
基于GA优化的支持向量机模型在青椒作物需水量预测中的应用
2021-01-27 00:25刘婧然武海霞李灶鹏
节水灌溉 2021年1期
刘婧然,刘 心,武海霞,邓 皓,李灶鹏
(1.河北工程大学水利水电学院,河北 邯郸056038;2.河北省智慧水利重点实验室,河北 邯郸056038)
0 引 言
近年来,随着经济的发展、人口的增长,水资源短缺问题日益突出。2025年农业用水量需增加19%,才能满足基本粮食需要[1]。中国是农业大国,农业是最主要的用水部门[2-3]。2018年,农业用水占用水总量的61%以上[4]。农田灌溉用水量占农业用水量的80%以上[5]。在干旱和半干旱地区,灌溉用水尤其匮乏,因此,实现智能精准灌溉,进行作物需水量预测,节约农业灌溉用水,对缓解水资源短缺问题尤为重要。
气象条件,农业技术措施等均会对作物需水量产生影响。作物需水量与其影响因素之间呈非线性关系,采用人工智能方法模拟非线性关系已得到广泛应用[6],因此很多学者用人工神经网络(ANN)对作物需水量进行预测:李志新[7]等构建了GA-Elman 神经网络参考作物需水量预测模型;孟玮[8]等建立基于人工蜂群算法的径向基网络预测日参考作物需水量模型;邓皓[9]等提出基于MIV-MEA-Elman 核桃果实膨大期作物需水量预测模型;Abrishami[10]等采用ANN 对小麦和玉米日实际需水量进行估算。此外,支持向量机(SVM)也是人工智能领域中的重要算法模型之一,与ANN 相比,SVM 能够很好地克服ANN 训练时间长,训练结果存在随机性和过学习等不足[6]。彭世彰[11]等建立了有较强适应性的基于支持向量回归机的参考作物腾发量实时预报模型,该模型比BP 神经网络模型有更优的泛化能力;郭淑海[12]等用最小二乘支持向量机对实际蒸散发量进行了估算,估算精度较高;杨会娟[6]等在气象资料短缺的干旱地区,建立了预测精度较高的基于SVM 的月潜在蒸散发模型;Yunjun Yao[13]等人用贝叶斯模型平均法、一般回归神经网络法以及SVM 法估计地面蒸散发,发现SVM 优于其他方法。
以上所述作物需水量(ET)预测模型的输入变量大多仅选用了常规的气象因素(气温、风速等)。因为气象因素是作物需水量的主要影响因素之一,但是除气象因素之外,作物因素、种植模式也会对作物需水量产生影响[14]。对植物而言,作物冠层温度(Tc)是反映作物水分状况的一个良好指标,当植物受到水分胁迫、土壤水分亏缺时,导致许多植物气孔关闭,Tc升高[15-16],可见,Tc与作物需水量息息相关。但以往的作物需水量预测模型研究鲜见将Tc作为预测模型的输入因素之一,同时,Tc的获取克服了作物其它生理参数测量时取样误差较大和费时的缺点[17],因此本文探讨了将Tc引入作物需水量预测模型的适用性。此外,针对节水灌溉的特定种植模式下青椒实际作物需水量(ET)的预测模型研究也较少。滴灌(Drip irrigation)是一种现代高效节水灌溉技术,在国内外已被广泛应用[18]。垄沟集雨覆盖种植技术采用沟垄集雨、秸秆覆盖技术改善土壤水热状况,减少土壤水分散失,提高作物产量和水分利用效率,该技术已成为全球农田生态系统的一项重要的集水节灌技术[19-23]。本文将滴灌、秸秆覆盖、垄沟集雨技术相结合(MFR-DI),用于青椒种植,并对青椒ET 的SVM预测模型进行研究,实现多重节水。为避免模型训练过程中出现局部最优解,采用具有较强全局优化能力的遗传算法(GA)优化SVM 模型。同时,探讨了在模型输入因子中引入Tc时,预测模型的适用性,为实际作物需水量预测提供参考,对节约水资源有重要的现实意义。
1 数据来源及模型构建
1.1 数据来源
试验在河北省邯郸市河北工程大学精准灌溉试验场进行(36°35′20″N,114°29′23″E,海拔62.22 m)。试验布置如图1所示,试验小区长为1.2 m,宽为1 m,植株行距50 cm,株距30 cm。集雨滴灌(MFR-DI)种植中,垄和沟的宽度分别约为40 cm和60 cm,垄的高度约15 cm,垄上铺设塑料薄膜。青椒种植于沟内,同时将玉米秸秆粉碎成20 cm 左右碎段,均匀撒于集雨沟内,测孔距离滴头5 cm。青椒生育期划分为4个阶段:苗期(约35 d)、开花坐果期(约30 d)、结果盛期(约45 d)、结果后期(约40 d)。研究区气候为温带大陆性季风气候,年平均气温14°C,多年平均降水量548 mm,全年无霜期200 d,年日照时数2 557 h。精准灌溉试验场设有自动气象站,记录的主要气象数据有:气温(°C)、日平均相对湿度(%)、日平均风速(m/s)等。冠层温度(Tc)采用红外热像仪测量,测量精度为0.07°C。在试验小区内选取长势均匀的4棵植株,测量每棵植株东南西北各方向的顶部叶片,4个方向的顶部叶片温度平均值为青椒植株的冠层温度。将小区内4棵植株的冠层温度平均值作为本小区青椒的冠层温度。Tc观测时间为8∶00-18∶00,每小时测量一次。将每日测量的均值作为日平均冠层温度。青椒作物需水量的计算根据水量平衡方程求出[14],试验区无地下水补给。
试验地土壤土质均匀一致,均为壤土,0~40 cm 土层内的平均容重1.54 g/cm3,田间持水量(占干土质量)为27%,土壤pH值约为7.42。
1.2 GA-SVM 青椒作物需水量预测模型构建
1.2.1 支持向量机
支持向量机(SVM)是1995年由贝尔实验室的Vapnik 和其研究团队在统计学习理论的基础上提出来的一种机器学习算法[24]。支持向量机是建立在统计学理论的VC 维理论和结构风险最小原理基础上的,通过非线性核函数,将输入样本空间映射到高维线性特征空间,因此可以处理高度非线性的分类和回归等问题[12]。该算法的基础依据主要是ε-不敏感函数(ε-insensitive function)和核函数(kernel-function)算法。假定训练样本集为(xi,yi),i=1,2,…,n,xi为输入矢量,yi为对应的输出结果。φ(xi)为样本数据转换到高维空间的非线性映射,则在高维空间的线性回归表达式为[25]:
式中:w为权值矢量;b为偏置值。
w和b有最优解,可用下列函数得到[25]:
约束条件:
式中:C 为惩罚因子,即对SVM 出错时的惩罚程度,此参数的设置有效防止了个别误差影响支持向量机整体的优化性能[25]。
根据非线性回归问题在高维空间的解法,最终得到支持向量机的回归函数(即ε-不敏感函数)为:
ε-不敏感函数所得结果是该曲线和训练点的“ε管道”[11]。其中ai*和ai为拉格朗日系数,xiT为样本向量的转置,i=1,2,…,n;x为支持向量。在所有样本点中,只有分布在“管壁”上的那一部分样本点才决定管道的位置,这部分训练样本称为“支持向量”,这一求解策略使过拟合受到限制,因此能够显著提高模型的预报能力[11]。
核函数是预报样本点的向量x的函数Φ(x)与支持向量x′的函数Φ(x′)的内积[11]。
本文使用RBF 核函数,其表达式为exp (- g|x - xi|2),核函数参数g和惩罚因子C 是影响SVM 性能的主要参数[25],使用遗传算法(GA)对SVM的主要参数进行优化。
1.2.2 遗传算法
遗传算法(GA)是一种模拟自然界生物进化机制的随机全局搜索和优化方法,其本质是一种高效、并行、全局搜索的方法,具有很强的解决问题能力和广泛的适应性[26]。该理论利用一组称为群体的染色体进行操作。该算法包括种群初始化、适应度评价、选择、交叉和变异五个过程。首先对所有可能的解进行编码产生初始种群,然后计算种群中每个个体的适应度值,根据适应度值选择下一代个体,本文采用轮盘赌方法进行选择操作,之后对选出的个体进行交叉、变异操作以产生新的个体,再对新个体继续进行选择、交叉、变异操作[7,24,26],当满足终止条件时输出、解码最优个体,得到SVM 最优参数g和C的初始输入值。通过反复试验,设定参数见表1 所示:种群大小100,交叉概率为0.8,变异概率为0.01,迭代次数为100。

表1 遗传算法参数设置Tab.1 Parameter setting of Genetic Algorithm
1.2.3 GA-SVM 预测模型构建
合理选择SVM 的参数C 和g,对于提高SVM 预测模型的性能至关重要,传统SVM 预测模型随机生成参数值,预测存在不稳定因素。GA 具有较强的寻优能力,本文选取GA 优化SVM 的主要参数,构建GA-SVM 预测模型,构建思路如图2所示,具体步骤如下:
(1)首先进行数据的采集与预处理。将得到的气象数据、作物需水量等数据进行归一化处理,消除原始数据之间的量纲差异。
(2)种群初始化与编码[26]。构建一定数量的初始种群,并设置惩罚因子C 和核函数参数g的取值范围,对这两个参数进行二进制编码。
(3)计算适应度函数与解码。计算个体适应度函数,如果满足要求,解码种群中的染色体,获取C 及g 并进行步骤(5) 的模型训练,如果适应度函数不满足要求则进行步骤(4)。
(4)选择、交叉、变异操作。根据适应度值来决定选择下一代的个体,采用“轮盘赌”选择法进行个体选择。之后对选出的个体进行交叉、变异操作来产生新个体,再次进行适应度计算,当满足遗传算法的终止条件时输出、解码最优参数组合,进行步骤(5),否则再次进行步骤(4),即选择、交叉、变异操作产生新一代种群,开始新的遗传。
(5)将最优参数C及g输入SVM预测模型中进行训练。
(6)当模型预测精度达到要求,则输出预测结果,否则需重新调整参数C和g的初始化寻优范围。
2 结果分析与评价
2.1 数据分析及处理
MFR-DI种植方式下青椒作物实际需水量(ET)在作物生长发育期内的变化规律如图3 所示,从图3 可以看出,2014-2017年,青椒从苗期到结果盛期ET 波动式逐渐增加,至结果盛期达到最大值,之后到结果后期阶段ET 又波动式逐渐减少,但仍比苗期的ET大。总体来看,青椒ET在生育期内呈现出周期规律性变化。
MFR-DI 种植方式下青椒作物冠层温度(Tc)与同时段测得的平均气温在作物生长发育期内的变化规律如图4所示,可以看出,2014-2017年,气温与Tc的变化规律均为苗期最低,随后逐渐波动增加,至结果盛期达最高值,之后又逐渐波动降低。气温始终高于Tc。并且Tc与气温之间的差距(冠气温差的绝对值)在苗期最小,随后逐渐增加,到结果盛期最大,之后又逐渐降低,但仍比苗期差距大。经过相关回归分析,同一时间段Tc与气温的相关系数R2约为0.95。Tc与同一天的平均气温的相关系数R2约为0.9,说明Tc与气温关系密切。而气温又是影响作物需水量的重要气象因素之一。综上所述,青椒作物冠层温度与气温、作物需水量息息相关,有必要将其作为预测ET的输入向量之一。
在模型预测时为便于模型训练,消除原始数据之间的量纲差异以及极值对模型的影响,更好地反映各因素之间的相互关系,需要对样本数据进行归一化预处理,将数据转换到[0,1]之间。采用公式(5)进行归一化处理。
式中:xi(i=1,2,…,n)为第i 个样本数据;x′i为归一化后的数值;xmax=max{xi},xmin=min{xi}。
不仅要对模型的输入数据进行处理,对输出数据也应进行归一化处理。对使用模型预测的输出数据,还应进行还原计算,还原计算是公式(5)的逆计算过程,以恢复其实际值。
2.2 预测模型的性能评价
使用均方根误差(RMSE)、平均绝对误差(MAE)和纳什效率系数(Nash-Sutcliffe coefficient,NS)等来评价模型性能。
式中:Pi为预测值;Oi为计算值(观测值);ETmean为计算值的均值;N 为观测数。RMSE 和MAE 的单位都是mm/d,取值范围从0到∞。NS是无量纲的,取值范围从1到-∞。对模型进行评价时,RMSE和MAE越小,NS越大,预测精度越高。
2.3 GA-SVM 模型的预测结果分析与评价
以2014-2016年的数据样本进行训练,以2017年的数据样本进行验证。选择了不同输入组合建立了预测模型,如表2所示,其中T 为温度,包括日最高气温(Tmax),日最低气温(Tmin)和日平均气温(Tmean);RH 为日平均相对湿度;Ph为日平均气压;u2为两米处风速;Rs为太阳辐射;Tc为青椒冠层温度。因此,所有模型的输入向量数为7,输出结果为MFR-DI种植方式下青椒作物实际需水量。设置遗传种群数量大小为100,迭代次数为100,交叉概率0.8,变异概率0.01,惩罚因子C的变化范围为0~100,核函数参数g的变化范围为0~20,经过反复训练,搜索到SVM最优参数C为0.162 8,g为1.528 8。根据遗传算法寻优得到的最优参数C和g建立GA-SVM 预测模型并进行2017年青椒作物需水量预测,预测结果如图5和表3所示。
图5可以看出,在预测模型输入向量一致的情况下,GASVM 模型预测青椒作物需水量的精度比SVM 模型精度高,且预测性能稳定。为检验模型预测值与计算值ET(即期望目标值)之间的相关性,对二者进行了回归分析,GA-SVM1 模型预测值与计算值ET 相关系数R2为0.807 33,而SVM 模型的R2为0.728 63。表明GA-SVM 模型比SVM 模型的预测值与计算值之间具有更强的一致性。表3 为GA-SVM 与SVM 模型预测结果的统计性能分析表,可见SVM 与GA-SVM1 模型的RMSE分别为0.960 7、0.901 0 mm/d;MAE 分别为0.769 1、0.673 5 mm/d;NS分别为0.968 0、0.971 8,说明GA-SVM 模型的预测性能优于SVM 模型。由以上分析可知,在输入相同因素向量时,GA-SVM 比SVM 预测模型具有更高的精度性能。因此,本文仅选取GA-SVM 预测模型,讨论了模型输入因素引入冠层温度时对模型的预测性能产生的影响。

表2 MFR-DI种植模式下基于SVM预测模型的输入组合Tab.2 Summary of input combinations for SVM prediction model in MFR-DI
2.4 引入冠层温度的GA-SVM 模型预测结果分析与评价
通过对作物需水量的影响因素(气象因素,Tc)与作物需水量之间进行相关回归分析,发现Ph与作物需水量的相关关系比Tc与作物需水量的相关关系弱,因此将GA-SVM1 预测模型气象因素中的Ph替换为Tc,以保证模型的输入向量个数不变,如表2 所示(即将GA-SVM1 模型转变为GA-SVM2 模型)。GA-SVM2 模型预测2017年的作物需水量预测模型性能评价结果如图6及表3所示。
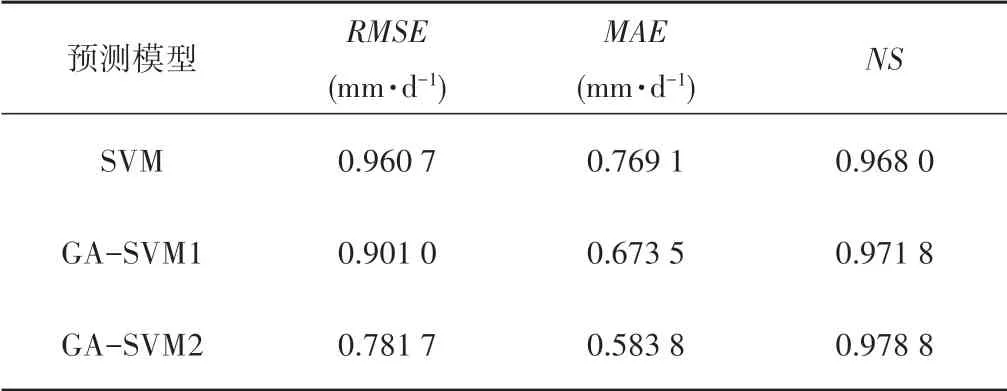
表3 ET预测模型的性能对比Tab.3 Performance comparison of ET prediction models
由图6可以看出,GA-SVM2模型预测值与计算值ET 相关系数R2为0.830 58,比GA-SVM1 的R2约提高了2.9%,比SVM约提高了14%。另外,从表3可见,GA-SVM2的RMSE,MAE和NS分别为:0.781 7,0.583 8和0.978 8。可以明显看出引入冠层温度的GA-SVM2 预测模型的预测结果比单独输入气象因素的GA-SVM1 模型预测的结果更接近ET 计算值(期望目标值),即GA-SVM2模型预测的准确度比GA-SVM1和SVM模型预测的准确度都高。因此,引入影响作物需水量的作物因素中的Tc对预测青椒ET模型起到了积极作用。
3 结 语
本文使用支持向量基作为非线性拟合方法,用于河北省南部地区MFR-DI种植模式下青椒作物需水量的预测,为实现多重、高效节水灌溉提供参考。利用农田水量平衡原理计算得到ET数据(期望目标值),以2014-2016年数据作为训练样本,对2017年模型预测结果进行了验证。在输入因子相同的情况下,GA-SVM 模型的预测结果优于SVM 模型,由于GA算法的优化,提高了SVM 预测模型的收敛速度,使预测模型的精确度更高,实用性更强。
另外,在预测模型的输入向量中引入了影响作物需水量的作物因素(冠层温度,Tc)。通过对该预测模型的性能评价可见,采用引入Tc的GA-SVM2 模型预测结果的准确度最高,其RMSE,MAE,NS,R2分别为:0.781 7 mm/d,0.583 8 mm/d,0.978 8,0.8305 8。综上所述,引入Tc的GA-SVM 方法为预测青椒作物需水量提供了新思路。
GA-SVM 预测模型参数是在一定自然条件及管理水平下试验获取,有一定的适用范围,并且各物理量之间的关系不能通过预测模型反映出来,这是此类预测模型不可避免的局限性。
猜你喜欢
水土保持通报(2022年3期)2022-10-15
农业工程学报(2022年12期)2022-09-09
农业机械学报(2022年7期)2022-08-08
作物杂志(2022年3期)2022-07-06
作物学报(2022年5期)2022-03-16
新疆农业科学(2021年11期)2021-12-23
食品与生活(2021年9期)2021-09-26
家庭百事通·健康一点通(2020年4期)2020-06-09
广东第二课堂·小学(2019年10期)2019-10-28
水能经济(2018年1期)2018-10-14
