
基于IM-SSD+ACO算法的整株大豆表型信息提取
2021-02-14 01:56陈海涛赵秋多王业成
农业机械学报 2021年12期
宁 姗 陈海涛 赵秋多,2 王业成
(1.东北农业大学工程学院, 哈尔滨 150030;2.黑龙江科技大学工程训练与基础实验中心, 哈尔滨 150022)
0 引言
种质资源是大豆品质和产量的基础,大豆考种是大豆作物表型组学研究中种质资源鉴定与筛选的重要方法之一。作物表型组学研究能够获得高质量、高精度和可重复性的植物表型数据[1-2]。然而,传统大豆考种工作主要依靠人工,在考种过程中需要消耗大量的人力物力。同时,人工操作还存在人为主观误差、效率低、时间周期长等问题。人工考种的方式已经制约了植物生物学研究的发展,随着机器视觉技术的飞速发展,采用高效率、低误差、低成本的自动化表型信息检测平台获取植物表型信息已成为农业领域研究热点且具有巨大潜力[3]。植物表型采集平台按照搭载方式可分为台式、传送带式、车载式、自走式、门架式、悬索式以及无人机式植物表型平台;按照使用环境分为室内植物表型平台和田间植物表型平台。大豆考种是对成熟后的大豆植株和籽粒性状调查的田间试验环节,目的是了解不同品种或不同处理因素对植株性状及籽粒的影响,从而分析掌握不同品种、不同处理因素的作用。其中,室内考种通常包括植株考种和籽粒考种两部分[4]。本文研究的是室内植株考种,其调查项目包括株高、有效分枝数、主茎、株型及全株荚数。
近年来,基于深度学习的目标检测在农业领域得到了广泛的应用,如大豆豆荚识别[5]、杂草的田间识别[6]、番茄关键器官识别[7-8]、猕猴桃图像识别[9-10]、蛋类识别[11]等。深度卷积神经网络[12-16](Deep convolution neural network, DCNN)是深度学习中较为常用的网络模型,在目标检测方面的应用非常广泛并显现出巨大的优越性,它主要包括两大类:一类是基于区域生成的检测方法,即根据生成可能包含目标的候选区域采用卷积神经网络(Convolution neural network,CNN)对每个候选区域进行分类,如RCNN[17]、Fast R-CNN[18]、Faster R-CNN[19];另一类是基于回归的检测方法,采用CNN对整个图像进行处理,在实现目标定位的同时预测目标类别,如YOLO[20]、YOLO v2[21]、SSD[22]。
LIU等[22]对Faster R-CNN、YOLO、SSD300、SSD512进行了比较,YOLO的实时性较好,但准确率相对SSD低。REDMON等[20]将YOLO v2与SSD进行比较,它们有较相似的整体框架,但在低分辨率图像上SSD精度略高,SSD对GPU资源占用率较低。SSD通过anchor boxes机制,在不同尺度感受野的特征层上提取特征,回归计算得到目标的空间信息以及分类结果,进而提升准确率。然而,如果将SSD直接应用于大豆植株的豆荚与茎秆的定位与识别,其检测精度受到豆荚与豆荚、豆荚与茎秆之间相互遮挡影响较大,在检测重叠、遮挡等特殊情况时易出现漏检、误检等情况。针对传统SSD的缺陷,本文提出一种增加残差结构的IM-SSD模型,在网络的中低层部分引入残差结构,将低层的细节传到高层进行融合,调整基础网络结构,提高识别准确率。
在植物茎秆定位与识别研究中,深度学习算法常常需要与其它算法相结合来准确提取茎秆[23],本文采用IM-SSD模型对大豆植株茎秆分段识别和定位,再结合蚊群优化(Ant colony optimization, ACO)算法提取大豆植株的完整茎秆,根据豆荚与茎秆的定位获取全株荚数、株高、主茎、有效分枝数与株型。
1 材料与方法
1.1 数据采集
试验大豆样本为收获期的大豆植株,包括东农52、东农251、东农252和东农253共4个品种,均来自于东北农业大学向阳农场试验基地,分别在2017年9月底和2018年10月初分两次采集。试验样本图像采集采用大豆植株图像表型检测平台,如图1所示,该检测平台采用佳能5D Mark Ⅱ型相机搭配佳能EF 24~105 mm 1∶4 L IS USM型变焦镜头,垂直固定于距放置植株的采集平台2 000 mm处,照明系统采用高角度照明方式,为DPX-400型工作室闪光灯,指数为GN66,色温为5 500 K,输出量为0.375,柔光箱长、宽、高为1 200、800、450 mm。拍摄图像的分辨率为5 616像素×3 744像素,焦点为55 mm,光圈值f/11,曝光时间0.005 s,ISO为100,曝光补偿为0。在植株表型检测中,叶片不作为检测目标,为避免叶片可能产生的误识别及遮挡等问题,样本采集前,将大豆植株上未脱落的叶片清理干净。同时为减少复杂背景的干扰,植株采集平台以蓝色无纺布为背景,采集时将大豆植株平放并将植株子叶结与采集平台的子叶结基准线对齐。最后,批量剪切图像尺寸为5 400像素×2 700像素,图像背景处理采用RGB彩色模型并根据每个像素的R、G、B分量的亮度来判定是否为背景,如果B分量的亮度大于其它两个分量,则视该像素为背景,如图2所示,图像保存为.jpg格式。
1.2 数据集标注
为实现对IM-SSD模型的训练,本文使用图像标注工具Windows v1.6.0对植株上的豆荚和茎秆分别进行定位及标记,豆荚为“pod”类,茎秆为“stem”类。由于豆荚与豆荚、豆荚与茎秆的相互遮挡,对豆荚和茎秆的识别和定位影响较大,而豆荚尖部的相互遮挡概率相对较小,为了减少相互遮挡的影响,在真实框标注中仅标注豆荚尖部即远离茎秆的1/3至1/2部分,具体标注范围视被遮挡情况而定。茎秆标注采用分段标注,仅标注未被遮挡的部分,因为未被遮挡的茎秆易于识别与定位,大豆植株标注如图3所示。
1.3 数据集处理
图像样本总量为3 695幅,按7∶2∶1分成训练集、测试集和验证集,训练集样本2 600幅、测试集样本735幅、验证集样本360幅。训练集和测试集分别用于训练和评估模型。在模型训练过程中,利用验证集对超参数进行优化。为保证样本集的均匀分布及评价的可靠性,所有样本集均为随机抽取。
为降低颜色变化、拍摄角度、生长状态等对识别的影响,提高检测精度[24-25],实现模型的鲁棒性,通过以下几种方式对训练数据进行扩增。采用RGB颜色3通道对训练集图像进行随机调整,以提高图像颜色的多样性。对训练集图像进行水平、垂直和对角翻转、随机旋转和平移操作。将所有变换后的训练集样本进行整理,如果变换后样本图像的标注框超出边界,该标注框将被丢弃,如果变换后图像丢弃标注后没有标注信息,则删除图像。
1.4 IM-SSD卷积神经网络模型
SSD网络是在VGG16[26]网络的基础上进行修改,在VGG16网络结构上增加了5个特征提取层,同时分别在6个不同尺度的卷积层输出特征图,目的是对不同尺度的目标进行检测。传统SSD网络主要包括SSD300和SSD512,其输入图像分别被压缩为300像素×300像素、512像素×512像素,这种压缩比对于植株图像的压缩变形大,为降低图像变形带来的影响,IM-SSD的输入图像被压缩为300像素×600像素。另外,传统SSD在检测重叠、遮挡等情况下的豆荚时易出现漏检、误检。针对传统SSD的缺点,IM-SSD在网络的中低层部分引入残差结构,将低层的细节传到高层进行融合,调整基础网络,提高识别率。
IM-SSD结构在SSD深度卷积神经网络结构的基础上增加了2个卷积层:Add1层,由Maxpool2和Conv3_2按位相加并归一化(Batch normalization,BN)[27];Add2层,由Maxpool3和Conv4_2按位相加并归一化,其结构如图4所示,红色的层为卷积核3×3的卷积层,绿色的层为卷积核1×1的卷积层,蓝色的层为最大池化层,步长为2。增加残差结构的卷积层能够提高网络对小目标的检测能力,从而提升被遮挡或重叠豆荚的识别率。
IM-SSD采用特征金字塔检测目标,分别对Conv4_3层、Conv7层、Conv8_2层、Conv9_2层、Conv10_2层和Conv11_2层生成比例不同的默认框,每一类共生成17 236个检测框,使用非极大值抑制(Non-maximum suppression, NMS)[28]过滤重复的预测框。在多个特征图上同时进行识别和定位回归,损失值L由置信损失值(Lconf)和定位损失值(Lloc)的加权组成[22],计算式为
(1)
(2)
(3)
(4)
式中N——匹配的默认框数
x——类别的真实值
c——类别置信度的预测值
l——预测框位置
g——真实框位置
α——加权因子
cx——预测框中心x坐标
cy——预测框中心y坐标
w——预测框宽度
h——预测框高度
f(·)——平滑函数
Neg——负样本集
Pos——正样本集
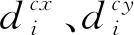
(5)
(6)
(7)
σ——光滑度控制系数
1.5 基于ACO算法的大豆茎秆提取
IM-SSD对植株茎秆的定位是不连续的,不能完全反映真实的茎秆形态。本文提出了一种基于ACO算法的完整茎秆提取方法,该方法利用IM-SSD已定位茎秆的数据,以及茎秆的连续性特点,运用ACO算法获取最短路径将分段茎秆连接起来最终获得完整的茎秆。ACO算法对路径搜索空间有一定要求,如果搜索空间大、复杂度高,蚂蚁易陷入非可行点或规划路径迂回等问题。通过IM-SSD的茎秆定位,根据已定位茎秆的坐标数据对二值图像进行剪切,为减小栅格地图的规模,将剪切图像分为3部分,如图5所示。3部分图像运用等间隔像素采样的方法将图像压缩成z×z栅格并形成栅格地图,如图6所示。此外,每个部分都根据已定位茎秆的位置设置多个起点和终点,为降低算法的复杂度,将信息素存储在栅格中。
在ACO的栅格模型中采用二进制,其中“1”表示非植株栅格,“0”表示植株栅格。每个栅格按照从上至下、从左到右的顺序进行编号。
栅格地图与植株二值图像的二维坐标(x′,y′)转换式为
(8)
式中r——栅格包含的像素行数,列数和行数相等
n——栅格数目
R——当前行数
mod(·)——取余函数
ceil(·)——取整函数
ACO是一种进化智能启发式搜索算法,用于寻找蚂蚁从居住地到食物源的最短路径[29-30]。蚂蚁k从栅格i移动到下一个栅格j是基于距离和未被访问栅格的信息素浓度。
迭代中,当每只蚂蚁到达终点或出现死锁时,搜索将停止。完成搜索后,保存所有到达终点蚂蚁的搜索路径长度。信息素浓度计算式为
(9)
其中
(10)
(11)
式中τij(st+1)——下一时刻从栅格i到下一个栅格j的信息量
m——蚂蚁数量
ρ——信息挥发系数
st——当前时刻
Q——常量
Lk——蚂蚁搜索的路径长度
dOiOi+1——蚂蚁一次移动的长度
Rk={O1,O2,…,On+1}是组成路径的一组栅格,O1=S,On+1=E。从初始点到终点有多条可选路径,路径规划可以得到一条最优或次优的可行路径,最短路径Lopt的数学模型为
Lopt=min(Lk)
(12)
最短路径与大豆茎秆坐标转换公式为
Ropt=min(Rk)
(13)
F(Ropt)=(k1ONi,k2ONj)
(14)
式中ONi——横坐标值
k1、k2——横坐标转换系数
ONj——纵坐标值
Ropt——最优路径
F——路径转换函数
2 试验与结果分析
2.1 试验环境与参数
本研究深度学习运行硬件环境为Intel(R)Core TM i7-9700K CPU,3.6 GHz,16 GB内存,3 TB硬盘,256 GB固态硬盘,NVIDIA GTX1080GPU显卡,操作环境为Ubuntu 16.04系统、Anaconda 4.2.0、Tensorflow 1.4.0和Keras 2.0.8。
由于采集的训练样本数量有限,不足以训练全新的网络,同时也为了减少训练时间,采用迁移学习[31-32]方法,使用Pascal-VOC“07+12”[33]20类数据集的网络权重剪裁后对训练集进行训练。用随机梯度下降算法对网络分类层进行微调。加权因子α为0.8时,可降低局部损失因子对全局损失函数的影响。批处理量设置为32,动量衰减设置为0.9,初始学习率为0.01,每20次迭代验证一次。根据平均损失的变化率,每次将学习率降低为原来的1/10,直至网络不再收敛。
2.2 模型评价指标
采用3个全局指标和1个局部指标来评估网络模型的稳定性和分类性能,分别为精确率(Precision,P)、假阴性率(False,F)、召回率(Recall,R)和交并比(Intersection over union,IoU)。其中,使用精确率和假阴性率来获得测试集中的性能指标,召回率代表预测框与所有真实框匹配的比例,IoU评价每个目标检测结果的指标。
在确定默认框的情况下,正样本为IoU大于0.4的默认框。精确率是预测样本为阳性样本占所有阳性样本的比例。假阳性是指被误判为阴性的样本。假阴性率是指被误判的阳性样本占所有阳性样本的比例。
2.3 基于IM-SSD的豆荚和茎秆识别与定位
根据2.1节的模型参数,通过随机抽取训练样本和验证样本的方式对IM-SSD模型进行训练和性能评估,以判断模型的可靠性和稳定性,经过4 200次迭代后收敛,其试验结果如图7所示。
大豆植株样本I通过IM-SSD模型识别豆荚和茎秆的预测框分别为52、21个,如图7a所示。其中,在豆荚检测中有4个未被检出,在茎秆检测中多检出2个、少检出1个茎秆。大豆植株样本Ⅱ的豆荚和茎秆预测框分别为75、31个,如图7b所示。其中,在豆荚检测中有7个未被检出,在茎秆的检测中多检出3个、少检出4个茎秆。从试验结果可以看出,在豆荚的识别中,未重叠豆荚的识别率最高,相邻豆荚次之,重叠豆荚识别率较差,被遮挡豆荚识别率最差。当豆荚由于拍摄或摆放角度产生变形时,容易被漏检。因此,在全株豆荚数检测时,增加全株豆荚数补偿因子,全株豆荚数计算公式为
Ps=Pf+Pb
(15)
其中
Pb=0.08Pf
(16)
式中Pf——IM-SSD模型已检测到的豆荚数目
Pb——补偿因子
Ps——全株豆荚数
计算得到样本Ⅰ的全株豆荚数检测值为56个,样本Ⅱ的全株豆荚数检测值为81个。而在茎秆的识别过程中,中间部分多检或少检对茎秆的完整提取影响较小。IM-SSD模型对豆荚和茎秆的检测精确率分别为89.68%和81.99%,平均检测精确率为85.84%,豆荚的识别精确率高于茎秆。另外,通过增加豆荚数补偿因子使全株豆荚数的统计精确率达到92.76%。
2.4 基于ACO的大豆植株茎秆提取
在茎秆完整提取试验中,为了验证ACO算法提取大豆茎秆的有效性,以其中一个验证集样本为例,将其分为3部分,3部分压缩尺寸均以35×35的栅格作为蚁群规划地图。参数设置为:种群规模n=50,最大迭代T=200,α′=1,β′=7,ρ=0.3,Q=1。
在蚁群地图中,将已定位栅格的最左侧中“0”栅格作为起始栅格S,将最右侧与起始栅格相对应的“0”栅格作为结束栅格E,分别对植株的每个分枝进行基于蚁群算法的路径规划,并根据路径规划结果获得完整的植株茎秆定位,图8为最优路径规划结果,图9为最优路径的收敛曲线。最终获得的完整大豆植株茎秆的预测结果如图10所示。
基于ACO算法的大豆植株茎秆提取同样适用于具有较复杂分枝结构的大豆植株,如图11所示。有效分枝数是指成熟期植株上有两个以上茎节并有一个以上成熟豆荚的第1级分枝数。试验中通过拟合的分枝个数确定植株的有效分枝数。在多分枝大豆植株中,与其它分枝相比主茎较粗,将平均茎粗最大的茎作为主茎,用不同颜色标出不同的分枝,其中蓝色虚线标出主茎,图10共2个有效分枝、图11共4个有效分枝。株型的判断是通过成熟期下部分枝与主茎的收敛程度确定,如图12所示,下部分枝的生长方向与主茎的自然夹角为α1、α2、α3,当所有夹角的平均值小于30°则为收敛型,大于30°小于60°为半开张型,大于60°为开张型,其中图10为收敛型,图11为半开张型植株。株高是成熟期从子叶节到植株生长点的高度,如图12所示,株高的计算是通过最顶端茎秆像素点到子叶结基准线的垂直距离乘以0.05,其株高的单位为mm,其中图10的株高为992 mm,图11的株高为875 mm。
2.5 不同网络模型的对比试验
利用大豆植株训练集对3种网络模型(SSD300、SSD512、IM-SSD)的性能进行评价,所有默认框的IoU大于0.4即为正样本。经过4 200次迭代,损失曲线如图13所示。在相同的网络参数下,SSD300模型的网络训练初始损失误差小,收敛速度快。而SSD512模型的初始损失误差最大,收敛速度较快,但IM-SSD模型在3种模型中经过2 000次迭代后损失值最小。
将3种模型与植株真实值进行对比,其样本均来自于验证集,其中3种模型分别对豆荚和茎秆通过分段定位进行预测。由于人工检测可能存在主观误差,为获得植株的真实值,采用多次人工选荚和人工框选取茎秆的方法,即对所有验证集样本进行5次重复检测,真实值为5次观测选荚的数量结果中出现概率最多的数值,茎秆框选真实位置为5次框选中IoU最大的一次框选,结果如表1所示。从试验结果可以看出,人工对豆荚和茎秆的检测与定位的精确率最高,但人力和时间耗费较大,而文中模型通过样本训练后可自动对豆荚及茎秆定位,无需人工操作。另外,与SSD300网络和SSD512网络相比,IM-SSD平均检测精确率分别提高了7.79、3.83个百分点,在3种模型中IM-SSD模型对大豆植株豆荚与茎秆的检测更稳定、有效。

表1 3种模型与人工检测结果的比较Tab.1 Comparison of three models and manual detection results %
2.6 基于ACO算法的茎秆表型特征数据分析
由IM-SSD模型得到的植株茎秆定位是不连续的非完整茎秆。本文提出了基于ACO算法并运用IM-SSD获得茎杆定位来提取完整茎秆的方法能够准确定位茎秆,并弥补IM-SSD的不足。同时,根据完整茎秆定位,提取出大豆植株的株高、有效分枝数和株型。将人工5次重复测量株高及有效分枝数、株型中出现次数最多的值作为真实值。人工检测的单次株高、有效分枝数和株型的精确率分别为98.65%、99.12%、93.21%,运用完整茎秆定位提取的精确率分别为95.56%、96.12%、90.28%,其精确率均略低于人工测量。株型判断的准确率较低的原因是受拍摄角度的影响,单一角度很难准确获取复杂结构的植株分支夹角。人工检测虽然有较高的精确率但消耗大量的人力物力且劳动强度高、时间周期长、对数量级也有一定要求,而本文检测模型通过样本训练后可自动对豆荚及茎秆定位,无需人工操作,减少了主观误差、降低了劳动强度、缩短了检测周期,适于数据量较大的样本检测,更具有客观性,精确率均在90%以上,基本满足植株表型平台自动化的要求。
3 结论
(1)提出了一种基于IM-SSD模型的大豆植株豆荚与茎秆表型信息检测方法。试验结果表明,该模型具有较高的检测精度,对遮挡和重叠干扰有较强的鲁棒性。
(2)在整株大豆植株样本训练集上,对已标注训练样本进行随机处理,实现图像扩增,提高网络的特征提取能力。在真实框标注时,只标注一部分特征区域,有效降低了相互遮挡产生的误判率。
(3)提出了基于SSD结构的残差网络,将低层特征图融合到高层特征图,增强对小目标检测能力,提高网络的识别率。与SSD300网络和SSD512网络相比,IM-SSD平均检测精确率分别提高了7.79、3.83个百分点。同时,增加全株豆荚数补偿,使全株豆荚数统计的精确率提高到92.76%。IM-SSD模型与传统SSD相比,检测精度得到了提高,同时也为其他植株检测的研究提供了思路。
(4)采用ACO算法弥补IM-SSD分段提取茎秆的不足,从而获取大豆植株的株高、有效分枝数和株型。
猜你喜欢
江西农业大学学报(2022年3期)2022-07-07
重庆理工大学学报(自然科学)(2022年1期)2022-02-18
中国生态农业学报(中英文)(2021年9期)2021-09-10
北京航空航天大学学报(2021年5期)2021-06-09
大科技·C版(2018年11期)2018-10-21
作文周刊·小学一年级版(2018年8期)2018-03-15
汽车文摘(2016年1期)2016-12-10
建筑工程技术与设计(2015年26期)2015-10-21
科学种养(2014年1期)2014-02-19
农民科技培训(2009年7期)2009-09-18
