
基于K-means算法实现电商企业ERP系统的大客户跟踪分析
2021-02-19 05:28戴远泉
现代信息科技 2021年13期




摘 要:RFM模型是客户价值细分的一种方法和手段,在不同领域的应用中会有一定的差异性。阐述了客户价值分析的分析方法和分析过程,分析了影响奢侈品电商企业客户购买行为的重要因素,构建了一种改进的RFM模型为RFMLC模型,阐述了使用RFMLC模型实现大客户跟踪分析过程。该系统在业务运行中表明有一定的使用价值,对开发企业客户价值分析系统有一定的参考价值和借鉴作用。
关键词:RFM模型;客户活跃度;消费能力;K-means算法
中图分类号:TP18;TP391 文献标识码:A文章编号:2096-4706(2021)13-0173-03
To Achieve Key Customer Tracking Analysis of E-commerce Enterprise ERP System Based on K-means Algorithm
DAI Yuanquan
(School of Information Engineering, Hubei Light Industry Technology Institute, Wuhan 430070, China)
Abstract: RFM model is a method and means of customer value segmentation, and there will be some differences in the application of different fields. This paper expounds the analysis method and analysis process of customer value analysis, analyzes the important factors affecting the customer purchase behavior of luxury E-commerce enterprises, constructs an improved RFM model as RFMLC model, and expounds the implementation of key customer tracking analysis process by using RFMLC model. The system has certain use value in business operation, and has certain reference value and function for developing enterprise customer value analysis system.
Keywords: RFM model; customer activity; consumption capacity; K-means algorithm
0 引 言
某奢侈品经销企业主要通过天猫、淘宝、京东等第三方平台销售商品,同时,也通过拼多多、云集、短视频平台、微信销售商品,甚至还通过线下实体店销售商品。该电商企业销售渠道复杂,货源来源广,客户分布广而且构成复杂,需要整合各种资源,开发电商企业的ERP系统。ERP系统中的大客户跟踪管理显得尤为重要。电商企业需要针对不同类型客户,进行精准营销,实现利润最大化,建立合理的客户价值评估模型,进行客户分类,是解决问题的关键。
1 分析方法與过程
该电商企业ERP系统中的大客户跟踪分析的目标是首先根据客户的相关数据,对客户进行聚类分析,然后衡量客户价值,识别出大客户,再针对大客户制定个性化的沟通和营销服务。
1.1 分析方法
RFM模型[1]是进行客户价值分析的一种方法。该方法是基于三个指标即R、F和M。其指标体系如表1所示。
应用这些信息能够预测客户的购买行为[2]。若采用传统RFM模型分析,其缺点是细分客户群太多,导致难以形成对每个客户群的准确把握,精准营销成本太高。另外,由于RFM分析指标中的购买次数与同期总购买金额存在多重共线性,即一个给定客户每多购买一次,总价值也相应增加,这就降低了RFM分析的有效性[3]。实际应用中还需考虑其他指标。
客户忠诚度是指客户对某一特定产品或服务、品牌、商家有较强的好感,并形成了偏好,进而重复购买的一种情感与态度趋向[4]。通过企业组织的各种活动可以深入了解客户,主动把握客户的需求,最终实现客户的忠诚度的提升。客户若能很积极参与公司活动,在一定程度上表明该客户的忠诚度高。因此选定指标活跃度Liveness,计作L。
客户的消费能力决定着成交的金额,也可以缩短咨询时间,更决定着这个单是否成交[5]。针对不同客户的消费能力制定销售方法,有针对性的销售方式可以大大增加产品销售的成功率。因此选定指标消费能力consumption capacity,计作C。
基于以上分析,本案例中,作为电商企业识别客户价值指标,记为RFMLC模型。
1.2 分析过程
某电商企业ERP系统中的大客户跟踪分析的分析过程如图1所示。
主要包括以下几个步骤:
(1)ERP系统中的业务生产的数据存于关系数据库、非结构化数据以及档案文件中。从数据源中抽取数据,包括选择性抽取与新增数据抽取,形成历史数据和增量数据。
(2)进行数据处理,主要是缺失值与异常分析、数据清洗、数据的属性规约和数据标准化处理。
(3)分析客户购买行为的影响因素,进行建模,构建RFMLC模型。
(4)编码实现,采用K-means算法进行客户分群,进行聚类分析、分类分析和关联规则分析,识别有价值客户。
(5)针对模型结果得到不同价值的客户,采用不同的营销手段,提供定制化的营销服务,设计针对性的优惠与关怀。
2 实现过程
2.1 抽取数据
一般原始数据通常包含很多字段,最为关心的就是3个字段:客户编号、购买时间、购买金额。
R=当前日期-最近一次购买日期,转换为天数。
F=给定时间内购买次数综合
M=给定时间内购买金额总和
L=给定时间内参加公司活动的次数,从ERP的子系统“客户关怀”数据库表中统计。
C值计算较为复杂。电商上的交易数据,“最低消费金额”“最高消费金额”“平均每次购买消费金额”,通过这几个指标来计算出一个值,表示一个消费者的消费能力强弱。即为C值。本案例中,采用PERT分析模型的三点估算法。即:
期望消费金额=(最高消费金额+4×平均消费金额
+最低消费金额)/6
2.2 数据处理
首先数据清洗。对数据进行初步加工,因为数据源中很多脏数据,会影响我们的分析结果,需要先将其筛选出去,比如一些空值、异常值、特殊文本显示等等。主要对数据进行缺失值和异常值分析。查找每列属性观测值中空值、0值、最大值、最小值,丢弃数据项为NULL的记录,丢弃F、M、C值为0的记录。得到如表2所示的样本数据。
然后,规约属性。在RFMLC模型中,R值为最近一次购买距离当前日期的间隔,转换为天数。理论上R值越小的客户是价值越高的客户,与F、M等指标是负相关性。在进行分析计算是采用1/R的倒数的形式。
再进行数据标准化处理。数据标准化最典型的就是数据的归一化,即将数据统一映射到[0,1]区间上。本案例采用z-score法。
z-score标准化是将原始数据x的均值(mean)、标准差(standard deviation)使用z-score标准化到y。这种方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况[6]。
2.3 编码实现
本案例使用Java语言编写,采用K-means算法。K-means作为一种无监督聚類算法在各种业务场景中得到较为普及的运用。K-means是将给定数据集中的数据使用其不同特征进行聚类的算法模型,将数据集分为K个不同的簇,且每个簇的聚类核心点采用簇中所含值的平均值计算而来[7]。
编写方法为getClustering(DataArraydataArray,int k),实现K-means的聚类,聚类后的数据存于ClusterArray中,代码具体为:
/**运行k-means算法进行聚类*/
public ClusterArraygetClustering(DataArraydataArray, int k) {
ClusterArrayclusterArray = new ClusterA();
dataArray.clearIsAllocated(); //清除数据分配
//创建初始的簇
clusterArray.add(createClusterWithRandomlySelectedDataPoint(dataArray));
//如果簇没达到所定义的簇数量,则创建新簇
while (clusterArray.size() < k) {
clusterArray.add(createClusterBasedFurthestData(dataArray, clusterArray));
}
//开始迭代
int i=0;
for (; i<clusteringIterations; i++) {
//基于质心和数据点的距离,分配没有分配的数据
assignUnallocatedDataPoints(dataArray, clusterArray);
//更新质心,取每个簇所有数据点的各维度的均值
clusterArray.updateCentroids();
if (i<clusteringIterations - 1) {
//清空簇,重新迭代
clusterArray.clear();
}
}
return clusterArray;
}
其中DataArray 为产生的数据,K聚类个数。簇的个数K是手动指定的,每一个簇经过其聚类核心点(即簇中所有点的中心)来描述。本例中K为5,如表3所示。
3 模型应用
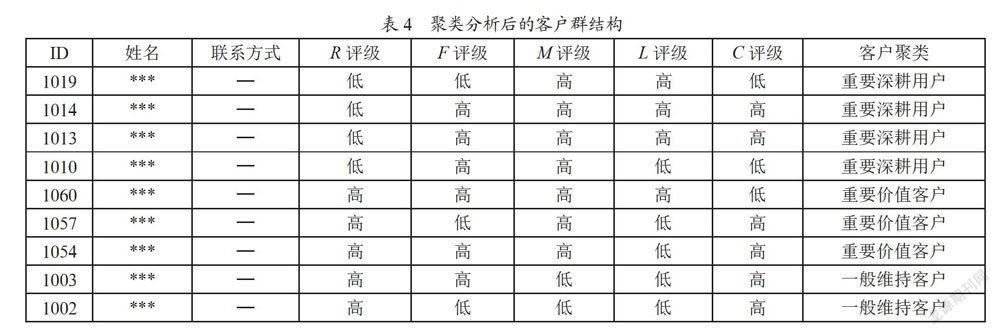
根据聚类分析得到的客户群结构如表4所示。
针对不同的客户,实施客户关怀和营销方案。对重要价值客户进行提醒或促销活动,提高客户满意度;对重要深耕客户实施客户跟踪分析;对重要挽留客户从公司的活动入手。
4 结 论
RFM模型是测算消费者价值最重要也是最容易的方法,这充分的表现了这三个指标对营销活动的指导意义。但在奢侈品行业的电商企业中,业务方除了消费金额、频次以外,还会考虑客户的跨场景使用,客户的活跃度和消费能力是主要的影响因子。本案例中改进了RFM模型,采用K-Means算法对客户数据进行客户分群,聚成五类,在实际开发中得到了应用,并且效果较好。
参考文献:
[1] 林盛,肖旭.基于RFM的电信客户市场细分方法 [J].哈尔滨工业大学学报,2006(5):758-760.
[2] 杨玉梅.基于信息熵改进的K-means动态聚类算法 [J].重庆邮电大学学报(自然科学版),2016,28(2):254-259.
[3] 蒲晓川,黄俊丽,祁宁,等.基于密度信息熵的K-Means算法在客户细分中的应用 [J].吉林大学学报(理学版),2021,59(5):1245-1251.
[4] 陈新华.基于K-Means改进的算法在客户聚类中的应用 [J].信息通信,2020(9):35-37.
[5] 乔文瑄,杨小勇.平台经济下消费力的发展及其提升研究 [J].消费经济,2021,37(3):12-19.
[6] 姜朋,李挺.基于大数据的航空客户价值分析 [J].民航学报,2019,3(3):1-4.
[7] 马培梁.基于K-means算法的数据挖掘与客户细分研究 [J].市场研究,2019(11):66-67.
作者简介:戴远泉(1965—),男,汉族,湖北黄梅人,副教授,硕士研究生,研究方向:软件开发、大数据应用开发。
