
结合特征选择与集成学习的密码体制识别方案
2021-01-15 07:17陈永乐王庆生陈俊杰
计算机工程 2021年1期
王 旭,陈永乐,王庆生,陈俊杰
(太原理工大学信息与计算机学院,山西晋中 030600)
0 概述
安全的密码体制必须能够抵御各种不同类型的攻击。由于攻击者主要关注如何通过密文获取密钥以及如何将密文恢复为明文,因此诸多以此为目的的攻击方法常针对特定密码体制而设计,其中,设计识别密文所用的加密算法是开展密码分析的重要前提。
明文经不同密码体制加密后形成的密文数据并不能达到完全随机,彼此间尚存有微小差异,对此,可通过提取表征密文信息的相关特征作为区分不同密文类别的依据。现阶段研究主要利用机器学习方法和统计学方法对密文所用的加密算法进行识别。相比于利用统计学方法,基于机器学习方法的识别方案设计思路清晰,适应性强,并且可供利用的理论基础丰富,是目前的主流研究方向。
文献[1]借鉴文档分类方法中的词袋模型,以支持向量机为分类算法,研究针对DES、3DES、AES、RC5 和Blowfish 密码体制的识别问题。文献[2]借鉴信息检索中的向量空间模型,通过合理构建神经网络对MARS、RC6 和Twofish 等密码体制进行识别研究,但该方案受限于计算复杂度,仅可在密文数据量较小的情况下完成识别,推广难度较大。文献[3]结合统计学与机器学习方法,以NIST 发布的随机性测试作为构造密文特征的依据,即以密文随机性度量值作为判断密文相似性的标准,使用K-均值聚类算法对AES、DES、Camellia、SMS4 和3DES 密码体制进行识别研究。文献[4]依据密码学常识,提出一种基于随机森林的分层识别方案,并初步给出一种密码体制识别问题的定义系统,以助于对识别问题的形式化研究。
在现有研究中,所提取的特征基本为借鉴其他领域中有关识别任务中的所用特征,如文献[1-2]借鉴文档分类中所用相关特征(词袋模型和向量空间模型),文献[4-6]引入信息论的理论作为提取特征的方法,文献[3-4,7]利用随机性测试的方法提取密文特征。对于所用分类方法,文献[1]选择支持向量机作为提取密文特征后进行分类的算法,并比较不同核函数情景下的识别情况,文献[2,8-9]引入神经网络作为识别任务的分类模型,文献[5]利用C4.5 算法构建决策树作为识别任务中的分类模型。为比较不同分类算法在识别任务中的优劣,文献[10-11]选择朴素贝叶斯、支持向量机、神经网络等8 种常见分类算法对4 种分组密码体制进行识别,并对不同分类算法的识别性能进行对比。为比较不同分组密码工作模式下的识别情况,文献[12-13]对利用CBC 和ECB 模式加密的密文数据进行了研究。
目前,较多识别密码体制的研究基于多种密文特征和分类算法,但研究者较少探讨不同特征对识别性能的影响,并且现有理论框架还有待进一步完善。对此,本文提出一种新的密文特征提取方法,同时完善密码体制识别问题的定义系统,给出提取密文特征的形式化描述。在此基础上,结合特征选择方法设计基于集成学习的密码体制识别方案。比较特征不同的属性对识别方案识别效果的影响,并且使用该方案分别对包含多种序列、分组和公钥密码体制的3 种具体识别情景进行实验。
1 密文特征建模
现有基于机器学习算法的密码体制识别研究基本符合构造新特征,即选择新分类模型的简单研究模式,但较少对该问题进行更深入的探讨,因此,利用现有研究成果难以做进一步推进。另一方面,鉴于密码体制识别问题的理论基础尚不完备。文献[4]初步给出了密码体制识别问题的定义系统,该定义系统有助于将识别问题规范化和形式化。但对于识别问题的进一步深入研究,此理论框架仍稍显单薄。首先,该定义系统仅对识别问题和识别方案进行了形式化描述,但未涉及识别任务的主要难点,如密文特征提取和分类模型选择等问题;其次,形式化识别问题和识别方案仍没有改变先提出识别方案再将其统一于定义系统之下的流程,割裂了理论框架与方案设计间的关系;此外,利用识别问题和识别方案的形式化描述难以对各类识别方案的设计思路和彼此优劣作出较完备的解释,无法做到由理论指导实践。
鉴于以上考量,本文基于文献[4]识别问题的定义系统,对识别方案中提取密文特征的环节做形式化定义。
遵照文献[4]密码体制识别任务的定义系统,令F 表示密文文件,其可表示为由某类字符组成的有序集合,定义如下:
定义1(密文) 设有未知密码体制的密文文件:

其中,ci表示密文文件的第i个字符,且ci可表示为不同类型的字符,现阶段研究[3-5,10-11]多将密文表示为以比特或字节为基本字符ci的有序集合。
获取密文后需要提取密文的特征,定义如下:
定义2(密文特征) 对未知密码体制的密文文件提取特征,得到维数为d的特征向量:

可将提取密文特征的过程抽象为将密文文件F映射为特征vfea的过程,即Fea(F)→vfea,其中,Fea()表示具体的特征提取过程或方法,如计算密文数据中各字符出现概率[4,6-7]、各字符熵或最大熵[4-5]等。
定义3(加工函数) 给定未知密码体制的密文F,将密文映射为特征vfea过程中的计算方法称为加工函数,记作f。计算各字符的概率、熵值或最大熵值等方法,均为不同种类的加工函数。
加工函数的输入对象是密文数据。输入的密文数据可以是密文依顺序按固定长度分块后的每一分块,也可以是各分块相同位置处字节或比特重新组合后的数据[4]。此外,还可将表示密文的字符分别组合,以每一类字符组合作为加工函数的输入对象[5]。
定义4给定未知密码体制的密文F 和加工函数f,令oper 表示加工函数输入对象,即密文数据的组织形式。
定义5综合以上定义系统,密码体制识别方案中提取的密文特征可表示为四元组vfea=(C,f,oper,d)。其中:C 为密文数据的表示方式,如将密文F 表示为以比特或字节为单位的有序集合,并从中提取密文特征;f 表示将密文映射为特征的加工函数;oper 表示加工函数的输入对象,即对密文数据的组织形式;d表示密文特征的维数。
在定义5 中,识别方案提取的密文特征被表述为具有4 条属性的四元组。以此密文特征模型为出发点,下文将通过实验比较该四元组中各属性对识别方案效果的影响。
2 密文特征及识别方案
2.1 特征对比
基于上文对密文特征的定义,本节通过实验探究特征的不同属性对识别准确率的影响。
依照现有密码体制识别方案,选择AES、DES、3DES、RSA 和RC4 这五组包含分组、序列和公钥的加密算法[14]作为待识别的密码体制,并以KNN 分类算法作为实验所用分类模型。根据密文表现形式、加工函数和特征维数等的不同,选择文献[3-5,10-11]中的多类特征进行实验,实验的具体细节见本文第3 节。
从现有研究及密文特征的定义系统出发,此处实验所选特征为vfea=(C,f,oper,d),其中,C 包含比特和字节两种形式,即C={bit,Byte}。选取熵、最大熵[15]、概率和随机性测试[16]作为加工函数f 的待选项,即f={Entropy,Maxentropy,Probability,NIST}。关于密文数据组织方式oper,此处选择将密文依次序分块、各分块内相同位置再组合和不同类型字符组合3 种方式。
图1 所示为所选12 种特征的识别准确率比较结果,其中,图1(a)所示为选择不同加工函数密文特征的识别准确率曲线,图1(b)所示为将密文分别表示为比特与字节的有序集合后不同维数特征的识别准确率曲线。由图1(a)可以看出,当以字符出现频率、熵、最大熵和随机性测试作为提取密文特征的加工函数时,以最大熵与随机性测试作为加工函数的特征表现最好。由图1(b)可以看出,在加工函数与密文组织方式相同的情况下,比特类特征与字节类特征的识别准确率差距不大,且不同维数特征间识别准确率的差异不明显。

图1 不同密文特征属性对识别性能的影响Fig.1 Influence of different attributes of ciphertext feature on recognition performance
通过分析图1 可以发现:在密文特征的4 种属性中,密文数据的字符形式C,即提取密文特征时表示密文数据的基本字符单位对识别准确率的影响有限;密文特征的维数d对识别准确率的影响有限;加工函数f 选择计算各字符频率的特征远不如以随机性测试和信息熵为加工函数的特征,且以熵或最大熵作为加工函数的特征表现更稳定,适应性更好。此外,在提取密文特征时,对密文数据的不同组织方式也对识别效果有较大影响。
综合以上分析,本文选择以ASCII 表中的256 种字符作为表示密文数据的基本字符。对于密文数据的组织方式oper,此处选择将表示密文数据的字符重新组合的方式,即把表示密文数据的256 个字符分为6 组字符组合,分别为所有字符、可见字符、大写字母、小写字母、数字以及字母和数字之外的字符。同时,以熵、最大熵和基尼系数等信息论中度量信息的不确定性及数据随机性的方法作为提取密文特征的加工函数。3 种加工函数的计算方法如下:
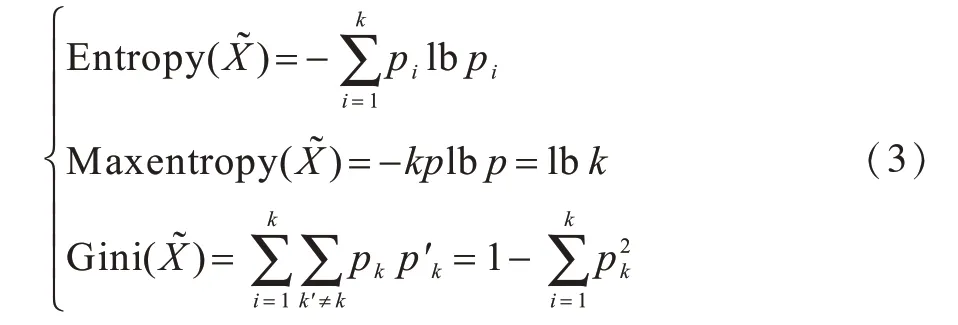
对密文文件F,计算其中对应上述6 组字符组合中每一组字符的熵、最大熵和基尼系数,并以6 组字符的计算结果作为密文文件F 的特征。在此基础上,根据不同密码体制识别情景构造不同的字符组合方法。
2.2 特征选择
在识别包含多种密码体制的密文时,提取相同特征难以应对密文数据间的多样性,此处选择以上述6 组字符集作为基础,利用Relief 特征选择算法[17]对每组字符集进行字符选择,在不同密码体制识别情景中以不同字符集合作为提取密文特征的基础。
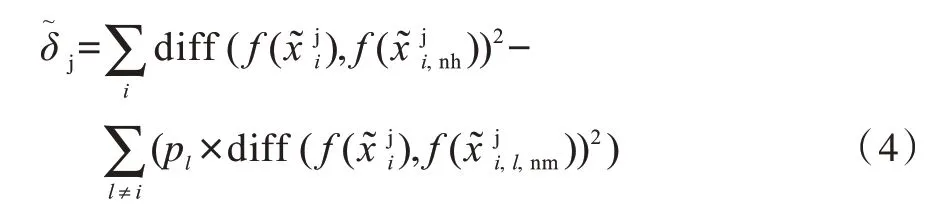
其中,f(x)表示上文所提3 种信息熵类加工函数,表示去掉字符j 后,其余字符经加工函数f(x)计算后的值,pl表示第l类样本占总体样本的比例,diff(a,b)表示a、b间的差值。
对每一组字符集,若去掉字符j 后,其与猜中近邻的距离小于与其他各类别猜错近邻的距离,说明去掉字符j 后对分类有积极作用,则减小字符j 的权重;若去掉字符j 后,其与猜中近邻的距离大于与其他各类别猜错近邻的距离,说明去掉字符j 后对分类有消极影响,则增加字符j 的权重。
在不同密码体制识别情景下,以2.1 节中6 组字符集为基础,利用式(4)的方法重新构造各字符集,并根据新的字符组合,利用式(3)中的函数提取密文特征。
2.3 识别方案
在包含多种密码体制的识别情景中,现有分阶段识别方案对多种密码体制划分层次,通过减少各阶段待识别密码体制的数量,降低识别任务的难度[4,9]。但在识别方案不同阶段均使用相同特征及分类模型,难以兼顾不同密码体制识别情景间可能存在的差异。因此,本文在分阶段识别方案设计思路的基础上,选择集成学习算法[18]作为识别方案中的分类模型。集成学习算法流程如图2 所示。
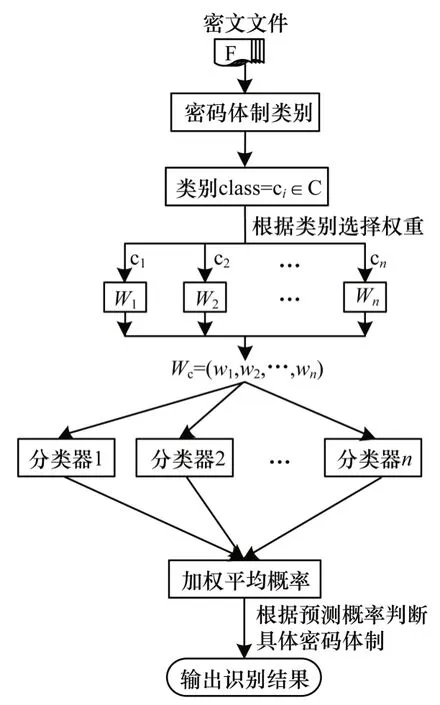
图2 集成学习算法流程Fig.2 Procedure of ensemble learning algorithm
在包含多种密码体制的识别情景中,依据密码学常识可将识别过程分为两个阶段,即识别出密文所用加密算法所属序列、分组或公钥密码体制的类别,此处称为密码体制类别识别阶段,以及完成识别出密文所用具体加密算法的任务,如在已知密文所用加密算法所属类别为分组密码后,进一步识别出其所属AES、DES 或3DES 等分组密码加密算法。
在不同密码体制识别情景中,待识别的密码体制类别和具体算法间均存在差异,若选择单一分类算法进行训练,可能因误选导致该分类算法的泛化性能不足,而结合多种分类学习算法作为个体学习器并集成的方式可降低此风险。本文以集成学习算法作为分类学习器设计密码体制识别方案,工作流程如图3 所示。
在训练阶段,首先对带有密码体制标签的密文数据(F,label)以2.2 节中的方法进行特征选择,得到在该识别情景下各字符的权重,然后根据各字符的权重重新提取密文特征,并将带标签的密文特征(Fea,label)导入分类模型进行训练。
在识别阶段,首先提取密文类别特征fea0,利用训练好的分类模型识别出其所属的密码体制类别,然后根据所属类别,进一步提取可识别具体加密算法的密文特征feak并导入训练好的分类模型,最终输出识别结果。
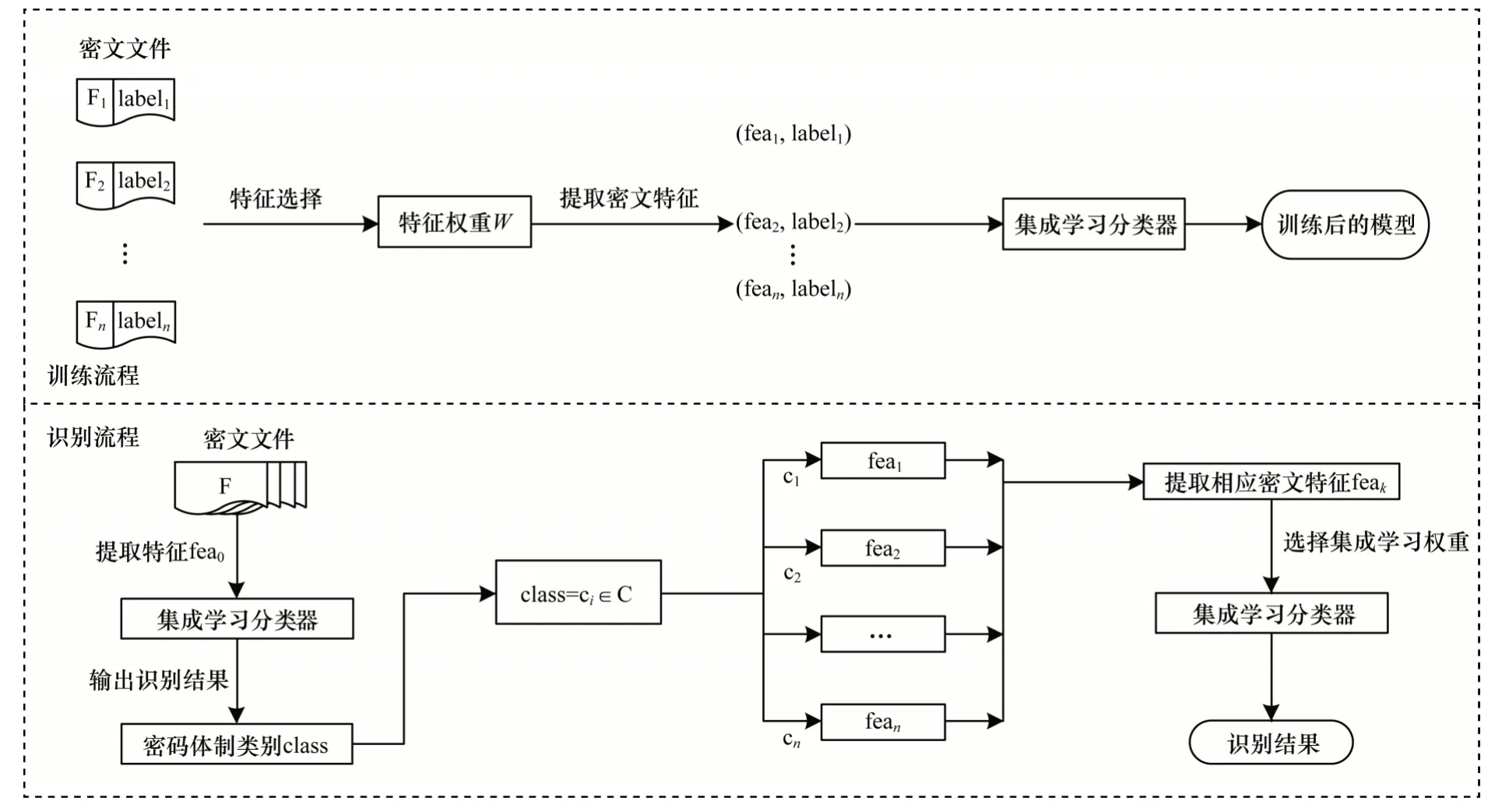
图3 本文识别方案流程Fig.3 Procedure of the identification scheme proposed in this paper
3 实验与结果分析
3.1 密文数据采集与实验设置
为验证本文方案的有效性并开展后续实验,随机选取Caltech-256 图片库中大小固定为512 KB 的1 000 张图片作为实验所用明文数据,以RC4、Salsa、AES、DES、3DES、Camellia、Blowfish、SMS4、IDEA和RSA 密码体制为基础,通过改变每种密码体制的参数长度或工作模式等设置,扩展为36 种不同的密码体制,并分别对1 000 张图片进行加密,得到共计36 000 个512 KB 的密文文件。有关各密码体制的设置情况及实现方式如表1 所示,其中涉及各密码体制的详细介绍参见文献[19-21]。

表1 密文数据采集使用的10 种密码体制Table 1 Ten cryptosystems for ciphertext data collection
以下实验以识别准确率p作为评价识别方案效果的标准。在每组实验中均对密文数据进行十折交叉验证,并以各次结果的平均值作为衡量识别效果的指标。
3.2 密码体制类别实验
在包含多密码体制的识别情景中,需要识别密文所用加密算法的类别。依据密码学常识,首先将上述36 种密码体制作为以下两种识别情景分别进行实验:一种是将上述密码体制分为对称加密与非对称加密类型2 类识别情景(简称两类情景);另一种是将其分为序列、分组及公钥密码体制3 类识别情景(简称三类情景)。为探究不同序列密码及分组密码中不同分组长度、工作模式等识别情景下的识别情况,从上述3 类密码体制中各选出一部分组成新的密码体制识别情景,具体如下:

在由式(5)~式(7)给出的3 种情景中,序列密码RC4 和Salsa 通过选择不同密钥分别各扩展为4 种不同的密码体制:情景1 中选取分组长度与工作模式均相同的6 种分组密码(AES、DES 等);情景2 中选取分组长度相同但工作模式不同的4 种分组密码(SMS4);情景3 中选取工作模式相同但分组长度不同的3 种密码(AES);公钥密码体制选取2种密钥长度的RSA。
实验利用2.2 节中的算法对各类具体识别情景进行特征选择,结果如图4 所示。可以看出,在不同识别情景下,每种字符对识别任务的权重存在差异。因此,根据每种识别情景中的字符权重重新提取密文特征,实验结果如表2 所示。可以看出,在两类情景中基本可实现准确识别,在三类情景中,识别准确率也高于随机分类的准确率,在改变不同参数设置的3 种情景中,由于待识别密码体制数量的减少,因此整体好于三类情景的情况,且熵与最大熵作为加工函数时要好于基尼系数。
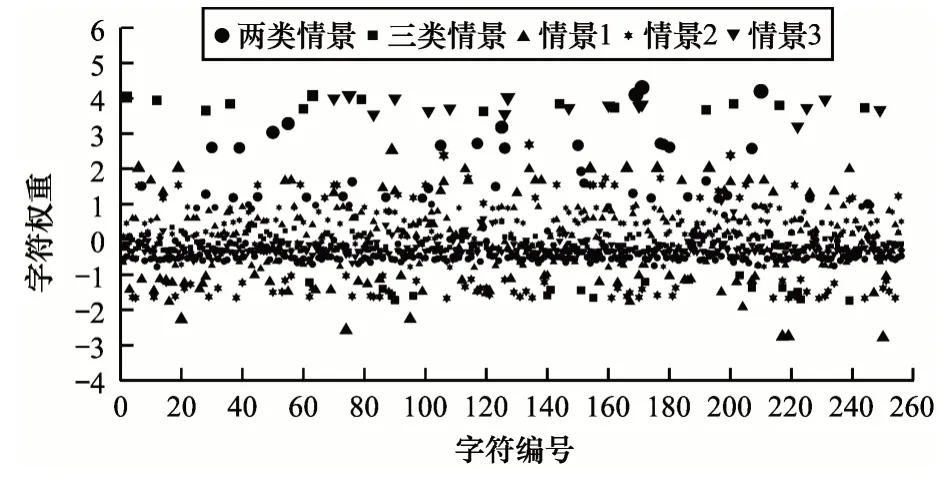
图4 不同识别情景下的字符权重Fig.4 Character weight under different recognition scenarios

表2 不同识别情景下的类别识别准确率Table 2 Class recognition accuracy under different recognition scenarios %
3.3 加密算法识别
完成对密文所属密码体制类别的识别后,执行对相同类别内具体加密算法的识别任务。针对式(5)~式(7)给出的情景,对其中具体的加密算法进行识别实验,组成6 种识别情景。其中,序列1 对应式(5)中的RC4,序列2 对应式(7)中的Salsa,分组1~分组3 分别对应式(5)~式(7)中的分组密码设置,最后一种为识别公钥的情景。图5、图6 分别表示以熵和最大熵为加工函数f 时,各具体识别情景中的字符权重。根据各识别情景中的字符权重重新提取密文特征,实验结果如表3 所示。可以看出:本文方案在识别公钥密码体制的情景中基本可达到准确识别;在两种序列密码识别情景中最高识别准确率分别为55%和48%;在3 种不同参数设置的分组密码识别情景中最高准确率分别为32.46%、41.20%和39.29%,均高于随机分类的准确率。利用十折交叉验证过程中的结果进行单样本的T-检验,结果显示,3 种分组密码识别情景下的p-value 均小于9.93×10-9。实验结果表明,在这3 种识别情景下,各最优特征的识别准确率显著高于随机识别的准确率。
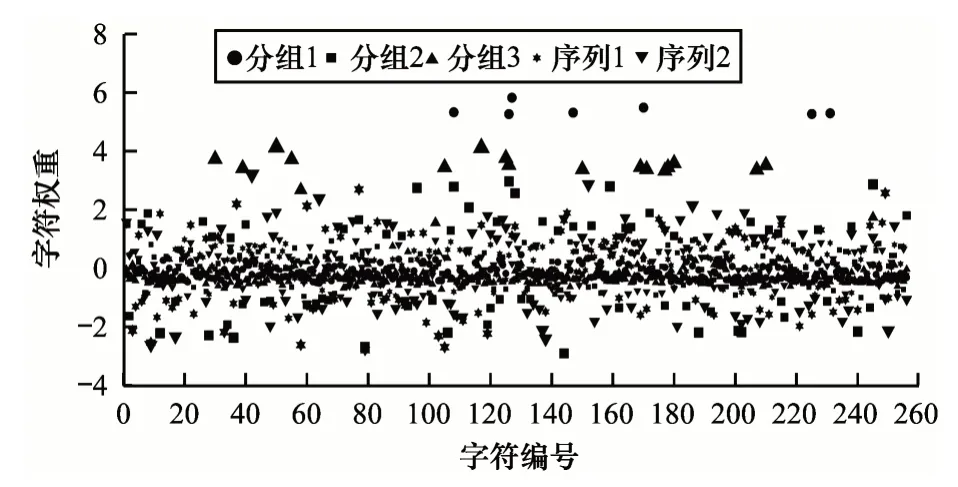
图5 不同识别情景下的熵权重Fig.5 Entropy weight under different recognition scenarios

图6 不同识别情景下的最大熵权重Fig.6 Maximum entropy weight under different recognition scenarios
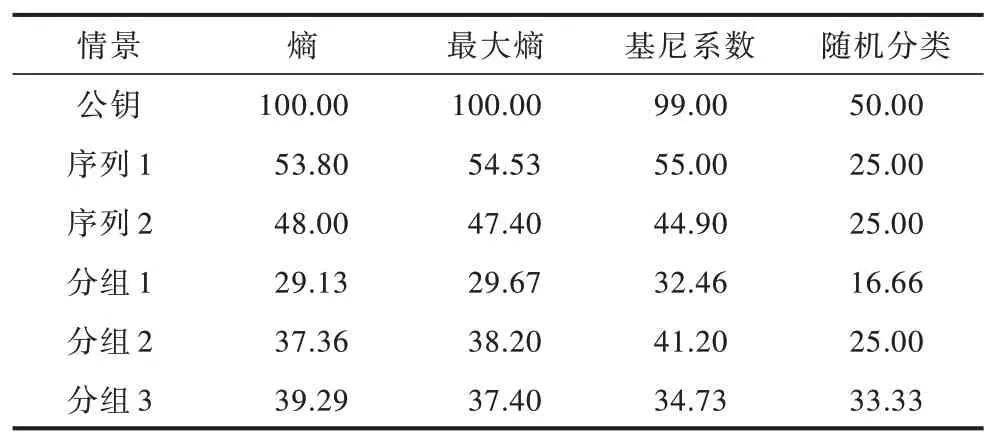
表3 不同识别情景下的识别准确率Table 3 Recognition accuracy under different recognition scenarios %
3.4 整体评价
对本文方案在由式(5)~式(7)给出的3 种情景中的整体识别效果进行分析。每种情景的总体识别准确率计算公式如下:
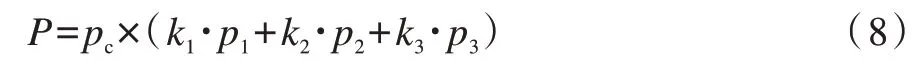
其中,P表示总体的准确率,pc和p1~p3分别表示识别密码体制类别阶段和识别各类别中每种具体加密算法的准确率,相应地,k1~k3表示每类密文样本占总样本的比例。
实验以不区分具体识别情景均提取相同密文特征的文献[4]识别方案作为对比方案,并选择其中表现较好的3 种特征进行识别实验。文献[4]方案与本文方案的识别结果比较如表4 所示。可以看出:在不区分识别情景的文献[4]方案中,密文特征以熵作为加工函数的识别效果整体优于以计算概率作为加工函数的特征,但在3 种识别情景中的差异不大;在区分识别情景的本文方案中,不同识别情景间表现最好的特征存在差异,但以熵和最大熵为加工函数的特征整体表现更好;本文方案准确率整体上优于文献[4]方案,但在不同识别情景中,提升效果存在差异,在3 种识别情景下最优识别准确率分别提升6.41%、10.03%和11.40%。
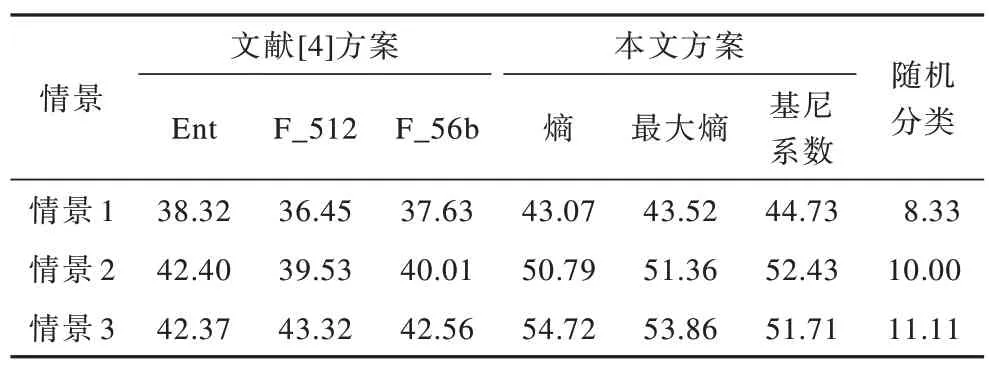
表4 本文方案与文献[4]方案的识别准确率比较Table 4 Comparison of identification accuracy between the scheme proposed in this paper and the one in literature[4] %
为进一步检验两种方案识别结果的差异,对上述3 种情景中各最优特征间的识别准确率进行两独立样本T-检验,结果显示,3 种情景下的p-value 分别为2.24×10-10、1.16×10-11和3.46×10-15,表明在统计学意义下本文方案的提升效果明显。
4 结束语
本文对密码体制识别问题进行探讨,并以现有理论框架为基础,对识别方案中提取的密文特征进行建模。为分析识别方案所用密文特征对识别结果的影响,从特征模型出发,提取12 种密文特征进行对比实验,结果表明,在提取密文特征时,密文数据的组织方式及所用的加工函数这两种因素对识别方案识别效果的影响较大。为此,在本文方案中加入特征选择的环节,并重新设计了提取密文特征的方法。运用该方法对包含多种密码体制的3 类不同识别情景进行实验,结果表明,与不区分识别情景均采用相同密文特征的识别方案相比,本文方案在包含多种密码体制的识别情景中具有更显著的优势。下一步将研究多种加密算法的原理及性能差异,同时探究其他密文组织方式和加工函数在识别问题中的应用。
猜你喜欢
保健医苑(2022年4期)2022-05-05
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
学与玩(2018年5期)2019-01-21
少儿美术(快乐历史地理)(2018年7期)2018-11-16
信息安全与通信保密(2016年10期)2016-11-11
语文世界(小学版)(2016年9期)2016-09-14
