
基于文本内容的科学前沿探测方法研究进展
2021-01-15 13:17华旦草安培浚肖仙桃
现代情报 2021年1期
华旦草 安培浚 肖仙桃
收稿日期:2020-08-21
基金项目:2020年中国科学院文献情报能力建设专项“科技领域战略情报研究咨询体系建设”(项目编号:E0290001)。
作者简介:华旦草(1996-),女,硕士研究生,研究方向:科学前沿识别与探测。肖仙桃(1965-),女,研究馆员,硕士生导师,研究方向:文献计量学。
通讯作者:安培浚(1979-),女,副研究员,硕士生导师,研究方向:地球科学科技发展战略研究,灾害评价与风险管理研究。
摘 要:[目的/意义]本文从科学前沿概念出发,对当前已有的基于文本内容的科学前沿探测方法进行梳理总结,为科学前沿探测方法的发展提供基本参考和启发。[方法/过程]对科学前沿相关概念、基于文本内容的科学前沿探测方法进行了系统的总结,分析了现有探测方法的优缺点。[结果/结论]对科学前沿极其相近概念做出进一步辨析,总结目前方法存在的问题,并提出未来发展的建议。
关键词:科学前沿探测;词频分析;共词分析;文本挖掘
DOI:10.3969/j.issn.1008-0821.2021.01.020
〔中图分类号〕G250.252 〔文献标识码〕A 〔文章编号〕1008-0821(2021)01-0169-09
Research Progress of Scientific Frontier Detection
Methods Based on Text Content
Hua Dancao1,2 An Peijun1* Xiao Xiantao1
(1.Northwest Institute of Eco-Environment and Resources,Chinese Academy of Sciences,
Lanzhou 730000,China;
2.Information and Archives Management,School of Economics and Management,University of Chinese
Academy of Sciences,Beijing 100190,China)
Abstract:[Purpose/Significance]Starting from the concept of scientific frontiers,this article summarizes the existing scientific frontier detection methods based on text content,and provides basic reference and inspiration for the development of scientific frontier detection methods.[Methods/Process]A systematic summary of the relevant concepts of scientific frontiers and scientific frontier detection methods based on text content,and the advantages and disadvantages of existing text-based detection methods and composite detection methods were analyzed.[Results /Conclusions]Make a further analysis of the scientific frontier and its similar concepts,summarized the shortcomings of the existing methods,and put forward suggestions for future development.
Key words:scientific frontier detection;word frequency analysis;co-word analysis;text mining
随着信息技术的不断发展,机器自动处理与学习的大数据时代、智能化时代来临,加速了科学知识创新、科研信息流动和学科交叉融合,并呈现出复杂多样的发展趋势。准确识别科学前沿,把握学科发展趋势,正在成为科学规划与科学预见迫切需要解决的关键问题,文本挖掘技术发展与开放获取的实现,使得获取论文文本的难度大大降低,基于文本内容进行科学前沿探测识别的方法迎来了新的发展机遇。
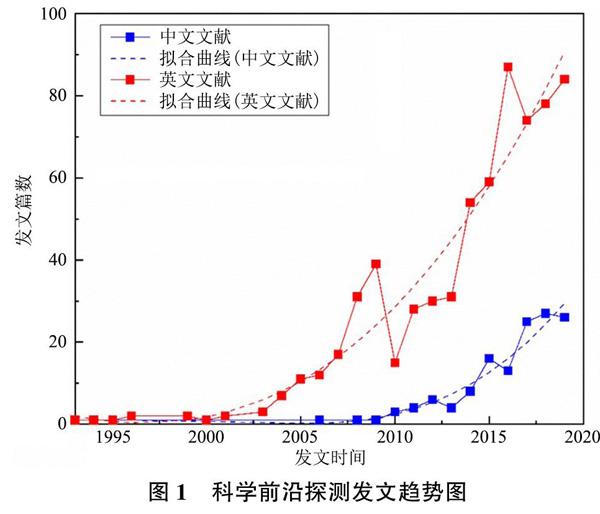
通过对Web of Science和中国知网(CNKI)两大检索平台中与“科学前沿识别”和“文本内容探测”相关的国内外文献检索,遴选出与图书情报學领域和计算机领域中有关科学前沿识别的中文文献339篇,英文文献687篇,检索截至2020年4月25日,获得如图1所示的相关论文发文趋势图。从图中可以看出,相关研究在2000年以前发展相对缓慢,国外从2005年前后,国内在2010年前后,相关主题研究得到快速发展。通过综合分析现有文献发现,已有研究中很少对基于文本内容的探测方法进行精确划分以及详细描述。鉴于此,本文从科学前沿概念出发,对当前已有的基于文本内容的科学前沿探测方法进行梳理总结,为科学前沿探测方法的发展提供基本参考和启发。
1 科学前沿及相关概念辨析
目前科学前沿还没有清晰标准的定义,与之相近的“研究热点”和“新兴主题(新兴技术)”之间的界限也十分模糊。
1.1 科学前沿定义的发展
科学前沿最早是由Price D J[1]于1965年提出,他认为学科领域的论文会被一组新论文通过参考文献紧密联系起来,这些被积极引用的论文发展迅速,将这些活跃论文定义为科学研究前沿,并具有时效性,会随着时间发生变化。
在此之后,对科学前沿的定义主要分为两类:一类是将科学前沿定义为通过引文分析得到的较为宏观文献或文献集。Small H等[2]认为科学前沿是共被引文献聚类得出的论文集,展现了科学领域内的“高水平活动”。Garfield E[3]认为科学前沿是近3年的共被引聚类的核心文献集以及施引核心文献集的最新文献集。Persson O[4]认为科学前沿是核心被引文献的施引文献集,其中施引文献构成科学前沿,而被引文献构成其知识基础。Morris S A等[5]将科学前沿定义为被一组固定的、与时间无关的基本文献持续引用的文献集。另一类则是将科学前沿定义为源于文本内容分析得到的较为微观的词组或主题。这是由于科学前沿来源于新的科学发现或研究进展,通常伴随着某些文本内容的显著变化。Braam R R等[6]定义科学前沿是被不同知识及社会背景的科学研究者们共同关注的一系列相关研究问题和概念。Chen C[7]认为科学前沿是一组突然爆发的主题及潜在研究方向,强调其新颖性和突然爆发的特点。Upham S P等[8]认为科学前沿是在科技领域中动态变化最快、最受研究者关注的研究主题。他们将科学前沿分为5类:发展中的(Growing)、新兴的(Emerging)、收缩的(Shrinking)、稳定的(Stable)以及既存的(Existing)科学前沿。
通过以上表述可以发现,科学前沿定义内涵丰富,很难被准确描述,笔者认为科学前沿是源于最新科学发现或研究进展的,能在短时间内迅速引起领域内科学家的高度关注的,能代表科学发展的难点、热点与未来趋势的研究主题。
1.2 科学前沿相关概念
与科学前沿的相近概念有研究热点、新兴主题(新兴技术)。研究热点是热度高的研究主题,当前有很多研究人员关注和研究,在领域文献中反复出现。不少学者将研究热点视为发生频率高的一类主题,并通过社交媒体数据对其进行探测。新兴主题(新兴技术)在学科领域中,会随着时间逐渐推移被越来越多的学者讨论并在实践中不断丰富其内容。Rotolo D等[9]将新兴技术定义为具有新颖性、快增长性、连贯性、显著影响以及不确定性的技术。Wang Q[10]则认为新兴主题是具有强新颖性、较快增长性、连贯性和一定影响力的研究主题。
研究热点最为明显的特征是极高的关注度、讨论度与参与度,在领域中的体量相对较大,较易通过传统的文献计量方法识别。新兴主题最为重要的特征是新颖性与快增长性,因此需要利用针对其特性的情报分析方法识别。科学前沿相比起研究热点和新兴主题,具有更高的价值和创新程度,需要更针对性的情报分析与探测方法,识别难度也更大。
从三者的关系来看:科学前沿和新兴主题新颖性高于研究热点,但研究热点受到的关注度高于科学前沿与新兴主题。有些研究热点关注度虽高,但无法排除是研究人员对该主题跟风所导致的。钟镇在探讨研究热点和研究前沿之间的关系时,认为前沿选题有很大概率成为下一阶段的热点选题[11],因此研究热点范围大于科学前沿,即随着时间推移,科学前沿的持续发展会吸引众多研究人员加入,最终成为下一阶段的研究热点,也可能由于理论缺乏或发展不利,最终消亡[12];新兴主题是当下新出现且具有未来发展潜力的研究主题,它与科学前沿相近,都是研究人员对未知领域的探索,存在一定的重叠。但新兴主题可能发展成为科学前沿,也可能因为发展不利而消亡,三者之间呈现动态变化的过程。
由以上表述可以得出科学前沿的特征有:①新颖性:科学前沿多为近期产生,有稳定发展的潜力。②集中性:显性科学前沿会在短期内获得大量研究人员关注,相关研究数量增加。③高价值性:这是科学前沿的核心特征,前沿研究代表了研究领域未来发展趋势及研究走向,代表了所在领域急需解决的问题,能够为领域专家或学者提供研究参考或情报支持,因此蕴含极大的研究价值。
2 文本内容探测方法
科学前沿产生于科学发展过程中的新发现或新研究进展,自然伴随着某些文本内容的变化。为揭示科学前沿的深层内涵,国内外不断尝试通过语义和文本挖掘的方法探测科学前沿,因此,通过文本内容来探测科学前沿的可行性很高。基于文本内容探测方法的过程可以归纳为:根据数据源的文本內容构建分析语料库、提炼内容标识、选择指标、词汇聚类分析领域结构、识别科学前沿、分析呈现结果。主要的文本内容探测方法有词频分析法、共词分析法和文本挖掘法。
2.1 词频分析法
词频分析前沿探测主要是通过统计主题词的词频或者词频变化率来探测和识别科学前沿主题。通过给定阈值的词频反映某研究领域变化,词频越高,表示科学前沿的出现引起研究人员的注意越多,相关研究和产出文献越多,因此对词频变化进行跟踪可以在一定程度探测到前沿。潘若愚等[13]通过网络爬虫收集近十年国内外文本挖掘领域的关键词,使用词频分析法探测研究热点与前沿趋势。毕奕侃等[14]通过对2008—2018年CSSCI收录的统计学领域研究论文关键词的热度和潜力两个维度探测研究前沿及其动态演化。
然而关键词词频分析法易受同义词和近义词影响,而且只能追踪单个词的变化,词频变化速率的计算复杂,筛选高频词汇进行分析会忽略可能代表新兴研究趋势和潜在前沿的低频词,廖鹏飞等[15]就从被忽略的长尾关键词中探寻新兴研究前沿。
由于研究前沿的出现通常伴随着词频密度的改变,为避免词频分析法中阈值设置过于主观的问题,Kleinberg J[16]提出突现词检测算法(Burst Detection Algorithm),他认为单位时间内出现频次的增长率突然加大的词显得十分重要,并将其称为突现词。Chen C[7]利用突现词检测算法从题目、摘要、关键词和文献记录中提取突现术语,探测科学前沿。突现词检测方法被引入科学前沿探测,涌现出大量相关研究。Li M等[17]通过对关键词和突现词进行关联规则挖掘(ARM-KB),并结合共词分析法探测到纳米级抗癌药研究的科学前沿。He X R等[18]使用突发词检测算法分析关键词和参考文献,得到有序加权平均(OWA)算子研究的新兴研究趋势。周耀林等[19]对2011年以来国际图情领域大数据领域的关键词进行突发词检测,得到该领域的前沿主题。突发词检测的数据源不仅局限于论文文献,王兴旺等[20]基于多类数据源(科技论文、专利、科技舆情),使用词频分析和突发词检测法探测出车联网技术的基础研究前沿和技术研发前沿。
突发词检测需要一定时间的数据积累,其效果不仅受阈值选择的限制,而且对词的来源要求較高,通过预处理的突发词检测才会比较有意义,无形中增加了方法的复杂度。仅使用关键词词频分析或者突发词检测都会切断被分析词与文献之间的语义联系,缺乏关联性,难以表现科学前沿的知识结构。
2.2 共词分析法
共词分析一般以文本中的关键词为分析单元,根据在同一个文本主体中的词或短语共同出现的情况,统计共同出现的次数。通常认为共现次数越多,两者之间的联系越为紧密。由于研究主题通常由一组相互关联的词汇构成,因此可以根据词汇间的共词关系,对文献集的词汇进行聚类分析,生成词汇簇,跟踪词汇簇在不同时期的发展变化,从而探测科学前沿。
Callon M等[21]提出一种根据主题词聚类簇之间的密度和向心度作为关联强度数据并可视化展示的共词分析技术。Rip A等[22]对10年内生物技术领域的论文进行共词分析,探测出该领域的现状和科学前沿,并指出识别科学前沿要结合科学计量方法和专家认知分析。Besselaar P V D等[23]通过抽取论文标题中的词语后构建词共现网络,通过聚类分析,探测到凝聚态物理研究领域内和领域间的新兴研究领域。Ravikumar S等[24]发现共词分析能从更微观的角度分析研究发展趋势,成为描述学科或领域发展现状与态势的重要定量分析方法。共词分析在一定程度上展现知识结构的变化,直观揭示研究主题和研究领域,对科学前沿的描述比传统词频分析法准确,因此越来越多的研究者采用共词分析方法来识别科学前沿:如蔡运荃等[25]通过共词分析法构建共词知识图谱,探测我国高等教育领域研究前沿;赵丽梅等[26]以共词分析为基本研究框架,揭示大数据背景下数字图书馆研究领域的前沿趋势。许晓阳等[27]改造关键词共现识别模型,将论文和专利相结合,使用研究主题年龄和研究主题关注作者数量两个指标来识别研究前沿。
然而共词分析法也存在缺陷,有研究通过共词分析对表面效度[28]与有效性[29]进行检验时发现前沿探测存在明显的语料数量依赖性,基于题名和关键词而探测到的前沿与该科学领域研究者所共同认可的前沿之间的相关性并不高,侧面说明关键词共词分析依旧无法完整保留语义联系,仅通过关键词进行前沿探测无法保证结果具有很高的有效性。共词分析对分析词的频次有一定的要求,若分析文本量不足或内部相关性不高,导致共词分析矩阵过于稀疏,无法获得较好的聚类效果,忽略低频词中存在的科学前沿,且共词分析法分析的词间关系不能完全代表主题之间的相关关系,影响前沿探测结果的准确性。
2.3 文本挖掘法
由于词频分析和共词分析都出现分析词与文献之间的语义联系被切断的问题,为保证语义联系,学术界提出通过直接从文献的文本内容获取分析词的文本挖掘方法。基于文本挖掘的科学前沿探测方法多为无监督文本挖掘算法,基于全自动化或半自动化系统,在科学前沿探测时相对简单高效,使分析结果更加准确、可靠。目前用于科学前沿探测的方法主要的发展有:非相关知识发现、新兴趋势探测(Emerging Trend Detection)、主题模型,SAO结构和其他机器学习方法。
1)非相关知识发现由Swanson D R[30]首次提出,是指从表面没有任何联系的文献内容中识别出新颖的、尚未被发现的、潜在有用的关联。这种方法摒弃了传统的引文分析方法,利用自然语言处理技术对科技文献内容进行深入分析,从中发现相关知识点,进而发现潜在的知识关联[31]。
这些潜在知识关联自发现之后经过进一步研究论证发展成为科学前沿,然而非相关知识发现方法在具体的实施过程受到许多限制,存在发现效率低,在知识发现过程中需要专家解读,其结论需要专业人士进行验证的问题。
2)新兴趋势探测由Kontostathis A[32]正式提出,其认为发现某一特定领域中的热点与焦点的动态趋势,并在探测到最新的发展趋势时主动提示的过程便是新兴趋势探测。该方法首先将主题用一组时间特性关联的特征表示,然后根据这些特征用文本挖掘技术进行主题抽取,随着时间推移用一定的评价标准来关联主题,构建主题演化路径并判断其趋势,预测新兴趋势[33]。Tu Y N等[34]根据知识老化理论,提出新颖指数(NI)和已发表量指数(PVI)判断新兴主题。钟辉新[35]总结新兴趋势探测方法,分析存在的问题,提出基于新生词与知识图谱的探测方法。
但从主题内容和语义角度来看,ETD的方法还不够成熟和完善:第一,主题领域的界定局限于词频和词共现方法,没有从语义角度聚类形成主题领域;第二,许多特征可以从文献中提取,在其他文本数据中无法提取,这些特征无法放入ETD模型中,导致数据来源单一;第三,没有形成全面的评价指标体系,不能从多方面展现前沿主题特征;最后,不同ETD模型评价标准不一,无法保证探测准确度。
3)概率主题模型由Blei D M等[36]在概率隐性语义索引模型(Probabilistic Latent Semantic Indexing,PLSI)的基础上提出了LDA(Latent Dirichlet Allocation)模型。该方法通过模拟文档生成的机器学习技术实现分类和降维,利用Dirichlet概率分布和Gibb抽样,从词、主题和文档三层贝叶斯概率模型识别文档集中潜在的主题词信息。Wang X等[37]在LDA模型的基础上加入“主题—时间”分布,提出了主题随时间变化而变化的主题模型(Topic Over Time,TOT)。Wu Q等[38]融合内容共现理论和聚类分析指标构建了主题分割模型ATNLDA。
这种直接利用文献中的词来生成主题分布的方法提出后受到学术界的广泛关注,不少研究者通过LDA主题模型识别探测各个领域的科学前沿。徐路路等[39]使用基于PLDA模型与多数据源融合相关性分析的新兴主题探测方法探测出石墨烯领域新兴主题。侯捷[40]提出改进用户词典生成算法结合优化后LDA主题模型,对我国管理科学学科的研究领域前沿进行探测分析。冯佳等[41]通过LDA模型抽取研究主题,采用主题强度和主题新颖度两个指标识别科学前沿主题,并基于本体概念映射实现科学前沿主题的语义分析。张晖等[42]采用LDA主题模型从文献热度评价模型挖掘的科研文献中识别出学科的前沿热点,并将探测出的科学前沿与Altmetric获取的数据集比较。刘博文等[43]通过使用LDA主题模型对碳纳米管领域的基金项目和论文进行分析,从主题强度、主题新颖度和主题相似度3个指标探测出前沿主题。颜端武等[44]利用LDA主题模型生成各个时间窗的研究主题,根据研究主题关联筛选并构建石墨烯领域主题演化路径,探测出领域三大研究前沿。
主题模型法无需专门词表,难点是如何确定核心词,如果未对文本进行预处理,很多高频但意义不强的噪音词汇就会影响分类效果。而且主题模型分类数目确定有较大主观性,相似度阈值设定离不开较强的专业背景知识,不可避免地会影响到聚类效果,进而影响到主题探测效果。
4)SAO结构是Subject-Action-Object的缩写,即主谓宾结构,是文本语义挖掘的方法之一。最初由Yoon J等[45]为弥补专利引文分析的不足,给目标问题寻找解决方案而提出。SAO结构基于研究内容构建语义关系,更能表征内容之间具体的关系。因此在表达语义的同时,还可以有效地展示语句元素之间的语义关系[46],进而可以规避基于关键词的文本分析的不足,从而获得一个更加完整的语义理解。研究者们通过提取文本内容中的SAO结构,在保留原本语义联系的基础上进行分析,找到新兴的解决方案,进而发现相关的科学前沿。李欣等[47]对SAO结构中的主/客体对象和关系进行语义层面的消歧和相似度计算,进而准确地揭示新兴主题演化过程中存在的规律和特征。SAO虽多用于探测新兴技术,但是基于文本内容的探测方法在科技文献方面依旧适用。黄鲁成等[48]通过筛选出突现文献后,使用SAO相似度方法更准确地提炼出研究主题,最终达到识别新兴研究主题的目的。
SAO结构不易受同形异义词和同义词的影响,能更好地表达主题间的直接关系,更加准确地判断文献的相似性。SAO结构虽然可以利用软件辅助提取,但对所有的信息不加区分,提取效果并不令人满意,为获取更好的效果,需要人工加以修正,这在某种程度上降低了SAO结构提取的客观性。
5)除去以上常用的文本挖掘方法,还有部分学者使用有监督的机器学习、深度学习方法等识别探测科学前沿。例如采取结构风险最小化,综合考虑了模型复杂度等特征,具备较好的灵活性和模型适用性,算法简洁的支持向量机(SVM)方法:徐路路等[49]利用机器学习中常用的支持向量机时序分析方法进行预测,进一步改进粒子群优化算法,提高科学前沿探测的准确性。董放等[50]提出一种基于LDA-SVM论文多分类时序数据,使用ARIMA进行预测未来论文变化趋势,从而推测技术发展趋势的研究方法,来識别工程科技领域的新兴技术。
应用范围最广的是基于各类神经网络的模型,神经网络采取经验风险最小化策略,探测准确度高。李松等[51]针对神经网络存在的缺陷,提出一种用于优化的改进时序预测模型——遗传算法(GA,Genetic Algorithm),克服神经网络在连接权值和阈值选择上的随机性,提高准确度。Lee C等[52]利用前馈多层神经网络的方法,并结合两个量化指标以识别新兴技术。
有监督的机器学习方法虽然在一定程度上降低识别探测的风险,提高准确度,但训练速率较慢,可解释性不强,对训练数据依赖很强,无法将训练出的模型使用在其他学科领域,因此在前沿探测方面的实际应用依旧不多。
2.4 引文—文本内容复合探测方法
基于文本内容的探测无法克服单一方法的局限性,为了更准确地探测科学前沿,学术界提出将基于引文的探测方法与文本内容挖掘复合的新方法探测科学前沿,并进行了大量的研究工作。基于引文的探测方法主要包括共被引(Co-citation)分析法、文献耦合(Bibliographic Coupling)分析法和直接引用(Direct Citation)分析法。这些方法通过分析文献间的相互引证关系,可以绘制出前沿相关的可视化知识图谱直接展现文献间相互关系的演化,在利用引文聚类方法识别研究主题等方面具有重要作用。
Braam R R[6]最早提出将词和共被引结合起来,通过共被引关系聚类形成文献簇,使用标引词、标题和摘要组成的词集相似度分析识别相同主题的文献簇,探测出前沿主题。Besselaar P V D等[23]提出一种若两篇文献含有相同的主题词与参考文献,就假定这两篇文献在主题上有一定的相似性的词汇—参考文献共现的方法。Chen C开发的CiteSpace[7]将主题词与引文信息结合起来生成异构网络,将时区视图(Timezone Views)与聚类视图(Cluster Views)互补来揭示研究前沿。侯海燕等[53]以科学计量学领域为例,先使用共被引分析法获得该领域高被引核心文献,再使用共词分析探测前沿领域,最终通过科学计量学前沿知识图谱,探测出科学计量学领域前沿课题及重点研究方法。Boyack K W等[54]提出了一种从文献标题和摘要中提取主题词,将主题词看作特殊引文,然后使用文献耦合方法构建矩阵探测科学前沿的复合方法,获得更好的前沿探测效果。Liu X等[55]结合文本挖掘与文献计量方法提出了一种加权混合聚类模型方法,并对ISI 2002—2006年的大规模期刊数据进行分析,结果表明该方法可用于发现并识别不同研究领域的新兴趋势。周丽英等[56]提出了一种结合关键词共现矩阵与关键词—参考文献共现矩阵来增强共词分析效果的方法,能更精准地预测前沿主题,揭示科学结构与演化过程。
从以上研究可以看出复合分析法在科学前沿识别方面是对单一识别方法的完善改进,能够更加精确地识别科学前沿主题。但这种方法依旧存在不足:第一,复合方法对数据的处理程度较单一识别方法复杂得多,不仅要对引文进行分析处理,还需对文本内容进行分析,二者结合增加运算复杂度,应用时变得更加繁琐、复杂。第二,复合分析方法需要对从文本内容提取出的词和引文计算各自相似度,想要获得总体相似度必须先对引文和提取文本两种不同的相似度进行加权处理。加权数值的设定具有很大的主观性,需要反复调试,难以避免出现因权值设定不同而导致研究前沿探测效果差异很大的情形,在应用过程中受到很大限制。第三,不同学科、不同主题的权值设定差异较大,没有普遍适用的标准化识别指标体系,因此探测方法不一定能在跨学科的背景下获得更好的效果。
3 文本内容探测方法对比及存在的问题
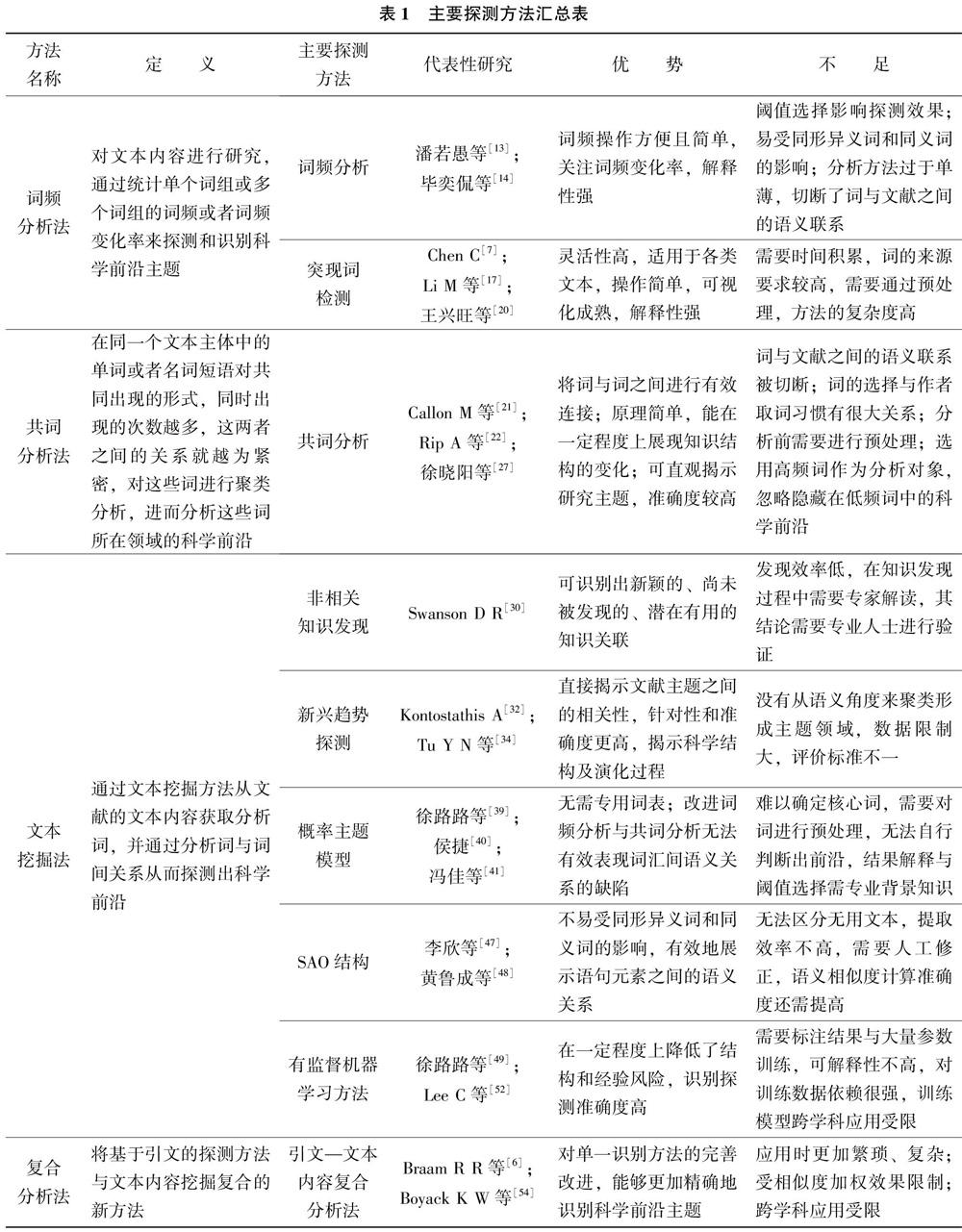
通过分析,对比得出基于文本的主要探测方法的概念、主要方法、优势与不足,如表1所示。
通过表1可以看出,基于文本内容的前沿探测方法主要存在以下问题:
1)探测过程中缺少统一的识别指标:由于科学前沿至今还没有统一定义,因此前沿探测方法需要自行设立指标对分析词进行取舍,因此无论是词频分析常用的Top50,以及共词分析常用的二八定律、主题模型常用的保留前10个主题词或是其他方法中需要通过人工修正,研究者一定程度上的主观意愿会影响识别效果。一些主观选择会导致处于低频词中的潜在科学前沿和未被关注的隐形科学前沿被遗漏。基于文本挖掘的自然语言处理算法在探测科学前沿时,由于没有统一指标,无法保证探测效果,结果仍需专家解读。
2)探测方法忽视语义关联:除去SAO结构方法,基于文本内容探测前沿的方法大多选择从已有的文本内容提取表达主旨的词汇并对其进行分析,提取方法多为主观选择(关键词)、频次选择(突现词)和统计分析选择(主题词)。这些方法或多或少地切断了词与文献之间的语义关联,单纯使用主题词不足以正确表达文献真实内容,缺少连贯性,忽视语义关联的方法也会导致无法解决同义词近义词干扰,从而降低准确度。
3)数据源无法交叉融合:已有的方法研究中,对多源数据融合的前沿探测研究较少。由于期刊论文和专利文献已有多个规模庞大的结构化数据库,目前科学前沿探测的数据主要以数据库内的文献为分析对象,很少涉及其他数据源。然而科学前沿并不只存在于期刊论文和专利文献数据中,因此探测出的科学前沿准确度不高。
4 科学前沿识别方法未来发展建议
自使用词频分析法进行科学前沿探测以来,基于文本内容的科学前沿探测方法不断发展。源于文献计量的突现词检测方法与共词分析法是目前应用最为广泛的方法,基于文本挖掘的相关方法依旧在不断发展,基于文本内容探测科学前沿方法已成为探测科学前沿的主要方法之一。通过对比分析目前已有的各种方法,针对未来发展提出如下建议:
1)明确科学前沿定义和指标。从科学前沿概念的发展过程中不难看出,随着探测方法的变化,前沿的定义也在发生变化。由于缺乏统一的指标,目前的探测过程中主要使用“文本表征词获取+文献计量分析+專家咨询”的方式衡量前沿探测结果,受专家影响较大;重要阈值设定也多为主观选择。目前常用的主题模型也并非真正用于“探测”前沿,而是对文本内容进行前期处理,实际探测方法依旧是词频分析与共词分析。理应打破从方法决定前沿的固有模式,提出一种脱离于方法的指标用于衡量前沿,才能从根本上解决探测方法过于依赖主观选择的问题。
2)语义分析与前沿探测方法融合。语义关系分析方法,不仅可以对文献进行全文本分析获得更为精确的语义信息,还可以将SAO结构等语义分析方法融入前沿探测方法,用以保证在识别探测过程中的语义关联,保证连贯性,获得更好的探测效果。
3)数据源从单一型变为混合型。随着信息技术不断发展,未来可增强多源数据交叉分析。整合科技规划文本、基金项目、研究报告等针对科学发展进程中边缘问题的数据,以支持科学前沿探测。未来前沿识别探测需要增强多源数据的深度交叉融合,发现隐藏的知识关联信息,明确知识发展脉络,有助于“隐形”科学前沿的识别。
参考文献
[1]Price D J.Networks of Scientific Papers[J].Science,1965,149(3683):510-515.
[2]Small H,C G B.The Structure of Scientific Literatures:Identifying and Graphing Specialties[J].Science Studies,1974,(1):17-40.
[3]Garfield E.The New 1956—1965 Social-science Citation Index.1.Analysis of 1988 Research Fronts and the Citation-classics that Made Them Possible[J].Current Contents,1989,(41):2-8.
[4]Persson O.The Intellectual Base and Research Fronts of JASIS 1986—1990[J].Journal of the American Society for Information Science,1994,45(1):31-38.
[5]Morris S A,Yen G,Wu Z,et al.Time Line Visualization of Research Fronts[J].Journal of the American Society for Information Science and Technology,2003,54(5):413-422.
[6]Braam R R,Moed H F,Raan A F J V.Mapping of Science by Combined Co-Citation and Word Analysis.II:Dynamical Aspects[J].Journal of the American Society for Information Science,1991,42(4).
[7]Chen C.CiteSpace Ⅱ:Detecting and Visualizing Emerging Trends and Transient Patterns in Scientific Literature[J].Journal of the American Society for Information Science and Technology,2006,57(3):359-377.
[8]Upham S P,Small H.Emerging Research Fronts in Science and Technology:Patterns of New Knowledge Development[J].Scientometrics,2010,83(1):15-38.
[9]Rotolo D,Hicks D,Martin B R.What is an Emerging Technology?[J].Research Policy,2015,44(10):1827-1843.
[10]Wang Q.A Bibliometric Model for Identifying Emerging Research Topics[J].Journal of the Association for Information Science and Technology,2018,69(2):290-304.
[11]钟镇.从高被引与零被引论文的引文结构差异看Research Front与Research Frontier的区别[J].图书情报工作,2015,59(8):87-96.
[12]羅瑞,许海云,董坤.领域前沿识别方法综述[J].图书情报工作,2018,62(23):119-131.
[13]潘若愚,姚浩浩,朱克毓.基于词频统计分析国内外文本挖掘的研究热点:第十二届(2017)中国管理学年会[C]//中国天津,2017.
[14]毕奕侃,韩毅.关键词时间分布特征视角下的研究前沿探测研究[J].西华大学学报:哲学社会科学版,2020,39(2):105-114.
[15]廖鹏飞,李明鑫,万锋.基于长尾关键词的领域新兴前沿探寻模型构建研究[J].情报杂志,2020,39(3):51-55.
[16]Kleinberg J.Bursty and Hierarchical Structure in Streams[J].Data Mining and Knowledge Discovery,2003,7(4):373-397.
[17]Li M,Chu Y.Explore the Research Front of a Specific Research Theme Based on a Novel Technique of Enhanced Co-word Analysis[J].Journal of Information Science,2016,43(6):725-741.
[18]He X R,Wu Y,Yu D,et al.Exploring the Ordered Weighted Averaging Operator Knowledge Domain:A Bibliometric Analysis[J].International Journal of Intelligent Systems,2017,32(11):1151-1166.
[19]周耀林,柴昊,赵跃.国际图情领域大数据研究现状与趋势探析[J].图书馆杂志,2019,38(12):16-27.
[20]王兴旺,董珏,余婷婷,等.基于多种类型信息计量分析的前沿技术预测方法研究[J].情报杂志,2018,37(10):70-75.
[21]Callon M,JJP C,WA T.From Translations to Problematic Networks- an Introduction to Co-word Analysis[J].Social Science Information,1983,22(2):191-235.
[22]Rip A,JP C.Co-word Maps of Biotechnology:An Example of Cognitive Scientometrics[J].Scientometrics,1984,6(6):381-400.
[23]Besselaar P V D,Heimeriks G.Mapping Research Topics Using Word-reference Co-occurrences:A Method and an Exploratory Case Study[J].Scientometrics,2006,68(3):377-393.
[24]Ravikumar S,Agrahari A,Singh S N.Mapping the Intellectual Structure of Scientometrics:A Co-word Analysis of the Journal Scientometrics(2005—2010)[J].Scientometrics,2015,102(1):929-955.
[25]蔡运荃,李保强.基于共词分析的我国高等教育研究前沿探讨——来自14种高等教育核心期刊近5年的文献计量分析[J].现代教育管理,2017,(5):44-50.
[26]赵丽梅,张花.我国大数据时代数字图书馆研究前沿分析——基于共词分析的视角[J].情报科学,2019,37(3):97-104.
[27]许晓阳,郑彦宁,刘志辉.论文和专利相结合的研究前沿识别方法研究[J].图书情报工作,2016,60(24):97-106.
[28]周文杰,张彤彤,高冲.共词分析预测研究前沿的表面效度研究:基于自然语言处理[J].高校图书馆工作,2018,38(2):17-21.
[29]周文杰.研究前沿探测的效标关联效度研究:基于自然语言处理[J].图书与情报,2018,(1):1-7.
[30]Swanson D R.Undiscovered Public Knowledge[J].The Library Quarterly,1986,56(2):103-118.
[31]白如江,冷伏海,廖君华.科学研究前沿探测主要方法比较与发展趋势研究[J].情报理论与实践,2017,40(5):33-38.
[32]Kontostathis A.A Survey of Emerging Trend Detection in Textual Data Mining[J].2003.
[33]Le M,Ho T,Nakamori Y.Detecting Emerging Trends from Scientific Corpora[J].International Journal of Knowledge and Systems Sciences,2005,2(2):53-59.
[34]Tu Y N,Seng J.Indices of Novelty for Emerging Topic Detection[J].Information Processing & Management,2012,48(2):303-325.
[35]钟辉新.新兴趋势探测研究综述[J].现代情报,2017,37(12):162-167.
[36]Blei D M,A Y Ng,Jordan M I,et al.Latent Dirichlet Allocation[J].Journal of Machine Learning Research,2003,3(4-5):993-1022.
[37]Wang X,Mccallum A.Topics Over Time:A Non-Markov Continuous-time Model of Topical Trends:ACM,2006.
[38]Wu Q,Zhang C,An X.Topic Segmentation Model Based on ATNLDA and Co-occurrence Theory and Its Application in Stem Cell Field[J].Journal of Information Science,2013,39(3):319-332.
[39]徐路路,王效岳,白如江.基于PLDA模型与多数据源融合相关性分析的新兴主题探测研究——以石墨烯领域为例[J].情报理论与实践,2018,41(4):63-69.
[40]侯捷.基于文本挖掘的管理科学学科研究热点及前沿发现与分析[D].北京:北京工业大学,2019.
[41]冯佳,张云秋.基于LDA和本体的科学前沿识别与分析方法研究[J].情报理论与实践,2017,40(8):49-54.
[42]张晖,杨小彦,赵旭劍,等.基于社会网络关注度的学科前沿热点挖掘[J].郑州大学学报:理学版,2018,50(3):46-52.
[43]刘博文,白如江,周彦廷,等.基金项目数据和论文数据融合视角下科学研究前沿主题识别——以碳纳米管领域为例[J].数据分析与知识发现,2019,3(8):114-122.
[44]颜端武,苏琼,张馨月.基于时序主题关联演化的科学领域前沿探测研究[J].情报理论与实践,2019,42(7):144-150.
[45]Yoon J,Park H,Kim K.Identifying Technological Competition Trends for R&D Planning Using Dynamic Patent Maps:SAO-based Content Analysis[J].Scientometrics,2013,94(1):313-331.
[46]Choi S,Yoon J,Kim K,et al.SAO Network Analysis of Patents for Technology Trends Identification:A Case Study of Polymer Electrolyte Membrane Technology in Proton Exchange Membrane Fuel Cells[J].Scientometrics,2011,88(3):863-883.
[47]李欣,谢前前,黄鲁成,等.基于SAO结构语义挖掘的新兴技术演化轨迹研究[J].科学学与科学技术管理,2018,39(1):17-31.
[48]黄鲁成,张璐,吴菲菲,等.基于突现文献和SAO相似度的新兴主题识别研究[J].科学学研究,2016,34(6):814-821.
[49]徐路路,王芳.基于支持向量机和改进粒子群算法的科学前沿预测模型研究[J].情报科学,2019,37(8):22-28.
[50]董放,刘宇飞,周源.基于LDA-SVM论文摘要多分类新兴技术预测[J].情报杂志,2017,36(7):40-45.
[51]李松,刘力军,解永乐.遗传算法优化BP神经网络的短时交通流混沌预测[J].控制与决策,2011,26(10):1581-1585.
[52]Lee C,Kwon O,Kim M,et al.Early Identification of Emerging Technologies:A Machine Learning Approach Using Multiple Patent Indicators[J].Technological Forecasting and Social Change,2018,127:291-303.
[53]侯海燕,刘则渊,栾春娟.基于知识图谱的国际科学计量学研究前沿计量分析[J].科研管理,2009,30(1):164-170.
[54]Boyack K W,Klavans R.Co-citation Analysis,Bibliographic Coupling,and Direct Citation:Which Citation Approach Represents the Research Front Most Accurately?[J].Journal of the American Society for Information Science and Technology,2010,61(12):2389-2404.
[55]Liu X,Yu S,Janssens F,et al.Weighted Hybrid Clustering By Combining Text Mining and Bibliometrics on a Large-scale Journal Database[J].Journal of the American Society for Information Science and Technology,2010.
[56]周丽英,冷伏海,左文革.引文耦合增强的共词分析方法改进研究——以ESI农业科学研究主题划分为例[J].情报理论与实践,2015,38(11):120-125.
(责任编辑:陈 媛)
