
基于Dandelion编码生成有界树宽CP-nets
2021-01-21 03:23李丛丛刘惊雷
计算机应用 2021年1期
李丛丛,刘惊雷
(烟台大学计算机与控制工程学院,山东烟台 264005)
0 引言
条件偏好网络(Conditional Preference networks,CP-nets)是常见的图模型之一,它以一种紧凑简洁的方式有效地表示了复杂的多元域中随机变量的条件偏好。该网络由两部分组成:编码生成了模型中变量间依赖或独立关系的有向无环图(Directed Acyclic Graph,DAG)以及能够重构条件偏好的条件偏好表(Conditional Preference Table,CPT)。随着模型中变量数的增多,从数据中对CP-nets网络的推理学习是NP-hard。
树宽为k的树结构(k-tree)是对树结构最自然、最有趣的概括之一[1-2],国内外的研究者通过k-tree 来学习约束CP-nets的有界树宽结构,且越来越多的研究者对开发有效的工具来操作这类图非常感兴趣。事实上,每个树宽为k的图都是ktree的子图,利用此特征,用k-tree来约束CP-nets的树宽,并实现其生成问题[3]。有界树宽的CP-nets 在进行推理运算时可提高推理算法的效率并且有许多NP-hard 问题在有界树宽的图模型中已经被证明是多项式可解的[4]。由此可知,有界树宽的CP-nets 提高了图模型推理的效率且保障了推理计算的有效性。
本文利用k-tree 生成有界树宽的CP-nets,主要研究的是由Dandelion 编码与k-tree 双向映射的过程,并且利用k-tree 完成对CP-nets树宽的约束。由k-tree编码形成标记序列的过程中,要经过以下步骤:首先由k-tree 转换为Renyik-tree;再者由Renyi tree 转换为特征树[2];最后由对应的特征树编码成Dandelion编码序列。相反在Dandelion解码生成k-tree的过程中,经过以下步骤:首先由Dandelion 编码生成特征树;由特征树生成Renyi tree;最后由Renyitree转换生成对应的k-tree。
本文有如下的特点和贡献:
1)针对特殊结构(有界树宽)的CP-nets 的生成问题提出了一种基于Dandelion 编码的算法框架,其核心思想是通过Dandelion编码来生成有界树宽的CP-nets结构,建立了编码与结构的一对一关系;完整实现了k-tree的生成过程。由此随机均匀地生成限定树k的CP-nets。
2)与传统的生成方法不同,所提出的算法由Dandelion编码生成有界树宽的CP-nets(Generating CP-nets with Bounded Tree Width based on Dandelion code,BTW-CP-nets Gen)的完整过程是在线性时间内完成。在线性时间内生成高质量的有界树宽CP-nets来提高推理算法的效率有更高的应用价值。
3)将生成的图结构用于常见的CP-nets 推理算法——占优查询。以此推理算法来检测生成结构更均匀,且验证推理算法难度的影响因素。基于实例数据集样本进行测试,生成多样式有界树宽的图模型,通过对特殊结构图模型进行推理运算证明其推理算法其时间消耗严重依赖于图的树宽结构。
1 相关工作
近年来,有界树宽图模型的生成已受到国内外众多领域研究者们的关注。标记树的编码问题在文献中得到了广泛的研究。
CP-nets首先由Boutilier等[4]在2004年提出。他们利用条件性的其他条件不变的偏好规则,以实现偏好关系的紧凑表示。近年来,在国内,研究者们大多数都通过图来表示随机变量间的依赖关系,为多变量统计建模提供了有力的表示框架[5]。图模型理论的基础是问题域中不同属性集之间的条件独立性与结构的多样性其中结构的多样性[6],可根据标记编码生成[7]。Robinson[7]研究了标记和未标记的DAG计数问题,推导了生成DAG结构的编码中的递归式。
以往的研究工作提出了几种实现标记树与标记序列之间关联的双射码[8-9]。1970年,Renyi[10]推广了Pruffer关于Cayley定理编码标记k-tree 子集的双射证明,并命名有根的k-tree 为Renyik-tree。他们在Renyik-tree 中引入了一个冗余的Pruffer码,并对有效码字进行了特征描述。随后,产生了k-tree(或Renyik-tree)与一组定义良好的字符串之间的双射的非冗余码[11-12]并结合编码和解码算法。Caminiti 等[13]提出了利用冗余Pruffer 码对Renyik-tree 进行编码和解码算法;但是此算法的时间复杂度非线性时间[14-17],并且所提出的解码算法在非有效码字的字符串上失败。算法以这些结果为基础来研究基于Dandelion编码生成有界树宽CP-nets的情况。
以往研究工作提出了几种学习有界树宽图结构的算法。文献[18]设计了一种近似算法,结合多种启发式算法计算树宽并学习图结构。Korhonen等[19]提出了一种基于动态规划的学习算法,学习最多k个树宽的n个节点贝叶斯网络。他们的算法保证在复杂度为O(3nnk+O()1)的树宽约束下,在n个节点上寻找给定评分函数的最优结构。2018 年,王慧玲等[17]就目前有界树宽的贝叶斯网络结构近似学习技术做了深入的探讨并且归纳了有界树宽的贝叶斯网络结构学习亟待解决的两个问题,虽然该算法能找到期望树宽的最高分网络,但是由于其时间复杂性随着变量数呈指数级增加。文献[18]给定一个图G和G的成对的不同顶点的集合,找到G的最小边集。即使将输入图限制为树,算法也被认为是NP-hard。Parviainen 等[20]开发了一种整数规划方法解决这个问题。它迭代地在当前解决方案上创建一个切割平面,以避免指数级的许多约束。然而,所有精确的算法只适用于小的网络和小的树宽。为了解决这个问题,引入了复杂度与输入量呈线性关系的精确算法和基于k-tree生成有界树宽CP-nets的实现步骤[21]。
2 关于图模型的基本符号与定义
2.1 条件偏好图CP-nets
定义1设CPT(Xi)为属性Xi的条件偏好表,它表示Xi在其父属性Pare(Xi)的不同取值下,对集合Dom(Xi)的排序,在Pare(Xi)的所有取值下,对Xi取值的排序构成CPT(Xi)。
定义2CP-nets 是一个有向图N=其中V是顶点集;CE是有向边集,代表所有属性之间的依赖关系,每个顶点Xi都有CPT(Xi)与其关联。
例1 某人一天饮品搭配主要考虑咖啡、茶和牛奶,分别用A、B、C表示,其中早上的咖啡种类与中午的茶种类决定晚上的牛奶种类。对于早上的咖啡,他喜欢黑咖啡胜过白咖啡。对于中午的茶,他喜欢红茶胜过绿茶。对于晚上的牛奶,若白天选了黑咖啡红茶或白咖啡绿茶,则选纯牛奶而不是酸牛奶;其他情况,则选酸牛奶而不是纯牛奶。该实例的CP-nets 图其中:a0表示黑咖啡,a1表示白咖啡,c0表示红茶,c1表示绿茶,b0表示纯牛奶,b1表示酸牛奶。如图1 所示,其中,V={A,B,C},Dom(A)={a0,a1},Dom(C)={c0,c1},Dom(B)={b0,b1},CE=

图1 例1中的CP-nets结构示意图Fig.1 Schematic diagram of CP-nets in example 1
2.2 有界树宽的CP-nets
在图论中,无向图的树宽与图的树分解有关。树分解是从无向图到树的映射。无向图的树宽是图的所有可能树分解的最小宽度。
现有的精确推理算法和具有理论保证的近似推理算法在最坏情况下的复杂度是树宽的指数形式或者NP-hard。事实,Kwisthout 等[22]证明了在多项式时间下,没有算法可以解决任意图结构的推理问题。此外,如果假设指数时间成立且存在一个对于任意推理问题都有效的树宽值k,那么此推理算法的时间复杂度为(O(klbk))且认为(O(klbk))是精确推理复杂度的一个下界。因此,有必要生成有界树宽的CP-nets,以提高推理算法的效率。通过对图的树宽进行约束,简化了模型,在表示能力和推理效率之间进行了权衡。
直接计算图的树宽是一个棘手的问题。实施树宽约束的一种方法是使用k-tree。所以在本文中,利用随机生成k-tree来实现有界树宽CP-nets的生成。
定义3k-tree的归纳定义如下:
1)一个(k+1)的团是一个k-tree。
2)用G=(V,E)表示一个k-tree,并且C⊆V是包含k个顶点的集合。如果归纳出的子图G(C)是k-团,那么对于每个u∈C,添加一个新的顶点v和一条边u-v得到的图结构就是ktree。
k-tree 是树宽为k的最大图,如果不增加树宽,就不可以添加更多的边。因此,树宽不超过k的每个图都是k-tree 的子图[23]。如果确保所生成的CP-nets 的DAG 结构图是k-tree 的子图,则从k-tree 学习CP-nets 自动满足树宽约束。k-tree 用Tk表示,n个节点上所有k-tree 的集合用表示,n个变量上的k-tree总数为
在k-tree 中,入度为k的节点称为k-leaf。每个k-leaf 的邻域形成一个团,然后k-leaf是单纯节点。
定义4Dandelion 编码定义为一对(Q,S),其中Q⊆{1,2,…,n}是包含k个整数的集合,S是一个(n-k-2)× 2 矩阵,其行是(i,j),其中1 ≤i≤n-k,1 ≤j≤k或者是(0,ε),其中ε是一个不在{1,2,…,n}的任意数。并且的基数可表示为(k×(n-k)+1)n-k-2。
例2 Dandelion 编码的一个例子是:12 个节点的3-tree(n=12,k=3)的Q=[1,2,3],S=此编码所对应的k-tree如图2所示。

图2 例2中的3-tree结构Fig.2 3-tree structure in example 2
3 Dandelion编码与k-tree的双向映射
本章介绍一种随机均匀生成有界树宽CP-nets的方法,这种方法的一个关键思想是有界树宽CP-nets的结构由k-tree进行约束。第3.1 节介绍了k-tree 与有界树宽CP-nets 的中间变量特征树;第3.2 节介绍了Dandelion 编码与k-tree 之间的编码算法;第3.3 节介绍了Dandelion 编码与k-tree 之间的解码算法。
3.1 特征树
在本节着重介绍有根k-tree 的特征树,是k-tree 与有界树宽CP-nets 的中间变量,因为将在编码过程中使用有根的ktree(即Renyik-tree)的特征树。首先本节先介绍一个有根的k-tree的骨架。
定义5给定一个根为R的k-treeTk,通过添加一个连接到k-clique 的新节点v,可以得到根为R的Tk′,骨架S(Tk,R)由在S(Tk′,R)上添加一个新节点X=(v∪k)和一条新边得到。Y是S(Tk′,R)的节点,它包含了k-leaf 到根的最小距离。如果Tk是一个k-tree就是一个节点为R的树。
定义6通过标记S(Tk,R)的节点和边,得到根为R的ktreeTk(Tk′,R)的特征树T(Tk,R):
1)根节点R标记为0,各节点{v}∪K标记为v;
2)从节点{v}∪K到它的父节点{v′}∪K的每条都用K′中没有出现的节点(一个有序集)的索引标记。当某节点的父节点为R时,其索引边用ε标记。
在本文所提出的代码中,将使用Renyik-treeRk的特征树作为有界树CP-nets的DAG结构。下文中,将骨架称为S(Rk),将特征树称为T(Rk)。
例3 在图3 举例显示了一棵有12 个节点的Ranyi 3-tree、它的骨架和特征树。

图3 n=12时3-tree的骨架与特征树举例Fig.3 Examples of 3-tree skeleton and feature tree when n=12
定理1对于任意一个具有n个节点的Renyik-tree,其基数与它的特征树基数的关系为:|Zkn|=|Rkn|,且Ranyik-tree 与其特征树T(Rk)之间的联系是双射关系。
3.2 Dandelion编码与树之间的编码实现
本节着重介绍了Dandelion 编码与k-tree 之间的编码实现过程,本文算法首先对Renyik-tree 中的k-tree 进行转换:在特定的团Q处将k-tree 的Tk根化,然后执行重新标记方法以获得Renyik-treeRk。这个过程中要求最高的步骤是从Rk开始计算T(Rk),将证明即使这一步也可以在线性时间内完成。将Tk转换为Rk的重新标记的信息。
编码得到的代码是双射的:可通过解码过程证明,此解码过程能够将中的每个代码与相应的k-tree 相关联,并且其基数关系如下:|Akn|=|Tkn|。由k-tree 到Dandelion 编码的编码算法可分为以下步骤。
3.2.1 将k-treeTk转换成有根的Renyik-treeRk
计算每个节点v的度d(v)并找到lM,即度为k的最大节点v,则节点集Q为adj(lM)。为得到相应的Renyik-treeRk,Q中的节点应该重新标记为{n-k+1,n-k+2,…,n}。通过以下方法来定义重新标记规则ℏ:
1)如果qi是Q中的第i个最小节点,则分配ℏ(qi)=n-k+i;
2)每个q⊄Q∪{n-k+1,n-k+2,…,n},则指定ℏ(q)=q;
3)未分配的值用闭环周期重新标记,形式上表示为:对于每个q∈{n-k+1,n-k+2,…,n}-Q,ℏ(q)=i使得ℏj(i)=i并且j被最大化。
例4 以下用一个实例来演示上述由k-treeTk转换成有根的Renyik-treeRk的实现步骤,以图2 所示的3-tree 为例,图2 中Q={1,2,3}取为lM=12 的邻域。正向箭头对应于规则1)分配的值,小的循环是规则2)派生的循环,而向后箭头的闭合循环是根据规则3)。
图4(a)重新获得的Renyi 3-treeR3。通过ℏ 方法重新标记后R3的根是{10,11,12}。
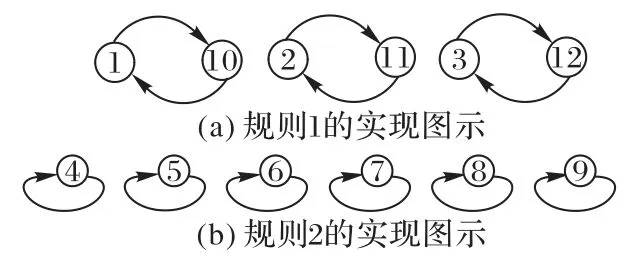
图4 3-tree的重新标记规则Fig.4 3-tree relabeling rules
3.2.2 生成Ranyik-treeRk的特征树T
在此步骤中,通过过渡骨架的方法生成Rk对应的特征树T,但为了保证线性时间复杂度,避免骨架的显式构造,且分别构建了T的节点集和边集。计算节点集以标识Rk中的所有最大团,此过程可以通过从k叶节点修剪Rk来完成。接而将v从Rk中删除,因此将其每个相邻节点的度数减1。将v的邻接表的这个子集存储为Kv,边缘集由标识父级的向量p表示。0是所有节点父节点。
例5 以下用一个实例来演示上述根据已知的Renyik-treeRk生成特征树T的实现步骤,以图3(a)所示的3-tree 为例,图3(c)就是其对应的特征树。为了实现此步骤,算法仍然需要标记每个边(v,p(v))。当p(v)=0 时,当前边标记为ε;边l(v,p(v))由中不属于Kv的唯一元素的序来索引。
3.2.3 应用与参数结合的Dandelion编码
在这一步骤中,应用参数r=0 且x=ℏ(q) 的广义Dandelion 编码,其中q=min{v∉Q},编译得到的编码串S由n-k-1 对组成。对于每个v∈{1,2,…,n-k}都有一对(p(v),l(v,p(v)))取自Akn。在运算中,与ℏ(lM)相关的对必须为(0,ε),且此代码对可以省略[24]。
例6 使用参数r=0 和x=1 从图3(c)的特征树获得的Dandelion 编码串为:[(0,ε),(0,ε),(6,1),(5,3),(5,2),(7,1),(8,2),(1,3)] ∈R312,在图2 中所示的3-treeT3相对应的Dandelion 编码为 [(1,2,3)(6,1),(5,3),(5,2),(7,1),(8,2),
3.3 Dandelion编码与树之间的解码实现
Dandelion编码与k-tree之间的解码过程分4个步骤:
1)从Q开始计算ℏ并找到lM和-q;
2)在骨架S(Rk)中插入与ℏ(lM)相关的对(0,ε)并对其进行解码以获得T;
3)通过遍历k-treeT重新获得Rk;将Rk初始化为{n-k+1,n-k+2,…,n}上的k团R;
4)应用ℏ-1方法从Rk获得Tk。
在实现过程中,一旦已知Q根集合,就可以如编码算法一样计算q=min{v∈[1,n]:v∉Q}和ℏ;由于T的所有节点都出现在骨架中,因此通过简单扫描骨架即可较容易得出T的所有叶子的集合L。在此,T中的叶子与Rk中的k-leaf 重合。将ℏ-1应用于节点集合L中的所有节点,就可以重构原始Tk的有k-leaf点的集合,从而找到lM,即Tk中度为k的最大标签节点。
例7 以下用一个实例来演示解码过程。以图3(c)的Dandelion code 为例:已知Dandelion code 是以下序列:[(0,ε),(0,ε),(6,1),(5,3),(5,2),(7,1),(8,2),(1,3)]按照解码步骤第1)步可以计算出Q={1,2,3},lM=12 且qˉ=4;第2)步在现有的特征树上添加一条边即节点4 到节点0 的边标记为ε,即得到图3(b)所示的骨架;第3)步通过扫描骨架找到原始Tk的所有叶子节点L={11,12,4,9},根据图示可知Tk的所有叶子节点与Rk的所有叶子节点相同,接着对每一个叶子节点进行ℏ-1运算,找到原始Tk中所有k-leaf,从而得到图3(a)所示的Tk;第4)步根据得到的Tk重建Rk,最终得到图2 所示的原始Rk。
定理2Dandelion 编码与树之间编码算法的时间复杂度为O(nk),其中n为节点个数,k为图结构树宽。
证明 可以通过扫描Tk的所有邻接表来实现每个节点v的d(v)的计算。由于具有n个节点的k-tree 具有k(n-k)条边,故算法的时间复杂度与输入树宽k的大小呈线性关系。通过例子可以发现,步骤1的总时间复杂度为O(nk)。
4 随机生成有界树宽CP-nets算法的设计
4.1 基本算法
4.1.1k-tree到Dandelion编码的映射算法
算法1 Encoding Algorithm。
输入 一个有n个节点的k-treeTk;
输出 相应Akn的编码。
1)定义集合Q,将k-treeTk转换成有根Renyik-treeRk;
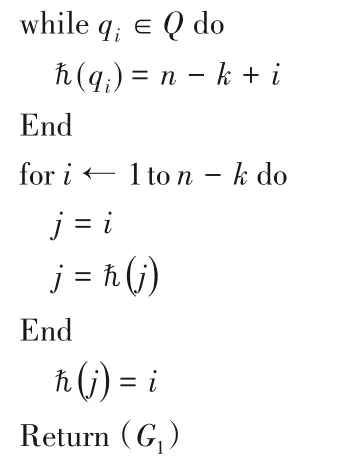
2)为Rk生成特征树T
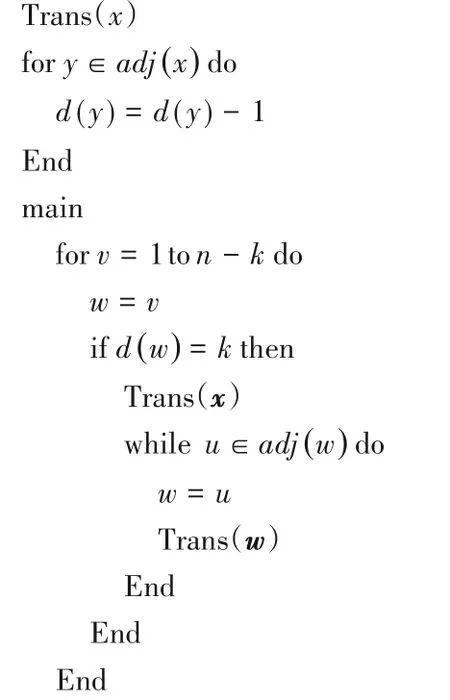
3)计算r=0和x=的T的代码对。

在此过程中,当v被删除时,其相邻节点中的最多一个成为k-leaf。如果发生这种情况,修剪过程将在邻接列表扫描中选择新的k-leaf和下一个k-leaf之间的最小值。在此过程结束时,得到的Renyik-treeRk其根为R={n-k+1,n-k+2,…,n}。该算法的总体时间复杂度为O(nk)。在实现过程中,算法删除了n-k个节点,每次删除都需要O(k)时间。
4.1.2 生成k-tree算法
本算法功能 可以对任意一对(Q,S)∈Akn进行解码以获得代码为(Q,S)的k-tree。使用以下算法执行过程。
算法2 Decoding Algorithm。
输出 生成相应的k-treeTk。
1)从Q开始计算ℏ并找到lM和
2)在S中插入与ℏ(lM)相对应的对(0,ε)并对其进行解码以获得T;
3)通过遍历k-treeT重新构建Rk;将Rk初始化为{n-k+1,n-k+2,…,n}上的R;
4)应用ℏ-1方法从Rk获得Tk


从编码串中删除冗余对完成了步骤3)。由于可以在线性时间内计算出Dandelion 编码,因此编码算法的总体时间复杂度为O(nk)。为了对骨架进行解码,需要添加与ℏ(lM)对应的一对(0,ε),所获得的树T由其父向量表示。解码过程的最后一步在于用ℏ-1将得到的有根Rk转换为无根的Tk。解码算法的总体复杂度为O(nk)。
4.1.3 生成有界树宽CP-nets算法
具有完整语义的CP-nets由两部分组成:DAG结构与表示语义的条件偏好表。
在本文中,利用迭代方法生成相应的CPT。在本文中CPT 的生成可借助带有离散多值函数的双射(一个一对一的映射)来实现。此函数可以将每个CPT(Xi)建模为函数其中d=2 是指变量的域大小,m=|Pa(Xi)|指各个节点其父节点的个数。
针对于二值的变量,函数f是一个布尔函数。在布尔值的情况下,每个父节点Xh的值Xh1和Xh2可以分别映射到0和1。两个可能的线性阶数可以对应于输出0和1。所以,可以将任何CPT编码成长度为dm的等效函数向量F(CPT code),可以使用表1 中的真值表对例1 中节点B的CPT进行建模。
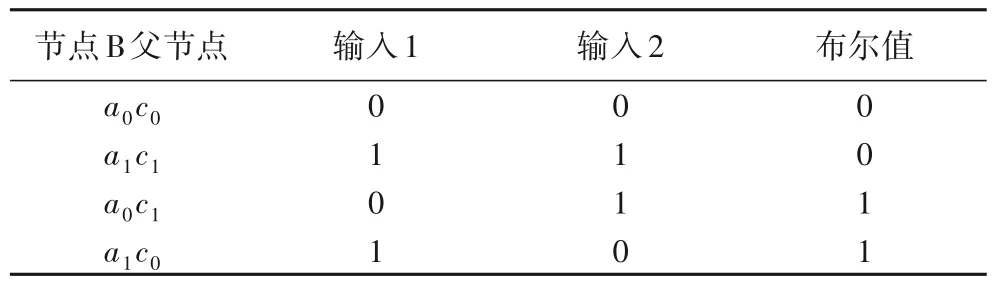
表1 CPT取值与对应的布尔函数值Tab.1 CPT values and corresponding Boolean function values
根据建模得到CPT 编码序列,由CPT 编码随机生成各个节点的CPT。
以下的生成算法分为两步:第一步,由算法2 提到的解码算法得到Dandelion 编码相应的k-tree,并以此得到对应的特征树T,特征树便是相应有界树宽CP-nets 的DAG 结构;第二步,由随机的CPT 编码生成各个节点的条件偏好表。最终结构与CPT一一对应,以矩阵的形式存储。
算法3 BTW-CP-nets Gen。
输出 生成相应树宽为k的CP-netsNk。
1)调用算法2生成Dandelion编码所对应的k-tree的特征树T;


Fj=的随机函数输入
由F0构造CPT(Xi);
ReturnNk
例7 以下利用该算法生成图2所示3-tree所对应的树宽为3 的CP-nets,由于特征树T已经提供相应的DAG 结构,故CP-nets的生成如图5所示。
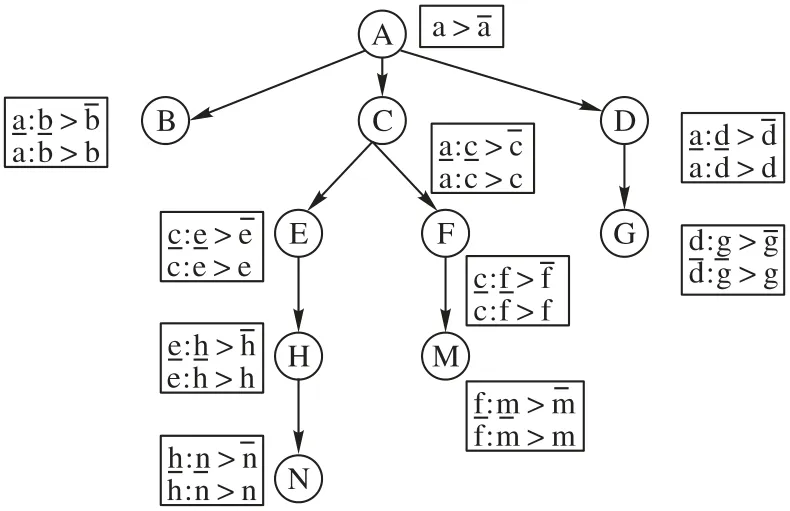
图5 对应于图3所生成树宽为3的CP-netsFig.5 CP-nets with tree width of 3 corresponding to Fig.3
4.2 算法的性能尺度
1)计算时间。算法的时间消耗主要有两方面:一个是对随机k-tree 模型的生成,即求随机编码与结构特征,复杂度为O(nk),第二个对所生成k-tree图结构的存储与推理,它需要消耗O(nk),因此整个算法实现的时间复杂度为线性时间O(nk)。
2)存储空间。随机生成算法的空间复杂度为:O(k(n-k)),k是CP-nets 图结构的树宽,n是CP-nets 图结构的顶点数。相对于其他算法,该算法不用存储原始数据,节省了很多空间。
5 算法的实验分析
在本章中,通过实验显示BTW-CP-nets Gen 算法的准确性与性能。进行了多次实验,通过测验6 个不同的数据集得出最终结论。实验分为4个部分。
1)首先证明了编码与解码算法的有效性,通过建立编码与k-tree 与有界树宽CP-nets 的关系,完成编码与图结构之间的双向映射。参照6 个数据集数据生成有界树宽的CP-nets,并测试其质量。
2)其次,把已有的生成算法与BTW-CP-nets Gen 算法进行了对比,在算法性能方面(运行时间、遍历节点与树宽质量评分)进行比较,结果如图6~8所示。
3)再者,研究占优查询算法在不同生成算法所生成的图模型上的运行时间,准确性与树宽之间的权衡,如图9所示。
4)最后,根据树宽评分与占优查询节点遍历比的相关系数的变化分析CP-nets 结构与推理算法对参数的依赖。证明树宽影响推理算法的运行效率与难度,实验数据如图10所示。
5.1 树宽质量评分
给定一个k-tree,定义树宽质量评分(T-score)来评估k-tree生成CP-nets 的质量;T-score值越大,证明所生成的有界树宽CP-nets质量越高。k-treeTk的T-score定义为:
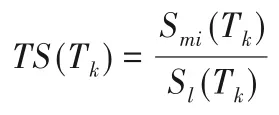
在分子上,Smi(Tk)指通过使用k-tree表示数据来衡量废弃了多少冗余结构。令eij表示连接节点i和j的边,并让Sij表示节点i和j的结构信息。从而:
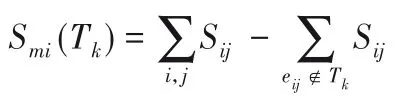
Smi(Tk)是k-tree 和有界树宽CP-nets 一致性的度量,可以解释为k-tree覆盖的结构信息的总和,也可以解释为全结构的CP-nets剪枝k-tree结构的总和。
在分母上,将Sl(Tk)定义为k-tree 的最佳子图的评分。其中m(G)是每个DAG 结构G的导出图,其同为k-tree的子图,Si(Xpai)指给定父节点数量总和。
可针对任何给定的k-tree非常有效地评估T-score,因为计算Smi(Tk)只需要各节点的结构信息(它们都可以预先计算,因此时间复杂度最多为O(n2))。
5.2 占优查询节点遍历比
给定一个CP-netsN,在此结构上进行占优查询时,若配置o与o′的取值一定,算法过程中所遍历到的节点数是一定的。若判定结果相同,遍历越多节点则代表此结构的占优查询算法效率越高。因此,在本文中定义节点遍历比N-trave来判定不同结构上占优查询的效率。N-trave定义如下:
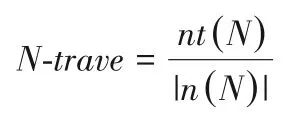
其中:分子上nt(N)代表算法运行中所遍历到的节点,分母上n(N)代表全结构CP-nets 中的所有节点。在实验中,比较了T-score与N-trave的相关系数,以此相关系数来判定k-tree所生成的有界树宽CP-nets与占优查询效率之间的关系。
5.3 实验环境
本文实验是在一台计算机上进行的,计算机操作系统是Windows7 32 bit,配有8 GB 内存,主频为3.2 GHz 的Intel Core i5-3470 CPU。使用的软件是Matlab,每个实验重复5 次,取5次实验的平均值作为最后的结果。
5.4 实验分析
在本节中,衡量k-tree产生有界树宽CP-nets结构的质量,为了保证实验结果的准确性及说服力,实验使用了6 个不同类型的数据集进行测试,每个数据集的样本数与样本量如表2 所示。每个数据集中非二元变量在中位数上二值化,丢弃缺少变量值的实例。假设在以下所有实验中,产生的CP-nets是二值的。
在算法对比方面,本文选择了文献[25]在1998 年提出的用于生成随机标记树的并行算法(简称PHC 算法),此算法基于Cayley 公式的证明,该算法早先用于从n-2个元素序列生成n个节点的标记树。是一种修改了用于树生成的原始顺序算法;在2005年,文献[26]提出了一种针对k树的新编码方案(简称Pruffer code 算法),不需要计算转换结构。实验分别在算法运行时间、节点遍历比与树宽评分等方面比较了3 种算法的性能。

表2 实验中使用的数据集的大小Tab.2 Size of the datasets used in the experiment
首先本文通过3 种算法分别生成相同结构难度的CPnets,针对不同的节点数n与树宽的算法运行时间如图6 所示。当生成结构较小的图模型时,例如n=10,k=3,3种生成算法的运行时间相差无几;但当k>5 时,其时间差距逐渐明朗,例如当n=10,k=10 时,Pruffer code 生成算法花费4.29 ms,PHC 生成算法花费3.07 ms,BTW-CP-nets Gen 算法花费2.16 ms。这说明BTW-CP-nets Gen 算法在生成图模型时相较于其他两个算法时间较快,效率更高。除此之外本文所提出的生成方法的运行时间与树宽之间存在更强的线性正相关。
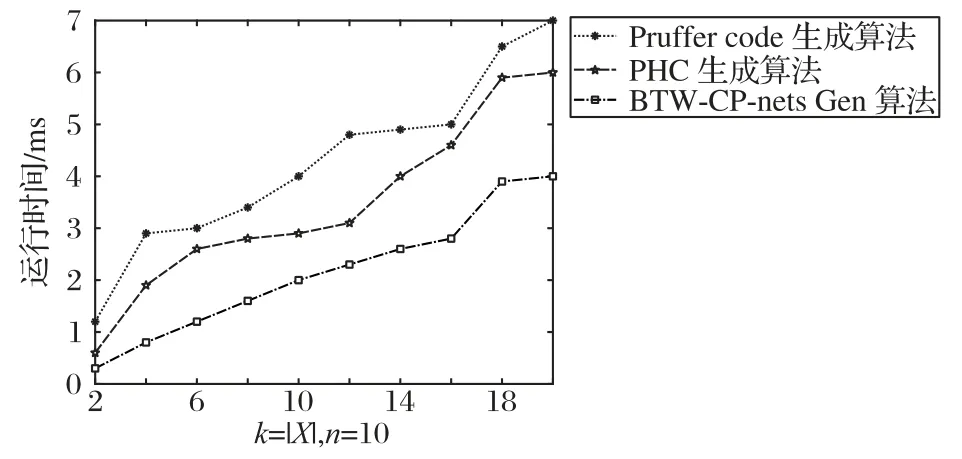
图6 不同生成算法的运行时间Fig.6 Running time of different generation algorithms
图7 表示的是随着CP-nets 树宽逐渐增加,不同的生成算法生成有界树宽的CP-nets 的质量变化趋势。由图7 可以看出,随树宽k值增加,所生成的CP-nets 质量提高。当节点数n=10,k=8 时,Pruffer code 生成算法的T-score=0.315,PHC生成算法T-score=0.356,BTW-CP-nets Gen 算法的T-score=0.386。3 种算法的树宽质量分数较相近,当k取较小值时,3种算法所生成的图模型质量相似。然而,当n=10,k=20时,其树宽质量分数分别是0.585,0.719,0.921。其中BTW-CPnets Gen 算法的T-score最大,这说明生成结构较大的图结构时,通过BTW-CP-nets Gen 算法生成的有界树宽CP-nets 质量更好,结构更加均匀。
实验基于Dandelion code 生成有界树宽的CP-nets 图模型,并对存储在数据库中的图模型进行推理。在实验中,首先引用了文献[27]提出的DFS(Dominance testing via model FlipS checking)占优查询算法[27],此算法是一种基于动态规划的占优查询算法,深度遍历优先。由于该算法的复杂性,它只适用于一些结构较小的数据集,因此在进行实验时规定所使用的CP-nets 树宽小于20 且父节点的最大数目为20。在实验中,本实验分别对3 种算法生成的图模型进行了占优查询,其节点遍历比如图8 所示,当节点数n=20 时,Pruffer code 生成算法的N-trave=0.598,PHC 生成算法的N-trave=0.719,BTWCP-nets Gen 算法的N-trave=0.927。由此可见,在结构复杂的图模型上进行占优查询时,BTW-CP-nets Gen算法的节点遍历比要大于其他两种算法,这代表着BTW-CP-netsGen 生成的图模型更加均匀,使得占优查询算法效率更高。

图7 不同算法的树宽质量评分变化情况Fig.7 Changing trend of tree width quality score for different algorithms
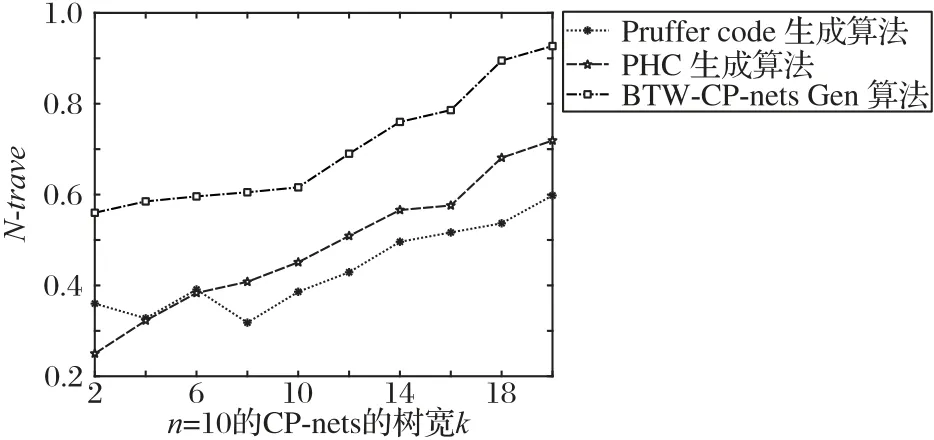
图8 不同生成算法生成图模型的节点遍历比Fig.8 Node traversal ratio of graph models generated by different generation algorithms
本文引用了DFS占优查询算法[27]对不同生成算法生成的有界树宽CP-nets进行占优查询,并记录了该算法相应的运行时间,实验结果如图9 所示,根据图9 可知:整体分析,当树宽n=20不变时,占优查询DFS算法的运行时间随着树宽k的增加而增加,这说明图模型的树宽影响其占优查询的运行时间。当k取得最大值k=20时,DFS算法在Pruffer code生成算法所生成的图模型的运行时间为4.95× 103ms,在PHC 生成算法所生成的图模型的运行时间为3.97× 103ms,在BTW-CP-nets Gen生成算法所生成的图模型的运行时间为1.98× 103ms,分别比前者减少了2.97× 103ms 与1.99 × 103ms,这代表着BTW-CP-nets Gen生成算法所生成的图模型结构更加均匀,使得DFS算法效率更高。

图9 DFS算法的运行时间Fig.9 Running time of DFS algorithm
在实验最后一部分,本文比较了不同数据集上T-score与N-trave的相关系数。T-score代表的是k-tree生成有界树宽CPnets 的质量,故其值越大则质量越高;N-trave代表的是推理算法在某给定的图结构上进行推理计算时所遍历到的节点比,其取值越大则推理算法效率越高;T-score与N-trave的相关系数用来判定k-tree所生成的有界树宽CP-nets与占优查询效率之间的关系。图10是在audio与adult数据集上相关系数的图示,表3 是在不同数据集上相关系数的值,由图10 与表3 可发现,当样本数增大时,相关系数的值也逐渐增加,当样本量足够大时,可将相关系数近似拟合为1,这代表着树宽质量评分近似100%影响占优查询的节点遍历比。由此可得出结论,CP-nets的树宽严重影响占优查询算法的效率与难度。

图10 不同数据集上k-tree的T-score与N-trave的关系Fig.10 Relationship between T-score and N-trave of k-trees on different datasets
就所花费的时间与遍历节点而言,占优查询算法的性能随图模型的树宽结构而变化,且占优查询算法过程因图结构复杂而复杂。在多值情况下,对于较小的树宽的CP-nets,占优查询算法可以更加高效运行[28]。
6 结语
本文提出了一种标记k-tree双射码,并在理论上证明了该编码与解码算法的运行时间与所输入的树宽大小呈线性关系。在本文中为了开发k-tree 的双射编码,利用到了Renyik-tree 与无根k-tree 的转换,并基于Dandelion 编码的泛化开发了标记Ranyik-tree 的新编码。提出了线性时间算法BTWCP-nets Gen 算法,解决了对k-tree 进行有效编码和解码的问题。经多次实验得出结论:
1)BTW-CP-nets Gen 算法在生成有界树宽方面有较高的效率,且所生成的图模型结构更加均匀。
2)用DFS 占优查询算法在不同树宽的CP-nets 上进行实验,验证了CP-net是的树宽严重影响占优查询的难度。
3)BTW-CP-nets Gen算法虽然能在线性时间内完成生成,但其运行时间仍然依赖于图模型的结构。
本文中的结论证实了树宽因素并且可扩展到更一般的CP-nets,例如具有异构域或不完整表的循环的CP-nets。
在未来的工作中将继续探索各种推理算法(次优查询、一致性查询等)和CP-nets结构之间的关系:
1)图模型的表示方面,仍然需要针对具体问题设计生成特定的图模型。在设计中既要对所生成图模型变量的依赖关系做出合理抽象,又要权衡所生成图模型在进行推理或学习所面临的难度与代价,下一步将改进生成算法的局限性,面对不同需求生成特殊结构的图模型[29]。
2)图模型推理算法方面进一步研究提高其效率,包括利用分布式推理[30]、针对查询的推理、启发式推理等。各个推理算法在图模型研究效率方面还有很大的改善空间。接下来研究一种启发式推理算法,根据评分函数的值简化推理步骤提高其推理效率。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2022年4期)2022-08-18
中国典型病例大全(2022年7期)2022-04-22
社会科学战线(2022年2期)2022-03-16
睿士(2020年6期)2020-08-18
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
南方周末(2019-12-19)2019-12-19
南方周末(2019-07-18)2019-07-18
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
南方周末(2019-05-09)2019-05-09
