
互联网开源信息智能采集与分析平台设计
2021-02-27 09:17
科学与信息化 2021年1期
北京道达天际科技有限公司 北京 100049
引言
随着互联网在全球范围内的迅速发展,可供人们利用的网络信息飞速膨胀,互联网已经成为人们取之不尽,用之不竭的公开来源信息资源宝库。开源信息的价值与日俱增,在各类数据体系中占据相当大的比重,其发挥的作用也越来越大,正成为分析决策、科研活动、技术研究的强大支持。信息挖掘技术不断革新的今天,已经逐渐摆脱了几十年前人工分析信息和收集信息的模式,计算机智能算法、大数据可视化、知识图谱等技术的引入,极大地增强了信息处理能力,同时也对信息价值的挖掘和利用产生深远影响。
面向现代社会对互联网开源信息采集与分析挖掘应用的迫切需求,结合自然语言理解、知识图谱、时空分析等关键技术,构建互联网开源信息采集与分析的技术体系,支持从社交媒体、门户网站、新闻媒体、论坛等各类互联网信源中自动采集关注的信息,支持对开源数据进行清洗治理、自动抽取、事件发现、关联分析、综合展示等处理和分析,支持各类业务信息监测预警、态势分析、综合研判,满足互联网开源数据分析挖掘应用的能力体系需要,为正确认识、快速处理和有效使用互联网开源信息奠定基础。
1 平台设计
1.1 技术框架设计
互联网开源信息智能采集与分析平台按照“云+端”架构来进行设计,可以划分为三层,分别是资源层、服务层、应用层,如图1所示。

图1 技术架构设计
(1)资源层
资源层是互联网开源信息智能采集与分析平台和数据源支撑,其中硬件方面需涵盖存储设备、计算设备、网络设备、安全设备、服务器等硬件资源;软件方面提供针对固定信源的定向自动采集和针对个性需要的交互采集两种功能,通过网络爬虫及搜索引擎采集公开原始信息数据存储至云端,为系统运行提供数据资源和硬件设备资源保障。
(2)服务层
服务层是互联网开源信息数据挖掘分析系统的中枢大脑,为系统的存储管理、分析计算提供能力服务保障,按功能划分为数据中心层和分析支撑层。
数据中心层主要分为数据治理以及数据存储管理两部分,主要包含分布式并行计算处理、全文检索引擎、人工智能框架、微服务管理平台、分析模型管理等底层应用支撑服务,为系统业务分析提供通用的底层平台框架;数据库主要解决结合业务流程加工形成的开源信息和数据产品的存储管理,按功能应用要求分别存储在关系型数据库、非关系型数据库、内存型数据库、图数据库、OSS面向对象文件系统等。
分析支撑层是平台功能应用的核心支撑部分,在原始开源数据人机结合治理清洗,形成先验知识库的基础上,开展要素提取、信息分类、数据计算、属性融合、业务分析等工作,主要负责图像识别、OCR识别、实体识别、关键词提取、去重过滤、属性一致性、属性补全、属性标准化、事件及实体分级分类、事件要素归一化、知识建模、关联分析、统计分析、情感分析等数据组织及处理,最终形成数据分析成果集。
(3)应用层
应用层主要解决平台的业务数据可视化能力,为用户提供层次清晰、操作方便的交互体验,支撑用户使用直观易操作的界面功能进行开源信息分析挖掘工作,主要应用包括开源门户、重点关注事件态势监视、各大事件体系编成、业务运用分析、重大事件案例 复盘等。
1.2 平台能力构成
(1)开源信息智能采集
面向互联网各类开源信息搜集任务需要,设计针对固定信源的定向自动采集和针对个性需要的交互采集两种手段,支持用户从互联网中的各类政府门户、资讯网站、知识百科、社交网络、位置服务等信源中采集相关地理数据、事件动向、智库报告、网络舆情、科技信息等,实现有针对性、行业性、精准性的数据抓取,并支持对采集的文本信息、视频、图片、文档等原始数据进行存储管理。
定向采集主要采用分布式网络爬虫、网页解析、图像识别、语音识别、自然语言处理、知识图谱等关键技术,基于开源网页数据,自动获取网页中的文本、视频、图片、文档等数据。
交互采集主要采用搜索引擎、智能主题推荐、用户行为学习、信息置信度评估等关键技术,根据用户关注点,从互联网中搜集并聚焦用户感兴趣的数据。
(2)开源信息清洗处理
通过互联网开源信息采集将海量信息和数据采集之后,对数据进行分拣和预处理,实现网络数据加智与利益的更大化、更专业化的目的。使得不同来源的数据格式相对统一、关联标识清楚,在一定程度上减少后续数据存储处理量,方便更为复杂的业务处理,为业务分析应用提供必要支撑[1]。
开源信息清洗处理的主要针对采集到的原始互联网信息进行一系列的预处理加工,为后续信息分析挖掘工作提供数据支撑。面向开源信息采集过程中用户踪迹与习惯的隐蔽等方面的安全需求,采用病毒查杀、深度清理等手段对采集的开源信息检测和处理,确保数据安全。提供木马/病毒检测查杀和文件检测与清洗、文字翻译、语义识别、自然语言处理、重复数据检测、自动分类、内容抽取、自动摘要、数据标识等功能。
其中数据清洗与语义识别是预处理过程中的关键步骤,数据清洗目前主要采取样本分析和内容过滤等方式,对垃圾信息进行辨别和分离。通过人工制定判别规则和机器学习相结合来识别目标数据,然后通过精确的数据抽取算法,精准定位目标数据,从而消除垃圾数据。语义识别主要采取中文分词技术、文本特征提取技术、情感分析和意图识别等技术结合各种分类模型与深度学习算法实现[2]。
(3)开源信息分析挖掘
经过预处理的开源信息数据,需要进一步进行分析挖掘,从海量数据中提取出有价值的信息,将这些信息合并,搜索隐藏于其中的潜在的有用的信息,这些信息是有潜在价值的,是各类用户可理解的、可运用的,支持辅助决策,可以为用户带来利益,或为科学研究寻找突破口。通过人工智能、深度学习、大数据分析等前沿技术构建良好的实体标签体系、先验知识库、建模分析库等数据分类、处理和分析工具集,提供数据聚合、关系分析、统计分析、态势分析、时间序列分析、关联图谱分析、二三维空间分析等分析工具,为挖掘更精细、价值密度更高的开源信息提供手段。
(4)开源信息综合显示
针对庞杂的开源信息以及分析挖掘成果,构建形象生动、层次丰富、操作便捷的可视化场景,实现大批量、多图层、高实时、高并发的开源信息可视化生成与操作,能够按照区域、类别和主题等不同内容,形象生动的展示开源信息及信息内在关系、演变趋势,为用户理解、掌握和利用开源信息提供支撑。
1.3 典型业务流程
按照互联网开源信息智能采集与分析平台技术体系与能力构成,可以划分为开源信息智能采集、开源信息清洗处理、开源信息分析挖掘、开源信息综合显示等典型流程。
(1)开源信息智能采集流程
主要解决来源于新闻网站、社交媒体、门户网站、研究机构网站等关于开源信息的近实时数据搜集问题,主要包括数据源管理设置、开源数据抓取、数据采集频率配置、数据采集监控等操作。如图2所示。
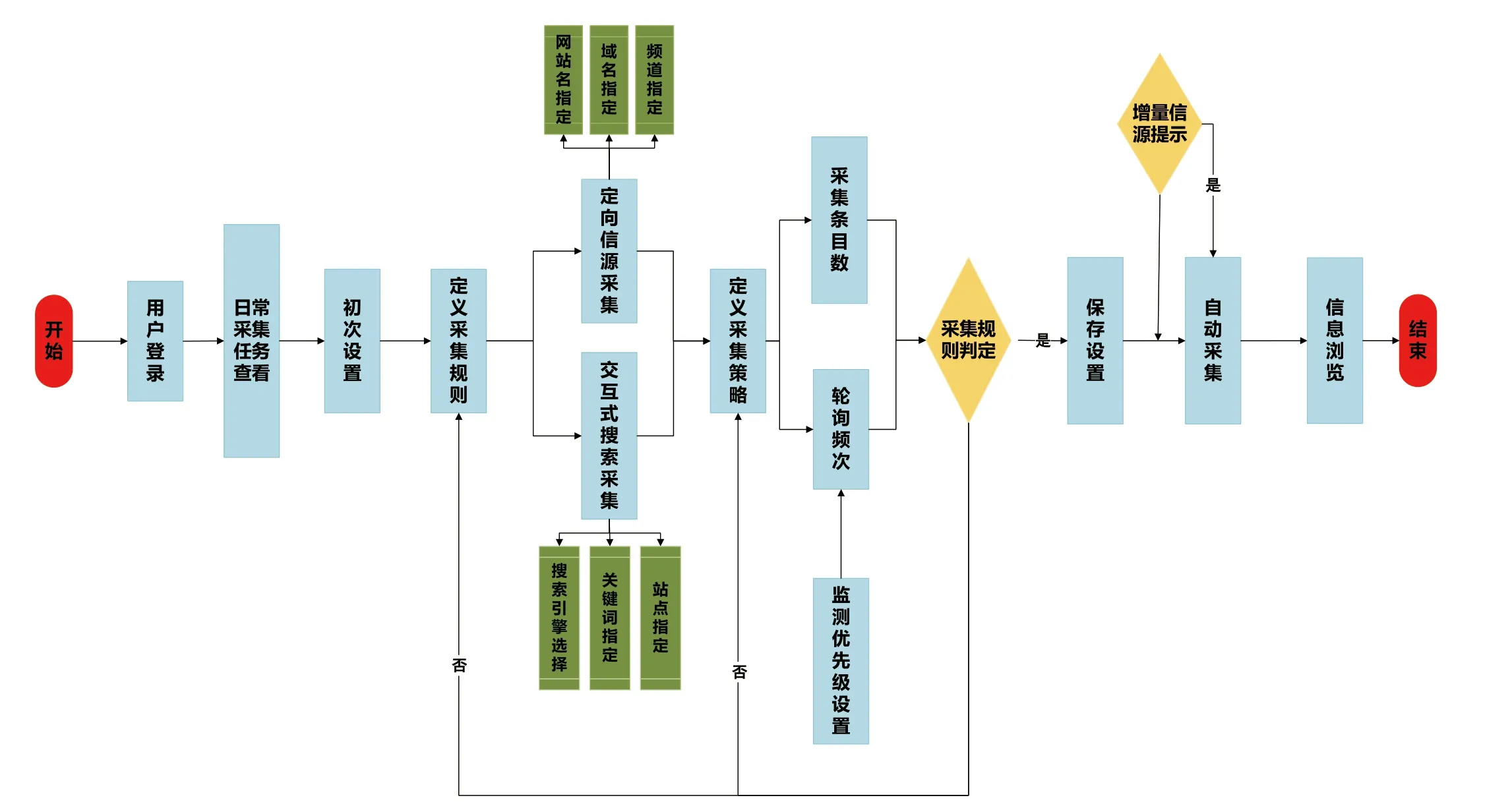
图2 开源信息智能采集流程
(2)开源信息清洗处理流程
主要解决将多源异构的开源信息治理形成格式化、计算机程序可自动化处理分析的结构化数据,主要包括文本数据、图像数据、视频数据、文档数据的自动去重、自动抽取、自动提取关键字和摘要信息、图像识别和标注、提取视频相关文字信息、OCR文字识别等操作。如图3所示[3]。

图3 开源信息清洗处理流程
(3)开源信息分析挖掘流程
主要提供数据分析人员基于搜集整理的开源信息数据,提供时空序列分析、信息关联分析、知识图谱分析、统计分析、动态分析、趋势分析、态势分析、规律挖掘等大数据分析模型及工具,支撑用户动向研判、监测预警以及辅助决策等开源信息应用和分析研究工作。如图4所示。

图4 开源信息分析挖掘流程
(4)开源信息综合显示流程
主要解决复杂开源数据的管理与展示问题,结合二三维地理、时空序列、统计图表、知识图谱、动画、文字等多种可视化表达方式,按照区域、类别和主题等不同内容,形象生动的展示开源数据及数据内在的关系,为用户理解、掌握和利用开源信息提供支撑。如图5所示[4]。

图5 开源信息综合显示流程
2 结束语
互联网开源信息的特性决定了其采集过程、分析过程必定以智能化、自动化分析为主,人工分析为辅助,互联网开源信息智能采集与分析平台从设计与研发上全面采用人工智能与深度学习、大数据分析挖掘、高并发实时处理等前沿技术,构建良好的开源信息采集、清洗处理和分析挖掘能力体系。
互联网开源信息智能采集与分析平台能够降低开源信息使用人员的主观因素影响、迅捷找到想要的开源信息、充分挖掘隐藏的高价值信息。本文提出的互联网开源信息智能采集与分析的技术架构及能力体系,能够为互联网开源大数据应用领域提供有价值的参考。
猜你喜欢
民用飞机设计与研究(2020年4期)2021-01-21
创新作文(1-2年级)(2019年3期)2019-09-03
软件和集成电路(2019年7期)2019-08-30
文苑(2018年23期)2018-12-14
电子制作(2018年18期)2018-11-14
文苑(2018年19期)2018-11-09
文苑(2018年17期)2018-11-09
文苑(2018年21期)2018-11-09
山东工业技术(2016年15期)2016-12-01
办公自动化(2016年18期)2016-08-20
