
一种面向路网时空约束的轨迹隐私保护技术
2021-02-14 02:14刘向宇许世惠琳夏秀峰宗传玉李佳佳
沈阳航空航天大学学报 2021年6期
刘向宇,许世惠琳,夏秀峰,宗传玉,朱 睿,李佳佳
(沈阳航空航天大学 计算机学院,沈阳 110136)
近年来,定位技术和移动感知技术的快速发展产生了大量的移动轨迹数据。例如,车辆行驶GPS数据或导航软件数据形成了用户的轨迹数据。通过对轨迹数据进行发布共享、分析和挖掘,可以得到大量有价值的信息和知识,用于交通路线设计或城市规划等。轨迹共享和分析在给城市建设和用户日常生活带来便利的同时,也给用户的个人隐私带来了巨大的安全隐患。如果对轨迹数据不加限制的直接发布,一旦这些数据被恶意攻击者获取,则攻击者可通过数据挖掘等技术获取到轨迹信息中蕴含的家庭住址、生活习惯或健康状况等用户个人隐私信息,给用户的隐私安全带来严重威胁[1-3]。因此,针对发布轨迹的隐私保护十分必要,其主要目的在于保护发布轨迹中用户个人隐私安全,同时保证发布轨迹集仍具有较高的数据可用性。
图1a所示为用户u轨迹T的信息,其中(li,ti)表示用户于ti时刻在位置li处进行位置签到。图1b显示了轨迹T在路网中的位置。轨迹T为用户u从家出发前往医院的轨迹,对于用户u而言,该轨迹属于其个人隐私。然而,如果数据拥有者在不对其进行任何处理的情况下直接发布,则导致攻击者可轻易获得该敏感轨迹,造成用户的轨迹隐私泄露。


图1 轨迹T的轨迹信息及其假轨迹在路网中的分布情况
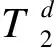
针对上述问题,本文提出一种面向路网时空约束的轨迹隐私保护算法,根据轨迹在路网中的时空特性生成满足路网时空约束、符合用户轨迹模式的假轨迹,从而更好地保护轨迹隐私。
1 相关工作
现有的轨迹隐私保护技术主要分为基于泛化的轨迹隐私保护、基于抑制的轨迹隐私保护和基于假轨迹的轨迹隐私保护3种。泛化法是指将轨迹上的位置点扩展为1个匿名区域使攻击者识别出用户的概率降低;抑制法通过对轨迹数据进行有选择的发布实现对用户敏感轨迹的保护;假轨迹法一般以向真实轨迹中添加虚假轨迹来达到混淆攻击者的目的。
轨迹k-匿名作为基于泛化的轨迹隐私保护的常用方法之一,其主要思想是通过可信的第三方匿名服务器选择k-1条与用户轨迹相似的其他用户轨迹来对用户轨迹进行混淆,保护用户轨迹隐私安全。Zhu等[4]提出一种基于偏好感知的轨迹匿名算法(PTPP),该算法先根据用户轨迹移动模式、用户熟悉度和位置受欢迎程度对用户偏好进行建模,再自适应选择合适的位置与用户原始轨迹上的位置点构建匿名域。Ye等[5]提出一种基于路网的l-多样性算法。算法先通过可信第三方匿名服务器对路网进行区域划分,并构建每个子区域内的通用轨迹数据库,再从轨迹数据库中选择l-1条距用户轨迹最近的其他轨迹构建匿名域。Hwang等[6]提出一种综合r-匿名、k-匿名、s-道路分段的时间混淆算法对用户轨迹隐私进行保护。算法首先构建用户历史轨迹数据集,再由可信第三方匿名服务器从中选择与用户当前轨迹相似的轨迹构建轨迹匿名域,在对轨迹数据进行发布时,打乱发布位置的时间顺序来对攻击者进行混淆。Chiba等[7]发现现有的轨迹匿名方法中有些匿名域内位置发生了变化,导致发布后轨迹集信息损失增大,故提出一种在一定范围内允许位置和时间不匹配的算法以减少位置距离修改,提高发布后轨迹的数据可用性。
轨迹抑制通过删除用户轨迹中敏感或频繁出现的位置信息实现对轨迹数据有选择的发布,防止攻击者通过此类信息对用户轨迹隐私安全造成威胁。Yao等[8]提出基于扰乱的数据隐私保护算法,通过删除轨迹上关键位置序列中的某些移动位置点使轨迹数据满足隐私保护要求。Chen等[9]提出基于局部抑制的轨迹隐私保护方案,有选择地删除用户局部轨迹中的位置点,在保护用户轨迹隐私安全的同时提高发布轨迹的数据可用性。赵婧等[10]提出一种基于轨迹频率抑制的轨迹隐私保护方法来对用户轨迹进行处理,在保护用户轨迹隐私安全的同时提高数据可用性和算法性能。
假轨迹方法指不借助第三方服务器生成与用户原始轨迹相似的假轨迹,并将原始轨迹与假轨迹一起发布来对攻击者进行混淆。假轨迹隐私保护技术具有实现简单、能保留较完整轨迹信息、不需可信第三方服务器等特点,因此在实际研究中应用广泛。假轨迹方法最早由Kido等[11]提出基本思想。LEI等[12]在此基础上提出通过随机法和旋转法生成假轨迹,随机法指随机生成一些位置点,并将它们按时间顺序连接得到与用户原始轨迹相似的假轨迹。旋转法则是以用户原始轨迹为基础,选择轨迹上某些采样位置点为轴点对原始轨迹进行旋转,旋转后得到的轨迹即为生成的假轨迹。林邓伟等[13]提出一种基于用户真实轨迹的虚假轨迹生成方法,主要通过建立用户轨迹的马尔科夫模型,并融入攻击者的背景信息,来抵御攻击者通过背景知识攻击来窃取用户轨迹隐私。Dai等[14]提出一种在路网环境下分段生成假轨迹的轨迹隐私保护算法。该算法通过第三方可信匿名服务器生成假位置,再将生成的假位置与上一时刻真位置连接得到假轨迹段,最后将假轨迹段按时间顺序连接得到假轨迹,算法有效提高了用户轨迹的隐私保护程度。LEI等[15]提出一种基于时空关联性的假轨迹隐私保护方案。该方案从轨迹整体方向、轨迹间相似性和轨迹上相邻位置间时空关联性进行分析,使生成的假轨迹可有效与真实轨迹进行混淆,防止攻击者识别出假轨迹,有效保护发布轨迹隐私安全。
但现有的针对发布轨迹的隐私保护方法在生成假轨迹时没有充分考虑轨迹在路网中存在的时空约束条件,所以生成的假轨迹很容易因不满足现实路网约束条件被攻击者识别出来,从而导致用户原始轨迹信息泄露。故本文提出面向路网时空约束的轨迹隐私保护算法解决上述问题。
2 预备知识和问题定义
在本文中,将用户的时空数据表示为(l,t),这里t指时间,l=(x,y)为用户的位置点坐标,x和y分别表示经度、纬度。轨迹是用户通过不断移动产生的时空数据序列,记作T={(l1,t1),(l2,t2),…,(ln,tn)},轨迹上采样位置点数量为该条轨迹的轨迹长度。将包含多条用户轨迹的轨迹集称为原始轨迹集,原始轨迹集TS={T1,T2,…,Tm},Ti为原始轨迹集中第i条待发布的用户轨迹,记为Ti={(li1,t1),(li2,t2),…,(lin,tn)}。原始轨迹集经本文算法处理后,得到包含待发布用户轨迹和对应假轨迹的发布轨迹集PTS。发布轨迹集PTS={T1,T12,…,T1j,…,T2,T21,…,T2j,…,Tm,Tm1,…,Tmj,…}。其中,Tij={(li1(j),t1),(li2(j),t2),…,(lin(j),tn)}表示轨迹Ti的第j条假轨迹,(lia(j),ti)表示Tij的第a个签到数据。
定义1 敏感轨迹和敏感轨迹攻击。将用户不希望别人知道的轨迹称为敏感轨迹。攻击者以较大概率识别出用户的敏感轨迹,导致用户轨迹隐私泄露,称为敏感轨迹攻击。
定义2 轨迹k-匿名。给定一条用户敏感轨迹Ti,当发布轨迹集中存在k-1条假轨迹与Ti的签到数据时间序列一致时,则Ti与其他轨迹在该时间段内相互之间不可区分,称Ti满足轨迹k-匿名。
定义3 轨迹泄露率。给定原始轨迹集TS,用|TS|表示TS中轨迹数量,|TS′|表示被攻击者识别出的轨迹数量,则轨迹泄露率如式(1)所示
(1)
定义4 位置距离。给定某时刻用户敏感轨迹上位置点li=(xi,yi),假轨迹上对应时刻位置点li′=(xi′,yi′),将位置距离定义为两点间的欧氏距离,则位置距离如式(2)所示
(2)
定义5 轨迹距离。给定用户敏感轨迹Ti={(li1,t1),(li2,t2),…,(lin,tn)}和假轨迹Tij={(li1(j),t1),(li2(j),t2),…,(lin(j),tn)},则两轨迹间的轨迹距离如式(3)所示
(3)
定义6 相似轨迹。给定敏感轨迹Ti,假轨迹Tij,距离范围阈值α、β,若满足α≤dis(Ti,Tij)≤β,则认为轨迹Ti和Tij是相似轨迹。

定义8 信息损失。给定原始轨迹集TS和发布轨迹集PTS。其中m为TS中轨迹数量,轨迹Ti∈TS,特征轨迹Ti′∈PTS。则基于TS发布轨迹集PTS导致的信息损失如式(4)所示
(4)
问题定义:给定原始轨迹集TS、轨迹匿名阈值k、距离范围阈值α、β,通过生成满足路网时空约束条件的假轨迹,构建符合轨迹k-匿名的发布轨迹集PTS,在保护轨迹隐私安全性的同时保证发布轨迹集的数据可用性最大化。
3 路网轨迹隐私保护
本节提出一种面向路网时空约束的轨迹隐私保护算法(A trajectory privacy protection algorithm satisfying the spatio-temporal constraints in road networks,TPPST),如算法1所示。算法1的主要思想是:首先,通过候选假位置生成算法,根据路网道路分布情况为原始轨迹集中每条敏感轨迹上采样位置点生成满足路网时空约束条件的候选假位置集;其次,根据候选假轨迹生成算法,将候选假位置集中位置按时间顺序连接得到满足路网时空约束条件的候选假轨迹集,并从中筛选得出k-1条满足距离范围约束且与敏感轨迹间轨迹距离最接近的假轨迹;最后,将敏感轨迹与假轨迹合并为一个发布轨迹匿名集进行发布。在该匿名集内,每条轨迹上的采样位置点都可与其他轨迹上相同时刻的位置点构成位置匿名集,防止攻击者识别出敏感轨迹中的任意位置点,从而推测出用户的完整敏感轨迹。由于本算法既要保证生成假轨迹的合理性与真实性,又要保证发布轨迹的隐私安全,所以生成的每条假轨迹都应在满足路网轨迹时空约束条件的同时符合用户的轨迹模式以实现对攻击者的混淆。
TPPST每次从原始轨迹集TS中获取一条用户敏感轨迹Ti进行处理。处理时先通过算法CDL生成Ti上所有采样位置点的假位置,再将所有采样位置和假位置一起存入位置候选集Candli中。通过算法CDT得到所有由Candli中位置点组成的满足路网时空约束条件和距离范围要求的假轨迹,并将假轨迹按轨迹距离值升序排列存入假轨迹候选集CandTi中(第3~4行)。最后,将敏感轨迹Ti和CandTi中前k-1条假轨迹存入发布轨迹集PTS中。当TS中所有用户敏感轨迹都得到满足要求的k-1条假轨迹后,返回包含所有用户敏感轨迹和假轨迹的发布轨迹集PTS(第5~7行)。
算法1.面向路网时空约束的轨迹隐私保护算法(TPPST)
输入:轨迹集TS,轨迹匿名阈值k,距离范围阈值α、β;
输出:发布轨迹集PTS。
1.PTS ← Ø;
2.Foreach trajectoryTiinTSdo
3. Candli= CDL(Ti,k,α,β);//包含轨迹上所有采样位置和假位置信息的候选位置集;
4. CandTi=CDT(Candli,k,α,β);//按轨迹距离值升序排列的候选假轨迹集;
5. PTS←Ti;
6. Select the topk-1 dummy trajectories from CandTito PTS;
7.ReturnPTS;
3.1 轨迹相似性度量
本算法通过假轨迹与对应用户敏感轨迹间的轨迹距离来对轨迹相似性进行度量。轨迹距离值越小,生成假轨迹与用户敏感轨迹在轨迹形状上越相似,越难被攻击者区分;轨迹距离值越大,生成假轨迹与原始轨迹间的区别越大,越容易被攻击者区分。但当轨迹距离值过小或过大时,生成假轨迹会因与原始轨迹过于相似或差别过大而被攻击者识别出来,很难起到有效的轨迹隐私保护效果。所以给定距离范围阈值α,β,只有轨迹距离值在给定范围内的假轨迹才是用户轨迹的相似轨迹,才能既在满足轨迹相似性的同时满足轨迹隐私保护要求。轨迹距离计算如式(3)所示。当且仅当满足式(5)时,假轨迹才可起到隐私保护效果,用于对攻击者进行混淆。
α≤dis(Ti,Tij)≤β
(5)
3.2 候选位置集生成
在算法TPPST中,通过候选假位置生成算法(Candidate dummy location generation,CDL)生成轨迹上采样位置对应的假位置集,并返回由采样位置和假位置构建的候选位置集。为满足轨迹隐私保护要求,生成的假位置点需满足路网时空约束条件和距离范围要求。同时每个采样位置都可与至少1个假位置点构建位置匿名域,实现对用户敏感轨迹上的任一位置点的位置隐私保护。因此将假位置生成分为以下3个步骤:确定假位置生成范围,计算假位置生成数量,假位置生成。
CDL算法先遍历轨迹Ti上所有采样位置li,确定li的假位置生成范围Zi并记录Zi内道路密度,删除道路密度为零的采样位置点,因为此时无法生成满足要求的假位置点,故抑制该采样位置不进行发布(第2~4行);然后对所得道路密度数据进行均一化处理,并通过计算每个li处应生成的最少假位置数量Ni(第5行);接着再次遍历轨迹Ti上的采样位置li,先将li的位置信息存入Candli中,在位置li对应的假位置生成范围Zi内随机生成Ni个满足路网时空约束的假位置,并将这些假位置的位置信息也存入Candli中,最后返回候选位置集Candli(第6~9行)。
算法2.候选假位置生成算法(CDL)
输入:原始轨迹Ti,轨迹匿名阈值k,距离范围阈值α、β;
输出:候选位置集Candli。
1.Candli← Ø;
2.Foreach sampling locationliinTido
3.Zi=dummy location generation range forli;
4.Z←Zi;
5.N←Ni;//Ni=the number of dummy location forlicalculated by Equation 7;
6.Foreach sampling locationliinTido
7. Insert the sampling location’s information into Candli;
8. GenerateNidummy locations inZiand insert these locations’ information into Candli;
9.ReturnCandli;
将路网道路地图抽象为一个无向图G(V,E),路口为无向图节点V,道路为无向图边E。当生成的假位置落在路网无向图上时,该假位置也可视为落在路网道路中,满足路网空间可达性约束。由于用户在路网中只能沿路网道路行驶,故用两点在路网无向图中的最短路径长度代替欧氏距离表示用户实际行驶路程,并用于路网时间可达性判断。由于两点间最短路径长度与欧氏距离相比更接近于用户实际行驶路程,故由此得出的路网时间可达性判断更符合实际。同时,考虑到轨迹上位置点间具有连通性,因此不能单独考虑某位置点与其前一时刻或后一时刻位置间的路网时间可达性,而应综合考虑其前后时刻所在位置点共同进行判断。只有当位置点同时满足与其前后相邻时刻位置间的路网时间可达性约束时,该位置点才是满足要求可用于后续生成假轨迹的假位置点。路网时间可达性由式(6)进行判断,其中S
(6)
综上所述,如图2所示,本算法将采样位置li的假位置生成范围Zi定义为满足式(6)且在以li为圆心,α、β为半径的同心圆圆环区域内的路网无向图上。将所有采样位置li对应的假位置生成范围Zi存放在位置范围集Z中。
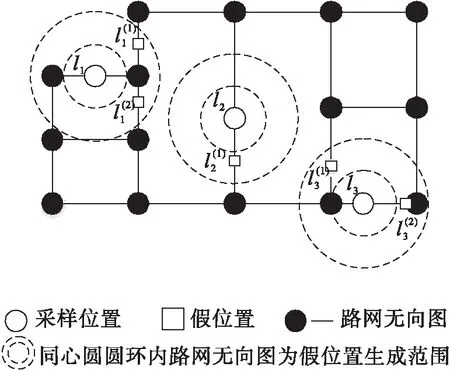
图2 假位置生成示意图
因为每个采样位置所处地理环境内道路密度不同,若生成相同数量的假位置则可能发生某区域无法得到足够数量的假位置,而其他区域生成假位置过于密集等情况,因此本文通过Zi内道路密度区分不同li对应的假位置生成数量。首先将所有区域内道路密度记为RD={rd1,rd2,…,rdn},然后以其中最小的道路密度为基准对道路密度进行均一化处理,处理后得到的结果为RD′={rd1′,rd2′,…,rdn′},其中rdi′=rdi/rdmin。通过式(7)计算每个采样位置对应的假位置生成数量,并对计算结果向上取整,可得出不同li处生成的最少假位置数量Ni,将所有采样位置li对应的假位置生成数量Ni存放在位置数量集N中。最后在每个li对应的Zi内随机生成Ni数量个假位置即可。
(7)
例如,给定一条包含5个采样位置的轨迹和轨迹匿名阈值k=5,轨迹上每个采样位置对应的道路密度为RD={3,2,2,4,3},以其中最小道路密度2为基准进行均一化处理后得到RD′={1.5,1,1,2,1.5},通过式(7)计算可知1.5x·x·x·2x·1.5x=4.5x5≥4,将计算结果向上取整后可知x=1,则对应假位置生成数量集合为Ni={2,1,1,2,2}。
3.3 候选假轨迹生成
本节提出候选假轨迹生成算法(Candidate dummy trajectory generation, CDT)生成敏感轨迹Ti对应的候选假轨迹集CandTi。CDT先将算法CDL生成的候选位置集Candli中的位置通过枚举法得出所有可能满足路网时空可达性约束的假轨迹,同时计算假轨迹与原始轨迹间的轨迹距离,并将所有轨迹信息存入候选假轨迹集CandTi中。候选假轨迹连接方式如图3所示(第2行)。然后根据给定的距离阈值α,β对CandTi中所有候选假轨迹进行筛选判断,若存在轨迹间距离值不满足轨迹相似性度量公式α≤dis(Ti,Tij)≤β的情况,则从CandTi中删除该条候选假轨迹(第3~5行)。最后将CandTi中假轨迹按轨迹距离值升序排列后返回(第6-7行)。

图3 候选假轨迹连接示意图
算法3.候选假轨迹生成算法(CDT)
输入:候选位置集Candli,轨迹匿名阈值k,距离范围阈值α、β;
输出:候选假轨迹集CandTi。
1.CandTi← Ø;
2.Through enumeration method and Candligenerate dummy trajectories and then insertTijto CandTi;
3.Foreach trajectoryTijin CandTido
4.Ifdis(Ti,Tij)not satisfiedα≤dis(Ti,Tij)≤βthen
5. deleteTijfrom CandTi;
6.Sort(asc)CandTiby dis(Ti,Tij);
7.ReturnCandTi;
本文通过枚举法列举得出所有可能的候选假轨迹。假设一条轨迹上有n个采样位置点,若为每个位置点都生成s个假位置则最多可得到(s+1)n-1条假轨迹,假轨迹数量随采样位置数呈指数形式增长。但这样得到的假轨迹集中会存在某些假轨迹上存在过多与采样位置点相同的位置,增加原始轨迹泄露的风险。故需进一步对得到的假轨迹进行筛选,只保留含有一个采样位置的假轨迹,删除其余假轨迹,这样得到的假轨迹集可在有效对攻击者进行混淆的同时,降低轨迹泄露概率。
3.4 算法安全性及复杂度分析
在本节中,会对算法的安全性和时间复杂度进行理论分析与证明。
定理1 采用面向路网时空约束的轨迹隐私保护算法(算法1)对原始轨迹集中的每条用户轨迹进行处理后,得到的发布轨迹集满足轨迹k-匿名要求。
证明 算法2为原始轨迹集中每条用户敏感轨迹上所有采样位置点生成假位置,且通过计算保证这些假位置连接得到的满足路网时空可达性约束和距离范围要求的假轨迹至少为k-1条。算法3在生成假轨迹时不仅使用算法2生成的假位置点还包含原始轨迹上部分采样位置点,所以最后得到的满足要求的假轨迹一定多于k-1条。算法1通过调用算法2和算法3得到所有满足路网时空约束和距离范围要求的假轨迹中轨迹距离值最小的k-1条,使轨迹集中每条原始轨迹均能满足轨迹k-匿名。综上,通过算法1生成的发布轨迹集满足轨迹k-匿名要求。
算法复杂度分析:用m、n分别表示原始轨迹集中用户敏感轨迹数量和敏感轨迹上采样位置点数量。在算法CDL中,生成轨迹上所有采样位置点对应的满足路网时空可达性约束条件的假位置需n+n·k1/n时,则算法的时间复杂度为O(n·k1/n)。在算法CDT中,通过枚举法得到所有候选假轨迹并计算轨迹距离耗时n!+(k1/n+1)n,算法复杂度为O(n!)。算法TPPST通过调用算法CDL和算法CDT得到轨迹集中每条用户原始轨迹的候选假轨迹集,并从中选择k-1假轨迹耗时为m·(n·k1/n+n!),所以算法TPPST的时间复杂度为O(m·n!)。
4 实验结果分析
本节对提出的面向路网时空约束的轨迹隐私保护算法进行性能分析和评估。实验使用北京市路网地图数据和1个真实的北京出租车轨迹集T-Drive。其中,北京市路网数据包括17万个路网顶点及43万余条边。T-Drive原始轨迹集包含北京大部分区域的10 357辆出租车一星期内的轨迹,总计72 499条轨迹,涵盖约1 500万位置点,轨迹中相邻位置点间的时间差为5 min。本文对T-Drive原始轨迹集进行处理,选取其中600条轨迹上的部分轨迹数据构建实验轨迹数据集进行实验,实验数据集统计信息如表1所示。

表1 实验数据集统计信息
本文先通过实验得出面向路网时空约束的轨迹隐私保护算法(TPPST)中的最优距离范围阈值。然后通过与基于随机法生成假轨迹的隐私保护方法(简称RM)和基于时空关联性生成假轨迹的隐私保护方法(简称STM)比较,分析本算法在运行时间、信息损失和轨迹泄露率方面的性能。在测试中,轨迹匿名阈值k的取值范围为[3,18](默认为9),轨迹数量n的取值范围为[100,600](默认为300),轨迹长度l的取值范围为[5,10](默认为7)。
本实验的软硬件环境如下:(1)硬件环境:Intel Core i5 2.71GHz 8GB DRAM;(2)操作系统:Microsoft Windows 10;(3)编程环境:Java,Eclipse。
4.1 最优距离阈值
本节通过测试TPPST算法在不同距离范围下的轨迹相似度和信息损失来获取最优距离范围阈值α、β。由于当距离范围过小或过大时,所得实验结果均趋于平缓,故选择波动较大区间作为实验测试范围。
由图4可知:(1)随着距离范围的增大,轨迹相似度逐渐增加,信息损失逐渐减少。这是由于随着距离范围的增大,假位置的生成范围也随之扩大,一些原始轨迹上原本因假位置生成范围内道路密度为零而被抑制发布的采样位置点,在扩大范围后也生成假位置并参与发布。由信息损失计算公式可知,信息损失为原始轨迹集中所有用户敏感轨迹与发布轨迹集中对应特征轨迹间轨迹距离和的平均值。随着距离范围的扩大,特征轨迹上的位置点也随之变化,部分位置点坐标与原始轨迹上对应采样位置点坐标更加接近,因此信息损失逐渐降低。而轨迹相似度主要通过原始轨迹与对应假轨迹间轨迹距离进行计算,随着更多假位置的生成,计算时会增加该点与对应假位置间的距离差,故轨迹相似度逐渐增加。综上所述,距离范围与轨迹相似度成正比,与信息损失成反比。(2)实验通过对比在不同轨迹匿名阈值k、轨迹长度和轨迹数量的情况下,得出距离范围变化对轨迹相似度和信息损失产生的影响。由图4可知,当距离范围从6 km增大到7 km时,信息损失明显下降,且在距离范围大于7 km时信息损失的变化趋于平缓。在轨迹相似度随距离范围的增加而逐渐增加的过程中,在距离范围为10 km时,增加趋势明显减缓。所以本文将距离范围设置为[7,10],在该范围内算法生成的假轨迹可在有效保护用户原始轨迹隐私安全的情况下,保持较好的数据可用性。

图4 轨迹相似度和信息损失随距离范围变化
4.2 运行时间
由图5可知,3个算法的运行时间均随着轨迹匿名阈值k、轨迹数量和轨迹长度的增加而增长。STM算法和RM算法的运行时间接近,TPPST算法快于STM算法和RM算法约1.5 s。这是由于TPPST算法通过CDL和CDT算法限定了假位置和假轨迹的生成条件,因此TPPST算法可以更快地生成满足要求的假轨迹。且由图5可知,运行时间与轨迹匿名阈值k、轨迹数量和轨迹长度值成正比,即要生成的假轨迹和待用户保护轨迹上采样位置数量越多则运行时间越长,且随着生成假轨迹数量的增加算法耗时翻倍增加。

图5 运行时间随k、轨迹数量和轨迹长度变化
4.3 信息损失
由图6可知,RM算法和STM算法的信息损失始终高于TPPST算法,最高可达TPPST算法的2倍。这是由于STM算法的假位置生成范围为将路网地图网格化后,两采样位置间欧氏距离加一个随机数长度的网格范围。RM算法的假位置生成范围为将路网地图网格化后距采样位置2β内的网格范围。由此可以看出RM算法和STM算法生成的假位置点要比TPPST算法生成的假位置点与采样位置间的位置距离大,因此计算所得信息损失也更大。由图6可知,信息损失与轨迹匿名阈值成反比,与轨迹数量值成正比。由信息损失计算公式可知,随着生成假轨迹数量的增加,敏感轨迹T与发布轨迹中对应特征轨迹T′间的轨迹距离值会逐渐减小。在轨迹数量不变的情况下,信息损失随着轨迹匿名阈值k的增加而减小。而在轨迹匿名阈值k不变的情况下,随着原始轨迹数量的增加,计算得到的轨迹距离累加和也在不断增加,且增长趋势大于轨迹数量的增长,故信息损失会随着轨迹数量的增加而增加。
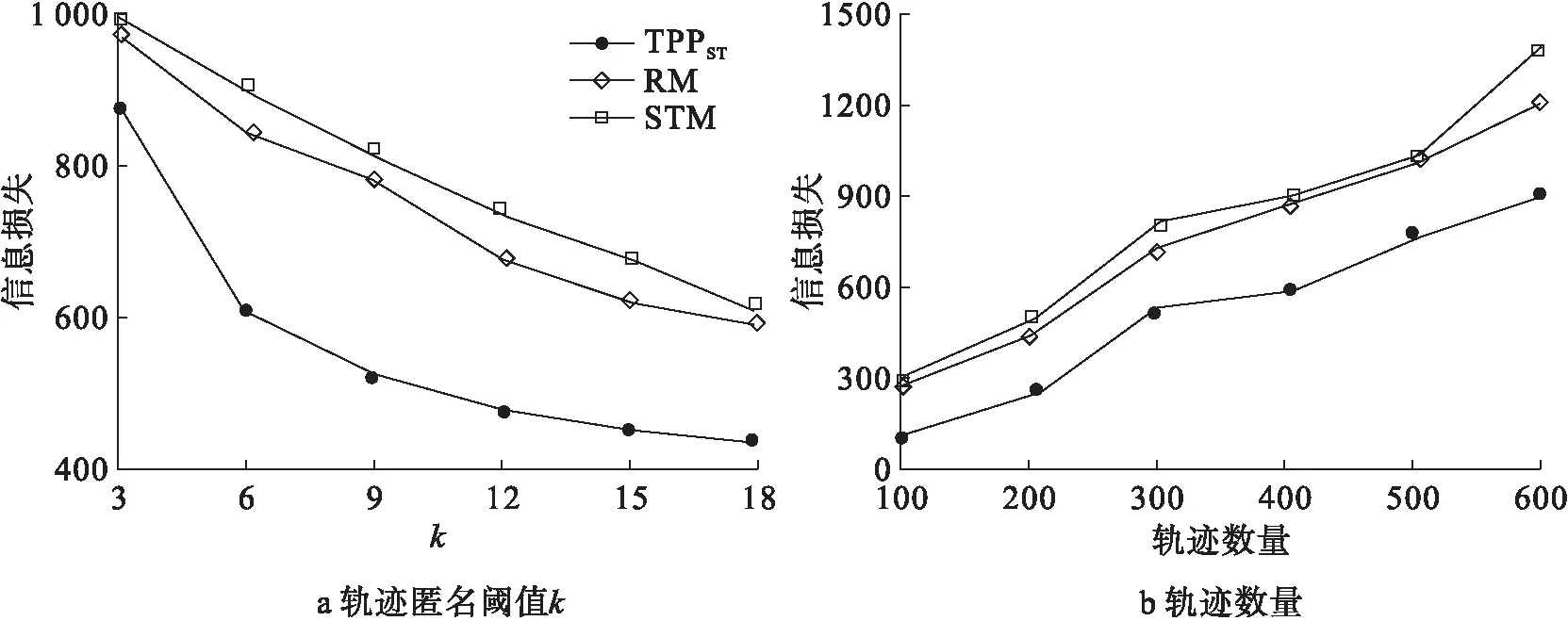
图6 信息损失随k和轨迹数量变化
4.4 轨迹泄露率
由图7可知,当发布轨迹为路网轨迹时,TPPST算法根据路网中轨迹的时空约束条件生成假轨迹,故无法被攻击者通过敏感轨迹攻击识别出来。RM算法和STM算法的轨迹泄露率接近于100%,远高于TPPST算法。这是由于RM算法只是以用户真实位置点为基准随机生成假位置点,而STM算法虽然是基于轨迹时空特性生成假轨迹,但二者均未考虑路网轨迹具有的时空约束条件,故使用上述两种算法生成的假轨迹有95%以上的概率会被攻击者通过敏感轨迹攻击识别出来,导致用户敏感轨迹隐私泄露。

图7 轨迹泄露概率随k和轨迹数量变化
5 结语
本文提出一种面向路网时空约束的轨迹隐私保护算法(TPPST),用以解决现有的假轨迹生成轨迹隐私保护技术因生成的假轨迹真实性较差而造成用户轨迹隐私泄露的问题。该算法在路网无向图的基础上根据路网轨迹时空约束条件生成假轨迹,使生成的假轨迹在有效保护用户隐私安全的同时,降低发布后轨迹集的信息损失。实验基于真实轨迹数据进行,所得结果表明TPPST算法可有效抵御攻击者的敏感轨迹攻击,在保护用户发布轨迹隐私安全的情况下保证发布轨迹具有较好的数据可用性。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
现代电子技术(2022年11期)2022-06-14
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
爱你·心灵读本(2018年6期)2018-09-10
环球飞行(2018年7期)2018-06-27
爱你(2018年16期)2018-06-21
