
基于SMOTE-AdaBoost-DT的类别不平衡信用评分模型
2021-02-15 11:57赵佳丽徐明江吴增源郑素丽
中国计量大学学报 2021年4期
赵佳丽,徐明江,吴增源,郑素丽
(1.中国计量大学 经济与管理学院,浙江 杭州 310018;2.杭州千岛湖发展集团有限公司,浙江 杭州 311701)
经济的快速发展和居民消费观念的转变驱使个人信用贷款规模逐年扩大。据中国人民银行数据显示,我国个人整体信贷消费余额从2016年的25.35万亿元升至2020年的49.57万亿元。然而,随着信贷规模的不断扩大,不良贷款率也逐年增长。据中国银保监会发布的数据显示,2021年三季度末,我国商业银行不良贷款率高达1.75%,不良贷款余额达2.8万亿元[1]。不良贷款不仅影响银行的正常运转,也可能诱发社会风险,造成一系列不良反应。对信贷申请人进行信用评分是降低信贷风险和不良贷款率的重要手段。
信用评分模型是一套帮助贷方发放贷款的决策模型。其核心思想是根据客户还贷或不还贷行为的特征,将其分为信用良好的“好客户”和信用不良的“坏客户”两个群体,最终做出是接受或拒绝信贷申请的决定。当前主要利用统计或机器学习的方法建立模型以衡量客户的风险水平。统计方法中的线性判别分析[2]和逻辑回归[3],因易理解和易于实现,而被经常使用。机器学习方法中比较有代表性的包括决策树[4]、神经网络[5]、支持向量机[6]等。Chern等[7]提出利用决策树算法来解决大数据环境下的信用评估问题。Bekhet和Eletter[8]运用人工神经网络以支持约旦商业银行的贷款决策,结果表明人工神经网络在减少决策系统时间和成本的同时,还可以出色地识别那些可能违约的客户。Kambal等[9]分别采用决策树(DT)和人工神经网络(ANN)建立信用评分模型并进行对比分析,发现ANN的方法优于DT,但DT的结果解释性更强。
信用评分模型在实际应用过程中面临一个不容忽视的问题:按期还款的“好客户”数量远大于违约的“坏客户”数量,即客户信贷数据的分布是不均衡的。同时,把“坏客户”误分为“好客户”和把“好客户”误分为“坏客户”的代价是不同的。因此,信用评分是一个典型的不平衡分类问题。然而,传统的单一分类器方法更倾向于提高整体的分类精度,却忽略了对少数类样本的识别。目前,不平衡数据分类问题的处理办法主要有两类:采用数据预处理技术和算法改进[10]。一方面,在数据预处理层面,通过重采样方法使得数据集分布接近平衡。重采样分为欠采样和过采样。欠采样是指通过减少多数类样本的数量来提高少数类的分类准确率,代表性的欠采样方法有ENN[11]和Tome links[12]法。过采样是指增加少数类样本的数量来提高少数类的分类性能,典型的过采样方法有合成少数类过采样技术[13](SMOTE)和自适应样本合成方法[14](ADASYN)。重采样方法的优势是操作简单,有较好的适应性,但其对样本的删减和扩充可能会导致某些潜在的有用信息的遗失或模型过拟合问题。另一方面,在算法改进层面,主要包括代价敏感学习和集成学习等。集成学习通过将多个单分类器按一定方式集成来增强单个分类器对不平衡数据的分类效果。典型的集成学习方法包括Bagging、Boosting等。AdaBoost算法作为Boosting的典型代表,能够自动调整基分类器的权重,通过增强错分样本的学习提高分类精度。以决策树为基分类的AdaBoost集成算法级联多棵决策树,能够有效弥补单颗决策树泛化能力不足的问题。但将AdaBoost-DT模型应用于客户信用评估中还存在一定局限性,该算法的基本假设是数据分布均匀,因此在解决不平衡数据分类问题时,正类样本的识别率并不高[15]。
基于以上分析,考虑到单一方法难以在不平衡数据集上达到良好预测效果,本文提出了过采样与集成算法相结合的信用评分模型,即SMOTE-AdaBoost-DT算法。首先,通过SMOTE增加少数类样本数量,使数据达到平衡;其次,在采样后的较平衡新数据集上,利用以DT为基分类器的AdaBoost算法进行分类预测;最后,使用十折交叉验证法,计算改进模型的分类准确率和稳定性,并将其与其他模型进行比较。
1 算法介绍
1.1 AdaBoost-DT算法
决策树是一种树型结构,将一组输入样本根据其属性特征划分为几个更小的集合。本文选择决策树作为基分类器,主要有以下三点原因:首先,该分类器表现形式直观,所得到的分类模型更易于解释说明;其次,不同于统计模型,决策树在数据分布方面所要求的假设更少[16];最后,与其他分类技术相比,决策树的构建速度相对较快。
AdaBoost[17]算法是经典的Boosting算法,通过对弱分类器的集成来实现更好的预测效果。其基本思想是:首先,如果有N个样本,则每个训练样本赋予相同的权重1/N;其次,在训练过程中,如果某个样本训练失败,则赋予较大的权重,下次迭代时让分类器将重点学习该分类错误的样本,而对于准确分类的样本,则降低其权重,从而得到新的样本分布;最后,将新的样本集用于训练下一个分类器,整个训练过程以此方式迭代,将循环后所有弱分类器组合得到最终的强分类器。AdaBoost算法流程如图1。
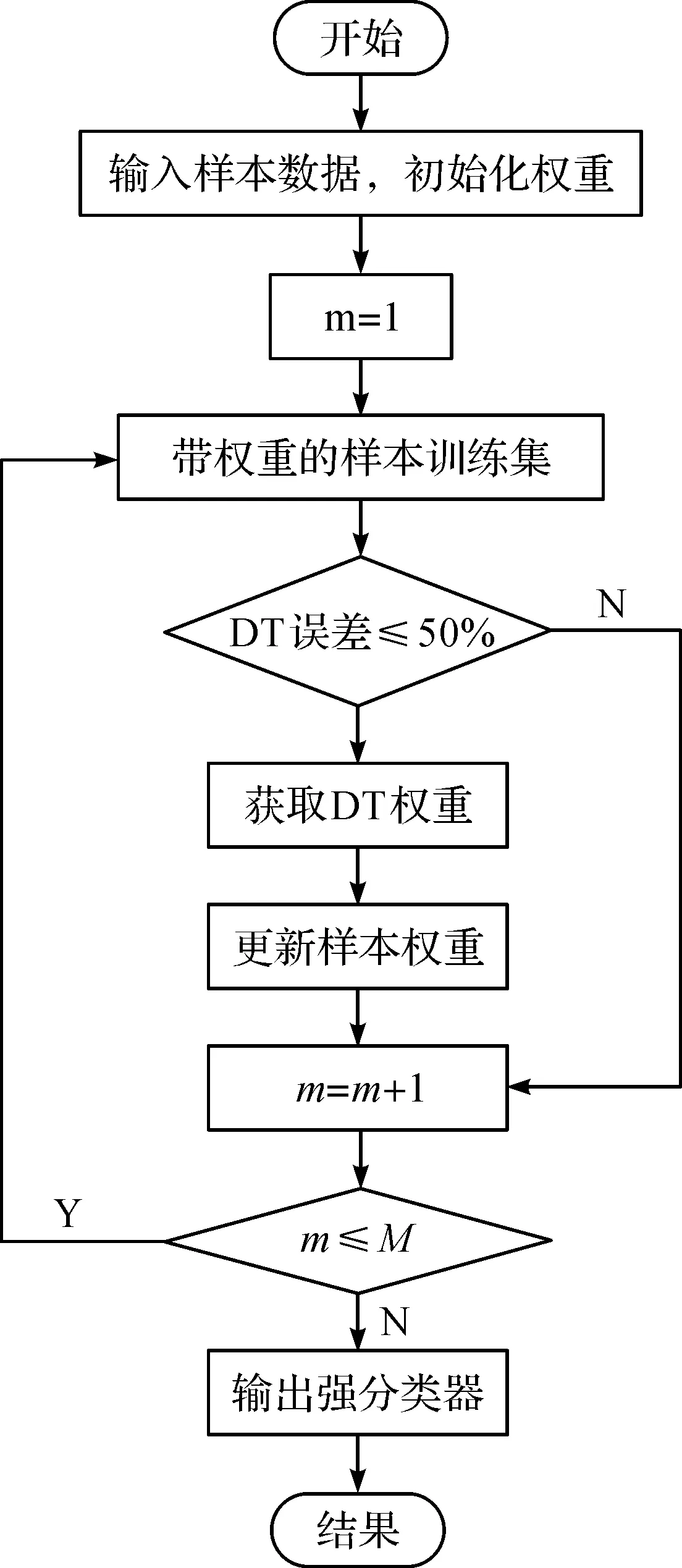
图1 AdaBoost流程图Figure 1 AdaBoost flowchart
1.2 SMOTE-AdaBoost-DT算法
SMOTE-AdaBoost-DT算法作为融合重采样与分类算法的方法,使得训练得出的模型具有更强的多元性和鲁棒性。该模型首先采用合成少数类过采样技术(SMOTE)方法生成少数类样本,使得正负类样本数达到平衡,再使用以DT为基分类器的AdaBoost算法在新样本中进行学习。
算法训练过程如下。
输入:训练样本集S={(X1,Y1),(X2,Y2),…,(Xi,Yi)},i=1,2,…,n,Yi∈{0,1},M为迭代次数,H为基分类器。
1) 使用SMOTE生成少数类样本集。
2) 初始化训练数据中每个样本的权值分布。
3) 进行M次迭代。
(a) 将拥有权值分布Hm的训练样本集进行学习,得到弱分类器Hm(x):χ→{-1,+1}。
(b) 计算分类误差率em,若em大于50%,则舍弃该弱分类器。
(1)
(c) 计算弱分类器在最终分类器中的权重;
(2)
(d) 更新训练样本集的权值分布,用于下一轮迭代;
(3)

4) 组合弱分类器,输出强分类器
(4)
2 实验结果与分析
2.1 实验数据与设计
为验证模型的有效性,实验选用Kaggle平台提供的公开数据集中的客户信用数据。将Status中两月及以上逾期未还贷款的客户定义为违约样本(正样本),其余为履约样本(负样本),其中正样本数为422,负样本数为24 712,不平衡比为1∶58。除还款状态外,每条记录还包含17个属性,如表1。

表1 样本属性Table 1 Sample features
为了验证本文算法在信用评分领域的有效性,将它与传统经典的不平衡分类算法进行比较。首先将自适应增强-决策树(AdaBoost-DT)、随机过采样-自适应增强-决策树(random over sampling-AdaBoost-DT,ROS-AdaBoost-DT)、最近邻规则-自适应增强-决策树(edited nearest neighbor-AdaBoost-DT,ENN-AdaB oost-DT)、合成少数类过采样技术-自适应增强-决策树(SMOTE-AdaBoost-DT)进行对比,证明SMOTE作为数据采样方法的有效性;再将本文算法与DT、随机森林、合成少数类过采样技术-神经网络(SMOTE-BP)进行对比,以AUC和G-mean为评价标准,验证该集成方法的有效性。
2.2 评价指标
目前,多数研究将分类正确率[18](accuracy,ACC)作为二分类问题的评价指标。ACC是以整体最优为目标,对少数类的识别性能不佳,然而在信贷领域,相较于多数类,对少数类样本的有效识别更有实际意义。因此,为了更好地评价该模型的准确性,本文采用几何平均准则(G-means metric)和ROC曲线下面积(AUC)作为评价指标。以上评价指标大多采用混淆矩阵(表2)表示。其中,TP表示正类样本预测仍为正类,TN表示负类样本预测仍为负类,FP表示负类样本误分为正类,FN表示正类样本误分为负类。

表2 混淆矩阵Table 2 Confusion matrix
1) G-mean值
(5)
G-mean以正类样本分类准确率和负类样本分类准确率为基准,能更好地衡量分类方法在不平衡数据集上的综合性能,其取值范围为[0,1]。G-mean值越大,模型的综合性能越好。只有当正类样本和负类样本的准确率均较高时,G-mean值才会大。
2) AUC
AUC是指ROC曲线与坐标轴围成的区域面积,ROC曲线是以假阳率为横坐标,真阳率为纵坐标绘制的曲线,刻画出不同参数变化情况下假阳率和真阳率的变化情况。曲线越靠近左上角表示分类器性能越好。通常AUC的值越高说明分类器的性能越好。
2.3 实验结果分析
实验采用十折交叉验证法,将数据集平均分成10份,训练集与测试集的比例为1∶9,最终以平均值作为对分类算法精度的估计。本文将从准确性和稳定性两方面对模型进行评估,并将其与其他传统方法进行对比分析。
2.3.1 模型准确性分析
经十折交叉验证,七种模型的分类准确性结果如表3。

表3 各类算法性能对比Table 3 Performance comparison of variousalgorithms
实验结果表明,SMOTE-AdaBoost-DT算法在不平衡数据集中的效果最佳。从表3可以看出SMOTE作为采样方法最优。对比没有重采样的AdaBoost-DT,AUC值提高了30.12%,G-mean值提高了18.87%。对比ROS方法AUC值提高了53.19%,G-mean值提高了53.08%。对比ENN方法AUC值提高了22.48%,G-mean值提高了22.38%。
在分类模型比较中,就AUC值而言,本文提出的算法均值都大于DT,随机森林和SMOTE-BP算法,因此本文模型的分类预测效果优于其他三个模型。一般而言,AUC值越接近1,模型分类性能越好,本文提出的算法AUC值达到0.89,具有较优性能。
G-mean值用于衡量正类样本和负类样本预测的准确率,G-mean值越高说明两者的预测越准确。本文模型的G-mean值为0.89,表明本文模型不仅能够有效判别出信用良好的客户,也能较为准确地判别出信用不良的客户,并能充分保持两者的分类平衡。
综上所述,SMOTE-AdaBoost-DT模型在不平衡数据分类中的客户信用评估,具有更高准确性。
2.3.2 模型稳定性分析
为进一步验证本文算法的稳定性,计算SMOTE-AdaBoost-DT与其他所有对比方法的标准差,获取分类结果的离散程度。
根据表4可以发现,在采样方法对比中,SMOTE-AdaBoost-DT模型的AUC、G-mean的标准差均小于其他采样方法。其中,没有重采样方法的AdaBoost-DT标准差最大,意味着稳定性也是最差的,也进一步说明了不平衡数据集中重采样方法的重要性。
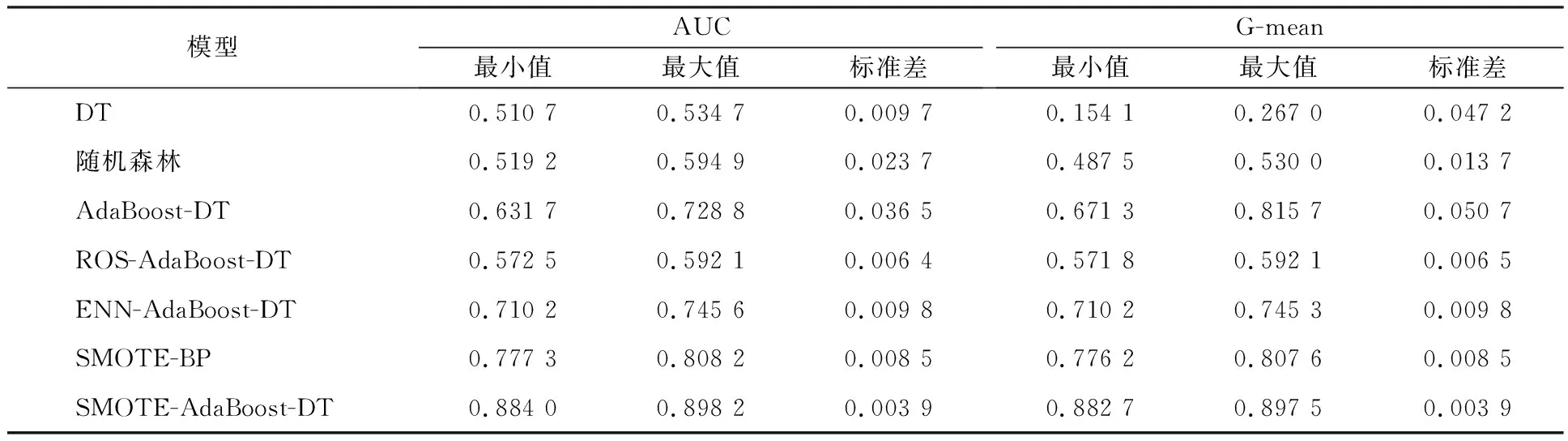
表4 七种模型稳定性对比Table 4 Comparison of the stability of seven models
在于DT、随机森林和SMOTE-BP分类方法的对比中可以看出,SMOTE-AdaBoost-DT模型的AUC、G-mean的标准差也是最小的。这表明本文模型在不平衡数据的分类方面具有较好的稳定性。
3 结 语
当前金融业与大数据技术深度融合,国内外领先的金融机构已将机器学习应用到客户的信用评分系统中。为提高信用评分的准确率和稳定性,本文提出一种针对不平衡大数据的SMOTE-AdaBoost-DT信用评分模型。针对单一分类器泛化能力不足的问题,模型采用以DT为基分类器的AdaBoost集成算法;同时,针对信贷领域中的样本类别不平衡问题,采用SMOTE过采样方法增加少数类样本,使样本数据达到平衡。实验结果表明SMOTE-AdaBoost-DT模型比DT、随机森林、AdaBoost-DT、ROS-AdaBoost-DT、ENN-AdaBoost-DT、SMOTE-BP具有更高的准确性和稳定性。本文提出的信用评分模型将帮助金融机构提高客户信用评分的准确率,进而降低违约贷款率。
本文提出的信用评分模型仅针对数据的不平衡特征,尚未考虑到数据的高维特征。传统的分类方法虽然能在低维数据中获得良好的分类结果,但不一定适合高维数据。未来研究有必要提出针对高维、不平衡数据的分类模型,以提高分类模型在实际应用中的普适性和价值。
猜你喜欢
公民与法治(2020年20期)2020-11-27
成都信息工程大学学报(2019年3期)2019-09-25
中国外汇(2019年9期)2019-07-13
电子制作(2018年16期)2018-09-26
计算机应用(2017年4期)2017-06-27
中国设备工程(2017年7期)2017-04-10
瞭望东方周刊(2016年45期)2016-12-07
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
