
基于深度学习的中文零代词识别
2021-02-22 04:00王立凯曲维光魏庭新周俊生顾彦慧
南京师范大学学报(工程技术版) 2021年4期
王立凯,曲维光,,魏庭新,周俊生,顾彦慧,李 斌
(1.南京师范大学计算机与电子信息学院,江苏 南京 210023) (2.南京师范大学文学院,江苏 南京 210097) (3.南京师范大学国际文化教育学院,江苏 南京 210097)
零指代是语言学中一种特殊的语言现象,是指为了保证语言的连贯性而省略的、且可通过上下文推断出的语言单元. 该省略的语言单元在句子中承担相应的句法成分,可以和前文中一个或多个名词短语等语言单元构成指代关系. 这种被省略的语言单元称为零代词,前文中与其构成指代关系的语言单元被称为先行语.
例句1虽然[卓伟]的新闻装备落后,但Ф1说起娱乐新闻观念,Ф2却比许多年轻同事更自由,更激进.
例句1中,Ф2就是一个零代词,指向前文中的人名“卓伟”. 但Ф1就不是一个零代词,前文中没有语言单元与其构成指代关系. 因此,零代词的两个必要条件是:(1)句中存在句法成分缺省;(2)前文中有语言单元与其构成指代关系. 与英文相比,汉语是一种意合型语言,其特点是形态不完整,这使得汉语中存在大量的缺省. 据Kim[1]统计,汉语中存在句法成分省略的现象高达36%,而英文中的省略现象则不超过4%,所以零指代的识别与消解对于中文信息处理来说显得更加迫切和重要.
中文零指代通常可分为两个子任务,一是零代词的识别,二是零代词的消解. 目前的研究工作多数聚焦于消解部分,并取得了丰硕成果[2-4],而零代词的识别研究相对较少. 零代词识别是指识别出句子中有回指的缺省语言单元的位置,是零指代消解必要的前期基础. 在早期的零代词识别研究中,主要是利用规则的方法去识别零代词[5],缺点是难以制定较为全面的规则且可泛化性差. 也有一些学者如Zhao[6]、Kong[7]等利用传统机器学习方法去识别中文零代词,但仍受限于特征模板和专家知识,忽略了语义特征对于识别零代词的重要作用. Zhao等[6]第一次使用了基于机器学习的方法进行中文零代词的识别与消解. 实验过程中,在识别阶段使用了13个特征,在消解阶段使用了多达26个特征. Kong等[7]提出了一个基于树核支持向量机的统一中文零指代消解框架,该框架包含3个部分,分别为候选零代词的生成、回指零代词的识别和消解. Chen等[8]也提及了其使用的基于规则的零代词识别方法来作为消解工作的铺垫,并在之前研究的基础上丰富了零代词特征,利用SVMlight算法取得了当时最好的效果[9]. 也有学者如Liu等[10]提出利用GRU网络去学习词向量中蕴含的语义信息,但忽视了句子中不同词语所蕴含的语义信息是不同的,同时也忽视了句法结构信息在识别过程中的重要作用. Kong等[11]在使用共指链信息进行零代词识别和消解时,将零指代识别分为两个步骤:零代词候选位置生成和零代词识别,在生成零代词候选位置时使用了句法信息,在识别时则利用词汇、句法和语义特征构造了一个分类器. Song等[12]则使用多任务学习方法,同时使用BERT进行编码,对零代词识别和消解进行联合学习,但由于错误传递,效果不尽如人意,联合模型F1值均低于40%.
本文为解决上述问题、提升零代词识别效果,提出了一种基于深度神经网络的回指零代词识别方法,首先利用注意力机制去捕获零代词上下文的语义信息,对蕴含更多语义信息的词语分配更高的权重,同时利用Tree-LSTM去挖掘句法结构信息,最后通过两者的融合特征识别零代词. 相比于传统识别方法需要建立繁琐的规则体系或特征模板、泛化性差等缺点,本文通过深度神经网络从输入文本中抽取抽象特征信息来识别零代词,降低了模型对繁琐的手工特征和专家知识的依赖. 在OntoNotes5.0中文语料上的实验结果证明,该方法有效提升了中文零代词的识别效果.
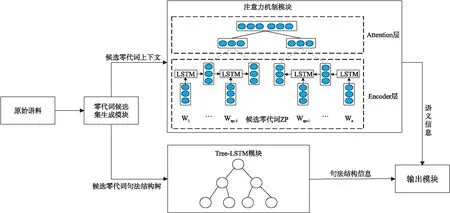
图1 中文零代词识别整体框架图Fig.1 Framework of Chinese zero pronoun recognition
1 模型
1.1 模型概述
本文的整体模型框架如图1所示,主要由4个部分组成:零代词候选集合的生成模块、注意力机制模块、Tree-LSTM模块和输出模块. 首先,通过事先制定的句法规则从原始语料中筛选出零代词的候选集合. 由于零代词在文本中缺省,无法直接获取零代词的词向量,本文通过两种方式间接对其进行特征表示:一是通过注意力机制模块,包含Encoder层和Attention层,Encoder层对零代词的上下文进行前向后向的LSTM编码,得到其上下文的隐藏层表示,再利用Attention层捕获其深层语义信息;二是通过Tree-LSTM模块挖掘其句法结构信息. 最后,将两者的融合特征送入输出层,得到分类结果.
1.2 零代词候选集合生成模块
零指代识别和消解任务常采用OntoNotes5.0语料[13]数据集,本文亦采用该语料. 由于OntoNotes5.0语料只标记了主语位置的零代词,故本文研究只考虑主语位置零代词的情况. 现代汉语中,主语位置零代词总是出现在谓词短语节点(VP)之前,而谓词短语是由一个或一个以上动词短语构成,由此,对于句法树中的节点T,若同时满足以下3条句法规则,则节点T的左边相邻位置是零代词的候选位置:
(1)T节点属于VP节点;
(2)T节点的父亲节点不属于VP节点;
(3)T节点的左兄弟节点不属于NP节点,或者T节点没有左兄弟节点.
例句2建筑是开发浦东的一项主要经济活动,这些年有数百家建筑公司,四千余个建筑工地遍布在这片热土.
如图2所示,例句2中,根据上文所制定的规则,节点(VP(VV(开发)NP(NR(浦东))))的当点节点为VP节点,其父亲节点为IP节点,且无左兄弟节点,因此判定其为一个零代词候选位置,但实际上该位置并不存在零代词,因为其不满足回指前文中语言单元的条件. 而树中“这些年有数百家公司”的句首位置也满足规则,同时回指前文中的“浦东”,因此该候选位置存在一个零代词.
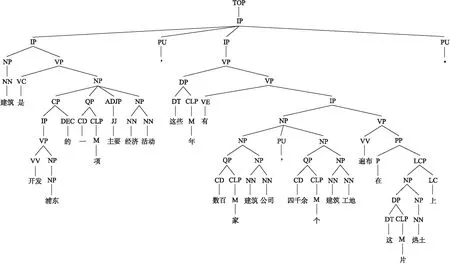
图2 例句2句法分析树Fig.2 Syntactic parsing tree of sentence 2
1.3 注意力机制模块
1.3.1 Encoder层
通过零代词候选集合生成模块的筛选,获取了零代词候选集合ZPS,对于候选集合中的每一个候选零代词zp,其上下文可表示为:
Contextprecedding=(x1,x2,…,xzp-1),
(1)
Contextfollowing=(xzp+1,xzp+2,…,xn).
(2)
式中,xi=[wi;pi],wi表示第i个词语的词向量,pi表示其词性向量,xi为wi和pi的拼接. 为了获取其上下文信息,本文采用LSTM网络对两个序列Contextprecedding和Contextfollowing分别进行编码. LSTM的公式如下所示:
it=σ(W(i)·[xt;ht-1]+b(i)),
(3)
ft=σ(W(f)·[xt;ht-1]+b(f)),
(4)
ot=σ(W(o)·[xt;ht-1]+b(o)),
(5)
(6)
(7)
ht=ot·tanh(Ct).
(8)
式中,·代表元素乘法,W(i),b(i),W(f),b(f),W(o),b(o),W(c)和b(c)代表LSTM网络的参数.
本文将零代词的上下文通过LSTM网络进行编码:
(9)
(10)
式中,LSTMpre和LSTMfol分别代表一个前向的LSTM网络和一个后向的LSTM网络. 可得零代词上下文中每一个词语的隐藏层表示:
(11)
(12)
1.3.2Attention层
由于零代词在文章中是缺省的,在以往的研究中,虽然学者们使用了许多方法去表示零代词,但仍存在无法获取部分关键语义信息等问题. 本文采用注意力机制去编码零代词的语义信息.
由于在Encoder层已经获得了零代词上下文的隐藏层表示Hpre和Hfol,接下来需将Hpre和Hfol作为注意力机制的输入,并计算权重:
(13)
(14)
式中,W1是一个a×u的参数矩阵,W2为r×a的参数矩阵,u代表零代词上下文隐藏层输出的维度,r代表选择的注意力机制层数.
通过该方法即可得到一个多层的权重矩阵A,与单层的注意力机制权重矩阵相比,多层注意力机制使得模型可从不同的角度关注句子的不同部分,可更高效地从语义角度对零代词进行句子级信息的建模. 当得到权重矩阵A后,将得到的r层权重与零代词的上下文隐藏层输出H作加权求和:
Mpre=Apre·Hpre,
(15)
Mfol=Afol·Hfol.
(16)
而后将每个矩阵(即Mpre和Mfol)的行向量取平均得到零代词的上文表示和下文表示,将两个表示向量做拼接得到零代词的语义表示向量. 通过注意力机制学习上下文中不同词对表示零代词语义信息的重要程度,完成注意力权重的分配,可更好地从语义角度对零代词进行表示.
1.4 Tree-LSTM模块
Kong等[7]指出,句法结构信息对于中文零代词的识别具有重要的作用. 本节通过Tree-LSTM[14]对零代词的成分句法树进行编码,从结构化句法信息的角度对零代词进行更好地表示. 传统的LSTM模型在每个时间步都是将当前时间步的词语信息和上一个时间步的输出信息作为输入,更新当前时间步的记忆单元和隐藏层状态. 在Tree-LSTM中,树中每个节点的输入为当前节点的词语信息和其孩子节点的输出信息,而不只考虑前一步的信息. 给定一个成分句法树,对于节点j,Tree-LSTM的具体公式如下:
(17)
(18)
(19)
(20)
(21)
hj=oj·tanh(cj).
(22)
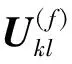
(1)保留句法树根节点到零代词出现位置动词短语节点的路径,并保留此路径上直接相连的名词短语节点和动词短语节点;
(2)保留零代词出现位置前一个动词短语节点和零代词出现位置动词短语之间的句法树;
(3)对于动词短语节点的子树,只保留那些以动词和名词为叶节点的路径.
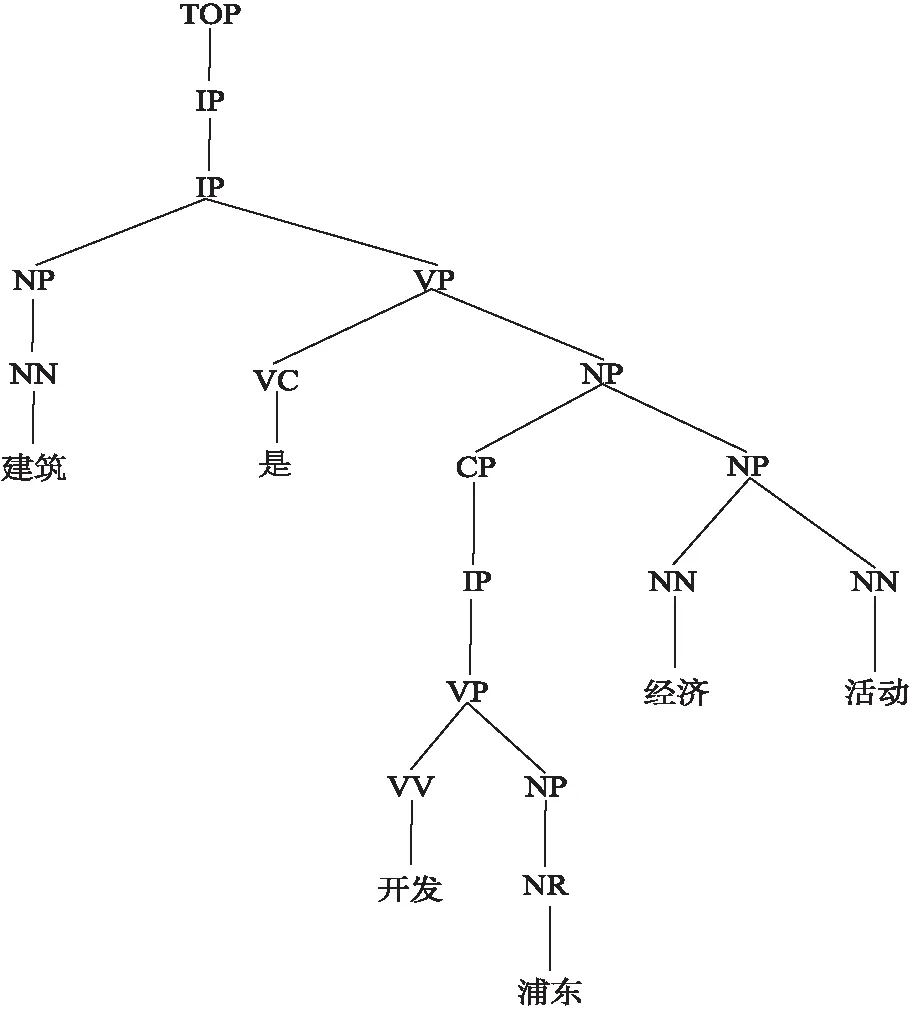
图3 候选零代词的裁剪句法树Fig.3 Pruned syntactic tree of candidate zero pronoun
对图2句法树中“开发浦东”前的候选零代词进行裁剪后的句法树结构如图3所示.
1.5 输出模块
通过注意力机制模块和Tree-LSTM模块分别获取候选零代词语义层次和句法层次的表示后,本文将其送入一个两层前馈神经网络中,判断其是否为一个零代词. 计算公式如下:
va=[avg(Mpre);avg(Mfol)],
(23)
s1=tanh(W1·[va;hpre;hfol;vt;vfea]+b1),
(24)
s2=tanh(W2·s1+b2).
(25)
式中,va表示注意力机制模块中Attention层所得矩阵Mpre和Mfol行向量取平均的拼接向量;hpre和hfol分别表示注意力机制模块中Encoder层中LSTM前向和后向的最终隐层状态;vt表示零代词句法裁剪树经过Tree-LSTM模块编码后的输出向量;vfea为候选零代词句法结构、位置等手工构建的特征信息所组成的数值向量,具体特征描述与文献[3]中一致;W1,b1,W2,b2分别代表两层前馈神经网络的参数;s1和s2分别代表两层前馈神经网络的输出.
最后,将其输出送入softmax层得到最终的分类概率为:
P=softmax(Wsoft·s2+bsoft),
(26)
式中,P表示候选零代词是回指零代词的概率;s2为前两层隐藏层的输出.
1.6 损失函数
本文采用交叉熵作为模型训练的目标函数. 损失函数的公式为:
(27)
式中,Z为零代词候选集;pi(z)表示通过本文模型的候选零代词z属于类别i的概率;yi(z)为候选零代词z的标签.
2 实验
2.1 评测指标
与早期关于中文零指代任务的研究相似,本文通过召回率(Recall)、精确率(Precision)和F值(F-score)来评估本文的模型,其中Recall和Precision定义为:
(28)
(29)
(30)
式中,AZPright表示本文模型预测正确的零代词;AZPres表示本文模型预测为正确的所有零代词;AZPgold表示语料中标注的所有零代词.
2.2 数据集

表1 OntoNotes5.0数据集统计Table 1 Statistics of the OntoNotes 5.0 dataset
实验数据选择CoNLL-2012共享任务中的OntoNotes5.0数据集[13],仅选用其中中文部分. 中文部分数据集只有在训练集和验证集上才有零代词的标注,在测试集上未作标记. 本文参照以往中文零指代文献中的做法,将模型在训练集上进行训练,在验证集上进行评测. OntoNotes5.0中文数据集主要包含6种类别,分别为广播会话、广播新闻、杂志、通讯新闻、电话对话和博客文章. 数据集的具体统计数据如表1所示.
2.3 参数设置
由于实验缺少验证集,本文从训练语料中切分了约20%的数据作为验证集,用以调整超参数. 具体参数设置如表2所示.

表2 实验超参数设置Table 2 Parameter setting of the experiments
在实验过程中发现,由于训练集正负样本不平衡(正负比例约为1∶3),导致实验效果下降. 因此,本文通过复制正例样本来平衡训练集中正负样本的比例. 经测试,最终选择将正例样本复制3次,模型达到了最优的效果.
本文将模型初始迭代次数设置为50. 图4所示为本文模型在验证集上的学习曲线,可以观察到模型在第一个epoch时,验证数据集上的F1-score约为56%,随着迭代次数的增加,F1-score值不断增加. 在第11次迭代时,模型在验证集上的性能达到最优. 之后,本文模型的F1-score开始下降. 因此本文保存验证集上效果最优的模型参数,在测试集上进行评价.
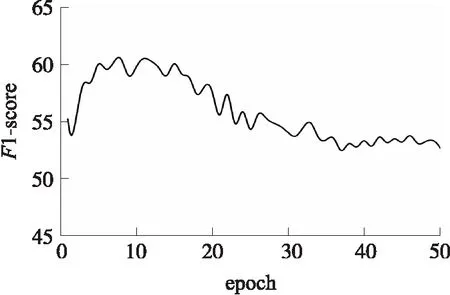
图4 模型在验证数据集上的学习曲线Fig.4 Learning curve of the model on the validation dataset

图5 r值对零代词识别的影响Fig.5 Effect of r value on zero pronoun recognition
此外,本文希望多层次的句子级信息可以为表示零代词提供丰富的语义信息,因而通过改变注意力机制层的r值,来评估不同的r值对于中文零代词识别的影响. 当r=16的时候,模型达到最优值,如图5所示. 本文通过注意力机制将模型关注的重点放在对编码零代词更加有用的部分,将句子以零代词为中心分成两个部分,当r=16时,说明本文的模型分别从16个不同的角度去编码前半部分和后半部分的语义信息,因而能够达到较好的结果.
2.4 实验结果与分析
表3所示为本文模型和近年中文零代词识别任务在OntoNotes5.0中文语料上的实验结果的对比,前 4行为以往对于中文零代词识别任务的实验结果,后两行为本文的实验结果. 可以看出,本文模型比以往最优模型的F值要高出1.4%,加入Bert预训练词向量后的F值更是高出了3.6%.

表3 不同模型实验结果对比Table 3 Comparison of experimental results of different models
从精确率来看,本文模型在未加入Bert之前比表中Chen and Ng(2013)和(2016)的模型分别低了5.2%和0.2%. 分析发现,这两个模型均采用传统机器学习的方法. 中文零代词具有较强的规则性,制定合适的特征模板会对中文零代词识别的精确率具有较好的正向作用. 从召回率来看,本文的模型无论是加Bert之前还是之后,均优于以往的中文零代词识别模型.
由于近期Bert模型在各大任务上均取得了较好的成果,本文也尝试了在现有模型上加入Bert预训练模型,主要是利用Bert的encoder层输出去增强本文模型中的词向量表示. 由于Bert的pytorch版本目前尚只能做字符级编码,本文对中文词语中每个字符的向量表示做了均值操作,以此来代替词级向量. 本文并未对Bert网络进行微调,仅将Bert网络的输出作为特征. 实验表明,加入Bert后模型在OntoNote5.0中文语料上的F值、准确率和召回率分别为63.7%、54.6%和76.4%,F值比原始模型高出了2.2%,精确率上升了4.7%,但召回率下降了3.8%.
2.5 模块分析
表4所示为本文中各个模块在模型中所起的作用.

表4 各模块在实验中的作用对比Table 4 Comparison of experimental results with different modules
如表4所示,Rules-based表示本文零代词候选集生成模块所生成零代词候选集的实验效果. 在本文的规则下,回指零代词的召回率很高,达到99.1%,但是精确率较低,只有24.2%. 因为本文主要是利用规则去生成零代词的候选集合,对召回率的要求更高.
Rules+Tree-LSTM表示本文模型去除注意力机制模块之后的实验结果,其F值为60.2%,精确率为46.7%,召回率为84.7%. 由于成分句法树的成分缺省具有较强的规律性,通过Tree-LSTM对成分句法树的学习,理论上可以找回绝大多数零代词的缺省位置. 但因语义信息的不足,对判断其是否回指存在不足.
Rules+Attention表示本文模型去除Tree-LSTM之后的实验结果,其F值为57.5%,精确率为47.2%,召回率为73.6%. 相比于Rules+Tree-LSTM,准确率略高,而召回率大幅下降,这主要是因为句法结构信息的缺失导致无法准确识别出句子中成分缺省.
Rules+Zpcenter表示同时去除Tree-LSTM模块和注意力机制模块之后的实验结果,其F值为56.8%,准确率为45.4%,召回率为76.0%.F值的再次降低证明了本文注意力机制和Tree-LSTM的有效性.

表5 与先行词不在同一句内的零代词数量统计Table 5 Statistics of zero pronouns that are not in same sentence with antecedants
2.6 错误分析
对模型输出的错误结果进行分析(例如句3)分析发现,零代词回指的名词短语虽大部分都在同一句话内,但也有部分零代词所回指的名词短语是在之前句子中出现的,表5给出了相关的统计数据. 本文的模型主要是在单句内进行,与前文中的句子并无联系.
例句3本届锦标赛到今天为止,已决出7枚金牌. *pro*明天将进行最后5个男女单项的决赛.
在例句3中,零代词“pro”回指前一句话中的名词短语“本届竞标赛”. 本文模型只能在同一句内对零代词信息进行捕捉,对跨句信息暂无法获取.
3 结论
本文针对中文零代词识别任务,利用LSTM编码中文零代词的上下文信息,再通过注意力机制捕捉句子中的关键语义,有效利用上下文语义,减少上下文无关信息对零代词表示的影响. 使用Tree-LSTM对零代词上下文的句法结构信息进行编码,将语义信息和句法结构信息的融合特征通过两层前馈神经网络对零代词进行识别. 本文首次通过深度学习方法同时利用语义信息和句法结构信息进行中文零代词的识别,实验结果表明,该方法在OntoNotes5.0语料上取得了较好的效果.
猜你喜欢
科学咨询(2022年19期)2022-11-24
疯狂英语·初中天地(2021年11期)2021-02-16
疯狂英语·初中天地(2021年12期)2021-02-12
考试与评价·八年级版(2020年1期)2020-10-26
高中生·天天向上(2018年1期)2018-04-14
东西南北(2016年19期)2016-11-01
海峡姐妹(2016年2期)2016-02-27
中学生天地·高中学习版(2008年5期)2008-03-20
