
基于融合元路径的图神经网络协同过滤算法①
2021-02-23 06:30蒋宗礼田聪聪
计算机系统应用 2021年2期
蒋宗礼,田聪聪
(北京工业大学 信息学部,北京 100124)
随着网络信息技术的发展,推荐系统被广泛应用到社交媒体网络、新闻推送、购物平台等领域.根据实现思想不同,推荐算法主要分为3 类:基于内容的推荐、基于协同过滤的推荐以及混合推荐方法[1].
协同过滤[2]作为应用最广泛的一种推荐算法,其主要思想是由用户对商品的偏好发现用户之间的关联性,基于关联性进行推荐,即相似度高的用户往往有相似的偏好.一般来讲,协同过滤主要通过用户和商品的历史交互信息建模(如评分、点击率等),并得到它们的嵌入表示.如矩阵分解[3]将用户和商品映射到同一维度的隐空间中,并使用内积计算用户对商品的偏好程度.近年来,深度学习的发展进一步提高了推荐系统的性能.He 等[4]提出的NCF 模型通过整合传统的矩阵分解和MLP 进一步优化传统模型.Wang 等[5]提出的NGCF 模型构建用户-商品的二部图,通过图模型嵌入用户和商品的历史互动到特征向量中.虽然这些方法提升了推荐系统的性能,但是当用户和商品的数量增多,推荐系统可能会面临据稀疏性和冷启动等问题,从而无法实现个性化推荐.
近些年来,异质信息网络[6]由于包含多种类型的结点和边,被广泛应用到各个领域中[7–9].由于异质信息网络能表征丰富的辅助信息,基于异质网的推荐算法被学者广泛研究.Sun 等[10]提出的PathSim 基于元路径的相似性做推荐.Feng 等[11]提出的OptRank 基于异质信息解决社交推荐系统的冷启动问题.Yu 等[12]基于异质网实体间的关系,进一步优化推荐算法.Shi等[13]将随机游走得到的异质信息与传统的矩阵分解模型做融合.这些方法通过异质信息网络中的辅助信息,得到了用户和商品的潜在特征,但是可能会忽略用户和商品的历史互动等信息.
针对以上问题,本文提出了基于融合元路径的图神经网络协同过滤算法.该算法基于NGCF[4]模型,首先构建用户和商品的二部图,将它们的历史互动嵌入到特征向量中,然后通过神经网络多层传播获取用户和商品的高阶表示.异质信息网络中不仅有用户和商品两种类型的结点,还存在其他的结点类型和边类型,这些节点会影响到用户和商品的表征.为充分利用异质网络中的语义信息,在模型的基础上引入元路径获取潜在的信息.而不同的元路径往往有不同的含义,得到多条元路径的潜在特征后,引入融合函数及权重对多条元路径的信息有效融合.总结来说,本文的主要贡献可概括为以下3 点:
(1)在图神经网络协同过滤算法中引入元路径,基于元路径的随机游走生成用户和商品的潜在特征,并引入融合函数及权重对多条元路径的表征融合.
(2)将图神经网络生成的高阶特征与异质网中元路径生成的潜在特征有效融合,并做评分预测.
(3)在公开数据集Yelp、Amazon Book 和Amazon Movie 数据集上做实验,并与传统算法比较,验证了算法的有效性.
1 基本概念
定义1.异质信息网络(heterogeneous information network)[14].异质信息网络可表示为G=(V,E),其中V表示节点的集合,E表示边的集合.对于每一个结点存在一种映射关系 φ:V→A,对于每一条边存在一种映射关系 φ:E→R,A和R分别代表结点类型和边类型,且|A|+|R|>2.
如图1(b)所示表示的是IMDB 数据集构成的异质信息网络.如图1(a)所示,该异质网络有3 种类型的节点,分别是演员、电影和导演.同时有两种类型的边,分别是演员和电影之间的关系以及电影和演员之间的关系.
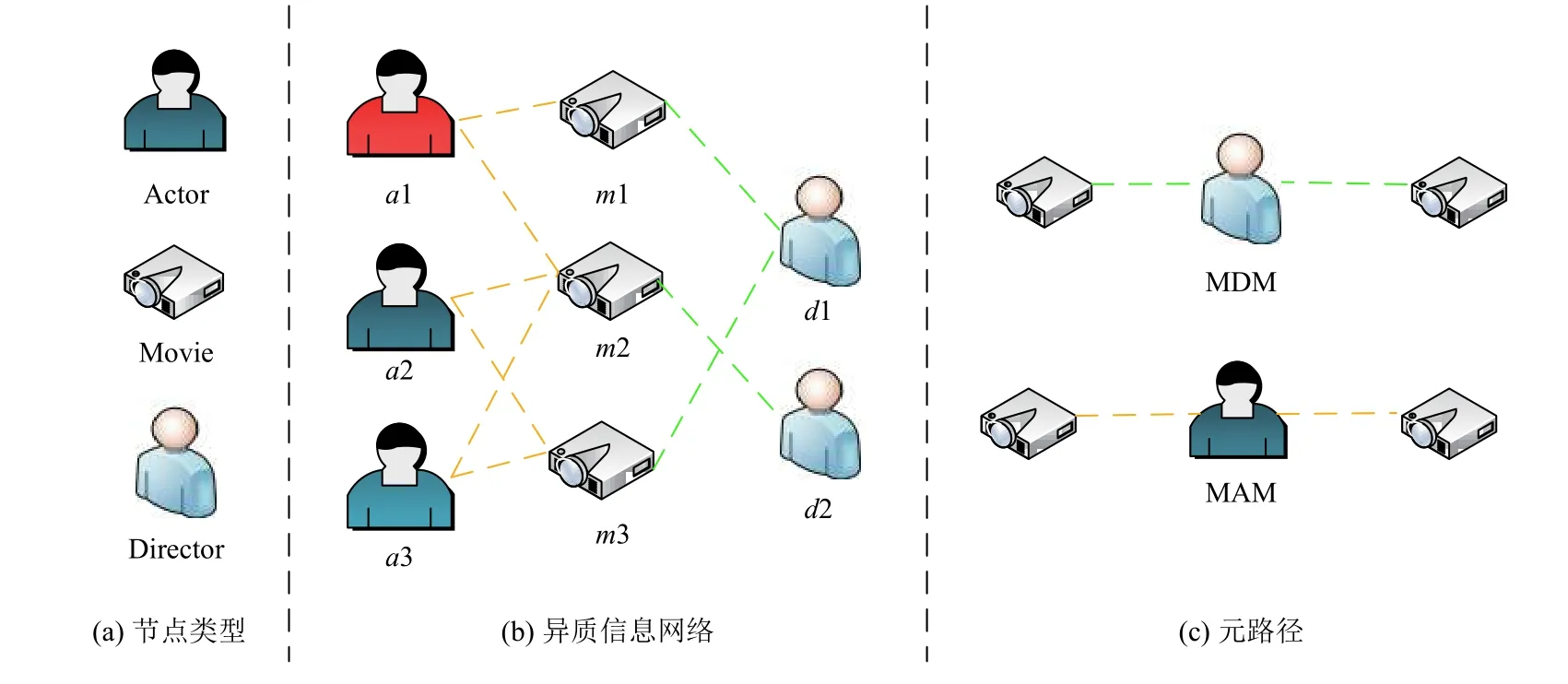
图1 异质信息网络及元路径
定义2.网络模式(network schema)[15].对于给定的网络G=(V,E),V表示结点的集合,E表示边的集合,且有映射关系 φ:V→A和φ:E→R,定义其网络模型为TG=(A,R).
在异质信息网络中不同类型的实体间的关系可以用元路径表示.
定义3.元路径(meta-path)[16].给定网络模型TG=(A,R),元路径可定义连接多种结点类型的一组关系,具体形式为其中Ri表示结点间的关系.
如图1(c)中列举了两条元路径,分别是MDM 和MAM.这两条元路径有不同的语义信息,其中MDM代表同一导演编导了不同的电影,而MAM 代表了同一演员出演了不同的电影.为了更丰富的表征异质网中的信息,我们在获取电影的特征向量时,会赋予这两条元路径不同的权重.
2 融合元路径的图神经网络协同过滤算法
这部分主要介绍基于融合元路径的图神经网络协同过滤模型.第一阶段基于NGCF[4]框架先构建二部图,将用户和商品的历史互动嵌入到特征向量中,并通过神经网络传播.异质信息网络中包含多种类型的节点和边.为了更丰富的表征用户和商品,在第二阶段通过元路径的随机游走获取用户和商品的低维表征,并将多条元路径的潜在特征有效融合.第三阶段将用户和商品的低维表征与高阶特征融合并做评分预测.
2.1 图神经网络协同过滤
从用户和商品的向量点积中很容易看出用户对商品的偏好程度.传统推荐算法,如矩阵分解等没有将交互信息嵌入到特征向量中,只是用ID 等属性初始化向量,用交互信息优化模型.为了从用户和商品的历史互动获取二者的高阶特征,在本文中我们采用NGCF 模型.该模型主要分为3 层:输出层、嵌入层和传播层.
2.1.1 嵌入层
嵌入层将输入的稀疏向量转化为稠密向量,随机初始化用户和商品的向量矩阵E∈R(M+N)×d,如式(1)所示,其中用户数量为M,商品数量N,d为表示维度的大小.
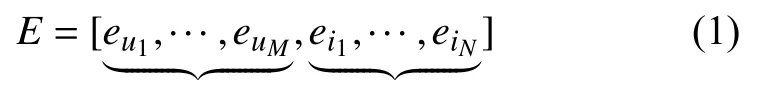
2.1.2 传播层
根据用户和商品的邻接矩阵,将特征向量与其邻居节点向量融合,然后通过多层神经网络进行信息传递得到最终的特征向量.
对于用户商品的任一结点对(u,i),定义从商品i到用户u的信息传递函数为式(2)所示.其中ei为商品的特征向量,eu为用户的特征向量,为用户u和商品i之间的权重系数,Nu>和Ni分别代表用户和商品的邻居结点个数,W1,W2∈Rd′×d是权重矩阵参数,⊙为向量对应元素之间的乘积.
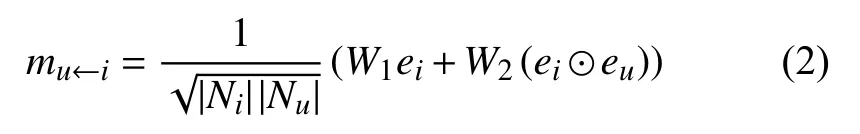
式(2)是针对一个邻居节点的表示,由于用户的邻居节点可能有多个,故用户最终的向量表示是其所有邻居结点的融合.通过l层的信息传递,用户可以获得其l阶邻居的信息,第l层的特征向量表示为式(3)所示.从中可以看出信息传递过程中用户不仅融合了其邻居结点商品的特征,而且保留了用户本身的特征.
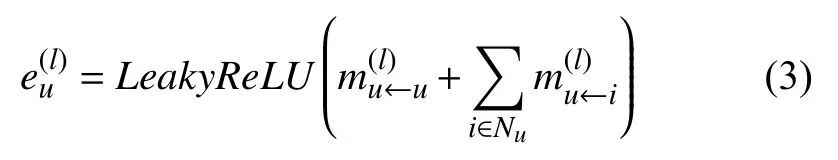
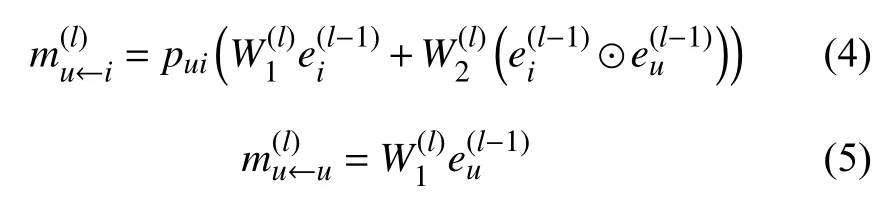
经过l层传播得到用户向量表示可为集合商品向量可表示为用户和商品的特征向量最终表示为式(6)所示,其中‖ 表示向量之间的拼接.
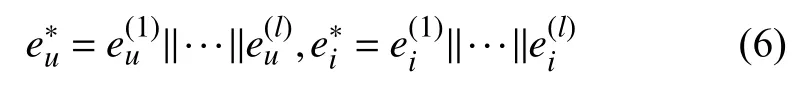
2.2 异质信息网络中的低维表征
2.2.1 元路径的随机游走
对于DeepWalk[16]和Node2Vec[17]采用的是随机游走生成网络中的节点序列,这种方式的随机游走会偏向于节点类型多的节点.为了解决这个问题,Dong 等[18]提出的Metapath2Vec 基于元路径的随机游走,能更好的涵盖异质网中丰富的语义信息.首先基于元路径进行随机游走生成节点序列,然后采用Skip-gram 学习异质网中的低维表征.
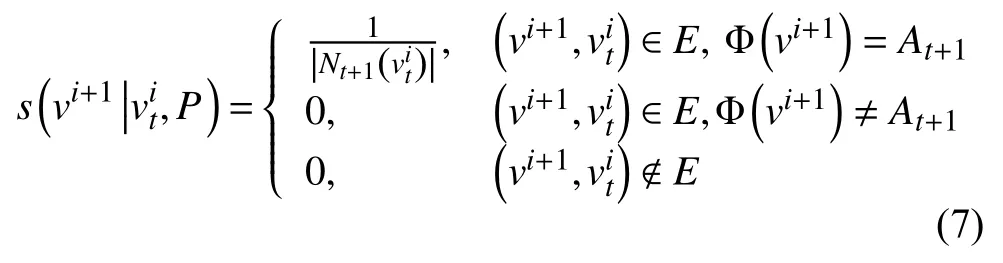
在得到随机游走的节点序列后,由于我们关注的用户和商品的低维表征,所以进行节点类型限制和过滤[13].具体来说,只选择以用户、商品类型节点为起点的节点序列.并且在每条序列中,只保留与起点类型相同的节点,对其他类型的节点过滤.例如,对于元路径MDM 我们可能游走出序列u1→m1→u2→m2→u3→m2→u4,对节点过滤得到u1→u2→u3→u4.
通过Skip-gram 模型学习异质网中节点的低维表征,优化函数如式(8)所示.其中Nt表示顶点为v的邻居节点中类型为t的集合.
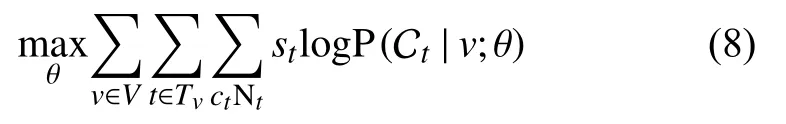
2.2.2 低维表征融合
对于给定的节点v,其元路径对应的表征集合为其中p为元路径的个数.现有的表征融合往往采用简单的线性的融合方式,即赋予每条元路径一个权重,这可能会造成表征质量降低.在本文中我们在权重的基础上引入融合函数,融合公式如式(9)所示.其中为第i个 元路径的权重,M(i)∈RD×d为权重矩阵,b(i)∈RD为权重参数.
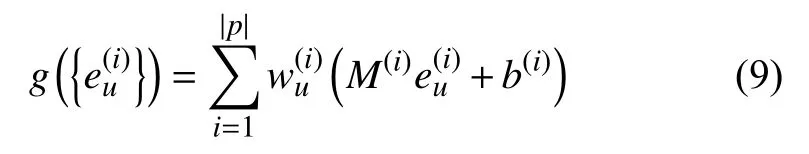
2.3 模型预测
在2.1 节中通过图神经网络得到了用户和商品的高阶向量表示,2.2 节中通过元路径得到了用户和商品潜在的特征,模型最终预测为式(10)所示.其中eu及ei是通过图神经网络得到的特征向量,zu及zi是由元路径得到的潜在向量,α为权重参数.
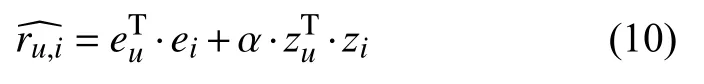
2.4 模型优化
为了更好地将高阶特征与潜在向量融合起来,我们采用式(11)所示的函数优化.其中ru,i表示用户和商品的实际分数,ru,i′是预测分数,eu及ei是通过图神经网络得到的特征向量,zu及zi是由元路径得到的潜在向量,λ为权重参数,Θ(U)及Θ(I)分别表示模型中用户和商品对应的参数.
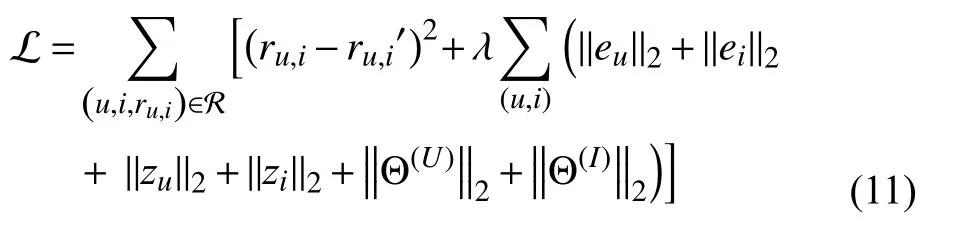
3 实验结果与分析
通过在Yelp、Douban book 及Douban movie 3 个数据集上做实验,实验结果表明均方根误差都小于传统模型,证明了算法的有效性.
3.1 数据集
为了证明算法的有效性,选取了3 个不同领域的数据集.Yelp是商务类型的数据,稀疏度为0.08%.Douban book是书籍类型的数据,稀疏度为0.27%.Douban movie是电影类型的数据,稀疏度为0.63%.3 种数据集的具体信息如表1所示.
在获取用户及商品的潜在特征向量阶段会使用到元路径,对于3 种数据集我们使用的元路径如表2所示.以Yelp 数据集为例,用户在神经网络传播层部分通过用户和物品的交互可以得到UBU,同理物品在神经网络传播层部分通过物品和用户的交互可以得到BUB 的路径,所以在元路径中不再使用这两条元路径.Douban movie 和Douban book 的元路径中采用同样的思想.
3.2 评价指标
在本文中采用均方根误差(RMSE)评价推荐模型,均方根误差是均方误差的算数平方根.均方误差指的是参数估计值和参数真实值之差平方的期望值.其中均方根误差值越小,推荐模型的效果越好,预测越精确.它的表示如式(12)所示.其中Dtest表示测试集数据,ru,i和ru,i′分别表示结点对(u,i)的实际分数和模型的预测分数.
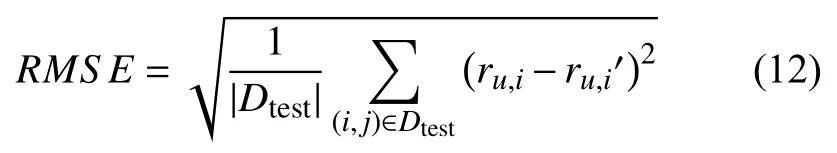
3.3 方法对比
为了验证算法的有效性,采取以下模型作为对比:
(1)HeteMF[12]:基于异质网中元路径的相似性做推荐.
(2)SoMF[19]:基于社交网络的推荐模型,提出了具有社会正则化的矩阵分解模型.
(3)SemRec[20]:基于协同过滤的思想,在加权异质信息网络中考虑不同元路径之间用户和商品的相似度做推荐.
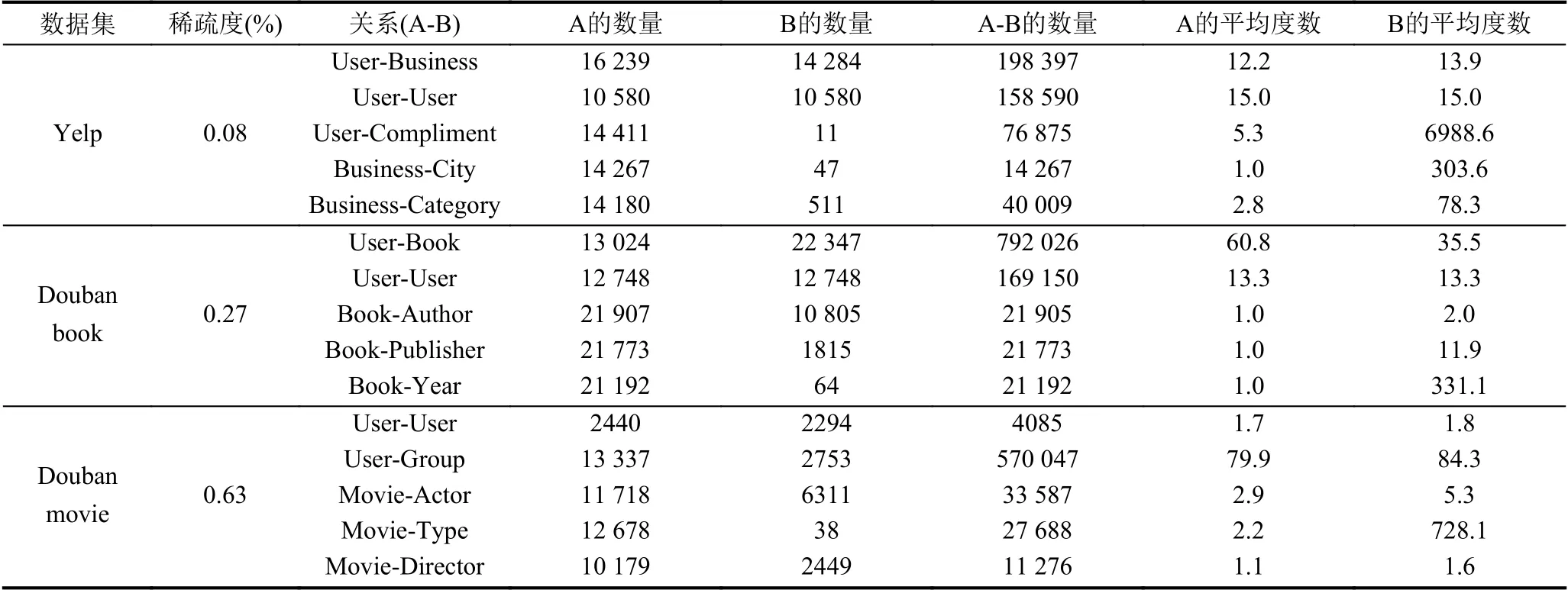
表1 数据集的具体信息

表2 数据集的元路径
3.4 实验结果及分析
3.4.1 确定训练集比例
通过改变训练集与测试集的比例,测试模型在不同比例下RMSE的值.对于Yelp 数据,由于比较稀疏将训练集数据的比例设为{90%,80%,70%,60%},而对于Douban movie 和Douban book 将训练集数据的比例设为{80%,60%,40%,20%},实验结果如图2所示,从左到右分别为Yelp、Douban movie 及Douban book的实验结果.从图2中可以看出Yelp 数据在训练集数据占90%时RMSE达到最好的结果;Douban movie及Douban book 数据在训练集数据占80%时RMSE达到最好的结果.所以我们将Yelp 的训练集和测试集的比例设为9:1,而Douban movie 及Douban book 的训练集和测试集的比例设为8:2.

图2 RMSE 在不同训练集比例下的值
3.4.2 用户和商品的历史互动
在模型最后的预测中既考虑了用户和商品的高阶历史互动,又考虑了异质信息网络中用户和商品的潜在语义信息.为了证明模型的有效性,将分别讨论用户和商品的历史互动及异质网中的语义信息对RMSE结果的影响.
在这个部分只保留用户和商品的历史互动,而不考虑异质信息网络中用户和商品的潜在的语义信息.在3 种数据集上分别实验,RMSE值的结果如表3所示.

表3 用户和商品的历史互动
3.4.3 异质信息网络中的语义信息
在这个部分只保留异质信息网络中用户和商品的潜在语义信息,而不考虑用户和商品的历史互动的信息.同时在原有的元路径基础上,加上用户和物品的交互.在3 种数据集上分别实验,RMSE值的结果如表4所示.

表4 异质网中的语义信息
3.4.4 预测函数中的权重系数
我们通过调整预测函数中的权重参数 α,研究这个权重参数时如何影响模型性能的.选定参数 α的值在集合{0.5,0.7,0.9,1.1}间调整.实验结果如图3所示,从图中可以看出RMSE的值随着 α的增大先下降后上升,在0.9 时RMSE达到最小值.
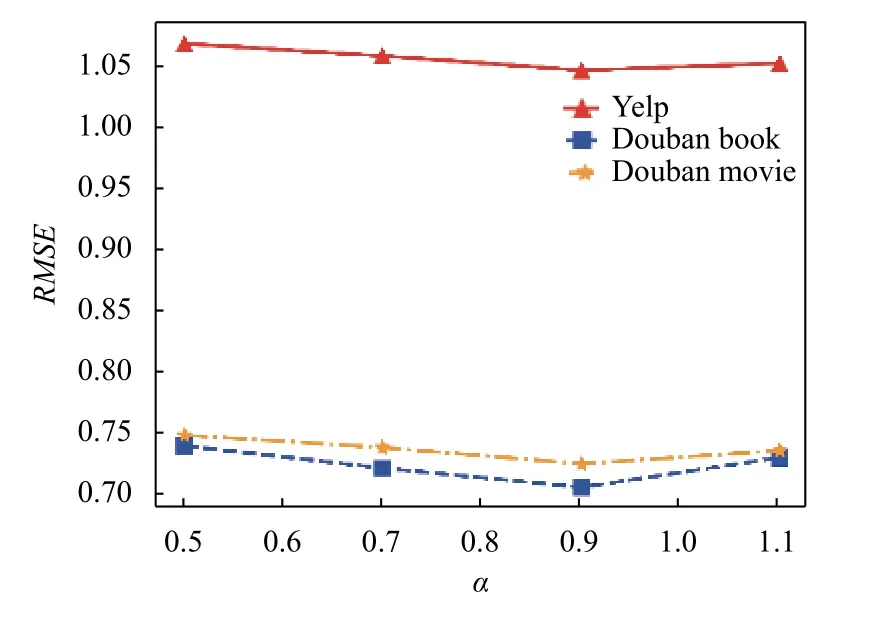
图3 RMSE 在不同α 下的值
3.4.5 实验结果与分析
3 种数据集在不同模型上的实验结果如表5所示,表中的数字代表实验结果RMSE的值.由实验结果可知,基于融合元路径的图神经网络协同过滤算法比传统的推荐算法有一定提高.同时与表3中只考虑用户和商品的历史互动以及表4中只考虑异质信息网络中的潜在语义信息的结果相比,融合元路径的图神经网络模型的RMSE值更小.本模型通过图神经网络模型既考虑了用户和商品的历史互动,又通过元路径考虑了异质信息网络中的语义信息,并将两者有效的融合起来,RMSE值更小,推荐效果更好.
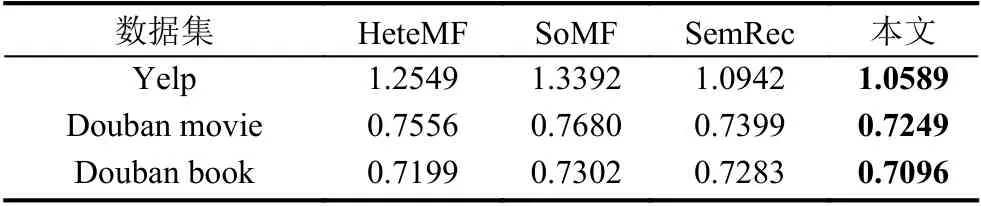
表5 实验结果
4 结论与展望
本论文通过分析传统推荐算法的缺点,提出了基于融合元路径的图神经网络协同过滤算法.该算法既考虑了异质信息网络中的语义信息,通过元路径获取潜在的信息,并引入融合函数和权重对多条元路径的表征融合,避免了冷启动及数据稀疏等问题.同时又充分利用了用户和商品的历史互动,通过二部图嵌入用户和商品的特征,图神经网络的多层传播得到高阶向量.本论文还与传统的推荐算法对比,证明了模型的有效性.在未来的工作中,我们将进一步优化元路径的融合方式,将注意力机制[21]引入元路径中,获取异质信息网络中更精准的语义信息.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
煤气与热力(2022年2期)2022-03-09
家庭教育报·教师论坛(2021年42期)2021-12-23
科学导报(2020年44期)2020-07-27
经济数学(2020年4期)2020-01-15
分析化学(2019年3期)2019-03-30
软件(2017年6期)2017-09-23
新教育时代·教师版(2016年26期)2016-12-06
求知导刊(2016年30期)2016-12-03
