
基于三态信号的改进游程编码压缩方法
2021-02-05 03:03任福继赵沪隐
计算机工程 2021年2期
陈 田,周 洋,任福继,3,安 鑫,赵沪隐
(1.合肥工业大学计算机与信息学院,合肥 230009;2.合肥工业大学情感计算与先进智能机器安徽省重点实验室,合肥 230009;3.德岛大学工学部,日本德岛770-8506)
0 概述
随着集成电路技术的发展,晶体管的特征尺寸不断缩小,芯片集成度与频率日益提高,使得集成电路芯片设计对数据测试的要求越来越严格,并对自动测试设备(Automatic Test Equipment,ATE)的I/O通道数及ATE数据传输率提出了更高要求[1]。然而,由于大量的测试数据增加了测试时间和功耗,因此测试数据压缩技术[2-3]应运而生。
测试数据压缩方法主要分为基于线性解压[4]、广播扫描[5]和编码[6]的压缩方法3类。基于线性解压的测试数据压缩方法是先将测试数据压缩成较小的种子集,测试时将种子集传输到线性解压器中扩展成测试向量进行测试。该方法压缩率较高,但只有当其原始测试集中包含很少的确定位时,才能生成合适的种子。基于广播扫描的测试数据压缩方法通过一个共同的输出结构将相同的测试数据扇出到不同的扫描链中[7]。该方法较简单,但是每一次数据扇出时都需要单独连线,并要求原始测试数据具有较高的相容性。基于编码的测试数据压缩方法利用压缩算法对原始测试数据集进行高度压缩,将压缩后相对较小的测试集存入ATE,测试时利用芯片上的解压电路进行无损解压得到测试数据。该方法具有良好的适应性,但压缩率较低。近年来,研究人员陆续提出基于Golomb编码[8]、FDR编码[9]、EFDR编码[10]、FRPRL编码[11]等的测试数据压缩方法。传统基于编码的测试数据压缩方法使用二值逻辑“0”和“1”进行编码,文献[12]指出ATE可支持高阻态(Hi-Z)信号的传输,“0”、“1”和“Hi-Z”被称为三态信号,因此文献[13]提出基于字典的三态信号编码压缩方案。本文受此启发,提出一种基于三态信号的改进游程编码压缩方法,先对测试集进行预处理,降低测试集中确定位的比例,再根据游程长度进行变长分段编码压缩,并使用三态信号编码标志位。
1 基于三态信号的游程编码压缩方法
为减少测试数据量,本文提出一种基于三态信号的游程编码压缩方法,整体流程如图1所示。首先对原始测试集进行预处理;其次填充测试集的无关位;然后利用基于三态信号的改进游程编码压缩方法对填充后的测试集进行编码压缩,并将编码压缩后的测试集存入ATE;最后通过设计解压电路对ATE中存储的压缩数据进行无损解压。
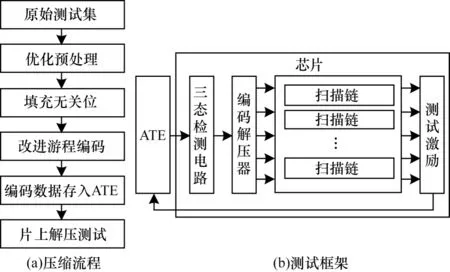
图1 基于三态信号的游程编码压缩流程Fig.1 Procedure of run length coding compression based on tri-state signal
1.1 三态信号检测
本文方法的研究重点为通过片上解压电路检测三态信号并将三态信号转化为二值逻辑信号用于数据测试。文献[14]提出一种三态信号检测电路,如图2所示,其中VDD为电源工作电压。该电路由6个晶体管组成,硬件结构简单、开销小且操作便捷。
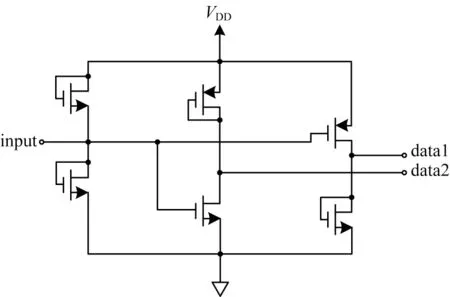
图2 三态信号检测电路Fig.2 Tri-state signal detection circuit
虽然ATE能存储三态信号,但由于被测电路不能识别三态信号,因此本文在ATE输出后增加了一个三态信号识别电路。该三态信号识别电路的真值表如表1中“转换前”部分所示,可以看出:data2为“1”时,输入信号是“0”;data2为“0”时,输入信号是“1”或者“Hi-Z”。为了能仅读取1位数据就知道该输入信号为高阻态,本文在解压结构和有限状态机(Finite State Machine,FSM)之间增加了一个转换电路,使得data2’为“0”时,输入信号一定为“Hi-Z”,真值表如表1中“转换后”部分所示。在本文方法中,将含有三态信号的压缩向量从ATE输出到片上三态信号检测电路中,并将三态信号转化成二值信号,同时通过解码器生成与原始测试向量相容的测试模式,最终将解码后的测试向量输入扫描链中进行测试。

表1 三态信号解压输出转换前后的真值表Table 1 True value table of tri-state signal decompression output before and after conversion
1.2 测试数据预处理
原始测试集包含“0”、“1”和“X”,其中:“0”和“1”为确定位;“X”对测试结果不产生影响,被称为无关位。在将其输入扫描链时,无关位可根据需要设置成“0”或“1”。根据测试向量中确定位的不同,两个测试向量之间的关系分为相容、反相相容和不相容3种。在两个测试向量中:如果对应位的位置都为“0”(“1”),或者一个为“0”(“1”),另一个为“X”,那么称这两个向量相容;如果对应位的位置一个为“0”(“1”),另一个为“1”(“0”)或者“X”,那么称这两个向量反相相容;如果两个测试向量中既存在相容又存在反相相容,那么称这两个向量不相容。
为降低测试集中确定位的比例,本文使用部分输入精简技术[15]对原始数据集进行预处理。部分输入精简技术将相容(反相相容)的测试向量合并成一个测试向量,测试时进行一个扇出处理,并保留全是无关位的测试向量,但不作任何处理,其主要原因为将测试集相容或者反相相容的测试向量合并成一个向量可减少确定位,从而降低测试集中确定位的比例。
1.3 游程编码压缩方法
1.3.1 游程选取
若字符串中确定位“1”后面有多个“0”,或者确定位“0”后面有多个“1”,则称具有该特性的字符串为游程,可抽象地表示为0n1或1n0,其中,0n表示n个“0”,1n表示n个“1”,n为该游程长度,即两个相同确定位之间的距离。为更直观地展示确定位“0”和“1”在原始测试集中的分布,本文对ISCAS-89基准电路中的s5378电路测试集绘制更直观的“0”、“1”和“X”分布图,如图3所示,测试集中的“0”用黑色表示,“1”用白色表示,无关位“X”用灰色表示。

图3 s5378原始测试数据位置分布Fig.3 Position distribution of the original test data about s5378
从图3可以看出,两个相同的确定位不是集中在一起,就是两两相隔很远,而且很多确定位之间的距离相同。利用该特性,本文设计一种基于确定位距离(游程长度)的编码压缩方法。由于测试集中确定位一般非常稀少,且其在测试集中所占比例为1%~5%[16],如果仅统计在测试集中所占比例小于5%的确定位的游程长度,则将减少存储信息量,而如果完整存储“0”和“1”的游程长度,则将浪费很多存储空间,因此为进一步减少存储位数,本文只存储“0”或“1”一种确定位的游程长度。一般的游程编码方法是对固定的一种确定位或者同时对两种确定位的游程进行编码,但会在一定程度上增加游程长度的种类数,因此本文对需要编码的确定位采取灵活的选取方式,并将该确定位称为参考位,具体定义如下:
定义1令A=(S0,S2,…,Sn-1)为某一测试集,其中Sn表示测试向量中的第n个测试向量,集合T(A)为测试集A中所有确定位的集合。若T(A)中“1”的数量小于“0”,则令参考位为“1”;若T(A)中“0”的数量小于“1”,则令参考位为“0”。
对于测试集中的无关位,本文进行与参考位相反的确定位填充。经统计,s5378电路的测试集中“0”有2 968位,“1”有3 537位,因此,s5378的参考位是“0”,同时将所有的无关位填充为非参考位“1”。最终s5378测试集只需要存储2 968个“0”的游程长度,占整个测试集的12.49%,从而明显减少了所需存储的信息量。图4为对s5378测试集中无关位填充“1”后的分布图,可以直观看出“0”所占的比例很小。

图4 s5378填充测试数据位置分布Fig.4 Position distribution of the filling test data about s5378
1.3.2 游程编码表的编码规则
传统游程编码表是根据游程长度依次进行编码,游程长度越长,排序越靠后,码字也越长。然而,编码时虽然有些游程长度并不存在,但也会在编码表中占用相应的码字,这就可能会增加其后面的码字长度。因此,传统游程编码方式未能充分利用短码字的优势,而且不能有效利用所有的二进制集合。
图5是s5378测试集中参考位“0”的游程长度出现频率分布图,横坐标为“0”的游程长度,纵坐标为该游程长度的出现次数。可以看出,游程长度的出现次数均集中于1~10,其中游程长度为1出现了1 033次,游程长度为2出现了473次。根据游程长度的出现频率分布,本文重新设计了三态信号游程编码表。新编码表中的码字为不同长度的二进制全排列,长度从0开始,直到能表示完游程长度的所有种类数时为止。因为码字长度不统一,所以本文使用三态信号作为标志位,每个码字都以“Hi-Z”作为后缀,为方便后文的叙述,将“Hi-Z”简记为“Z”,最终码字依次为{Z,0Z,1Z,00Z,01Z,…}。根据以上规则可得出新的s5378编码表,如表2所示。

图5 s5378游程长度的出现频率分布Fig.5 Occurrence frequency distribution of the run length about s5378

表2 s5378编码表Table 2 Coding table about s5378
传统游程编码方式根据游程长度依次对应相应码字,而本文为充分利用码字,分别使出现频率高和低的游程长度对应采用短和长的码字,并对不曾出现过的游程长度不设置码字,从而保证高频设短码、低频设长码、零频不设码的原则。
通过观察s5378编码表发现,游程长度从36到140都只出现了1次,其在编码过程中出现次数少,编码字段长,利用率低,占用空间多,对于编码压缩非常不利。为进一步提高编码表中码字的利用率,本文为整个测试向量设计一种变长分段压缩方法。变长分段压缩就是先从整个测试向量中划分出一个给定长度的测试向量,并记录该子向量中所有参考位的游程长度。如果测试向量最后的测试数据不是参考位,例如对于从测试集中划分出的子向量S={101XXX},其最后一位为无关位,该无关位将被填充为非参考位。由于本文只对参考位进行编码,因此最后的3位无关位无法被编码。如果最后一位无法被编码,那么就将离该位最近的参考位的下一位作为起始位,重新设定给定长度的向量为子向量并进行重新编码。如果子向量全是非参考位,即最近的参考位不存在,那么设定该子向量游程长度为给定长度。在整个测试集编码完成后,将每个子向量的游程长度合并成一个编码表,根据所有游程长度的出现频率设置编码表,并对该编码表进行存储。
为找出变长分段压缩的最优段长,本文从段长为1一直遍历到测试集长度为止,从中找出最优的子向量段长进行编码压缩。由于寻找最优段长是测试前的准备工作,因此不会增加测试时间。图6为变长分段编码压缩流程。经过测试可知,s5378的最优段长为43,此时字典位数为283,相比不进行变长分段压缩的字典位数(940)约减少了70%,而且游程长度也更集中地出现在多个固定游程长度上,使得压缩率由整体压缩的66.629%提升到68.085%。

图6 变长分段编码压缩流程Fig.6 Procedure of variable length segment coding compression
1.3.3 编码流程
本文首先统计出测试集中游程长度出现次数较少的确定位,记为参考位,进行非参考位填充;然后从段长为1开始进行变长分段编码,直到段长为测试集长度时停止,找出其中的最优段长,并统计在该最优段长下进行变长分段编码中所有参考位的游程长度出现次数,根据游程长度出现频率高低进行排序并生成编码表;最后根据编码表进行编码。
下文以测试集S为例进行说明,如图7(a)所示。假设经过遍历后测试集中最优段长为8,以段长为8进行编码,整个编码过程中将不涉及变长分段的编码过程。因为测试集中“0”的个数为8,“1”的个数为4,所以参考位为“1”,首先进行非参考位填充,将无关位“X”填充为非参考位“0”,然后从该测试集中划分出一个段长为8的子测试向量S0。该测试集被分成新的子向量S0和剩下的测试集S,如图7(b)所示。该子向量中第1个、第2个、第3个参考位的游程长度依次为0、2、1。编码到第1个子测试向量的最后一位“0”时,因为该位不是参考位,所以退到最近的一个参考位的下一个非参考位,即S0中倒数第2个“0”,然后以该位作为起始位重新划分段长为8的下一个子向量S1,如图7(c)所示。因为该子向量是8个“0”,所以第4个“1”的游程长度为8,然后将剩下的测试集划分为第3个子测试向量S2,如图7(d)所示,因此第5个、第6个“1”的游程长度为0、6。

图7 编码示例Fig.7 Coding example
统计出这些游程长度的出现次数,并对游程长度按照出现频率高低设计编码表,最终的示例编码表如表3所示。编码后的结果为{Z0Z00Z1ZZ01Z},压缩后的测试数据共有12位。为便于对比,本文使用游程编码重新对该测试集进行一次压缩,因为该测试集中有较多的短游程且没有连续的“1”游程,所以本文选FDR码进行编码。该测试集根据“1”游程可划分为001、021、011、081、061,所以按照FDR编码表编码为00100001110010110000,共20位。可以看出,本文方法的压缩效果优于FDR码,主要原因为本文不仅设计了根据游程长度的出现频率来编码的三态码字,而且采用变长分段压缩编码方法使游程长度进一步集中于出现频率高的码字。

表3 示例编码表Table 3 Example coding table
2 解压结构
图8为本文方法的解压结构,压缩过的测试集存储在ATE中,其中,ATE_clk、SCK为时钟信号,SE为使能信号,SI为输入数据。测试时数据由ATE通过测试数据输入(Test Data Input,TDI)端口输出到解压结构进行解压,然后将解压后的数据(即原始数据)输出到扫描链上进行扫描测试。

图8 解压结构Fig.8 Decompression structure
解压过程主要分成以下两个步骤:
1)三态信号转换为二值信号。ATE将包含高阻态信号的压缩后的测试数据输出到三态检测电路中,三态检测电路将“Hi-Z”进行转换输出,输出信号经过转换电路转换成data1’、data2’并将其输入到FSM中。
2)解压数据并将其输入到扫描链中进行测试。若FSM收到的data2’信号为“1”,则表示收到的是“0”或者“1”信号,说明正在读入游程长度的值,直接将该信号输入到移位寄存器中;若FSM收到的data2’信号为“0”,则表示收到的是“Hi-Z”信号,说明游程长度已经读取完毕,此时移位寄存器将游程长度输入到编码表存储器中,找到编码表中对应的游程长度并输出到计数器,由计数器将“0”或者“1”信号输入到扫描链中进行测试。
3 实验结果与分析
为验证本文方法的有效性,采用Mintest集[17]对ISCAS-89基准电路中的6个电路进行实验。表4为实验电路的基本信息。本文方法的测试压缩算法程序由Java实现,并在Core i7 3.4 GHz CPU、8 GB内存的PC机上进行验证。

表4 实验电路信息Table 4 Experimental circuit information
压缩率计算公式如式(1)所示。本文方法对Mintest集上压缩结果如表5所示,其中,前4列为测试集经过压缩处理后的基本信息,第5列为使用本文方法的测试数据压缩率。表6为本文方法与Golomb方法[8]、FDR方法[9]、EFDR方法[10]、FRPRL方法[11]、文献[13]方法、文献[18]方法、9C方法[19]、BM方法[20]和文献[21]方法的测试数据压缩率对比,其中,本文方法与文献[13]方法均使用三态信号对测试集进行压缩,其余方法均使用二值信号对测试集进行压缩。可以看出,本文方法的测试数据压缩率要优于其他方法,主要原因为其对测试集进行预处理能有效降低测试集中确定位的比例,为后续压缩提供了良好的基础条件,并且压缩时使用三态信号作为标志位,将编码字段由定长变为变长,而且根据游程长度的出现频率进行编码,能更充分地利用编码表。

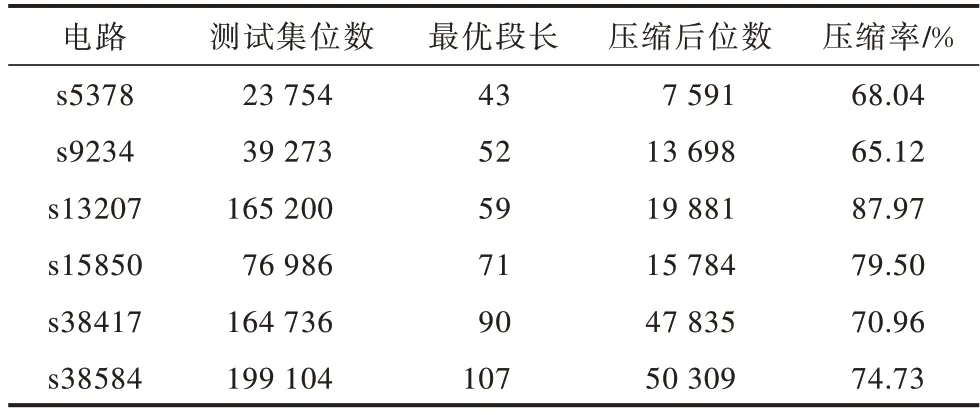
表5 本文方法对Mintest集的压缩结果Table 5 Compression results of the Mintest set by the proposed method

表6 10种方法的测试数据压缩率比较Table 6 Comparison of test data compression rate of ten methods %
本文使用Synopsys公司的DC工具对解压结构及其对应的基准电路进行综合分析,得到硬件开销的计算公式如式(2)所示:

表7为本文方法与Golomb方法[8]、FDR方法[9]、EFDR方法[10]、文献[13]方法、9C方法[19]和BM方法[20]在解压结构的硬件开销上的对比。由于本文方法的解压结构主要是增加了1个三态信号检测电路以及1个编码表存储器,但三态信号检测电路仅由6个晶体管组成,硬件开销较少,因此其硬件开销主要集中在编码表的存储器上。与同样需要开辟额外存储空间的9C和BM方法及同样基于三态信号的文献[13]方法相比,本文方法的硬件开销更小。
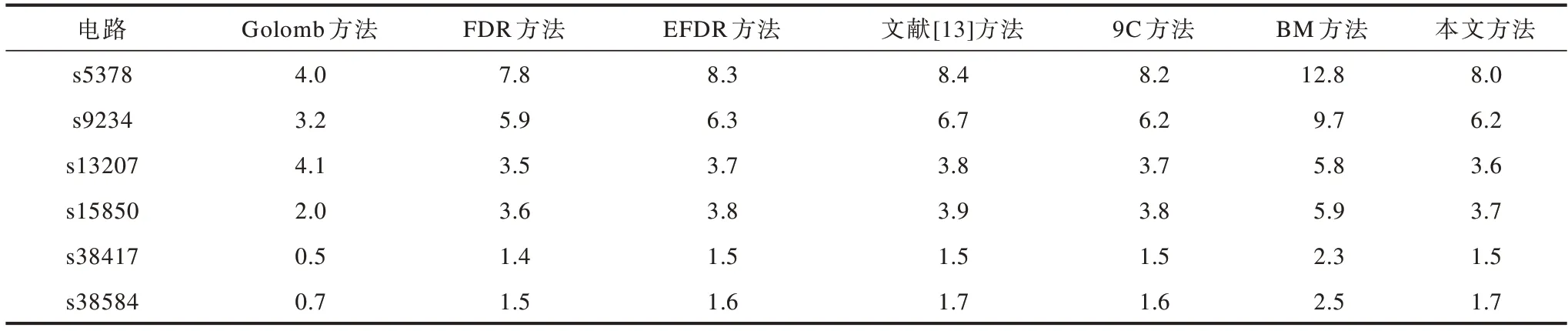
表7 7种方法的硬件开销比较Table 7 Comparison of hardware overhead of seven methods
4 结束语
本文提出一种基于三态信号的改进游程编码压缩方法。该方法对原始测试集进行部分输入精简处理,降低了测试集中确定位的比例并减少参考位的数量,且对经过预处理的测试集根据游程长度进行变长分段处理,从而找出最优段长,同时按照游程长度的出现频率对最优段长下的参考位设置编码表进行编码压缩,提高了编码表中码字的利用率。实验结果表明,本文方法相比同类压缩方法具有更高的压缩率,且硬件开销没有明显增加。但由于本文方法仅针对二维芯片上的测试数据进行压缩处理,因此下一步将在三维芯片的基础上研究测试芯核的排布和测试数据的调度问题。
猜你喜欢
文体用品与科技(2021年7期)2021-04-09
安庆师范大学学报(自然科学版)(2019年2期)2019-08-26
数学物理学报(2019年1期)2019-03-21
扬子江诗刊(2018年1期)2018-11-13
舰船电子对抗(2018年3期)2018-08-28
扬子江(2018年1期)2018-01-26
新课程·上旬(2016年7期)2016-11-02
中国卫生统计(2016年2期)2016-06-24
中老年健康(2016年5期)2016-06-13
商品与质量·消费视点(2014年11期)2014-10-21
