
基于镜像层关联的Docker注册表缓存预取策略
2021-02-05 18:10邓玉辉
计算机与生活 2021年2期
张 晨,邓玉辉,2+
1.暨南大学信息科学技术学院计算机科学系,广州 510632
2.中国科学院计算技术研究所计算机体系结构国家重点实验室,北京 100190
在过去的十年中,Xen、VMware、KVM 和Hyper-V是大多数云计算系统使用的虚拟机管理程序,为云计算在共享池中快速配置和释放计算机资源提供支撑。随着操作系统虚拟化的快速发展,其较强的兼容性和较低的资源开销吸引Google 和IBM 等企业使用容器[1]来创建隔离的虚拟环境[2]。Docke 是Linux平台上的一款轻量级容器管理引擎,不仅具有很好的性能优势和安全性,而且能帮助用户提升持续集成/持续交付(continuous integration/continuous delivery,CI/CD)的效率。例如,ING 是全球十大金融服务公司之一,通过使用Docker 部署高度自动化的CD 流水线,为基础设施资源节约了50%的开销(https://www.docker.com/blog/docker-selected-as-gartner-cool-vendorin-devops)。在业界对容器技术强烈的需求导向之下,越来越多的企业在生产环境中使用Docker 进行大规模任务部署。
在实际项目中,企业通常利用Docker 提供的注册表服务来解决容器镜像的分发和存储问题。目前,市场上有不同云服务商提供的Docker 注册表实例,如Docker Hub(https://hub.docker.com/)、Google Container Registry(https://cloud.google.com/containerregistry/)、IBM Cloud Container Registry 和Amazon Elastic Container Registry(http://aws.amazon.com/cn/ecr/)等,注册表提供一套REST(representational state transfer)接口用于Docker客户端向注册表自由发布镜像并供他人下载。图1 是IBM Cloud Registry 的部署架构,负载均衡器将用户请求分配到不同地区的注册表服务器中,注册表服务器均采用对象存储服务(例如Amazon S3),无冲突地写入共同的后端存储[3-4]。据统计,大型容器公共注册表至少存储数百TB 数据,每天增加1 500 个公共镜像存储库[5],并且私人镜像存储库也在不断更新。有工作表明,从此类规模的注册表中拉取镜像的时间占容器总启动时间的76%[6]。

Fig.1 IBM Cloud Registry architecture图1 IBM Cloud Registry 架构
在传统Docker 注册表架构中,注册表由负载均衡器、注册表服务器、对象存储服务器等组件构成,在用户发出构建容器指令后,Docker 客户端发出请求会遍历所有组件。图2 展示了分析IBM 注册表trace 数据集得出用户拉取镜像层的延迟分布情况,大约88%的镜像层拉取延迟小于5 s,拉取单个镜像层的最长延迟超过2 min。由于容器启动需要收集完整镜像,通常镜像由数十个镜像层组成,且Docker 客户端最大并行拉取3 个镜像层,在大型公共容器注册表的场景下,拉取镜像请求的高延迟已经大大削弱容器快速启动的特性,因此减少拉取镜像延迟成为研究的热点。
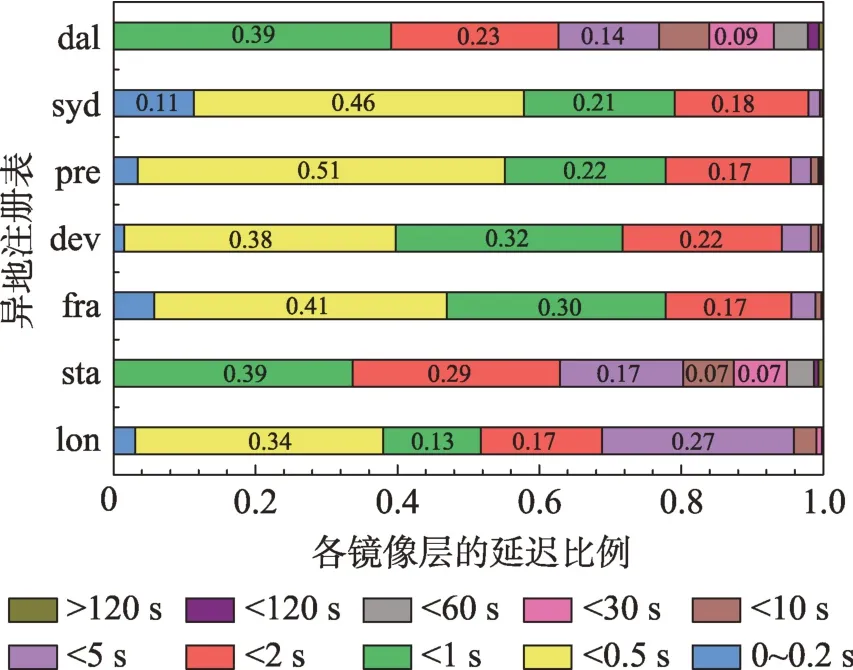
Fig.2 Distribution of image layes pulling delay in IBM Cloud Registry图2 通过IBM 注册表拉取镜像层的延迟分布
目前,国内针对容器技术开展了很多研究,例如通过分析以Docker 为代表的自动化工具在实践中出现的问题,深入探讨Docker 对中国DevOps 的影响并提出相关建议[7],有的研究从技术架构分析容器技术特点,并从容器实例层、管理层和内核资源层梳理操作系统虚拟化的现状[8],有的研究提出一种服务质量敏感的,基于前馈的容器资源弹性供给方法,解决传统虚拟化环境中资源供给时效差和难以应对负载突变的问题[9]。国外研究聚焦优化镜像拉取延迟问题,如Harter 等人提出的Slacker[6],该方案在拉取镜像的最初时刻仅检索并传输启动容器的最小数据集,然后采用lazy cloning和lazy propagation的方式从共享NFS(network file system)存储中提取剩余需要的镜像数据,从而缩短了容器的启动时间,但这种方案需要注册表与客户端保持持续连接,协作要求较高。Nathan等人[10]提出了一种在一组节点之间使用P2P 协议协作管理Docker 镜像的系统——CoMICon,该系统在接收到用户请求时会优先从邻近的节点获取缺失的层,然后查询远程注册表,并行拉取镜像的方法能有效缩短网络传输延迟,加快容器的启动与部署。
由上述分析发现,现有的研究工作对于中小规模组织中容器部署场景的优化已经相当成熟,因此从网络或存储驱动等方面对Docker 做出改进的空间有限。基于现有云服务商重新设计注册表架构的背景下,本文以注册表服务器组件为核心优化点,从Docker 镜像结构和注册表功能出发,提出一种基于镜像层相关性的缓存预取方案,将部分体积较小的热点镜像层预先从后端取回,缓存至注册表服务器内存中,当用户请求命中时即可拉取镜像。本文方案提高了注册表内存资源利用率的同时,减少请求跳数和后端I/O 压力,缩短用户拉取镜像的流程从而隐藏耗费的网络延迟,最终加快容器启动速度。这项工作的主要贡献概括如下:
(1)通过研究镜像层存储机制,利用镜像层的空间局部性设计关联模型,最终实现一种基于镜像层关联的Docker 注册表缓存预取策略LCPA(layer correlation prefetch algorithm)。
(2)在本文方法中,实现由镜像结构提取模块、拉取请求处理模块和关联镜像层计算模块为核心的模拟仿真器,并利用基于真实负载下的Docker 数据集进行实验。
(3)验证了LCPA 策略的正确性和有效性。实验结果表明,与LRU(least recently used)、LIRS(low interreference recency set replacement policy)、GDFS(greedy dual frequency size)和LPA(least prefetching algorithm)算法相比,本文提出的预取策略在缓存命中率和节省延迟方面有着明显的性能提高。
1 背景知识
1.1 缓存算法和预取算法
随着对缓存管理的不断研究,针对不同工作负载的缓存替换算法相继提出,通常划分为以LRU[11]、LFU(least frequently used)[12]、SLRU(size least recently used)[13]、GD(greedy dual)[14]、RAND 为代表的五类算法。虽然LRU 在现有的各种应用场景中都能发挥比较稳定的性能,但依旧存在一些不足,例如LRU 对再次访问的数据会放置队首,重置它的缓存周期,从而带来“缓存污染”,同时缺少对数据多维度的考量,捕捉数据体积较大的文件会导致命中率降低,无法适应局部性较弱的访问模式。
LIRS 是一种突破LRU 限制的算法,使用重用距离作为缓存替换的依据,有效避免了LRU 中冷热数据相同的缓存周期,提高了对未来可能访问数据的命中。LIRS 将缓存划分成LIR(low inter-reference)堆栈和HIR(high inter-reference)堆栈,将空间较小的HIR堆栈作为二级缓存,捕捉重用距离小的数据并送入LIR 栈,替换掉长时间没有重复被命中的数据。这个特性同样给算法带来不足,一个冷数据在HIR 栈中短时间命中两次之后再无访问,则该数据将在LIR 栈中经历全部数据流出后才被替换,造成一定程度的“缓存污染”。
GDFS 算法的核心是利用数据的大小、访问频率以及访问代价建立老化函数,并给参数分配不同的权值,最终给每一个数据计算出相应的特征值。考虑到时间局部性,老化因子是随时间而增大的,短期内命中的数据特征值较大且更新在缓存队列中的位置。GDFS 根据访问情况每次淘汰掉特征值最小的数据,但算法并不能跟随自适应工作负载的变化,向公式添加新的适应性参数会提高算法复杂性,带来较高的性能开销。
预取技术是提高云存储系统性能的重要研究方向,现代数据中心使用分布式内存缓存服务器(https://memcached.org/,https://redis.io/)[15]来提高数据库查询性能,同时结合缓存和预取[16-17]技术能显著地提高缓存命中率。
1.2 镜像层的相关性
注册表通常会将请求信息存储在日志中,分析日志可得出对镜像操作的请求信息,例如请求时间、响应时间、用户IP、HTTP 请求方法等,这些信息主要被以时间相关性为基础的缓存算法利用,使得LRU、LIRS 和GDFS 根据时间局部性来筛选需要缓存的镜像。由于Docker 镜像的分层机制,用户向注册表发出的请求并不是每次都拉取所有镜像层,而是根据用户本地的存储情况,拉取缺失镜像层。为了保证镜像完整性,即使本地存储所需的全部镜像层,客户端依然会发送请求取回镜像元文件进行校验,这种模式削弱了镜像层之间的时间相关性,因此本文同时考虑镜像层的空间相关性。
当用户上传镜像时,注册表对镜像计算得出为manifest 的元数据文件,文件包含了例如镜像大小、默认参数、镜像层标识等属性,通过分析镜像元数据文件能精准地还原镜像的存储结构。注册表的存储基本单位是镜像仓库,每个仓库包含了同一应用软件或不同版本操作系统镜像,整个仓库的镜像层结构呈树型,处于不同位置的镜像层与其周边的镜像层存在不同的关联度,用户往往会拉取一连串相关镜像,此时,如何衡量镜像的关联度并得出未来可能请求的镜像层成为问题的关键。
2 基于镜像层关联的注册表缓存预取策略LCPA
LCPA 策略的核心思想是利用镜像层存储的空间局部性,建立关联度模型来预测与未命中请求可能相关的镜像层,预先从后端存储服务器取回缓存在注册表服务器中。LCPA 主要解决两个难点,即如何计算注册表中未命中镜像层的相关镜像层和如何设置预取操作的触发点。因此,策略的设计思路也合理地分为两个部分:一方面是收集并构造每个容器镜像的结构,将同一仓库的镜像结构整合起来,依照镜像层之间的强关联、弱关联和无关联构建关联度模型,还需要考虑时间和频率等属性来辅助计算相关镜像层集合。另一方面是算法分析了用户拉取镜像的请求流程,虽然部分请求环节均可以设置为预取的触发点,为了达到最好的效果,触发点应该设置为每一个镜像仓库中第二个未命中镜像层缓存的拉取请求,能够有效过滤针对镜像元文件的冗余请求,从而避免了重复预取带来的性能开销以及缓存污染的危险。
本策略充分利用注册表服务器的存储资源,通过关联模型确定镜像层集合并预取至注册表,弥补触发预取操作的未命中损失,整体提升缓存命中率,解决用户拉取镜像的延迟问题。为了比较效果,算法的缓存替换部分结合了LRU,针对镜像层的场景进行了改进,下面介绍LCPA 模拟仿真器的框架。
2.1 模拟仿真器框架
图3 是LCPA 策略模拟仿真器的架构,其中包含工作流和主要模块,缓存包含着镜像层和元数据文件。三个核心模块为镜像结构提取模块(layer select extract,LSE)、拉取请求处理模块(prefetching request handler,PRH)和关联镜像层计算模块(correlation layer calculate,CLC),各自的工作流如下:
(1)LSE 从元数据文件中解析出镜像层之间的结构关系,整合同一镜像仓库的所有镜像结构,并以键值对的数据结构存储。

Fig.3 Architecture of LCPA simulator图3 LCPA 模拟仿真器的架构图
(2)PRH 设置注册表缓存的预取触发点,并将请求信息发送到CLC。
(3)CLC 通过镜像层结构关系和关联度模型计算出相关镜像层集合,向后端拉取注册表缓存中缺失的镜像层,实现预取以提高请求命中率。
2.2 镜像结构提取模块
LCPA 策略的核心是通过镜像层存储的空间局部性来计算相关镜像层,那么研究镜像层存储机制并收集镜像层的结构关系就尤为重要。图4 表示镜像层结构以及镜像的元数据文件,镜像是由被压缩为tarball 的镜像层组成的只读文件系统,每一个镜像层包含了可执行文件、相关依赖库和配置文件,并通过基于SHA256 的内容寻址算法生成的digest来对其标识。元数据文件包含了父镜像ID、默认参数、创建日期,以及每个镜像层的内容可寻址标识符等镜像基本信息,当用户拉取或推送镜像时,元数据文件作为镜像基础信息的描述文件被短时间存入注册表服务器。此时,镜像结构提取模块通过解析元数据文件,按由底向上的存储顺序,将每个镜像层的digest 和镜像层大小与请求到达时间戳以字典数据结构存入内存中,同时在每个新增镜像层的value 中添加值为1的流行度字段,每当拉取请求处理模块处理有效拉取请求,则向对应镜像层的流行度字段修改加1,为关联镜像层预取模块提供每个镜像层实时的流行度。
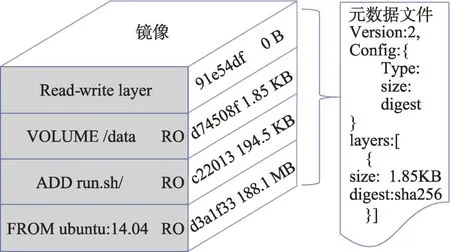
Fig.4 Docker image stored architecture图4 Docker镜像存储结构
在图4 的栈式镜像存储结构中,最顶部的镜像层由用户根据业务需求制作的可写容器层转化形成,越靠近顶部的镜像层越能代表整个镜像的专用性,越靠近底部包含越多的依赖库,最底部的镜像层一般为包含操作系统的基础镜像,被不同镜像共享使用。虽然镜像层复用为注册表节省存储空间,但正是因为这种特性,复用镜像层比其他镜像层有更大的概率被拉取,从而形成热点镜像层。假设预取策略是按照镜像层被复用的概率降序排序,每次将较高复用率的镜像层预取回缓存中,这种方法会存在明显的缺点:
(1)由于每个镜像层在缓存队列中的存活期是均等的,高复用率的镜像层被频繁预取并放置于缓存队列的前端,使其获得比其他镜像层更久的存活期,较低复用率的镜像层很容易被替换掉,从而造成缓存污染。
(2)虽然通过保留较底部的镜像层来保证一定的命中率,但预取回的镜像层并没有和引起预取操作的未命中镜像层产生联系,且没有将复用率低的镜像层有效转化为有效命中,策略有较大的提升空间。
LCPA 策略的关联度模型克服了上述缺陷,用关联性将镜像层连接起来,避免高复用率的镜像层使注册表丢失了其他请求命中,同时达到精准预取的目的,在2.4 节将详细描述。
2.3 拉取请求处理模块
本模块负责处理用户拉取镜像层的请求,并设置以第二次未命中缓存的请求为预取策略触发点。在传统Docker 架构中,用户的一次拉取操作需要遍历的所有组件,包括代理服务器,请求流程如下:
(1)Docker引擎中守护进程接收到用户的拉取命令后,向注册表发出Get/v2/
(2)守护进程通过对layers 字段校验,已经存储于本地的镜像层不做改动,对于需要拉取的缺失镜像层,守护进程发出Head 请求方法查询注册表后端存储中是否有该镜像层。
(3)通过Get 请求方法从注册表服务器获得重定向url,通过新url 在后端存储中取回镜像层,在本地用sha256 算法进行校验,以确保镜像层完整性。
图5 中请求的多次跳跃很大程度决定了延迟的下限,特别当后端存储服务器处于高负载时,性能下降会极大地影响拉取镜像的效率。LCPA 策略将一部分镜像存入注册表内存中,合理利用注册表的空闲资源以减轻后端存储服务器的负载。同时,拉取请求处理模块判断请求命中注册表缓存并返回镜像层,相比传统的请求流程减少了一半的请求跳跃次数,极大减少了高延迟。
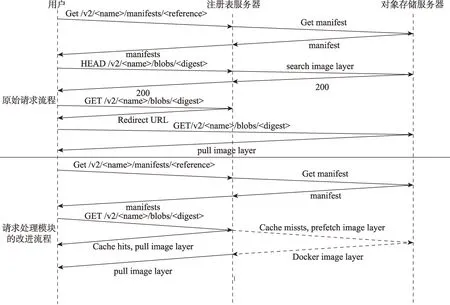
Fig.5 An example of http requests sequence of pulling an image图5 拉取镜像的http 请求流程
为了保证LCPA 策略的性能,需要在拉取请求处理模块中设置合理的预取触发点。过去的研究中一般设置为整个流程的首要操作,在此场景下为拉取元数据文件的请求,但这种触发点有两个缺陷:
(1)用户需要先从注册表中取回元数据文件到本地校验,再发送缺失镜像层的拉取请求。由于元数据文件只保存镜像的信息,注册表无法从拉取元数据文件的请求中感知用户本地的存储状态,因此这种预取触发点会导致预取回的镜像层与后续请求所需的镜像层偏差较大,造成网络资源浪费的同时,降低了缓存命中率。
(2)通过对注册表接收到的拉取请求进行分析,如图6 所示,大于50%的拉取请求是针对镜像层,但位于syd、fra 和lon 三地的注册表接收到大于55%的请求是拉取元数据文件,数量远远大于拉取镜像的请求,这表明部分用户因为网络拥塞或中断操作,向注册表重复发送了针对镜像的拉取请求。在这种元数据文件和镜像层关联割裂的场景下,即使Docker客户端只需一份元数据文件即可校验确定所需镜像层,但冗余触发的预取操作会导致资源浪费。

Fig.6 Distribution of pulling requests in registry of different geographic locations图6 不同地理位置的注册表中拉取请求分布
为了克服上述问题,本模块以第二次未命中的镜像层拉取请求为预取触发点。首先,以镜像层拉取请求为依据解决了缺点2,同时让注册表服务器感知到用户端缺失镜像层的状态。其次,注册表服务器第一次接收到某个镜像仓库内的未命中请求时,没有前驱请求可以建立关联,无法准确判断是否还有后续请求以及与其他镜像层的相关性。最终,结合接收的第二个未命中请求,注册表通过关联度模型得出关联镜像层集合并从后端存储中预先取回,使得未来接收的请求能更多地命中缓存以弥补损失的命中率,提高注册表性能。
2.4 关联镜像层预取模块
预取操作包含关联镜像层的计算和拉取,核心关键在于如何计算出用户未来最可能拉取的镜像层。过多的预取镜像层可能会造成网络拥塞且浪费网络流量,淘汰缓存中有效的镜像层,而仅仅拉取较少关联镜像层又不能达到较好的预取性能,同时浪费了注册表的计算资源。为了实现提升LCPA 效果,本模块利用镜像层局部性建立关联模型,下面从两部分介绍:(1)关联规则,划分镜像层之间的关系;(2)关联模型,计算相关镜像层,同时校验缓存得出镜像层预取集合。
2.4.1 关联规则
首先,给出关联规则的相关基本概念。
定义1镜像L是其镜像层组成的集合,即:
Li={l1,l2,l3,…},i=1,2,…,n
镜像仓库R存放着同类型版本的所有镜像,即:
Rj={L1,L2,L3,…},j=1,2,…,n
定义2对于同属一个镜像仓库R1的镜像L1和L2,即L1⊂R1,L2⊂R1,当L1⋂L2={l1,l2,l3,…}时,l1,l2,l3等为共享镜像层,则{l1,l2,l3,…}为L1和L2的共享镜像层集合。对于仓库R1中的L3镜像,当l3∈L3,l3∉L1⋃L2时,则l3是L3的专用镜像层。
定义3一个预取窗口包含了未命中的拉取请求的生命周期,即:
PWk={p1,p2,p3,…},k=1,2,…,n
注册表中每个镜像仓库都是应用程序或系统镜像的不同版本所构成的镜像组,由于注册表接收两个连续的拉取请求可能针对不同镜像仓库,设置一个预取窗口不能有效分析被拉取镜像层之间的关联性。因此,为每一个镜像仓库设置独立预取窗口PWk,k=1,2,…,n,将拉取请求处理模块发送来的未命中请求保存在相应的预取窗口里,以便记录和查询请求之间对应的镜像层是否产生关联。
定义4针对镜像层之间的关系分为不同程度:强关联、弱关联和无关联。前提条件有预取窗口PW1={p1,p2,p3,…},其中任意两个未命中的请求对应的镜像层集合为Lx={l1,l2},则描述如下:
(1)若Lx⊂Li,对于∀Lj(i≠j),都有Lx-Lj=∅,则Lx中的镜像层l1和镜像层l2是强关联,例如图7中镜像仓库1 的2 号镜像与6 号镜像,Lx的强关联镜像层集合为Li-(Li⋃Lj)-Lx。
(2)若Lx⊂Li,对于∀Lj(i≠j),都有Lx-Lj≠∅,则Lx中的镜像层l1和镜像层l2是弱关联,例如图7中镜像仓库2 的1 号镜像与5 号镜像,Lx的弱关联镜像层集合为(Li⋂Lj)-Lx。
(3)对于∀Li,都有Lx∉Li,即Lx中的两个镜像层分别为不同镜像的专用镜像层,则镜像层l1和镜像层l2是无关联,例如图7 中镜像仓库2 的15 号镜像与10 号镜像。

Fig.7 Storage structure of repository in registry图7 镜像仓库在注册表中的存储结构
2.4.2 关联模型
每一个镜像仓库的预取窗口按照时间顺序保存若干历史请求,新进请求会与前驱请求对应的镜像层产生不同程度的关联。通过将镜像结构提取模块收集的镜像结构信息代入关联规则判断关联程度,针对不同关联程度,关联模型分别设置计算方法得到相关镜像层集合,分析如下:
(1)新请求与历史请求对应的镜像层是强关联时,表明后续请求序列都倾向于拉取其周边的镜像层,通过关联规则可计算出新请求对应镜像层所产生的强关联镜像层集合。
(2)新请求与历史请求对应的镜像层是弱关联时,由关联规则可知,新请求对应镜像层被多个镜像复用,无法根据此请求判断目标镜像,将其弱关联镜像层全部拉取可能会造成资源浪费,同时加重网络延迟。本文考虑镜像的其他属性来精准计算关联程度C,如式(1)所示:其中,d表示新请求和历史请求对应镜像层的间隔镜像层数量;Plast表示历史请求对应镜像层的流行度;Pnow表示新请求对应镜像层的流行度;Tlast表示历史请求到达的时间戳;Tnow表示新请求到达的时间戳。
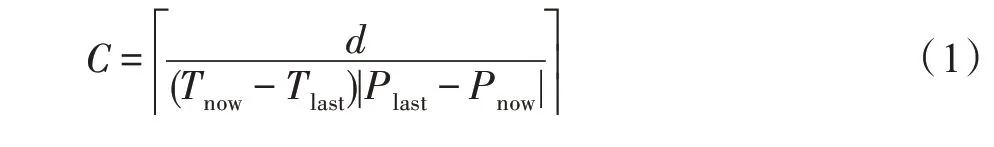
通过镜像结构提取模块收集的镜像层信息代入公式计算关联程度C,在镜像仓库的结构中,选取从新请求对应镜像层至历史请求对应镜像层方向的C个镜像层作为弱关联镜像层集合。
(3)新请求与历史请求对应的镜像层无关联时,即新请求无法对要预取的镜像层提供信息,则清除该预取窗口中所有历史请求,仅保留最新请求,为后继请求提供关联性参考。
由于注册表服务器内存中缓存了镜像层,从关联模型中得到的相关镜像层集合并非全部拉取,需要查询缓存数据,得出缓存缺失镜像层的预取集合,从存储后端取回注册表服务器。
LCPA 策略的算法如算法1 所示。

3 实验评估与分析
为了进一步验证缓存预取策略LCPA 的有效性,在仿真模拟器上实现了LRU、LIRS、GDFS 和LPA 四种算法,由于预取策略是对缓存策略的扩展,LCPA和LPA 均以LRU 为缓存替换算法。实验采用真实的注册表工作负载trace 数据集进行测试,分别在不同缓存规模下测试预取策略相对缓存策略的提升的缓存命中率和延迟节省率,以及相比其他预取算法提高的效果。
3.1 实验环境及说明
本文实验采用Intel Core i7-6700 的CPU,24 GB DDR3 RAM,和7 200 r/min 500 GB SATA 硬盘,并安装操作系统CentOS 7.3,Linux 内核版本是3.10.0,Docker版本是1.12.0,对应的API版本为1.27,采用的编译语言python 版本为3.5.2。实验环境具体参数如表1 所示。

Table 1 Parameters of experiment environment表1 实验环境参数
3.2 数据集分析
使用SNIA trace data files 来测试LCPA 的性能,SNIA trace data files 是从IBM 云注册表中收集的真实工作负载数据集,其中包括从2017 年6 月20 日到2017 年2 月9 日间,5 个不同地理位置的注册表(另外两个是IBM 内部使用的注册表)处理的总计超过3 800 万个请求,总数量传输超过181.3 TB,由于原始日志中部分信息不能公开,经过删除冗余字段并匿名处理后,数据集总大小为22.4 GB。数据集由http请求组成,每一个请求都有固定的属性,包括处理请求的注册表服务器的主机号、请求的响应时间、HTTP 请求方式、用户IP 地址、请求的URL、用户使用的Docker 版本、请求状态、请求数据大小、请求id、请求时间戳。由于本文提出的预取策略仅涉及元数据文件和镜像层的操作,对数据集处理后仅保留数据的拉取和上传请求,表2 展示本实验采用的真实负载的特性。
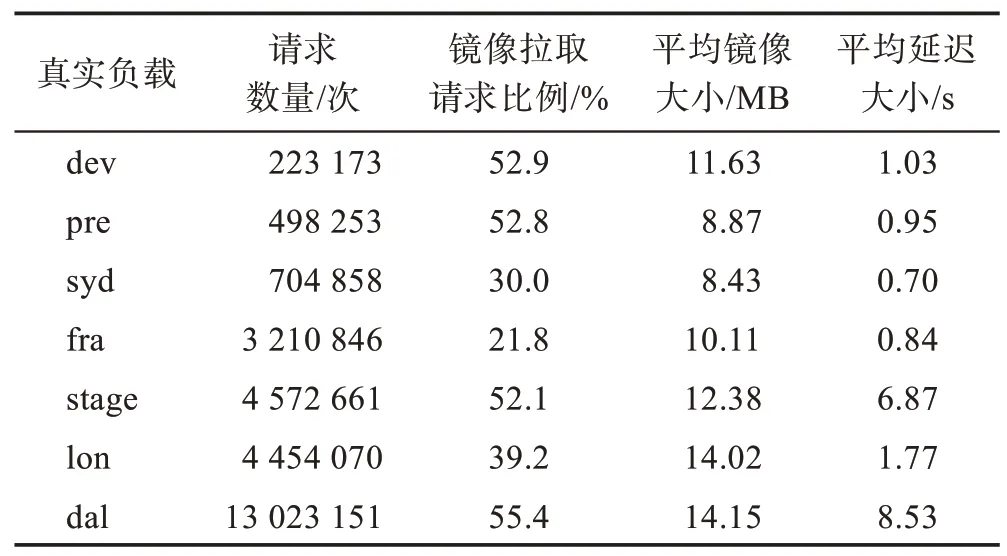
Table 2 Characteristics of real workload used in experiments表2 本实验采用的真实负载的特性
3.3 实验结果分析
为了更好地评估算法的性能,本研究使用请求命中率和延迟节省率两个指标。
定义5请求命中率(hit ratio)是指在注册表服务器缓存中命中的镜像层拉取请求占镜像层拉取请求总数的百分比。
定义6延迟节省率(latency saving ratio)。从用户发出拉取镜像请求到所有镜像被下载到本地的过程中,设Tregistry为命中注册表服务器缓存并拉取镜像的延迟,Tobject为根据重定向url 到对象存储服务器拉取镜像的延迟,则计算延迟节省率如式(2)所示:
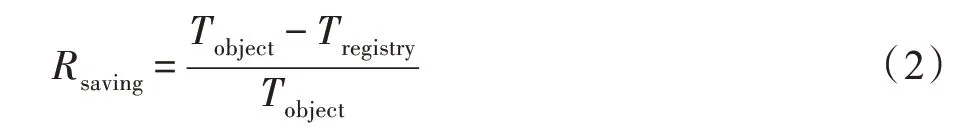
3.3.1 数据集命中率测试分析

Fig.8 Hit ratio for LRU,LIRS,GDFS and LCPA图8 LRU、LIRS、GDFS 和LCPA 算法的请求命中率
图8 给出的是LCPA 策略与3 种缓存算法LRU、LIRS 和GDFS 在不同数据集下实现的请求命中率,设置的缓存范围从50 MB 到12 GB,灵活地展示算法在注册表资源变动时的性能。
实验的测试结果表明:首先,所有算法在不同的注册表trace 数据集上都受到请求顺序的影响,例如GDFS 算法在dev 数据集上取得了较高的命中率,但在dal 和lon 数据集中却非常低。从横向上看,随着缓存容量的增大,每种算法的命中率都有不同程度的提升,其中LRU 和LIRS 在dev 和pre 数据集的测试中从极低的命中率快速提升,这是因为两个trace 是IBM 公司内部使用的注册表数据集,镜像种类不够丰富,注册表服务器能缓存大部分热点镜像。从纵向上看,LRU 算法由于自身的各种缺陷,平均命中率是最低的,但是在部分数据集中能与LIRS 算法的命中率相似。GDFS 综合考虑请求镜像层的大小、获取成本等属性,在请求命中率这个指标中优于LRU 和LIRS。最后,本文提出的LCPA 算法在不同的trace数据集中的命中率均处于领先位置,总体表现优于其他缓存算法,能够在较小缓存空间中根据关联规则预得到很好的命中率,算法性能平均提升了12%~29%不等。
3.3.2 数据集延迟节省率测试分析

Fig.9 Latency saving ratio for LRU,LIRS,GDFS and LCPA图9 LRU、LIRS、GDFS 和LCPA 算法的延迟节省率
图9 给出了LRU、LIRS、GDFS 和LCPA 算法的延迟节省率的实验结果。从结果来看,LCPA 算法均比其他算法要节省更多的延迟。结合请求命中率来分析,LCPA 在stage 和dal数据集中测试时,当缓存容量较小,40%左右的请求命中率获取了不到8%节省延迟率,原因是这两个数据集中存在的较小热点镜像层在真实拉取时均没有产生较高的延迟,同时在缓存中的生命周期较短,没有较大节省延迟的空间,随着缓存大小的增加,延迟节省率会迅速增加。综合所有数据集结果,当注册表服务器资源较少时,四种算法为用户节省的延迟相差无几,但LCPA 总体表现优于其他算法,延迟节省率平均提升21.1%~49.4%。
3.3.3 与LPA 预取算法比较分析
LPA 算法[8]的基本思想是将注册表服务器接收到的PUT 请求信息记录在查找表中,包含请求中的镜像层信息、请求到达时间以及客户端地址,当注册表在设置的时间阈值内从客户端收到GET manifest请求时,检查查找表中是否包含manifest 指定的镜像层,如果是非上传主机发出的请求命中,则从后端对象存储中实施预取。
为了验证两种预取算法的性能,实验选取了7 个数据中心的数据集来测试两种算法的请求命中情况,由于LPA 算法中有两个时间参数控制镜像在注册表中的缓存时间,使得缓存中镜像总大小处于变化的数值,于是对参数进行调整,尽量使得注册表服务器中的缓存处于饱和状态,结果如图10 所示。
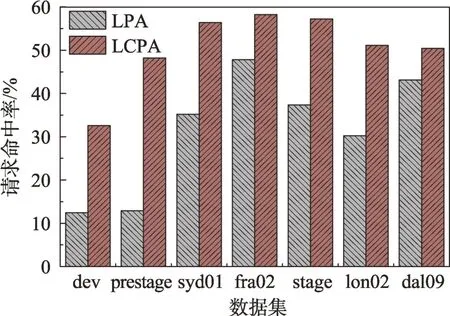
Fig.10 Hit ratio for LCPA and LPA图10 LCPA 与LPA 算法的请求命中率
从图10 中可以看出,LPA 算法在dev 和prestage数据集中表现出极低命中率,这是因为这两个数据集来自IBM 内部开发和测试所使用的注册表,注册表中的镜像分布较为平均,没有流行度非常高的镜像,所以被预取回注册表的镜像层在下一次拉取该镜像层的请求到来时,其会在规定大小的缓存中被快速替换导致未命中,而LCPA 算法在这两个数据集中的高命中率表明了通过关联性去预判未来可能被请求命中的镜像层更加精确。LCPA 的请求命中率总是优于LPA,LCPA 的平均命中率是60.3%,最高达72.8%,比LPA 的平均命中率提升25.6%。
图11 的实验结果表明,与LPA 算法相比,LCPA在7 个trace 数据集中的延迟优化效果更好,平均延迟节省率提高了43.3%。由表2 可知stage 和dal 数据集中镜像的平均拉取延迟较大,但相比其他数据集,LCPA 策略的优化效果不明显,这是因为LCPA 不缓存某些体积巨大的镜像,则损失了部分可以节约的拉取延迟。pre 和syd 数据集中镜像的平均镜像大小和平均拉取延迟均较小,即使LPA 算法的命中率与LCPA 较大,但延迟节省率的差距有着明显的缩小。

Fig.11 Latency saving ratio for LCPA and LPA图11 LCPA 与LPA 算法的延迟节省率
两个实验结果不仅体现了LCPA 算法预测的稳定性,同时也体现了现有算法预测请求镜像的不够精准以及LCPA 策略在Docker注册表中的研究意义,突出了LCPA 策略的创新价值。
4 结束语
Docker 作为云计算领域中的容器管理工具,具有很强的市场前景。本文针对用户启动容器延迟逐渐增加的问题,对Docker 生态中的注册表服务器进行改进,设计基于镜像关联的Docker 注册表缓存预取策略LCPA。仿真实验结果表明,与LRU、LIRS、GDFS 等缓存算法相比,LCPA 通过主动式预取有效提升了注册表性能,在不同数据集中均实现了较好的请求命中率。与现有的预取策略LPA 相比,克服了LPA 算法寻找关联性的局限性,并通过关联模型计算相关镜像层集合进行预取,从Docker 注册表服务器返回镜像至客户端节省了大量延迟,从而加快了容器启动效率。
猜你喜欢
体育科技文献通报(2022年5期)2022-06-05
当代党员(2020年20期)2020-11-06
小康(2018年23期)2018-08-23
电脑爱好者(2017年24期)2017-12-27
电脑爱好者(2016年21期)2016-12-16
小康(2015年4期)2015-03-31
学生天地·初中(2014年4期)2014-07-28
读者(2013年5期)2013-12-25
计算机应用文摘·触控(2009年19期)2009-09-27
移动一族(2009年3期)2009-05-12
