
基于TLSmote-SVM的非均衡用户窃漏电诊断算法
2021-01-18 08:14杜星秋温东欣唐伟宁张洪明
吉林大学学报(理学版) 2021年1期
刘 颖, 杜星秋, 温东欣, 唐伟宁, 张洪明
(1. 吉林财经大学 管理科学与信息工程学院, 长春 130117;2. 国网吉林省电力有限公司 电力科学研究院, 长春 130021)
窃漏电行为是电力系统检测的重点, 目前的反窃电方法主要为人工检测, 存在工作量大、 效率低、 取证困难和缺乏针对性等问题. 机器学习源于统计模型拟合, 目前, 应用机器学习技术诊断窃漏电行为的方法主要有逻辑回归[1]、 聚类分析[2]和深度学习[3]等. 支持向量机(support vector machines, SVM)作为一种经典的模式识别方法, 具有泛化能力强、 结构简单, 易解决具有高维度、 小样本等问题的优势. 将支持向量机技术应用于窃漏电行为的检测目前已有很多研究结果[4-6]. 窃漏电用户用电检测过程中, 异常用户数量通常只占少数, 导致获取的数据样本存在严重的分布不均衡现象. SVM分类算法大多都基于正负类样本数量大致相同的假设, 在SVM训练分类模型过程中, 样本不均衡可能导致分类超平面偏移而影响分类精度.
针对非均衡数据分类问题, 通常采用两种解决策略: 一种是改变分类算法, 在传统分类算法的基础上对不同类别采用不同的加权方式, 更看重少数类; 另一种是改变数据分布, 从数据层面平衡样本类别, 主要包括随机欠采样和过采样方法. 欠采样算法是减少多数类样本数量, 预先设置多数类与少数类最终的数量比例, 在保留少数类样本不变的情形下, 根据比例随机选择多数类样本. 例如: 韩旭等[7]采用高斯混合模型对多数类样本进行聚类欠采样消除样本间的不平衡问题; 金旭等[8]先通过求解样本间的欧氏距离, 再利用k-means算法在大类样本集上进行聚类, 使数据集在分布上更均衡; Liu等[9]将EasyEnsemble 和BalanceCascade两种算法相融合提取多数类样本子集, 从而实现数据的再平衡. 通常, 欠采样依赖于样本分布, 但也容易丢失部分多数类样本信息. 过采样方法主要是通过增加少数类样本数量, 即在保留多数类样本不变的情况下, 随机复制少数类样本. 蒋宗礼等[10]利用变分自编码器均衡训练数据集; Estabrooks等[11]提出基于随机过采样算法弥补SVM缺失的代价敏感性; Chawla等[12]和张月平等[13]采用Smote算法借助少数类样本及其邻域样本生成新数据, 提高算法分类性能. 过采样方法操作简单, 但重复样本过多, 易导致分类器的过拟合问题. 因此, 解决非均衡问题, 既要考虑多数样本的数据分布, 避免剔除多数样本时丢失有用信息, 又要克服分类器过拟合现象[14-15]. 基于此, 本文提出一种将欠采样和过采样相融合的TomekLink-Smote(TLSmote)方法, 解决窃漏电非均衡检测问题, 先利用Smote方法扩充少数类样本, 同时考虑距离SVM分类超平面较近的样本, 根据其重要度使少数样本被反复学习; 再采用Tomek-link算法剔除多数类样本并进行噪声处理. 将本文算法应用于非均衡用户窃漏电诊断实验, 结果表明, TLSmote-SVM算法既能有效去除非均衡优化过程中产生的噪声样本, 提高数据的利用率, 又能在保留尽可能多有用信息的前提下实现样本均衡, 有效提高窃漏电用户的检测精度.
1 基于TLSmote算法的SVM窃漏电诊断模型
1.1 支持向量机
支持向量机是在特征空间中寻找一个将两类样本分隔的超平面, 且样本与超平面的距离尽可能大. 设正负样本与超平面的距离为
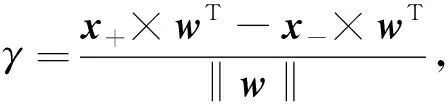
(1)

给定样本x, 若使对应的y与距离的计算同号, 则

(2)
其中yi∈{+1,-1}为分类标记,b表示偏移量. 将其代入式(1)可得

(3)
SVM的核心思想是使γ尽可能大, 即‖w‖/2最小:

(4)
采用Lagrange乘子法得到其对偶问题为

(5)
求导解出w和b, 即可得到所求超平面.
支持向量机常用的核函数有线性核函数、 多项式核函数、 高斯核函数和Sigmoid核函数, 常用的参数包括核函数选择参数Kernel、 惩罚参数C、 多项式维度参数Degree、 核函数参数Gamma、 核函数常数项coef0、 最大迭代次数max_iter等. 为比较不同核函数及参数取值对支持向量机分类精度的影响, 本文随机抽取部分用户用电数据, 在样本均衡的情形下, 比较4种核函数的分类超平面变化情况. 图1为SVM在线性核函数和高斯核函数下不同参数取值的分类结果. 由图1可见, 不同核函数及参数取值对分类精度有较大影响, 根据实验结果, 本文模型选用高斯核函数.
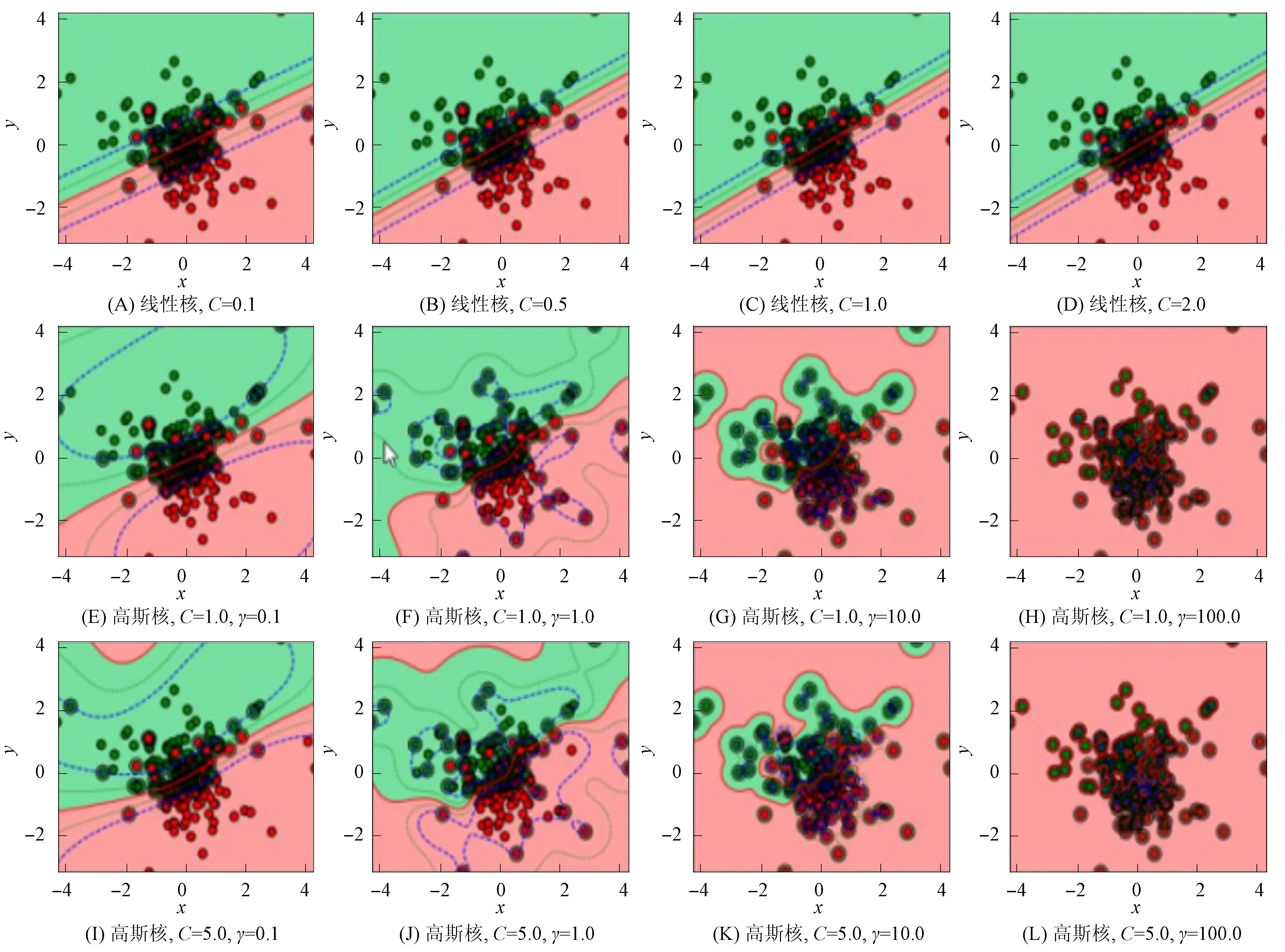
图1 SVM在线性核函数和高斯核函数下不同参数取值的分类结果Fig.1 Classification results of SVM with different parameter values under linear kernel function and Gaussian kernel function
1.2 TomekLink-Smote算法
传统Smote算法生成新的少数类样本平衡数据类别时, 首先随机选择少数类样本n, 从其最近邻中随机选取一个样本m, 然后在n和m之间的连线上随机生成一个样本点作为新样本. 通常, Smote算法忽略了少数类样本类内不平衡现象的存在, 并易受噪声影响. 当不平衡度较高时, 合成的新少数类样本点会与原始数据高度相似, 甚至重复, 很难为分类器提供新的分类信息. Tomek-Link的基本思想是: 少数类样本x与多数类样本y, 如果不存在另外一个多数类样本z, 使得d(x,z) 本文首先对样本集进行预处理并对其属性降维, 将欠采样Tomek-Link与过采样Smote算法相结合, 对二分类非均衡样本集进行类别补全并剔除噪声, 最后选择不同正负比例的样本对SVM进行训练与测试, 比较最终分类的精度. TLSmote-SVM算法如下. 算法1TLSmote-SVM算法. 步骤1) 处理数据缺失值和异常值, 将数据归一化; 步骤2) 根据协方差矩阵计算特征值和特征向量, 保留前4个特征向量; 步骤3) 利用Smote算法随机选定n个少数类样本, 采用欧氏距离计算距离最近的m个样本, 在两点间选定中间点作为新增样本点, 使得少数类与多数类样本数量均衡; 步骤4) 用TomekLink判定新增样本点是否为有效点, 若有效, 则判定新增样本为非噪声样本, 转步骤5); 否则, 剔除噪声样本后重复步骤3)和步骤4), 直至正负样本比例平衡; 步骤5) 初始化SVM分类器, 选择高斯核函数, 参数C和Gamma取默认值, 利用测试集训练SVM; 步骤6) 输出准确率与精确度. 本文所用数据来自国网吉林省电力有限公司电力科学研究院, 数据包含2014—2017年吉林省某地区用电负荷数据, 数据规模为439 409条, 包括12个字段, 分别是用户序号、 用户类型、 供电电压、 合同容量、 运行容量、 综合倍率、 日期、 总用电量、 平时段用电量、 峰时段用电量、 尖时段用电量、 谷时段用电量. 通常, 窃电用户通过篡改电表使电表用电负荷为零或小于其实际用电负荷, 图2和图3分别为正常用户(编号为A01,A306,D081)和窃漏电用户(编号为D8,C52,C17)使用电量的数据曲线. 图2 正常用户用电数据Fig.2 Electricity consumption data of normal users 图3 异常用户用电数据Fig.3 Electricity consumption data of abnormal users 本文用数据缺失值填补、 数据异常值处理以及数据归一化3个步骤对电网数据进行预处理. 2.2.1 缺失值处理 当时间序列数据出现大量缺失值时, 缺失值的整体填充会引入噪声. 为避免该问题, 本文首先剔除缺失量达50%的数据样本, 同时对少量缺失值用下列均值填充的方法: (6) 其中D表示缺失时间段用电量的均值,data1和data2分别表示缺失段后端和前端电表示数,num表示缺失段天数. 2.2.2 异常值处理 若用户用电量数据中20%以上为负值, 则删除该序列; 若少于20%为负值, 则视为缺失值, 对缺失值的处理同上. 2.2.3 数据归一化 用归一化消除不同量纲下的数据表示: (7) 其中X表示数据归一化前的原始数值,Xmax表示数据归一化前所在维度下所有值的最大值,Xmin表示数据归一化前所在维度下所有值的最小值,X*表示归一化的特征值. 特征构建是检测异常数据的关键, 本文分别按每日用电量、 每15 d用电量(当日及其后连续14 d用电量)对该数据集中所包含时间序列的特征进行提取. 10个特征分别是日用电量均值E_MEAN、 日用电量标准差E_STD、 日用电量方差E_VAR、 日用电量变异系数E_CV、 日用电量偏度E_SKEW、 每15 d用电量标准差系数均值FT_MEAN、 每15 d用电量标准差系数标准差FT_STD、 每15 d用电量标准差系数方差FT_VAR、 每15 d用电量标准差系数变异系数FT_CV、 每15 d用电量标准差系数偏度FT_SKEW等, 特征指标列于表1. 表1 特征指标Table 1 Characteristic indexes 从已知样本中抽取20个用户作为测试集, 从剩余样本中抽取180条数据作为训练集, 计算10个维度的特征值, 经主成分分析(PCA)得出贡献度在10%以上的特征有4维, 实验选取贡献度前4维度指标训练SVM分类器, 总方差解释列于表2. 表2 总方差解释Table 2 Total variance interpretation 本文采用基于高斯核函数和TLSmote-SVM算法检测国电网吉林省某地区非均衡窃漏电用户, 并与传统SVM, Smote-SVM算法进行对比. 利用混淆矩阵的准确度和精确度作为评价指标, 其中TN表示被正确识别的负类样本, FP表示被错误识别的负类样本, FN表示被错误识别的正类样本, TP表示被正确识别的正类样本, 准确度为 (8) 精确度为 (9) 实验中, 取惩罚函数C=1.0, Gamma=0.1, 分类准确度和精确度结果列于表3. 由表3可见: 在样本比例均衡情形下, SVM与TLSmote-SVM算法的准确度(0.84)相同, Smote-SVM和TLSmote-SVM算法的精确度高于SVM算法; 当样本比例达7∶3时, TLSmote-SVM算法的准确度(0.92)和精确度(0.90)均高于Smote-SVM算法的准确度(0.88)和精确度(0.85), 更高于传统SVM算法. 实验结果表明, 本文方法在检测用户异常用电时更有效. 由表3还可见, 当样本比例为8∶2和9∶1时, 3个模型的精确度和准确度相同, 说明当样本出现极度不均衡时, 重采样方法效果不佳. 表3 不同样本比例的SVM模型分类准确度和精确度比较Table 3 Comparison of classification accuracy and precision of SVM models with different sample proportions 综上所述, 本文以国电网吉林省某地区用户用电数据为例, 分析了用户用电过程中涉及的影响因素, 选取日用电量均值E_MEAN、 日用电量方差E_VAR、 日用电量标准差E_STD、 日用电量变异系数E_CV、 日用电量偏度E_SKEW、 每15 d用电量标准差系数均值FT_MEAN、 每15 d用电量标准差系数方差FT_VAR、 每15 d用电量标准差系数标准差FT_STD、 每15 d用电量标准差系数变异系数FT_CV、 每15 d用电量标准差系数偏度FT_SKEW作为特征指标体系. 针对传统SVM分类器在处理非均衡数据时分类平面向少数类偏移而导致分类精度较低的问题, 提出了一种将Tomeklink欠采样和Smote过采样相融合的方法, 避免了欠采样过程中剔除多数样本时导致有用信息缺失以及克服Smote过采样产生的过拟合问题, 模型使用支持向量机作为基分类器. 将TLSmote-SVM模型应用于窃漏电非均衡检测问题, 实验结果表明, 在窃漏电样本非均衡分布时, 模型检测效果较好.1.3 基于TLSmote算法的SVM分类模型
2 实验结果与分析
2.1 数据来源


2.2 数据预处理


2.3 特征构建与降维


2.4 不同样本比例下分类器的比较分析



猜你喜欢
电力设备管理(2022年8期)2022-11-25
电气技术(2022年5期)2022-05-23
建材发展导向(2022年3期)2022-04-19
计算机技术与发展(2020年9期)2020-11-26
宁夏画报(2019年2期)2019-06-11
数学学习与研究(2018年14期)2018-10-29
中学数学杂志(初中版)(2014年1期)2014-02-28
中学生数理化·八年级数学人教版(2008年6期)2008-09-05
