
基于数据空间网格化的密度峰值聚类算法
2021-01-16 02:53张萍
廊坊师范学院学报(自然科学版) 2021年4期



【摘要】密度峰值聚类方法能够对数据进行聚类,且适用于任意形状数据集的聚类。但当数据量增大时,算法的时间复杂度和存储开销也会大幅增加。针对此问题,提出一种基于数据空间网格化的密度峰值聚类方法,将数据每个维度的对应值域等分为若干区间,即将数据空间分成若干网格,在计算局部密度和距离时,仅需利用相邻网格的点。实验表明,该方法在保证聚类质量的前提下能极大地减少计算时间和占用内存,具有较高的可靠性和有效性。
【关键词】密度峰值;网格化;聚类;数据空间
〔中图分类号〕TP183 〔文献标识码〕A 〔文章编号〕1674-3229(2021)04-0019-05
0 引言
聚类算法是根据数据的相似性,把相同或者具有相似特征的数据划分成同一组进行特征分析,用于数据的进一步挖掘。目前,聚类算法被广泛应用于电子商务、社区检测以及图像分割等方面[1]。但大多数聚类算法都存在着聚类中心确定困难、聚类精度低、数据集自适应性不高,导致聚类效率低下和参数依赖性等问题。针对这些问题,2014年,A.Rodriguez等[2]首次提出了密度峰值聚类(DensityPeak Clustering,DPC)算法,该算法结合密度和距离两个维度选择出聚类中心,且不需要任何迭代。此后,学者们对DPC方法进行了一些改进,如R.Mehmood等提出了一种模糊CFSFDP方法[3],可有效而自适应地选择聚类中心;其他学者根据高斯分布的3B原则[4],每个点的影响半径为3σ(其中σ是数据点的标准差),使用数据的潜在嫡自动计算截断距离dc,提高聚类效果[5-6];高诗莹等[7]通过计算数据样本中的密度比,减少密度较小类簇的遗漏,提高聚类精度;Shuliang Wang等[8]使用多变量的核密度估计方法自动选择截断距离dc;Rashid Mehmood等[9]基于热方程,使用另一个非参数密度估计器进行密度估计;Z.Yan等[10]提出基于点与第k个最近邻点之间的距离(称为半径)来估计每个点的局部密度,同时利用两个点的k个最近邻点的交点较小,分配不同的聚类特性,改进了DPC算法的分配策略:在KNN核密度估计(NKD)[11]的启发下,Geng YA等[12]利用相对k最近邻核密度(RNKD)来估计点的密度,解决了NKD在类密度不均匀的情况下聚类性能不佳的问题,设计了RECOME算法。
DPC在聚类过程中,需要计算每个数据点的局部密度和每个数据点与其他较高局部密度点之间的最短距离,其时间复杂度为O(N2),存储开销为O(1/2N2)。对于大规模数据集,为提高效率,ShichaoCheng[13]等提出了FDP算法,使用k-dtree建立指标索引,只计算当前点的k个最近邻。王飞等[14]提出了基于网格的密度峰值聚类算法(GDPCA)。该算法根據数据集的分布,按照一定的规则自适应地划分网格,并将数据按照规则映射到网格空间中,然后对每个网格空间的数据使用密度峰值聚类算法进行聚类分析,接着根据边界点的分布进行相邻网格聚类结果的合并,其不足之处在于没有利用距离这个维度,在一些数据集上无法达到令人满意的效果。Courjault-rad等在2016年提出IDPC算法[15],通过使用缩小窗口(ICMDW)迭代封面图来构建密度图,从而减少维度,但当局部密度较高时,迭代次数会急剧增加。
本文提出的基于数据空间网格化的密度峰值聚类(LSDPC)算法利用相邻网格所在的点计算密度,而不必基于所有全局数据点两两之间的距离来计算密度;最后得到的决策图是全局数据点的决策图,而不必像文献[14]再进行各个网格聚类结果的合并;在保证聚类质量的前提下,极大地减少了计算时间和内存的开销。
1 密度峰值聚类(DPC)算法
密度峰值聚类算法中,聚类中心的确定需要给出样本点的局部密度ρ和两个样本点之间的距离δ。假设待聚类的数据集s={xi}i=1N,数据点xi和xj之间的距离可以表示为dij=dist(Xi,Xj)。定义S中任意数据点xi的两个参数为ρi和δi,ρi表示当前点的局部密度,δi表示密度大于当前点且离当前点最近的距离。使用截断核函数来定义数据点Xi的局部密度ρi,其表达式如下:其中参数dc为截断距离(Cut-off distance)。定义Xi与Xj之间的最小距离δi为:
在计算δi的时候同时记录ρ值更大的数据点中与第i点距离最近的点的编号j,记做L(i)。
计算综合考虑ρ值和δ值的聚类决策值γi,用来确定一个聚类中心,如式(3)
γi=ρiδi,i∈IS(3)
DPC算法的具体步骤如下:
DPC算法的瓶颈在于计算数据点的密度时,要利用所有数据点间的距离进行密度值的计算。一种做法是引入一个(对称的)距离矩阵,用来存储数据集中的任意两个点之间的距离,但是这种方法的时间复杂度为O(N2),且需要O(1/2N2)的存储开销。
对于样本点的局部密度ρi的计算,需要求出Xi和其他样本点之间的所有距离dij{j=1…N,j≠i}。因此,ρ的计算复杂度为O(N2)。
对于两个样本点之间的距离δi,需要对所有的ρ进行排序,并查找比较大于ρi的所有点的距离。因此,δ的计算复杂度为O(1/2N2)。
2 基于数据空间网格化的密度峰值聚类算法
2.1 问题分析
用DPC算法计算局部密度ρi耗时较长,当数据量增大时,这个问题尤为突出。有效计算局部密度ρi的瓶颈在于要求出Xi和其他样本点之间的所有距离dij{j=1…N,j≠i}。实际上,随着样本点的距离越近,它对局部密度ρi的贡献越大,而其他点对密度的贡献随着到目标点的距离增大而呈指数衰减。据此,本文将样本在n维空间进行划分,对每一个维度等量划分,将全空间划分为互不相交的网格单元。如图1所示,在二维数据的情况下,对于圆点所在的编号14的网格,本文只需要将上下左右以及斜线上的8个相邻网格以及自身网格(编号为8,9,10,13,14,15,18,19,20)中点集合做密度计算,求近似值即可。只需搜索相邻网格的局部点来近似计算局部密度,不用对所有数据点间的距离进行排序,避免样本点对上的重复计算。
图1 二维空间网格化
同样,对于两个样本点之间的距离s,只考虑相邻网格的点即可。因为距离最近的点一定在相邻的网格中,只需查找这些网格中密度ρj比它大的点即可。如果不存在密度比它大的点,说明该点是局部密度最大,可以参加第二次的全局密度比较。
该相邻网格计算法显著降低了原始DPC算法中密度计算成本,却获得了几乎相等的聚类效果。图2第一列展示了数据集flame上,DPC算法截断距离dc=4%的情况下以及LSDPC算法截断距离dc=8%、网格数为5×5情况下的聚类结果和決策图。图2第二列展示了数据集S2上,DPC算法截断距离dc=4%的情况下以及LSDPC算法截断距离dc=8%、网格数为88×88情况下的聚类结果。
图2 Flame和S2数据集上DPC和LSDPC的聚类结果比较
2.2 算法步骤
LSDPC算法步骤如下:
2.3 计算复杂度分析
假设样本数为N,则ρ的计算复杂度为O(N2),δ的计算复杂度为O(1/2N2)。分成m个网格后,则每个网格平均有N/m个点,对每个网格来说,有k个邻居,ρ的计算复杂度为(kN/m)2,全部的计算复杂度为m*(kN/m)2=k2*N/m*N。根据归纳总结则计算复杂度为O(kN)。
同样可以求得δ的计算复杂度为O(kN)。
3 实验分析与讨论
3.1 评价指标
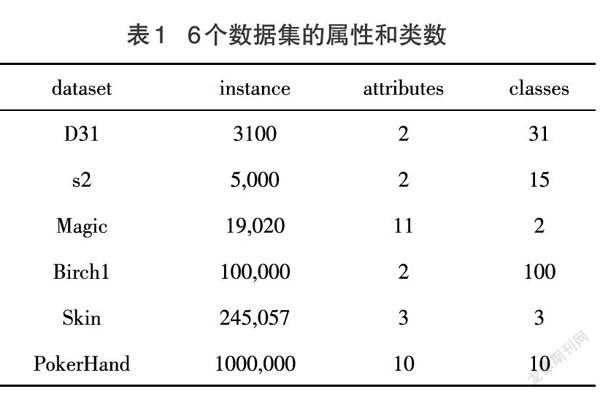
为了验证本文算法的性能,使用了6个模拟数据集,每个数据集的属性数量和类数如表1所示。
表1 6个数据集的属性和类数
为了客观评价比较聚类算法,本文从三个方面来评估:内部评价指标、外部评价指标和运行时间[16]。内部评价指标使用戴维森堡丁指数(Da-vies-Bouldin Index),DB越小意味着类内距离越小,同时类间距离越大,聚类效果越好。外部评价指标使用调整兰德指数(Adjusted Rand index ARI),ARI考虑到同一个聚类和不同聚类中存在的实例数。ARI取值范围为[0,1],值越大意味着聚类结果与真实情况越吻合。值为1的时候代表所有的样本都被正确地聚类,每个聚类只包含本类样本。从广义的角度来讲,ARI衡量的是两个数据分布的吻合程度。
3.2 实验结果比较
为了验证算法的有效性,首先在随机生成的包含三类的高斯数据集及随机生成的包含二类的均匀分布的数据集上进行比较。图3分别展示了高斯数据集和均匀数据集的聚类效果。可见两者算法都能达到较好的聚类效果,并且都能从决策图上识别出聚类中心。
图3 随机高斯数据集和均匀数据集上DPC和LSDPC的聚类结果及决策图比较
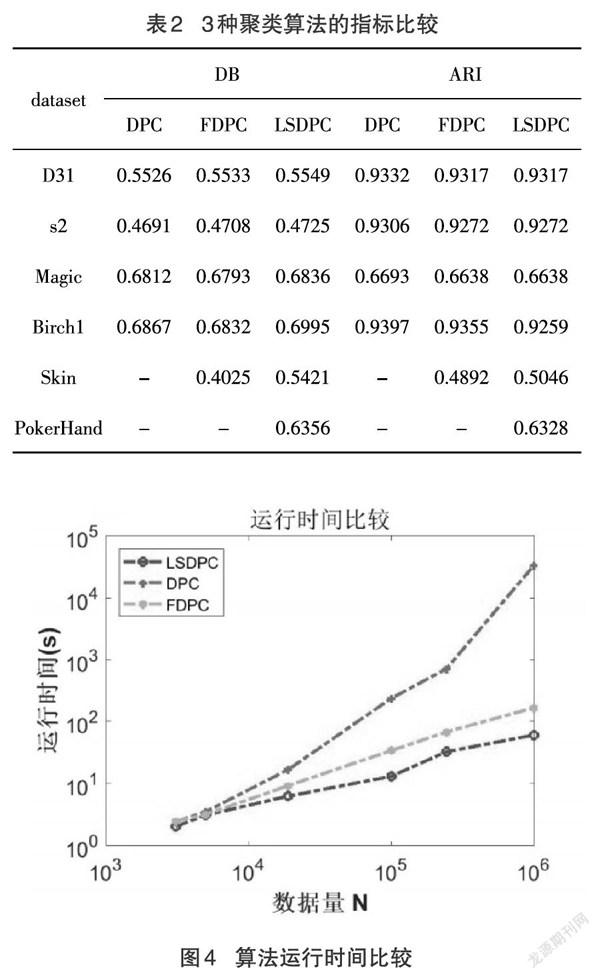
表2展示了DPC、FDPC[13]、LSDPC在6个数据集上的DB、ARI指标结果。对于每个聚类算法,每个度量的最佳值都以粗体显示。而“-”代表无法度量,内存溢出。
从表2可以看出LSDPC算法与DPC、FDPC聚类算法相比,LSDPC算法在6个数据集上,基于所有外部度量提供了最佳的聚类输出。
表2 3种聚类算法的指标比较
图4算法运行时间比较
图4显示了三种聚类算法的运行时间比较结果。当N=104时,LSDPC使用的时间与FDPC相差不大;相比于DPC,LSDPC节省了1个数量级。当N=106时,LSDPC使用的时间相比于FDPC节省了一个数量级;对比DPC,LSDPC节省的时间将达到3个数量级。结合表2可以看出,LSDPC在聚类指标(ARI、DB)上十分接近DPC,而且随着数据量的增大,指标值更为接近。虽然LSDPC在聚类指标ARI上略低于DPC,但可以极大地减少运行时间。
4 结论
本文针对在大规模数据聚类时,DPC算法所需时空代价急剧增大的问题,提出了数据空间网格化的密度聚类方法。LSDPC算法将数据每个维度对应值域等分为若干区间,将数据空间分成若干网格,同时仅利用相邻网格所在的点计算局部密度和距离。文中将LSDPC在6个数据集上作了实验,并从ARI、DB、运行时间三个方面对LSDPC结果进行分析比较。当数据量增大时,该方法对比DPC来说,极大地降低了算法的时间和内存消耗。例如,当原始数据样本点数大小超过100,000时,所提算法仍能在可承受的时间和内存中执行。但本文实验中的网格数目采用经验方法来确定,今后可根据不同的数据集来确定网格数目,改进算法,以提高聚类算法的准确性。
[参考文献]
[1]Olfa Nasraoui,Chiheb-Eddine Ben N'Cir.Clustering Meth-ods for Big Data Analytics[M].Switzerland:Springer,Cham,2019.
[2]Rodriguez A,Laio A.Machine learning.Clustering by fastsearch and find of density peaks[J].Science,2014,344(6191):1492.
[3]Mehmood R,Bie R,Dawood H,et al.Fuzzy Clustering byFast Search and Find of Density Peaks[J].Personal&Ubiq-uitous Computing,2016,20(5):785-793.
[4]Barany I,Vu V H.Central limit theorems for Gaussian poly-topes[J].Annals of Probability,2006,35(4):1593-1621.
[5]Ji C,Lei Y.Parallel clustering by fast search and find ofdensity peaks [A].2016 International Conference on Au-dio,Language and Image Processing(ICALIP)[C].NewYork:IEEE Xplore,2017:563-567.
[6]Wang S,Wang D,Caoyuan L 1,et al.Clustering by FastSearch and Find of Density Peaks with Data Field[J].Chi-nese Journal of Electronics,2016,25(3):397-402.
[7]高诗莹,周晓锋,李帅.基于密度比例的密度峰值聚类算法[J].计算机工程与应用,2017,53(16):10-17.
[8]WANG Shuliang,WANG Dakui,LI Caoyuan,et al.Cluster-ing by Fast Search and Find of Density Peaks with DataField[J].Chinese Journal of Electronics,2016,25(3):397-402.
[9]Mehmood R,Zhang G,Bie R,et al.Clustering by fastsearch and find of density peaks via heat diffusion[J].Neu-rocomputing,2016(208):210-217.
[10]Yan Z,Loo W,Bu C,et al.Clustering spatial data by theneighbors intersection and the density difference[A].2016 IEEE/ACM 3rd International Conference on Big DataComputing Applications and Technologies(BDCAT)[C].New York:IEEE Xplore,2016:217-226.
[11]Tran T N,Wehrens R,Buydens L M C.KNN-kerneldensity-based clustering for high-dimensional multivari-ate data[J].Computational Statistics&Data Analysis,2006,51(2):513-525.
[12]Geng Y A,Li Q,Zheng R,et al.BECOME:a New Densi-ty-Based Clustering Algorithm Using Relative KNN Ker-nel Density[J].Information Sciences,2018:13-30.
[13]Shichao Cheng,Yuzhuo Duan,Xin Fan,et al.Review ofFast Density-Peaks Clustering and Its Application to Pedi-atric White Matter Tracts[J].Medical Image Understand-ing and Analysis,2017:436-447.
[14]王飛,王国胤,李智星,等.一种基于网格的密度峰值聚类算法[J].小型微型计算机系统,2017,38(5):1034-1038.
[15]Vincent Courjault-Radé,Ludovic D'Estampes,St6phane Pu-echmorel.Improved density peak clustering for large datasets[EB/OL].https://hal.archives-ouvertes.fr/hal-01353574,2016-12-12.
[16]Zhang Y,Cheny S,Yu G.Efficient Distributed DensityPeaks for Clustering Large Data Sets in MapReduce[A].2017 IEEE 33rd International Conference on Data Engi-neering(ICDE)[C].New York:IEEE Xplore,2017:67-68.
[收稿日期]2021-07-28
[基金项目]莆田学院科研项目“基于张量数据的显著性检测算法研究”(2016041)
[作者简介]张萍(1982-),女,硕士,莆田学院机电与信息工程学院讲师,研究方向:计算机视觉、机器学习。
猜你喜欢
计算机与网络(2021年20期)2021-12-18
时代人物(2020年2期)2020-06-19
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
知识文库(2018年9期)2018-10-20
软件(2017年6期)2017-09-23
教书育人·校长参考(2017年2期)2017-03-07
电子技术与软件工程(2016年23期)2017-03-06
商情(2016年50期)2017-02-28
中国信息化周报(2016年45期)2016-12-27
民主(2016年10期)2016-11-30
