
基于多级全局信息传递模型的视觉显著性检测
2021-01-21 03:23宋建伟
计算机应用 2021年1期
温 静,宋建伟
(山西大学计算机与信息技术学院,太原 030006)
0 引言
视觉显著性源于认知学中的视觉注意模型,旨在模拟人类视觉系统自动检测出图片中最与众不同和吸引人眼球的目标区域。显著性检测在很多视觉任务(例如目标跟踪[1]、图像语义分割[2]、行人重识别[3]以及基于内容感知的图像编辑[4]等)的预处理阶段起着至关重要的作用。
早期的显著性检测方法[5-6]主要采用一些计算模型和基于手工特征的传统方法来预测显著性区域。随着深度学习的兴起,较早阶段采用的深度方法都是利用卷积神经网络(Convolutional Neural Networks,CNN)提取特征的能力来预测像素点是否为显著性区域。例如:Wang 等[7]提出一种将局部估计和全局搜索相结合的显著性检测算法;Li 等[8]提出了一种利用每个超像素的上下文CNN 特征来预测像素的显著性值的显著性检测算法。虽然上述方法可以完成显著性检测任务,但是CNN 结构中的完全连接层会大幅地增加检测的时间,降低计算效率,并且影响空间位置信息的捕获。
针对这个问题,近几年提出了基于全卷积神经网络(Fully Convolutional neural Network,FCN)[1]来逐像素点地预测显著性值。Lee等[9]提出将低层空间特征嵌入特征图中,然后将其与CNN 特征组合以预测显著性图;Liu 等[10]提出了一个两阶段的网络,该网络首先产生粗略的显著性图,然后整合局部上下文信息对于显著性细节分层优化,完善最终结果;Wang等[11]使用低级线索生成显著性图,并利用它以循环方式定位显著性区域,从而完成显著性预测任务。
但是这些工作主要利用了FCN 里单独特定层的特征信息,没有充分地考虑各级特征之间的信息互补作用。由于缺乏底层空间细节,使得显著性图无法保留比较精细的对象边界。Luo 等[12]针对以上的问题,改进U 型结构的同时,又利用了多层次的上下文信息来准确检测出显著物体;Zhang 等[13]使用双向结构在CNN 提取的多级特征之间传递消息,以更好地预测显著性图。
但上述的这些方法依然无法准确地检测具有各种比例大小、形状和位置各异的显著性对象。而造成这些问题的原因主要有以下两点:
1)以前大多数的基于FCN 的显著性检测模型依次堆叠单尺度卷积层和最大池化层以生成深度特征。由于感受野有限,因此通过这种网络学习到的特征可能不包含丰富的多尺度全局信息。
2)在自上而下的网络传递中获得的丰富高级语义信息在反卷积的过程中,又被逐渐传送到较浅的层,因此,较深层捕获的信息在传递的同时逐渐被稀释。
因此,解决上述问题的方法转化为如何全局化多尺度地提取较高级语义信息,并且更有效地将全局高级语义信息和底层细节特征协同利用的研究。基于此,本文算法在多级特征分层处理的同时,充分地考虑高层特征空间的全局信息,通过引入多尺度全局池化特征聚合模块(Multi-scale Global Feature Aggregation Module,MGFAM)集成网络高级特征空间的不同尺度信息,全局化地提取到高层次特征图层带来的丰富语义信息。除此之外,为了将具有全局性的高级语义信息和底层细节特征有效协同利用,在本文中进一步将MGFAM提取到的特征信息进行特征融合操作,并且将融合的信息分别传递至较浅的层次;然后,将较浅层次中包含的底层空间细节信息和通过MGFAM 产生的全局高级语义信息进行融合,这样可以有效地解决自上而下传递过程中的信息被稀释,以及缺乏全局信息等问题。这些设计使得整体网络输出的特征信息包含全局高级语义概念和底层空间细节。
1 多级全局信息传递模型
在本章中,1.1 节具体描述了本文提出的模型整体结构;接着,在1.2 节中介绍了多尺度全局特征聚合模块;最后,针对于不同级别的特征图层,进一步设计了一种有效的特征融合方式以及多层次传递组合方式,这会在1.3 节中较为详细地阐述。
1.1 模型整体网络结构
在本文中,基于FCN 来构建模型的体系结构,并以VGG-16 Net 作为预训练模型。总体构架如图1 所示。本文模型使用的VGG-16 是以视觉显著性检测任务为驱动,从而做出修改的基干网络。首先将VGG-16 网络中的全连接层去掉,用于逐像素点预测;然后,将VGG-16 中最后的最大池化层去掉,从而使得最终输出的信息保留更多细节。
在基本骨架VGG-16 信息传递的同时,对每层输出的特征图分别进行分层处理。为了增大感受野,学习更为丰富的上下文信息,在VGG-16的5个层次的输出后都分别添加空洞卷积模块;除此之外,为了多级上下文特征信息得到充分利用,随后添加了门控双向消息传递模块。在此模块中,高层级中的语义信息和低层级中的空间细节双向传递,较深的层级将语义信息逐步传递至低级更好地实现显著区域定位,而较浅的层将更多的空间细节传递给较深层次。因此,通过这种不同于骨干网络的多层级信息相互传递配合以产生更准确的结果,最终经过融合得到输入图像初步的显著性预测结果。
为了关注更多全局性的高级语义信息,本文引入了多尺度全局特征聚合模块。此外,本文模型选择合适的层级插入MGFAM,提取到不同层级的全局高级语义信息进行特征融合操作。为了包含更多的底层细节信息,本文模型还将提取出的有判别性的特征信息有指向性地进行特征传递操作。最后,将来自MGFAM 的指导信息和较低层次的初步预测结果进行融合得到最终的预测结果。
在图1 中展示了模型所有的功能模块。模型以256×256图像大小作为输入,先使用VGG-16 分层提取多级特征(第一行),利用MCFEM(Multi-scale Context-aware Feature Extraction Module)捕获不同级别的上下文信息,然后经由门控双向消息传递模块(Gated Bi-directional Message Passing Module,GBMPM)后获得初步的预测结果。在Conv4-3和Conv5-3后面添加了MGFAM,降维后进行特征融合操作。最终多层次多尺度信息融合,利用集成特征Prev1进行显著性预测。

图1 本文提出的模型的总体框架Fig.1 Overall framework of the proposed model
1.2 多尺度全局特征聚合模块
在文献[14-15]中都表明,FCN 的感受野比理论上要小很多,尤其是对于比较深的层次,感受野无法全局地捕获或提取整张输入特征图像的全局信息。因此,检测结果总是仅发现了显著对象的局部信息,有严重的信息丢失现象。
目前,金字塔池化已经成功应用于图像分割[14]等领域,并且针对以上问题获得了不错的解决效果。金字塔池化通过融合不同感受野大小的子区域的信息,可以提取出更丰富的全局特征。为此,根据显著性检测的任务特点,对其进行了调整和改进,引入了多尺度全局特征聚合模块来解决这类问题。
图2 显示了MGFAM 的具体结构。本文模型在构建时摒弃了模块传统的嵌入方式,分别在Conv4层和Conv5层后添加MGFAM,双分支并行提取出不同层级的全局信息。在尺度方面,根据显著性检测任务特点,本研究构建了4 种尺度的平均池化操作,将特征图分别平均池化至1×1、2×2、4×4、8×8 的尺寸大小。图中尺度最小的为最粗略的层级,是使用全局池化生成的单个bin 输出。剩下的3 个层级将输入特征图划分成若干个不同的子区域,并对每个子区域进行池化。为了保持全局特征的权重,4 个尺度池化后的特征图分别都降维至1/4。

图2 MGFAM的详细图示Fig.2 Schematic diagram of MGFAM
为了更好地表示第n个级别尺度的全局平均池化操作以及降维操作,其统一表示如(1)所示:

Sn表示经过不同级别全局平均池化再降维后的特征图结果。接着将Sn分别上采样至与输入特征图相同的尺寸。不同尺度特征图从低分辨率上采样至高分辨率的过程由以下方式执行:
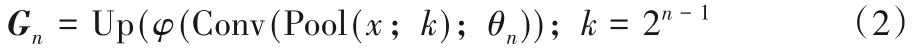
其中:n表示尺度等级,n∈{1,2,3,4};x代表输入的特征图;k代表每一尺度等级池化后的分辨率大小;Conv(*;θ)是参数θ={W,b}的卷积层;Up(·)是上采样操作,旨在将特征图分尺度上采样;φ(·)是ReLU(Rectified Linear Unit)激活函数。
最后,将不同尺度等级池化后的最终结果Gn和输入的特征图x拼接为最终的全局特征。为了保持通道维数不变,降维至原来的1/2。特征合并及降维的过程表示如式(3)所示:
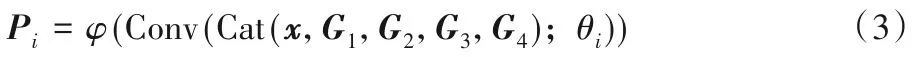
其中:Cat(·)是通道轴之间的串联操作,Pi(i=4、5)为Conv4-3和Conv5-3 后输出特征图分别经过MGFAM 处理后的最终结果。
特征聚合的过程就是融合目标特征的过程,聚合过程中给予了原本的输出特征图较大的权重,用于提供VGG-16 网络的原始层次信息。并且通过4 种尺度的池化,获得了全局池化生成的单个bin 带来的全局信息,以及其他3个尺度等级下的平均池化操作所提供的不同子区域之间的不同尺度信息。因此,特征聚合之后提供了本层级最为有效的全局上下文信息特征。
图2 展示了多尺度全局特征聚合模块的具体操作,每一层都分别池化至2n-1(n表示尺度等级)4 种尺度大小。上采样后,将4种尺度池化分支拼接聚合后输出。
1.3 特征融合及多层次特征传递
本文的基础模型基于VGG-16 网络构建。然而,VGG-16整体的结构是自上而下的单方向传递的,在特征提取的过程中特征图逐渐减小。因此,在显著性检测任务中,经过VGG-16 网络的输出需要通过上采样操作将特征图调整到和输入图像一样的大小。这一操作就使得高级特征在传输到较低层时将逐渐被稀释。
为了解决这一问题,本文将通过MGFAM 提取出的全局上下文信息进行特征融合操作,并且设计了一种有效的多层次传递方式。
1.3.1 基于MGFAM的深层次特征融合
在深层次特征融合方式地设计上,不再保留MGFAM 作为每层的固有部分,只在VGG-16 的Conv4 层和Conv5 层后分别添加该模块。
Conv5层作为VGG-16骨干网络的最后一个block,具有最强的语义信息。但是输出的特征图分辨率较低,无法获取更多的细节信息,对于细节的感知能力比较差。因此,在Conv4层后也独立加入了MGFAM。Conv4 层输出的特征图分辨率是Conv5层的4倍,相比最后一个block来说,具有更多的位置以及细节信息,并且在全局池化的过程中对于信息的损失相对较少。
接着将Conv4 层和Conv5 层分别经过MGFAM 提取后的多尺度信息进行特征融合操作,多层级全局信息进行融合互补后,获得更加具有判别力的特征。在后续2.2.2 节的模型简化实验中也详细地阐述了这种特征融合方式的设计缘由以及有效性。
1.3.2 多层次特征传递
基于MGFAM 的深层次特征融合之后,为了保证其产生的指导信息可以与自上而下路径中的不同级别的特征图信息融合在一起。本文通过多层次特征传递的方式将指导信息传递到不同级别的特征图层。在本文中,选择将指导信息传递至前三层,充分地考虑到浅层特征更需要全局性的高级语义信息,本文算法采用的这种局部传递(Local propagation)方式减少了冗余信息。如图3 所示,局部传递这种方法,比全局传递(Global propagation)方式(即,将指导信息自上而下传递到每个级别特征图的方式)可以避免重复的全局高级语义特征堆积,减少冗余信息干扰。

图3 多层次特征传递方式结果对比Fig.3 Result comparison of multi-level feature propagation schemes
例如图3(d)既获得了显著性目标蝴蝶,同时也避免了与蝴蝶目标相连的黄色鲜花区域的干扰。最终传递的引导信息如式(4)所示:

其中F为Conv4-3 和Conv5-3 经过MGFAM 提取信息后,特征融合后所得的信息。
1.4 计算显著性特征图
在计算最终的显著性预测结果的过程中,每层级的预测模块Previ将特征图hi和高层次预测信息Previ+1以及通过MGFAM 提取的多级全局信息的融合结果M作为输入进行融合。每层级预测模块的融合过程如下:
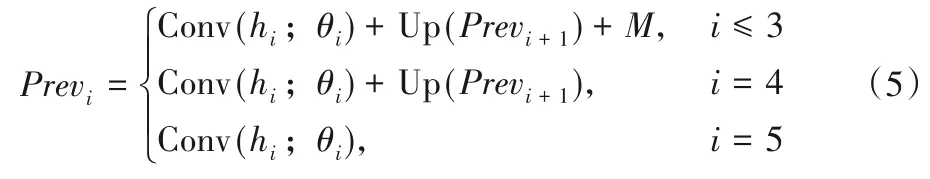
其中Conv(*;θi)是卷积操作,用1×1的卷积核来进行卷积降维处理。
模型的参数是通过最小化ground truth 和显著性图之间的交叉熵损失来优化的。Prev1是模型的最终显著性图预测结果。网络通过最小化softmax 的交叉熵损失函数来端到端训练提出的模型。式(6)给出了损失函数的定义:
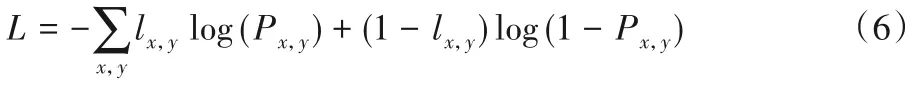
其中:lx,y∈{0,1}是像素(x,y)的标签,Px,y是像素(x,y)属于前景的概率。
2 实验设计与结果分析
2.1 实验环境与数据设置
实验设置 本文的模型是基于TensorFlow 框架而实现的。网络的骨干参数使用在ImageNet 数据集上预训练的VGG-16模型进行初始化。对于除骨干网络之外的卷积层,使用截断法线法初始化权重。在后面提到的模型简化测试中,默认情况,使用ECSSD 数据集进行测试对比。本文所有实验均使用Adam优化器进行,初始学习率为1E -6。
数据集 为了验证本文方法的有效性,本文在几个主流的公共数据集上面评估算法性能。本文实验选择使用数据集有:DUTS[16]、PASCAL-S[17]、ECSSD[18]、SOD[19]和HKU-IS[20]。DUTS是一个大规模的数据集,其中包含10 553张用于训练的图像。这些图像具有不同位置和不同比例以及复杂的背景,检测这些图像具有一定的挑战性。在本文实验中主要将该数据集作为训练数据集。PASCAL-S数据集主要包含自然图像。ECSSD 有各种复杂场景的图像,包含许多语义上有意义但结构复杂的图像用于评估。SOD 是基于伯克利分割数据集(Berkeley Segmentation Dataset,BSD)的显著对象边界的集合。HKU-IS 包括4 447 个具有挑战性的图像,在本文实验中将该数据集的3 000幅图像用于训练,1 447幅作为测试图像。
评估准则 在本文中,使用了在显著性任务中广泛使用的指标来评估本文方法的性能并且与其他方法进行对比,评估指标分别为准确率(Precision)、召回率(Recall)、平均绝对误差(Mean Absolute Error,MAE)和F度量值(F-measure)。
除此之外,为了使实验数据结果更加形象地展现,本文绘制了PR(Precision-Recall)曲线。PR 曲线对不同概率阈值(范围从0到1)下的显著性图进行二值化并与ground truth进行比较,从而计算出最终结果。
为了更全面地对本文的模型进行评估,本文使用F 度量值(F-measure)来对整体性能做综合度量,F-measure是查全率和查准率在非负权重β下的加权调和平均值,定义如下:

如文献[21]所述,将β2设置为0.3 的权重精度要比召回率高。MAE是直接计算模型输出的显著性图与ground truth之间的平均绝对误差,首先将两者进行二值化,然后通过式(8)进行计算:
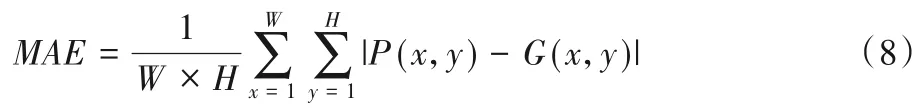
其中:P和G分别显著性图预测结果和ground truth;W和H分别表示P的宽度和高度。
2.2 模型简化测试
为了证明MGFAM 和深层次特征融合的有效性,进行了模型简化测试。除了MGFAM 和融合方式的不同组合之外,所有其他配置都相同。图4展示了不同组合的视觉效果。
2.2.1 MGFAM的有效性
为了捕获图像丰富的全局上下文信息,本文引入了MGFAM。本文在选择插入MGFAM 的VGG-16 网络层次上做了更多考虑。如果输入MGFAM 的特征图分辨率太大,那么在进行分尺度池化的过程中,对于分辨率大的特征图来说因为直接将其全局池化至1×1、2×2 等很小的尺度,在获取全局信息的同时会丢失更多信息。按照设想,分别在VGG-16 每层都添加MGFAM,最后因为损失太大很难完成显著性检测任务。
除此之外,本文通过实验做了更多的尝试,比如只在Conv1 后加MGFAM,只在Conv2 后加MGFAM,分别在Conv1、Conv2、Conv3 后加MGFAM 等,实验证明在VGG-16 网络的较浅层添加MGFAM,反而会因为损失太大而严重干扰检测结果。
因此,在前期实验中只在分辨率最低的Conv5 后添加MGFAM。如表1,MGFAM 使得检测结果在ECSSD 数据集上的F-measure 和MAE 均得到了提升。MGFAM 多尺度多区域的池化操作,更突出了显著物体在全局上的完整性。如图4(c),是不加MGFAM 的基础结果,对于感受野比较有限的模型,总是错误地将背景估计为显著物体。而图4(e),是在Conv5 后添加MGFAM 之后的检测结果。可以明显地观察到,引入的MGFAM在显著性检测任务中起到了较好的效果。
为了进一步证明MGFAM 的有效性,本文选择结构和MGFAM 相似,具有代表性的多平行分支提取特征的模块ASPP(Atrous Spatial Pyramid Pooling)[22]来做比较。图4(d)展示了引入ASPP模块后的最终检测结果。可以明显地观察到,虽然ASPP模块因为集成了不同感受野下的多尺度信息,起到了一些作用,但是ASPP因为是一种稀疏的操作会造成棋盘伪影效应,并且因为缺乏全局信息的提取,很易受到复杂背景干扰。
2.2.2 特征融合的有效性
在提取特征信息的过程中,既想要得到对细节感知能力较强的信息,又不想因为分辨率太大,使得在多尺度全局池化时让信息损失太多,所以在融合方法的设计上本文放弃了在较底层上做处理。Conv3 层作为承上启下的中间层,往往无法捕获有判别力的特征信息。通过实验表明,Conv3 对结果没有决定性的影响,为了避免信息的冗余利用,放弃了选择连同Conv3 层做融合操作,只在Conv4 层和Conv5 层加入多尺度全局池化特征聚合模块。
而针对融合和多尺度全局池化的先后顺序,本文通过实验又做了进一步的探讨。表1 第1 行第4~6 列数据为先将Conv4层和Conv5层输出的特征信息融合后再使用MGFAM进行多尺度全局池化(MFa)的F-measure(Max F)及MAE 结果,由表1可以看出,相较于只在Conv5层后添加MGFAM(表1中MGFAM)效果又有进一步提升。接着改变策略进行实验,在Conv4 层和Conv5 层后先分别加入MGFAM,将其分别经过MGFAM 提取后的多尺度全局信息再进行特征融合操作(MFp),实验结果(第2 行第4~6 列数据)表明,这种操作因分层处理有更好的表现。

表1 ECSSD数据集上模型简化测试结果Tab.1 Model simplification test results on ECSSD dataset
由表1 ECSSD 数据集上进行模型简化测试结果可以看出,模型中的MGFAM 以及融合操作都至关重要,并且都为检测性能做出了一定的贡献。
由图4 可以看出,在Conv4 和Conv5 分层添加MGFAM 后再进行特征融合的操作,既得到了对细节的感知能力较强的信息(第1 行),又获得了丰富的全局信息,使得显著性检测结果对前景和背景的分辨能力更强(第2~3行)。

图4 模型简化测试结果Fig.4 Model simplification test results
2.3 性能与比较
将本文提出的显著性目标检测模型与较先进的7 种算法进行了对比。其中HS(Hierarchical Saliency detection)[23]、wCtr(saliency optimization from robust background detection)[24]是传统的显著性检测算法,而PFAN(Pyramid Feature Attention Network for saliency detection)[25]、BDMP(Bi-Directional Message Passing model for salient object detection)[13]、DGRL(Detect Globally,Refine Locally)[15]、NLDF(Non-Local Deep Features for salient object detection)[12]和DSS(Deeply Supervised Salient object detection with short connections)[26]是基于深度学习的显著性目标检测算法。为了保证对比实验的公平性,NLDF、BDMP、DGRL 等主流的深度学习算法结果是使用原文作者提供的开源代码以及模型来进行训练、测试及评价获得的。对于PFAN 算法本文按照原文作者所提供的图像结果进行评价,获取最终的指标评价结果。
2.3.1 定量评估
本文的算法在4 个基准数据集上与7 种主流的显著性检测算法进行了比较。从表2 可以看出,本文的算法在ECSSD数据集上相较于HS、wCtr 等传统显著性检测算法在Fmeasure 值上提高了0.25 左右,MAE 也分别降低了0.18 和0.12。除此之外,相较于NLDF以及BDMP等较先进的基于深度的显著性检测算法,F-measure 值分别提高0.028 和0.008;其中相较于NLDF 算法,MAE 值也降低了0.023。除此之外,该算法在其他数据集下的F-measure 和MAE 均有较好的表现,这有力地证明了本文所改进的模型的有效性。图5 列出了4 个数据集上不同算法的PR 曲线。由图5 可以看出,本文算法的PR(Precision-Recall)曲线在4 个数据集上的表现总体优于其他算法。

表2 本文算法与7种显著性目标检测算法在4个广泛使用的数据集上的定量比较Tab.2 Qualitative comparison of the proposed algorithm with 7 saliency object detection methods on 4 widely used datasets

图5 8种算法在4个流行的显著性目标检测数据集上的PR曲线对比Fig.5 Precision-Recall curves comparison of eight algorithms on 4 popular salient object detection datasets
表3 列出本文在NVIDIA 1080Ti GPU 的硬件设备条件下测试一张输入图像的平均消耗时间。由表可以看出,本文的全卷积网络模型,与大多数先前的显著目标检测算法相比,也达到了较高的运算速度。
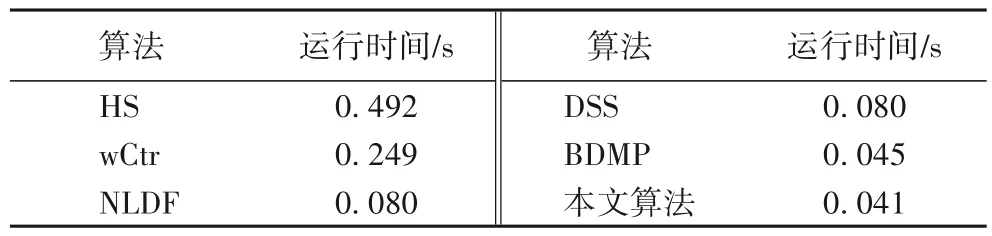
表3 各算法平均运行时间比较Tab.3 Average running time comparison of different methods
2.3.2 定性评估
为了进一步证明本文算法的优势所在,图6展示了本文算法最终显著性预测结果,从而定性地分析模型优越性。图6列出了本文模型和7种经典算法生成的显著图的视觉效果对比。

图6 本文算法与7种显著性目标检测算法结果的定性比较Fig.6 Quantitative comparison of the results of the proposed algorithm and 7 salient object detection methods
从图6中(第1行)可以清晰地看出,本文的算法针对前景和背景不明显的图片依然有较好的检测效果。不论是对于有复杂场景(第2、3行),还是多对象(4、5行)、小对象(6、7行)以及大对象(8、9 行)的图片均有不错的检测效果。除此之外,因为同时也集成上下文信息,分层提取特征,所以本文的算法不仅在全局方面能更可靠地检测,在边缘细节上也有较好的表现,如图6(第8、9行)。
但是在多尺度全局池化的过程中,不可避免地会造成一定的信息丢失;同时,在传递方式上的选择也不够优雅,虽然给底层提供了更有判别力的全局信息,但是因其多倍的上采样,使得结果在边缘和细节的处理上仍然不够乐观。
3 结语
本文提出了一种基于多级全局信息传递模型的显著性检测算法,算法引入了多尺度全局特征聚合模块,并且提出了有效的深层次特征融合算法,最终采用多层次特征传递的方式将较低层的特征信息和较高层全局特征信息组合,从而获得显著性目标区域。通过定性与定量实验比较验证了本文提出的算法不论是在性能上还是在速度上均有较好的表现。
针对多层级多尺度池化和上采样带来的信息损失问题,在未来的工作中,将考虑在充分利用全局信息的同时,增强边缘和细节上的处理;此外,将进一步优化网络结构,探索新的信息传递方法来减少信息损失。
猜你喜欢
计算机应用(2022年9期)2022-09-25
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
黑龙江大学自然科学学报(2022年1期)2022-03-29
软件导刊(2022年3期)2022-03-25
计算机仿真(2021年7期)2021-11-17
中国知识产权(2018年12期)2018-12-29
金桥(2018年4期)2018-09-26
智能计算机与应用(2018年2期)2018-05-23
中国知识产权(2017年5期)2017-05-25
