
基于Faster RCNN的布匹瑕疵识别系统①
2021-02-23 06:29蔡兆信李瑞新戴逸丹潘家辉
计算机系统应用 2021年2期
蔡兆信,李瑞新,戴逸丹,潘家辉
(华南师范大学 软件学院,佛山 528225)
1 引言
1.1 研究背景
经历了新中国成立后70 多年的社会主义建设,我国的纺织业取得了飞跃的发展,目前已经形成了种类齐全、生产布局合理、原料充足的生产局面.但步入信息化时代,纺织业产品质量检测仍停留在依靠人眼、经验的基础之上,容易因工作人员操作失误、工厂设备的老化故障或环境温度的变化等原因造成漏检、检错等情况[1].
少数纺织企业能通过智能验布系统解决其瑕疵检出率低、人员成本高等问题,但其技术仍需不断优化.通过自动化的布匹瑕疵检测,促使我国纺织工业迈向智能科技创新水平,推动纺织工业行业的科技进步,满足中国纺织工业领域的发展需求仍然任重而道远[2].
1.2 研究现状
国内外学者已提出许多布匹瑕疵检测算法,如Kandaswarmy 等研究彩色纹理图像在不同光照下的特征分析技术,选择合适特征对其进行纹理有效性图像检测[3],Shukla 等提出基于DSP 的视觉检测系统方法,实时性强[4].
目前目标检测算法主要分为3 种类别:(1)基于区域建议的目标检测与识别算法,如RCNN,Fast RCNN和Faster RCNN;(2)基于回归的目标检测与识别算法,如YOLO 和SSD;(3)基于搜索的目标检测与识别算法,如基于视觉注意的AttentionNet,基于强化学习的算法,其中目前最常用的目标检测算法为Faster RCNN,YOLO和SSD[5].YOLO 和SSD 算法主要针对大物体,且速度方面相对比Faster RCNN 快,但对于小物体目标检测其表现结果却不太理想.
本研究基于Faster RCNN 算法开发一款纺织布匹表面瑕疵识别系统.该系统通过采集高速相机拍摄的来自坯布、面料、服装的带有瑕疵的产品的影像数据,完成对布匹图像上瑕疵的检测,对布匹上的各种疵点精准检出,并准确定位瑕疵坐标位置.
2 数据扩展
2.1 大规模学习算法的难点
大多数优秀的神经网络都需要设置大量的参数,以深度学习领域最常见的图像识别来看,其中一种常用的特征提取模型为VGG16,用于初步提取图像的特征值,然后再做后续的处理,如分类、边框提取.要让这些优秀的神经网络模型正常工作我们通常需要大量的数据,然而实际环境下我们并没有如此庞大的数据集[6].几种模型对比如表1所示.
除此之外,数据集里各类别的数据量比例悬殊也会影响模型的训练效果.因此在数据不均衡时,为了获得较高的准确率,一般需要更多且更均匀的数据.
2.2 图像数据增强
克服数据量供不应求和数据类别参差不齐的一种常用的做法就是数据增强[7].一般神经网络在刚开始或欠训练的时候,并不能区分出相似的数据.将一张含有某物体的图片进行放大缩小加噪降噪的操作,早期的网络也会认为是同一个物体.数据增强主要有两个好处:(1)增加训练的数据量,提高模型的泛化能力;(2)增加数据噪声量,提高模型的鲁棒性.
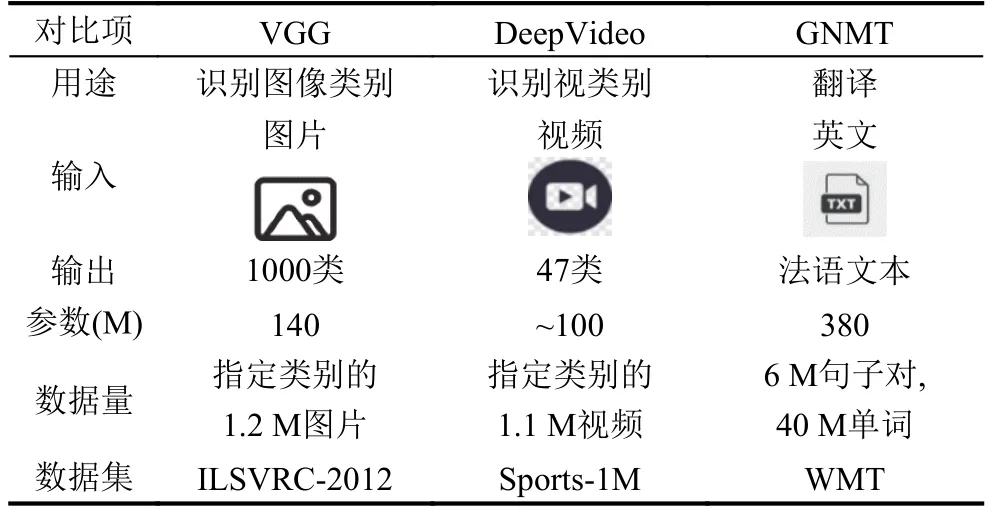
表1 VGG、DeepVideo 和GNMT 模型对比
3 布匹瑕疵检测与识别
3.1 目标检测与识别算法
本研究的数据集中,缺陷区域面积占比不到1%的布匹样本超过了82%,因此我们选择检测速度较低但对小物体较敏感的Faster RCNN 网络(对比图如图1).
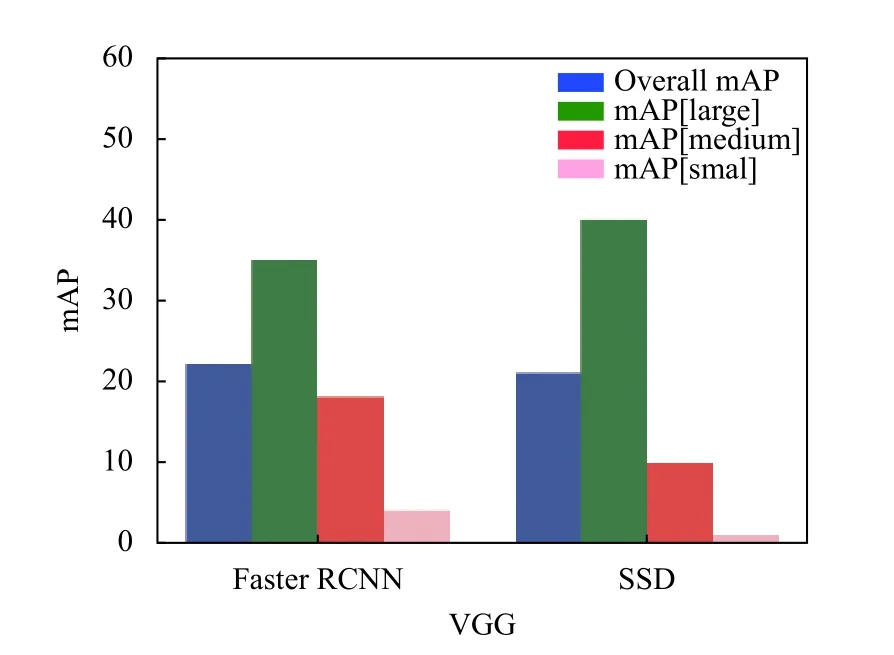
图1 Faster RCNN 和SSD 在VGG16 模型上对小物体的检测mAP 对比图
Faster RCNN是2016年提出的一种新型神经网络[8],是从RCNN、Fast RCNN 进一步改进而来,其抛弃了Selective Search[9]做法直接利用RPN网络来计算候选框,使得目标检测速度大幅度提高.
另外,我们针对布匹瑕疵目标小的特点,调整RPN网络的anchor 大小和数量,以及学习率等参数,提高了检测的准确率.
3.2 Faster RCNN 原理
Faster RCNN 主要由区域生成网络(RPN)和Fast RCNN 构成(图2),在经过基础的卷积神经网络(本实验采用VGG16)初步提取特征值后,其中RPN 主要用于生成可能存在目标的候选区域(proposal),Fast RCNN用于对候选区域内的目标进行识别并分类,同时进行边界回归[10]调整候选区域边框的大小和位置使其更精准地标识瑕疵目标.Faster RCNN 相比前代的RCNN 和Fast RCNN 最大的改进是将卷积结果共享与RPN 和Fast RCNN 网络,在提高准确率的同时提高了检测速度.
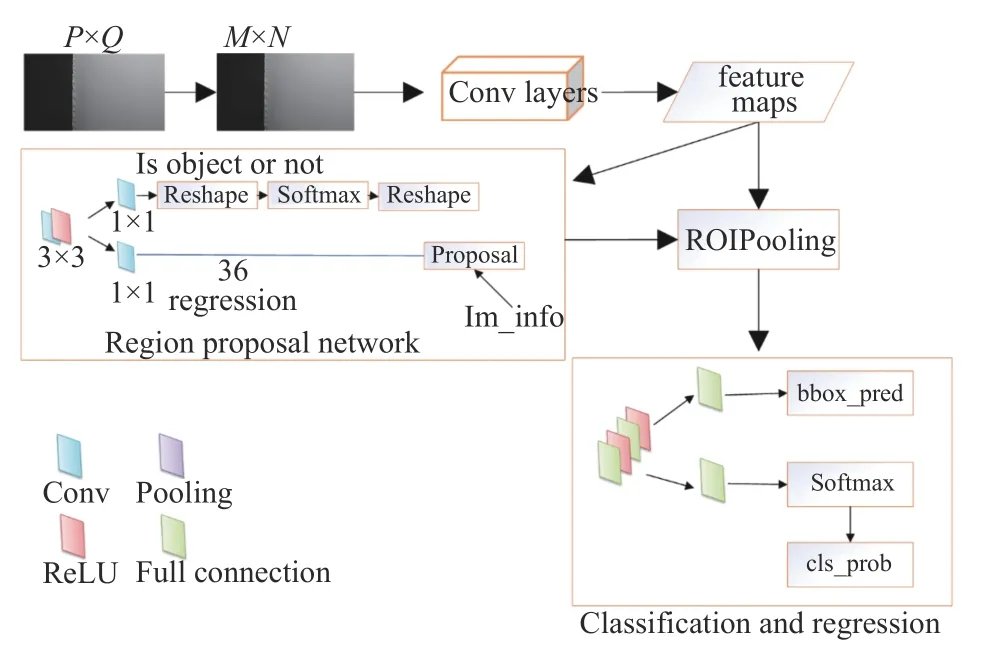
图2 Faster RCNN 网络结构图
RPN 网络是一个全卷积网络,采用一个n×n的滑动窗口在上一层共享卷积网络的输出特征图上进行滑窗选择,对每一个点同时预测k个被称为锚(anchor)的初始候选区域.对于一张大小为w×h的卷积特征图,则可得到w×h×k个锚.接着将每个点映射到一个低维向量,用作后续的边框分类和边框回归.边框分类中,通过Softmax 分类anchor 得到对应的前景(foreground)和背景(background),最终初步提取出foreground anchors作为目标候选区域.而边框回归则用于回归修正出锚的边界框,获得精确的proposals.因此要准确分类和回归边框需要对RPN 网络进行训练以得到正确的回归参数.在训练RPN 的过程中采用端到端(end to end)的方式,损失函数通过平衡因子将分类损失和回归损失相结合.训练好后的RPN 得到的候选区域,再在后续Fast RCNN 再做进一步的检测和纠正.
Fast RCNN 网络通过ROI 池化后,输出结果为固定长度的特征向量.将特征向量经过全连接层后分别输入到Softmax 分类器和边框回归网络(bounding box regression)分别获得边框区域内对应的类别和边框偏移量,回归得到更加精确的目标检测框.
3.3 调整RPN 网络
RPN 的输入是卷积层后的特征映射(feature maps),通过在特征图中运用anchor 机制和box regression,单独判断和定位瑕疵位置的网络.Anchor 以每一个锚点为中心生成大小不同的k个框,致力于使目标对象能出现在某个框中.
统计显示,本研究的数据集里瑕疵缺陷区域面积占比不到1%的布匹样本超过了82%,因此,针对小目标的问题,我们通过调整Faster RCNN 中的RPN 网络的候选框的大小和数量来提高检测率.以图3、图4为例,原始的RPN 网络中每个点拥有9 个矩形,共有3 种形状,长宽比大约为0.5,1.0 和2.0,scale 为8,16,32.在本实验中,选择k=36,即每个点拥有36 个anchor,针对布匹瑕疵目标小的特点,scale 为4,8,16,设置候选框的长宽比为0.1,0.5,1,2,5,scale 为4,8,16.通过移动anchor,利用Softmax 函数判断是否为瑕疵区域,即判定positive 与negative,实现二分类,初步提取了检测目标候选区域box.当得到positive 的区域后,对瑕疵边框进行坐标回归运算,获取瑕疵区域更加精准的proposals,同时剔除太小和超出边界的proposals.

图3 候选框调整前
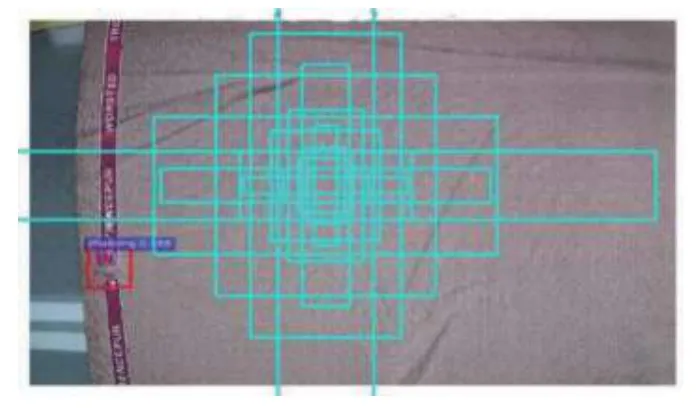
图4 候选框调整后
3.4 区域推荐网络(RPN)损失函数
RPN 网络层负责候选窗口的分类和回归,本文中PRN 网络的损失函数为分类交叉熵损失和回归SmoothL1损失的总和,定义如下:
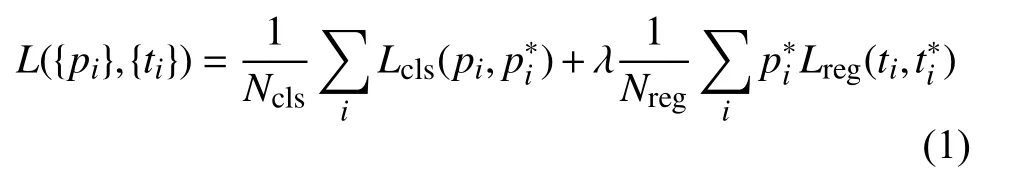
3.4.1 分类交叉熵损失
分类交叉熵公式定义为:
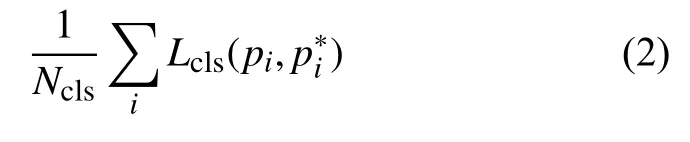
RPN 网络中的分类器将候选框分为前景(foreground)和背景(background),分别标为1 和0,并在训练过程中选择256 个候选框.式(2)中,Ncls代表候选框数量,本实验中候选框数量为256.pi为框内预测目标的概率,为实际目标的概率,定义为:

Lcls(pi,p∗i)代表pi和p∗i的对数损失,定义为:
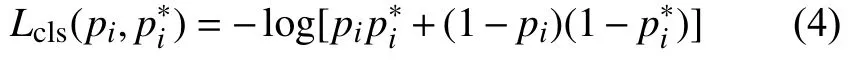
3.4.2 回归SmoothL1损失
回归SmoothL1公式定义为:
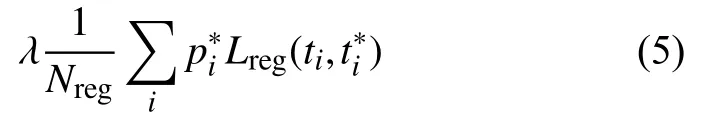
式中,ti为候选框相对于目标所在的真实框的预测的偏移量,为候选框相对于目标所在的真实框的实际的偏移量.ti>和的定义如下:
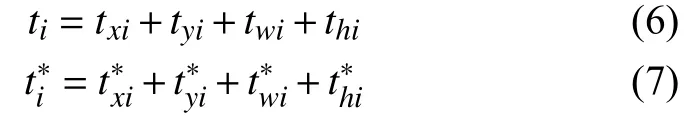
其中,
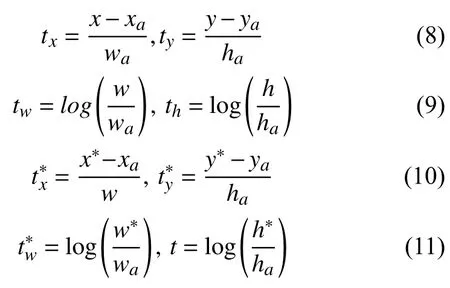
Lreg为回归损失,R为SmoothL1函数,两者的定义分别为:
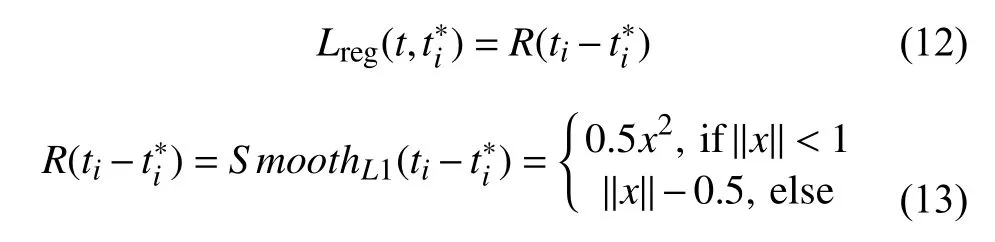
4 实验与结果
本实验使用的布匹数据集取自2018年太湖新城与阿里云联合举办的“2018 雪浪制造AI 挑战”天池大赛.实验中分别进行数据增强化和调整模型的参数,采用9:1 的方式随机选择训练数据集和测试数据集,训练共迭代45 000 次.
4.1 实验环境与系统架构
本实验的在MAC 系统上进行,采用PyCharm 开发工具和MySQL 数据库,同时利用深度学习框架Tensorflow 1.14.0 和Keras 2.2.4 来搭建并训练模型,布匹瑕疵检测系统前端和后台开发分别采用Bootstrap 和Flask框架.布匹瑕疵检测系统可运行在浏览器(推荐Chrome和Firefox 浏览器)上,系统的功能主要由布匹瑕疵识别和瑕疵数据分析组成.在第三方硬件支持上,我们利用Google Colab 来对模型进行训练.
4.2 实验过程
4.2.1 数据增强
本文中原始布匹数据集里共有37 种瑕疵类别,但每种类别所包含的数据量不均匀,如图5,甚至个别数据异常悬殊,如边擦洞种类有12 张图片,而粗纱种类仅有2 张,总体而言正常样本与某些缺陷类的比例超过了10:1.这对后期的训练工作带来极大不便,易对原本数据量大的瑕疵检测出来的准确率比数据量小的要大,甚至模型只会检测出数据量大的类别,抛弃小数据类别.
研究首先对原始图像数据进行增强,主要方法有翻转、亮度变化、加入噪声、裁剪以及固定角度的旋转等(图6),同时还对数据量偏小的类别偏袒,提高类别数量的均衡度.数据增强后,共有4668 张布匹图片数据.
4.2.2 模型训练过程和主要参数设置
研究对原始的Faster RCNN 网络进行调整,对RPN网络的候选框(或称锚)进行调整.检测过程分为5 步:
(1)增强后的布匹数据为4668 张图片,实验首先根据4668 张图片转化为VOC2007 数据集格式,然后按照20:1 的比例划分训练集和测试集;
(2)将测试数据集放入VGG16 模型的初步提取图像特征值,该层由基础的卷积层(Conv)、激活层(ReLU)和池化层(Pooling)构成,提取出图片的特征映射,用于后续的RPN 层和ROI 层,;
(3)用训练好的RPN 网络生成候选检测框,也就是proposal;
(4)收集VGG16 网络输出的特征映射和RPN 网络输出的proposals,结合起来进一步提取出proposal feature maps,送入后续全连接层判定目标类别;
(5)最后进行分类,利用Softmax 分类器和proposal feature maps 来判断出检测框内的布匹瑕疵类别,并再做一个回归(regression)获得更为准确的检测框位置.
训练过程如图7所示.主要参数调整如下:
(1)总迭代次数为4.5 万次;
(2)学习率为0.001;
(3)一次训练所选取的样本数(batch size)为256;
(4)候选框的尺度为4,8,16;
(5)候选框的长宽比(ratios)为0.1,0.2,0.5,1,2,5.
4.2.3 实验结果与分析
实验对4 种检测方法(如表2所示)进行对比,4 种方法分别为Fast RCNN (原始网络+原始数据)、Faster RCNN (原始网络+原始数据)、Faster RCNN (原始网络+增强数据)、Faster RCNN (调整网络参数+增强数据),其中最后一种方法为本研究采用的方法.
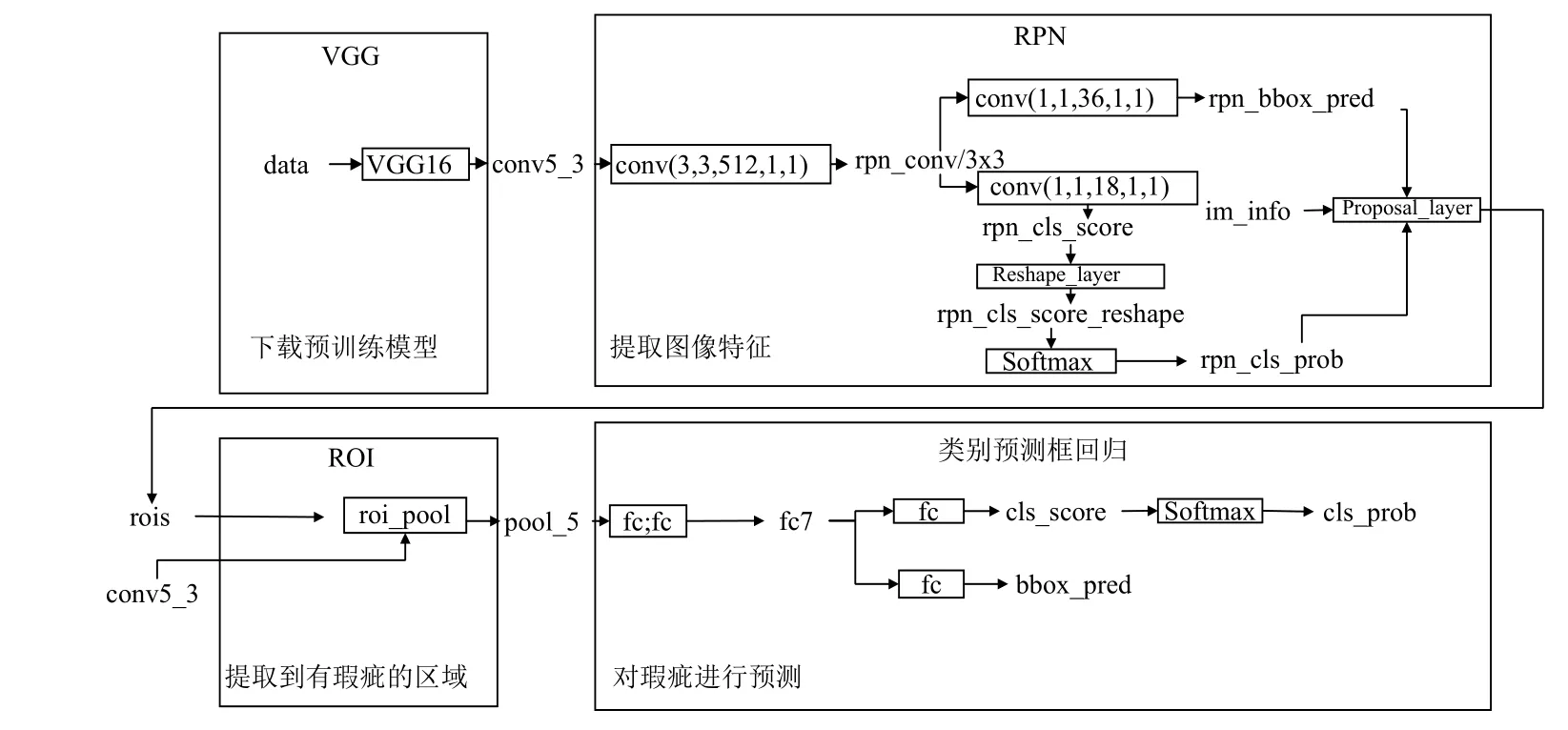
图7 布匹瑕疵检测流程图
对比分析4 种检测方法的结果,Faster RCNN 平均训练时间总体比Fast RCNN 较长,在调整网络和增强数据后更为如此,主要由于每个点的候选框(anchor)数量和训练集的数据量增大导致,但最终平均检测准确率显著提升,平均每张图片的检测速度的变化幅度也在可接受范围之内,因此这种检测方法是可行的.
本研究测试采用的设备性能偏低,但在实际的检测环境中,若采用性能较好的设备,单张图片的检测速度会进一步提升,且准确率也是较为可观.
对测试数据集进行测试得到的部分结果如图8所示.在图中红色检测框区域代表布匹瑕疵存在的位置,上方为对于该检测框区域目标的分类类别以及该类别的置信率.检测结果如图8所示,以图8(d)为例,模型可以同时在一张图检测出3 处瑕疵,并分别标识出对应类别的置信率.总体准确率为79.3%.
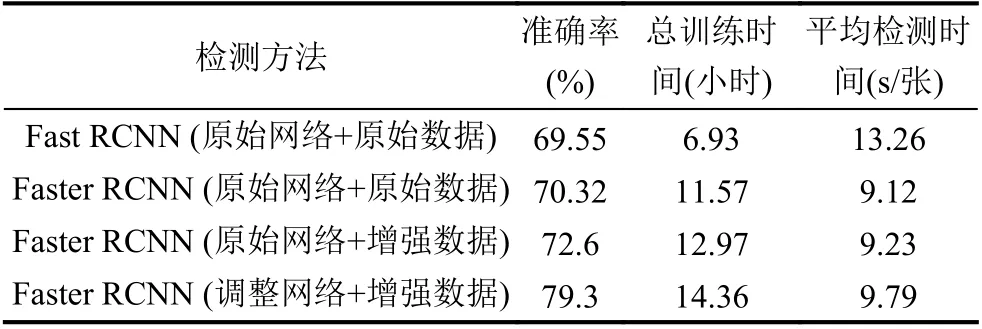
表2 4 种检测方法结果对比
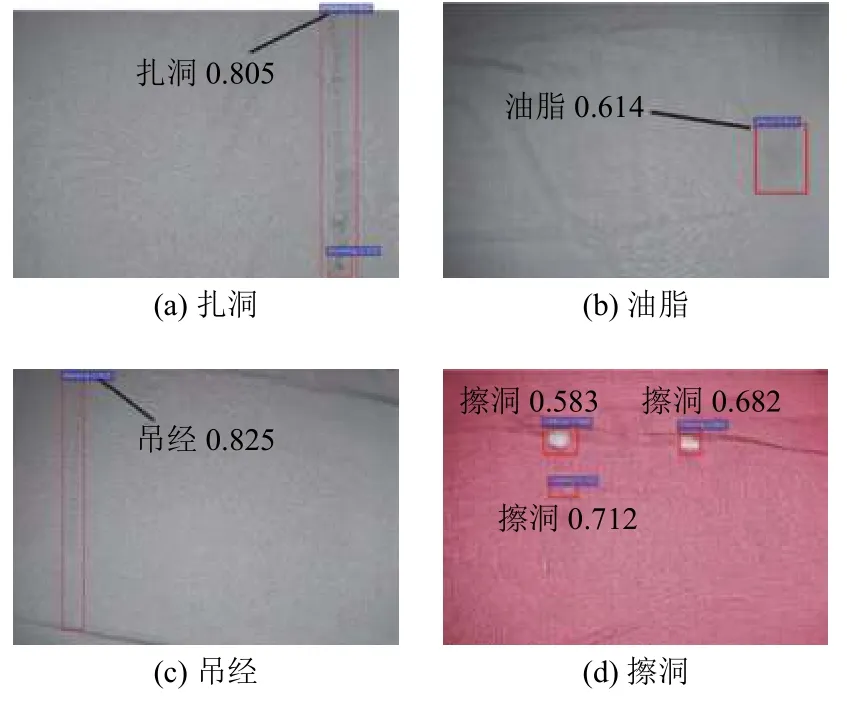
图8 布匹瑕疵检测结果图
5 讨论与总结
本研究针对原始布匹数据集中各类瑕疵的数据量不均匀以及瑕疵目标小的特点,分别对原始数据进行了增强,并选用对小目标更为敏感的Faster RCNN 网络,并调整其中RPN 网络中原始的anchors 大小和数量,提高瑕疵识别的准确率.因此在数据处理和识别算法上有一定的创新,与传统的使用卷积神经网络进行检测和识别有较大的不同.另外研究基于Faster RCNN模型开发了一款基于Web 技术的布匹瑕疵检测系统,可在布匹生产线和市场等场合用于布匹质量检测,提前感知生产上的不足和减低布匹买卖的损失.同时该系统使用到目前较为先进的前端开发技术,使系统在用户交互上更加智能化,操作简单,互动性强.
本文将增强后的数据放入Faster RCNN 模型中进行训练,通过4.5 万次迭代训练,在检测设备性能限制下,最终使得每张布匹的检测时间保持在10 s 以内,测试准确率为79.3%.
尽管相比于其他利用Faster RCNN 检测布匹瑕疵的研究中90%以上的准确率[11],本文的准确率比较低,但本文是基于数据量少且类别不均匀的基础上对进行数据增强,且多数布匹瑕疵目标特征不明显,并针对目标的特点调整Faster RCNN 网络,同时分类出37 种类别,因此在总体性能上比该研究高.
综上所述,本研究在数据量不足、各类别的数据量不均匀和目标小的情况下,对现有的技术进行改进并实践,在布匹生产质量检测领域中做出了实质性的尝试.
猜你喜欢
民间故事选刊·上(2022年2期)2022-02-25
电脑爱好者(2020年19期)2020-10-20
扬子江(2019年3期)2019-05-24
软件导刊(2018年3期)2018-03-26
人生十六七(2015年21期)2015-11-14
科普童话·百科探秘(2015年5期)2015-05-26
科技与创新(2014年11期)2014-08-21
第二课堂(小学版)(2014年3期)2014-08-02
语文世界(小学版)(2013年8期)2013-08-26
意林(2011年13期)2011-10-22
