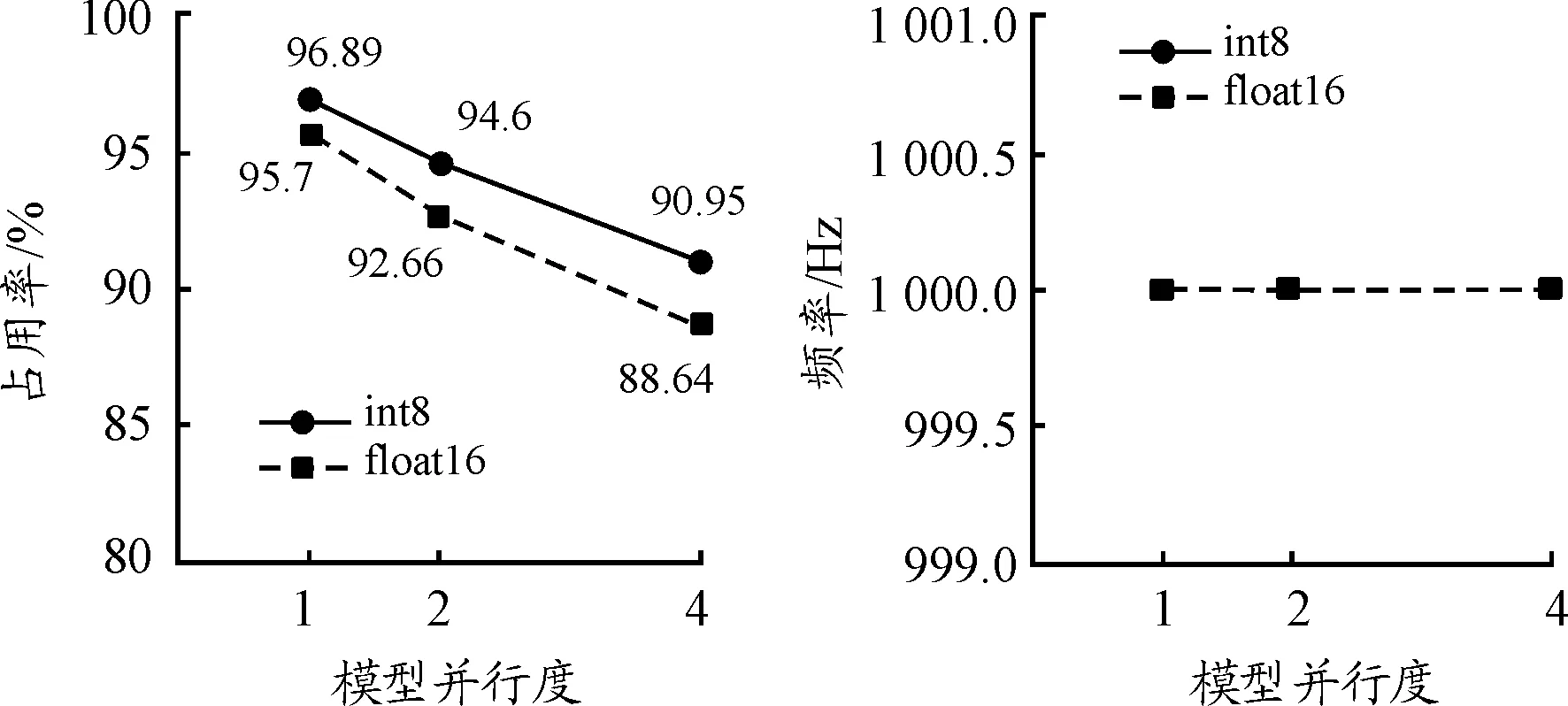
图13 占有率、频率与模型并行度
图11、图12、图13表明,MLU100 D2运行YOLOv3目标检测算法时,识别帧数、物理内存、功率、温度随着模型并行度的增加而增加;由于算法模型被分到更多的核上进行计算,MLU100的利用率随着模型并行度的增加而减少;加速卡的频率维持不变,即未出现降频现象,运行比较稳定。此外,采用半精度运算的物理内存、功率、温度、利用率明显高于整数运算,识别帧数稍微低于整数运算,但是能够保证更高的识别的精度。
4.1.2SSD测试
同样,将目标检测算法SSD离线模型的模型并行度分别设置为1,2,4,并分别采用半精度浮点运算和整数运算进行试验测试,测试结果如图14、图15、图16所示。

图14 识别帧数、物理内存与模型并行度
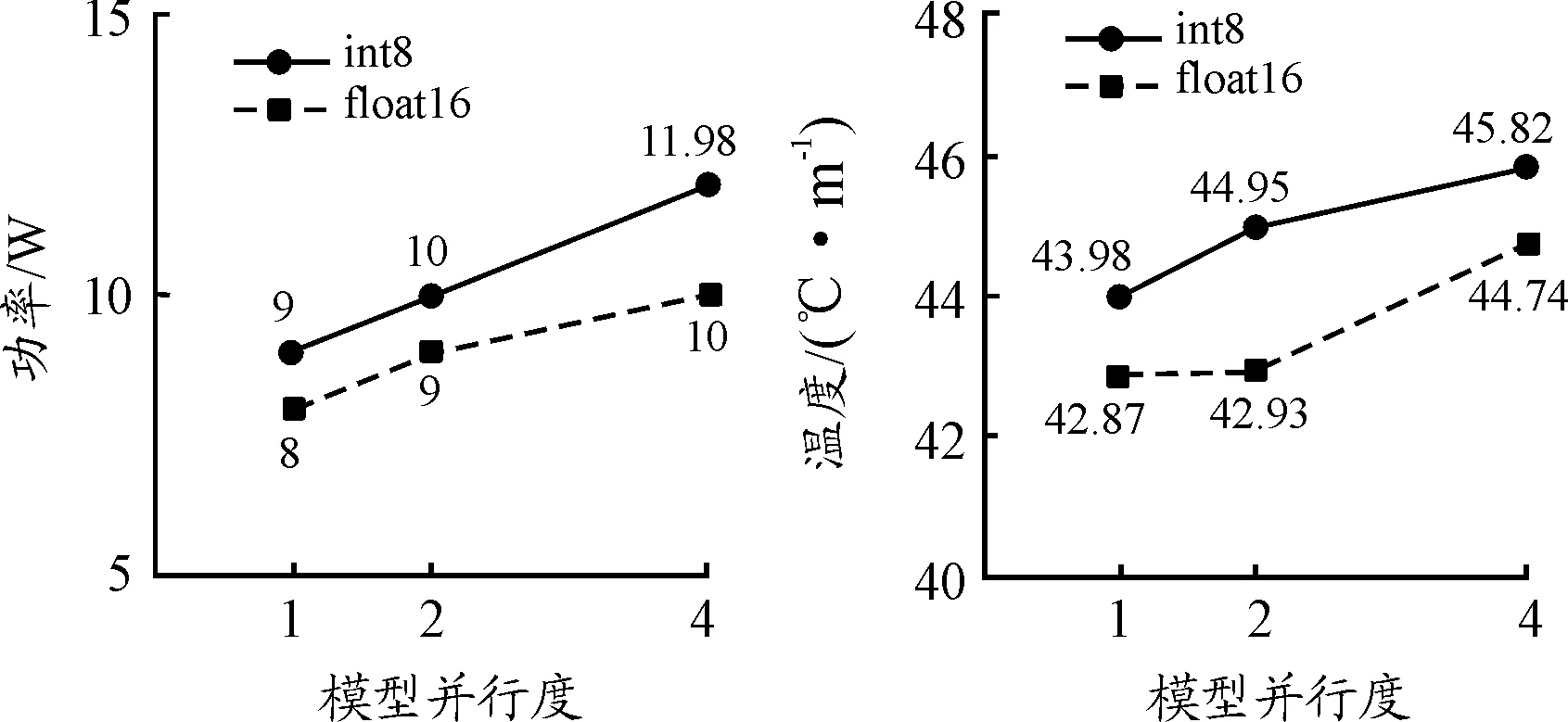
图15 功率、温度与模型并行度

图16 占有率、频率与模型并行度
图14、图15、图16表明,MLU100 D2运行SSD目标检测算法时,识别帧数、物理内存、功率、温度、利用率、频率随模型并行度变化趋势与YOLOv3相同。但是SSD算法的识别帧数(float16型为23.42帧/s,int8型为25.53帧/s)明显大于YOLOv3(float16型为15.48帧/s,int8型为21.21帧/s);与SSD模型相比,YOLOv3模型具有更大的复杂度,运行YOLOv3算法时加速卡的物理内存、功率、温度、利用率也大于SSD算法;频率均维持为1000Hz,并未出现降频现象,能够稳定运行。
4.1.3MLU100加速卡评价
本文选择智能加速卡的频率、识别帧数、温度、功率和占用率作为评价指标。正常情况下,目标检测算法的识别帧数是最应该受关注的,但是在地面无人平台部署配置智能加速卡的计算机时,由于车内空间相对狭小且存在大量发热元器件,不利于智能加速卡的散热,可能造成加速卡频率下降,不能维持稳定的帧率输出,故对加速卡温度或功率影响较大。因此需要对加速卡的各指标重要性进行评价、比较、判断,做出更合理的决策。为此,本文引入层次分析法,每个评价指标的重要性可以通过两两相互对比实现[17-18]。
本文以加速卡性能为目标层,识别帧数、温度、功率、占用率和频率为准则层,构建层次结构如图17所示。

图17 评价指标体系层次结构框图
为保证智能加速卡在地面无人平台上可靠运行,能否维持加速卡的频率恒定尤为重要,否则将使得加速卡的识别帧数动态变化,最终导致地面无人平台收发数据混乱。此外,目标检测算法的识别帧数影响地面无人平台的行驶车速,相对其他评价指标较为重要。经专家评估,制定如表1所示的判别矩阵。
计算出表1的评价指标的判别元素的最大特征值为5.091 7,特征向量为[0.428 7, 0.181 6, 0.111 8, 0.067 2, 0.875 3],分别表示识别帧数、温度、功率、占用率和频率对评价智能加速卡所占的权重。

表1 判别元素
然后计算一致性指标CI(Consistency Index):
最后计算一致性比率CR(Consistency Ratio):
其中,随机一致性指标RI(Random Index)可通过表2获取[19]。由于CR<0.1时,满足一致性检验,无需重新调整判别矩阵。

表2 随机一致性指标
因此,本文中准则层对目标层重要性的排序结果依次为加速卡频率、识别帧数、温度、功率和占用率,相对应的权重分别为[0.875 3, 0.428 7, 0.181 6, 0.111 8, 0.067 2],归一化后为[0.525 832 032, 0.257 539 349, 0.109 095 278, 0.067 163 282, 0.040 370 059]。
根据YOLOv3/SSD测试的数据,构建MLU100智能加速卡的评价标准,对不同范围的频率、识别帧数、温度、功率、占用率进行打分,如表3所示。

表3 MLU100智能加速卡评价标准
将MLU100智能加速卡运行YOLOv3/SSD算法的实验室测试结果(图11~图16)按照上述表3中的评价标准转化为相应的分数。然后根据各指标权重进行加权平均,获得评价分数,如表4所示。结果表明,MLU100 D2运行SSD目标检测算法时获得的分数最高,为92.68。
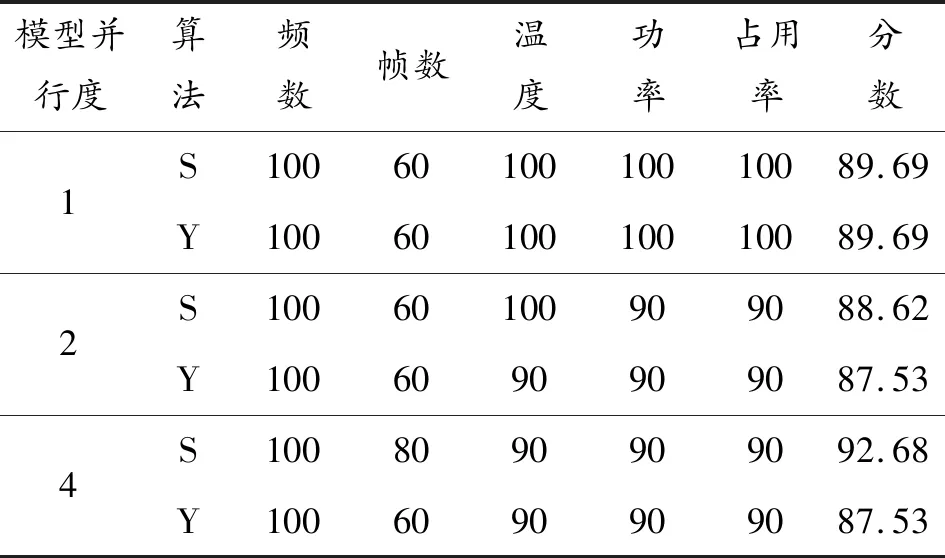
表4 MLU100运行SSD算法得分
4.2 实车动态测试
为验证智能芯片是否满足地面无人平台自主导航功能模块实时运行需求,设计相机/激光雷达避障模块,如图18所示。搭载智能加速卡的CONTEC工控机负责目标检测,通过UDP通信将输出的目标边界框的像素坐标发送到自主计算机。自主计算机将激光雷达采集的点云数据进行聚类,目标中心点像素与聚类后的点云数据进行融合获取已识别目标中心的三维位置,最后发送到地面无人平台的导航建图模块进行建图。
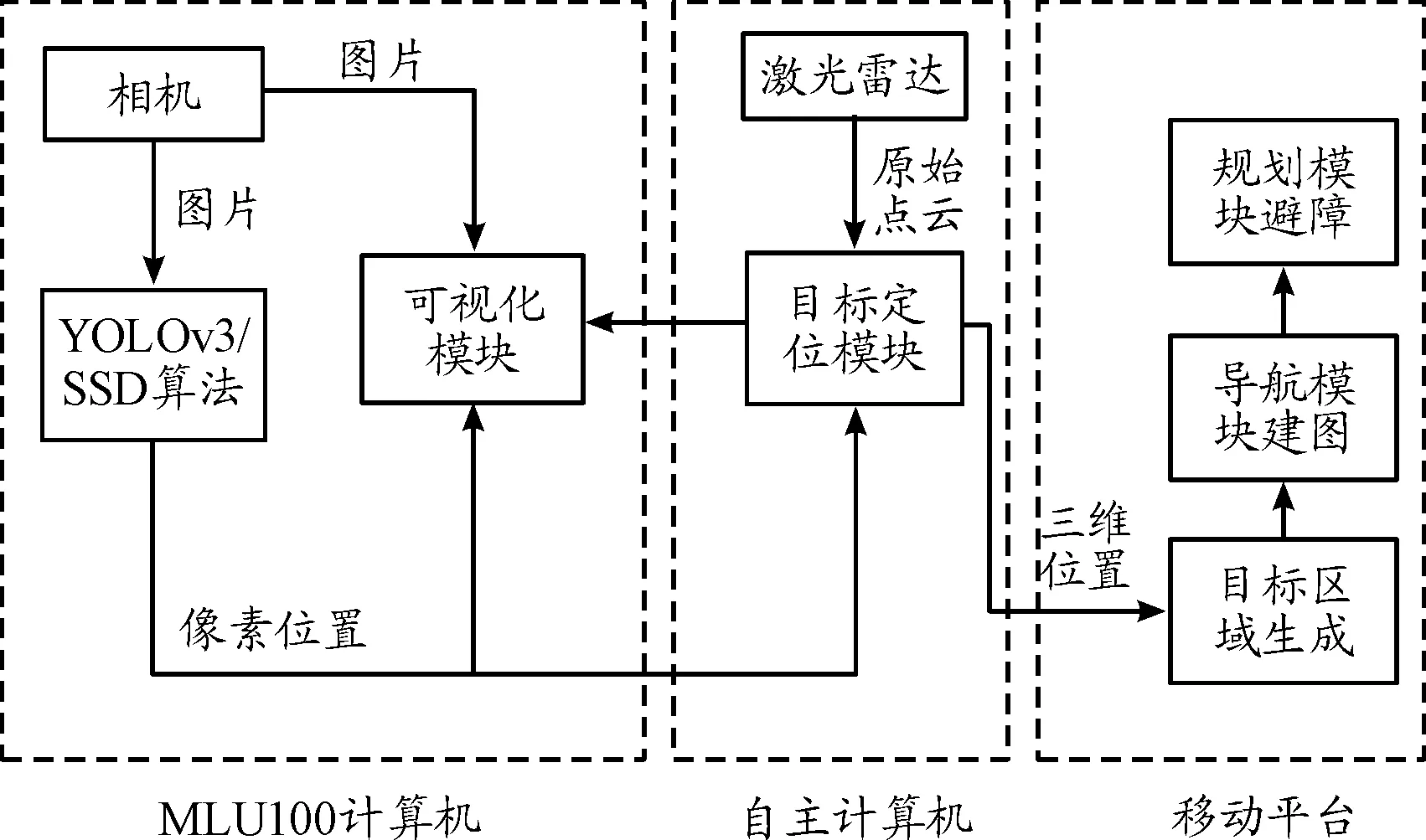
图18 相机避障模块框图
实验室静态测试结果表明,更大的模型并行度有利于识别帧数的提高,且int8推理速度优于float16,但检测精度稍有下降。本着安全原则,实车测试时调整模型并行度为4、采用int8进行实时推理识别。通过操控端下发直线任务路径,实车自主行驶,根据前方检测的“障碍”重新规划路径,如图19所示。

图19 实车测试现场
4.2.1YOLOv3测试用例
避障结果如图20所示。共进行30次实验,基于相机感知模块成功避障25次,失败5次,成功率83.33%。

图20 避障结果示意图
地面无人平台自主避障测试中,YOLOv3算法的识别帧数和智能加速卡的频率、识别帧数和功率、占用率和温度曲线如图21、图22、图23所示。
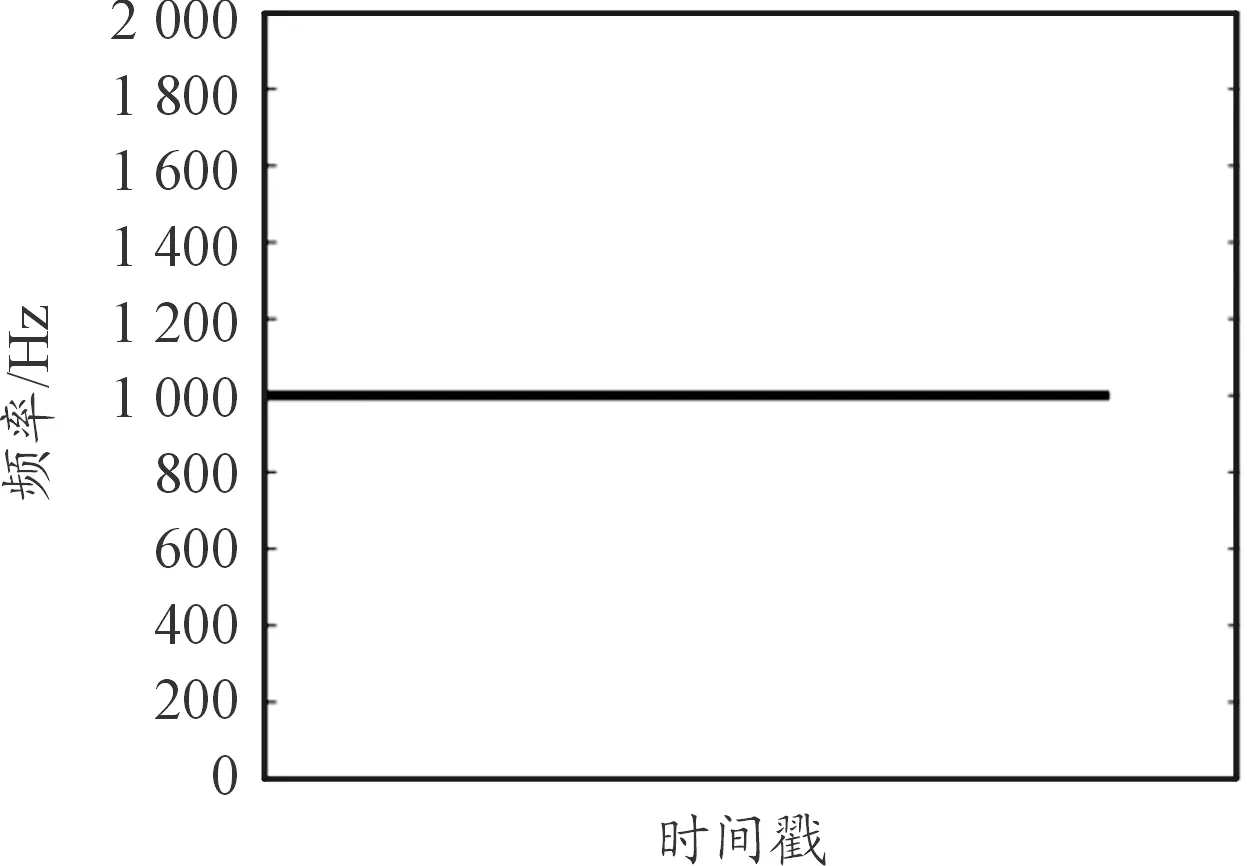
图21 频率曲线

图22 帧数和功率曲线
图21、图22表明,MLU100运行YOLOv3目标检测算法时的识别帧数约为21帧/秒,其中大于20帧/秒占据99.57%,但是低于图片集测试时的23帧/秒,主要是因为图片集能够一次加载,而相机实时识别需要边加载边推理计算;MLU100功率由0增加到12 W,低于图片集测试时的14 W,是因为批量图片测试可设置更大的数据并行度,使得每个核全负荷运行,而相机实时识别只能通过提高模型并行度加快推理运算,模型却不能充分拆分,仍明显优于市场同等产品(一般为30 W)。
图23表明,MLU100运行YOLOv3目标检测算法时板卡每个核的利用率约为68%,主要用于加载模型及与CPU进行交互,低于图片集测试时的98%,是因为图片集能够被充分拆分到每个核进行推理计算,而相机实时识别时无法将模型进行充分拆分,任务调度相对“悠闲”;MLU100板卡的温度由40 ℃提高到54 ℃,明显高于实验室测试温度,主要是因为车体内空气不流通,加速卡无法及时散热。

图23 占用率和温度曲线
4.2.2SSD测试用例
避障结果如图24所示。共进行30次实验,基于相机感知模块成功避障27次,失败3次,成功率为90%。相比YOLOv3算法避障,SSD算法具有更高的识别帧数,能够提供更快的目标位置更新,避障占据优势。同时,SSD算法的识别帧数和智能加速卡的频率、、识别帧数和功率、占用率和温度曲线如图25、图26、图27所示。

图24 避障结果示意图

图25 频率曲线

图26 帧数和功率曲线

图27 占用率和温度曲线
图25、图26表明,MLU100运行SSD目标检测算法时的识别帧数约为25帧/秒,其中大于25帧/秒占95.21%。相比YOLOv3,SSD网络更简洁,运行速率更快,但是仍低于图片集测试的31帧/秒,原因与4.2.1小节类似;MLU100的功率由0增加到10 W,相比YOLOv3,运行SSD时每个核的负载相对较低,功率相应较低,但仍低于图片集测试时的13 W,原因与4.2.1类似,明显优于市场同等产品(30 W)。
图27表明,MLU100运行SSD目标检测算法时每个核的利用率约为52%,低于YOLOv3的68%,是因为SSD网络简洁,拆分到每个核上的模型较少,任务调度较简单,但仍低于图片集测试时的96%,原因与4.2.1小节类似;MLU100板卡的温度由53摄氏度提高到55摄氏度,是因为长时间测试导致车体内的环境温度持续升高。
5 结论
基于寒武纪智能加速卡开展了应用研究及测试,完成了:
1) 对通用服务器架构下的目标检测算法SSD/YOLOv3进行了适应性改造,实现了算法在寒武纪智能加速卡MLU100 D2上的部署。
2) 在实验室场景下的对加速卡进行了测试,引入层次分析法对加速卡的性能进行了有效评价,结果显示更大的模型并行度能够提高目标实时推理识别的速度。
3) 针对地面无人平台的运行环境条件,设计相机/激光雷达融合模块,开展了实车避障任务测试,加速卡能够保持较为稳定的目标位置输出,满足地面无人平台低速自主导航实时建图需求
未来将开展MLU100在地面无人平台高速自主导航条件下的目标识别以及场景语义识别等方面的应用研究,对智能加速卡的车载环境适应性进行测试,对国产智能加速卡满足地面无人装备应用需求的情况进行综合评价。
猜你喜欢
电脑知识与技术(2022年15期)2022-07-02
舰船科学技术(2021年12期)2021-03-29
电脑爱好者(2020年23期)2020-12-30
阅读(低年级)(2019年2期)2019-04-19
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
中学生数理化·八年级物理人教版(2016年5期)2016-08-26
电脑爱好者(2015年5期)2015-09-10
新高考·高一物理(2015年3期)2015-08-20
文理导航·科普童话(2015年6期)2015-07-29
小猕猴学习画刊(2015年2期)2015-01-22
