
说话人特征约束的多任务卷积网络语音增强
2021-02-28 06:20张林濮邵玉斌杜庆治
小型微型计算机系统 2021年10期
龙 华,张林濮,邵玉斌,杜庆治
(昆明理工大学 信息工程与自动化学院,昆明 650500)
1 引 言
语音增强(Speech Enhancement,SE)是声学研究中的一项重要任务和课题,它的目的是在给出带噪语音的条件下,尽可能从中恢复不带噪的干净语音.语音增强的方法种类繁多,传统的单声道语音增强算法主要分为时域和频域方法.时域方法如基于参数和滤波的方法,主要利用滤波器估计发声器官的声道参数和激励参数[1].频域方法主要基于短时谱估计,如:谱减法[2],维纳滤波法[3],最小均方误差法[4]等.
近年来,深度学习成为语音领域的研究热点.深度神经网络(DNN)被广泛应用于语音识别,语音合成,说话人识别等领域.因为深度学习在图像识别领域的巨大成功,研究人员开始在语音增强方向应用类似的方法并取得成功[5].尽管神经网络在语音增强中很大程度提高了降噪音频的质量,但在这些模型中,增强过程在对背景噪声抑制的同时,也对原始信号造成了较大的破坏.
说话人识别(Speaker Recognition,SR)又称声纹识别,同样是语音识别任务中具有很大研究价值的方向.声纹识别已经成为身份认证领域的重要手段,声纹这一生物特征以经成功应用于监控、安全解锁、智能手机以及智能电器声控操作以及司法认证等领域.目前,神经网络包括d-vector[6],x-vector[7]等模型已经在说话人识别领域取得了成功.这些模型在理想无干扰或者高信噪比条件下均取得了比较满意的效果.但是,说话人识别任务在干扰环境特别是低信噪比干扰条件下的识别率迅速下降.虽然x-vector在数据集上做了加噪与加混响处理[8],但是这种方法更多是出于数据增强方面的考虑的,而且加入的噪声能量相对较小,面对低信噪比环境效果依然不理想.所以,面对真实情况下复杂的噪声类型以及信噪比环境,对语音进行预处理以及增强,提高说话人识别系统在噪声环境下的鲁棒性是很有必要的.文献[9]中利用DNN 网络拟合干净语音和带噪语音的i-vector特征矢量的非线性函数关系,获得干净语音i-vector的近似表征,降低了噪声对说话人识别的影响.文献[10]中将带噪语音的梅尔频谱倒谱系数(Mel frequency cepstrum coefficient,MFCC)和理想二值掩蔽(Ideal Binary Mask,IBM)与对数功率谱一起拼接并输入DNN网络中,预测对应干净语音的这3项特征.相较于仅估计纯净语音对数功率谱的单任务模型,该框架对目标函数添加了额外的约束,提高了语音增强的效果.文献[11]设计了一种去噪自动编码器,并在其上叠加一个深度网络形成深层结构,用这个神经网络结构替换传统i-vector的高斯混合模型.
受上述工作启发,本文提出了一种基于多任务学习的卷积神经网络语音增强模型.在多任务框架中,该模型不只学习带噪语音与干净语音的对数功率谱之间的映射关系,同时将离散的说话人标签作为网络的另一个输出.并且把语音的连续特征(如MFCC,基音周期)作为多任务学习中的辅助任务,希望能给网络提供更多的信息,并且作为限制项对输出的功率谱做一个约束,从而提高语音增强和说话人识别效果.
2 基于CNN的频谱映射模型
卷积神经网络(Convolutional Neural Network,CNN)近年来在图像识别领域取得了巨大的成功,并大规模应用于商业项目[12].CNN的原理是基于对生物视觉习惯和神经网络的一种模拟,并对大脑皮层中的局部感知做一种近似.相较于标准的全连接DNN模型,CNN可以更好地适应音频信息中时域和频域维度的变化,并克服语音信号中不稳定环境与非平稳噪声的影响[13].此外,由于CNN的卷积层采用了参数共享和稀疏连接的原理,相比于DNN,CNN模型(如图1所示)的参数数量也大规模减少,提高了训练和运算速度,使得其能在性能较弱的设备上更好的运行.
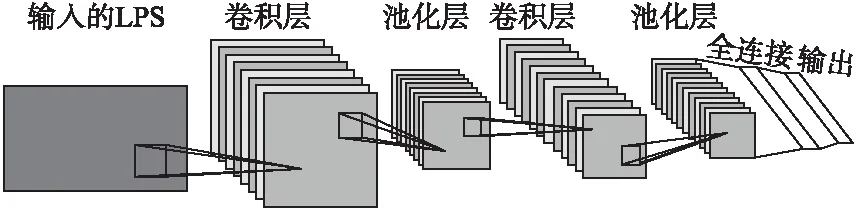
图1 CNN模型结构
假设有一段干净语音和一段噪声,那由它们得到的加性带噪语音为:
y=x+n
(1)

频谱特征提取及语音重构流程如图2所示.语音信号x和带噪语音y经过分帧处理后的短时傅里叶变换(Short-Time Fourier Transform,STFT)记为X(n,k)和Y(n,k),其中,n=1,2,…,N代表帧数.k=1,2,…,K代表频带维度,傅里叶变换的点数为D,因为傅里叶变换具有对称性,故幅值谱的有效频带维度K=D/2+1.语音信号的STFT的复数序列形如:

图2 频谱特征提取及语音重构流程
X(n,k)=Xr(n,k)+jXi(n,k)
(2)
Xr和Xi分别为STFT域上的实部和虚部.则其幅值F和相位φ的计算公式为:
(3)
(4)
Fx(n,k)=|X(n,k)|
(5)
因为人耳对音频信号的感知是非线性的,故一般对幅值谱取对数来增强振幅微弱的部分,则得到对数功率谱(Logarithmic Power Spectra,LPS):
Px(n,k)=log(Fx(n,k))
(6)

(7)
首先需要对估计的LPS进行指数操作恢复为功率谱:
(8)
因为对干净语音LPS的相位估计比较困难,而且实验表明人耳对相位变化的感知不明显,所以我们采用带噪语音的相位来对干净语音进行重构:
(9)
(10)
其中,K为上面提到的傅里叶变换的有效维度.
3 基于多任务学习的CNN声学模型
3.1 融合网络多任务学习
多任务学习(multi-task learning,MTL)概念的提出是相对于标准的单任务学习模型的.传统的单任务模型一次只优化一个目标函数,针对单个任务.而多任务学习通过共享一些隐藏层的参数,来获取多个任务之间的关联性信息[14].
带噪语音中不只混有语音与噪声的信息,也含有不同说话人之间的音调、音色差异等信息.语音增强任务注重提取干净语音之间的相似性,并区分语音与噪声的差异.说话人识别注重区分不同说话人在语音信号中的个人特征,如发音习惯,音色等.因此,利用多任务学习的参数共享机制,通过神经网络模型让语音增强任务和说话人识别任务能够获得彼此之间的隐含信息.两个任务之间的特性与共性也通过该机制体现,并可以对各自的训练提供帮助.

(11)
这些线性函数的参数记为Λ,网络就可以通过将ΛAB和ΛBA设置为0,来结束共享;通过将ΛAB和ΛBA附上更高的值来提高共享的程度.注意我们只在CNN的池化层或全连接层进行参数共享.
Λ是可以通过训练学习的参数.因为单元内的函数为线性组合,所以损失函数L对于Λ的偏导可以按如下计算:
(12)
(13)
融合网络多任务学习和CNN模型结构如图3所示,本文设计的CNN模型包含多个卷积层和全连接层,其中每个卷积层和全连接层之后需要进行非线性变换操作,我们选择线性整流函数(Rectified Linear Unit,ReLU)作为激活函数.卷积核的大小均为3×3,卷积核数量为64-64-128-128-256,步长均为1×1.池化层均采用最大池化(Max-Pooling),大小为2×2.卷积层之后为两个全连接层,节点数量均为512.最后,语音增强任务的输出层为包含101个节点的全连接层,说话人识别任务的输出层也为全连接层,节点数量与训练集说话人数目保持一致,最终通过softmax函数输出.

图3 融合网络多任务学习CNN模型结构
3.2 特征联合辅助训练
在基于CNN的语音增强中,优化的目标函数为对数功率谱上输入输出之间的最小均方误差[16,17].在对数功率谱域中,不同频率之间是独立假设的,各个维度的相互关系没有被考虑,模型的预测缺乏约束,也不利于对人耳的听觉特征的模拟与感知[18].
在本节,我们通过引入辅助学习(Auxiliary Learning)的方法来间接的优化目标函数.在多任务学习框架中,如果主任务的数据维度高,不相关特征较多,会对模型的拟合造成更多的困难.辅助任务对模型的训练添加了约束,使得模型能将注意力更加集中于那些与结果紧密相关的特征.所以,辅助任务的引入让模型不仅学习干净语音的LPS,同时学习如梅尔频谱倒谱系数和基音周期这样的连续特征.
MFCC是常见的用于语音识别,声纹识别和情感识别等任务的语音特征.MFCC的计算过程中,在倒谱上应用了跟人耳感知音高变化等距的梅尔滤波器组,凸显了声音中的低频部分,并且强调了相邻帧之间的联系.在MFCC中,梅尔三角滤波对语音频谱进行了平滑化,消除了谐波的作用,也使得语音的共振峰得到凸显.因此MFCC并不反映一段语音的音调或音高,所以说,如果将MFCC 作为一个语音辨识系统的输入特征,结果并不会受到输入语音音高的影响.但实际上,音高的变化可以表示出不同说话人发音习惯上的不同,是描述语音激励的一个重要特征.
基音(pitch)反映了人在发浊音时声带振动的周期性,而基音周期为声带振动频率的倒数.说话人声带的薄厚,韧性,长短等与基音周期有很大的关系,所以基音周期在很大程度上反映了说话人声音的个性.
本文采用小波变换法提取基音周期.由于小波变换对信号中频率和时间分辨率特性与人耳的时频分析特征极为类似,并且语音信号的小波变换极值点对应声门的开启和闭合点.所以基音周期就可以用小波变换中相邻极值点之间的距离估算.信号中的突变位置反映在零点或极值点上.于是,根据小波信号中的奇异点,就可以实现对基音周期的检测.
3.3 自适应损失
多任务学习中,多元回归和分类任务通过从共享的表示中学习多个目标来提升效率,预测精度和泛化能力.但是,不同的任务之间尺度是不同的,这就涉及到多任务学习中不同单位尺度任务的目标函数的联合学习.所以,多任务学习中很重要的一个问题是如何设计损失函数,平衡不同类型的任务,避免在训练过程中整个模型被某一个任务主导.这就涉及到为不同任务的损失函数赋上不同的权重,将不同任务的损失统一成一个损失函数.常规方法是将各任务的损失简单相加或者设置统一的权重,见式(14):
(14)
更进一步,可能会手动的进行权重调整,这样会造成最终模型在有些任务上表现很好,而在其他任务上效果较差.
文献[19]介绍了一种利用同方差的不确定性(Homoscedastic Uncertainty)自适应调整不同损失函数权重的方法.同方差的不确定性属于偶然不确定性,这种不确定性捕捉了不同任务之间的相关性置信度,所以这种不确定性可以作为不同任务损失权重赋值的衡量标准.
假设fw(x)为神经网络在输入为x、模型参数为w时的输出,y为对应的正确输出.在多任务情况下,得到K个离散回归任务的最大似然:
(15)
(16)
其中,每个模型都遵循带有噪声标量σ的高斯分布.对于分类问题,通常会通过softmax函数输出,如下式所示:
p(y|fw(x))=softmax(fw(x))
(17)
所以最大似然的估算可以表示为下式中最小化模型的负对数似然:
-logp(y1,y1,…,yk|fw(x))∝

(18)
求得softmax分类的似然估计:
(19)
以两个输出连续性y1和离散型y2为例,分别用高斯分布和softmax建模,可得损失函数:
(20)
指定每一个任务对应的损失函数Li(w)=‖yi-fw(x)‖2,则最终多任务模型的联合损失为:
(21)
当噪声σ增大时,相对应的权重就会降低;反过来,随着噪声σ减小,相对应的权重就要增加.
4 实验设计与结果分析
4.1 实验设置
本实验采用的语音数据为Free ST Chinese Mandarin Corpus中文语音库,均为重采样到8000Hz频率、单通道的干净语音.Free ST Chinese Mandarin Corpus语音库包含855个说话人的每人120条,总计10余万条的中文普通话语音数据.采用的噪声数据来自ESC-50噪声库[20],包括50类、每类40条的噪音.
关于带噪语音的合成,将每一条语音库中的干净语音,分别按-5dB,-2dB,0dB,5dB,10dB与噪音混合.其中,噪音是从ESC-50的50类噪音中随机挑选一类,并随机截取与干净语音等长的片段,按照信噪比调整噪音能量,然后与原始语音混合.
语音预处理部分,先对原始语音利用谱熵法进行端点检测(Speech Activity Detection,SAD);之后对信号进行分帧,帧长与STFT的点数保持一致,为200点(25ms);帧移为80点(10ms).之后在每一帧信号上加汉宁窗(hamming window)并计算STFT.MFCC变换中的STFT与上述保持一致,梅尔滤波器的个数为40.
测试集中的干净语音来自Free ST Chinese Mandarin Corpus中与训练集不重叠的127个说话人的254条语音;噪音来自ESC-50中的3种与训练集不重叠的6段噪音,分别是Laughing、Wind和Train类噪音.测试集的干净语音按照-5dB,0dB和10dB的信噪比分别与不同种类中随机截取的噪声混合,总计得到大小为4572条的带噪测试集.
本实验采用感知语音质量(Perceptual Evaluation of Speech Quality,PESQ)、短时客观可懂度(Short Time Objective Intelligibility,STOI)和分段信噪比(Segmental SNR,SSNR)作为语音增强结果的评价指标.其中,PESQ偏重于增强语音的总体质量,是评价语音质量常用的标准方法,得分介于-0.5~4.5之间,越高代表语音质量越好;STOI是近几年语音增强领域常用的评价语音可懂度的指标,得分介于0到1之间,越高代表可懂度越好;SSNR代表了增强之后语音的信噪比,越高代表增强语音的干净程度越高.
4.2 实验测试
为了验证本文提出模型的效果,本实验设计了基于DNN的语音增强模型的基线,模型采用LPS作为输入输出特征,其中每个输入为包含上下文共11帧的LPS,输出为对应的干净频谱的中间帧.模型共有4个隐藏层,每个隐藏层包含2048个节点,激活函数为ReLU;只包含语音增强和说话人识别两个主任务的CNN模型记为CNN-Mul;本文提出的包含两个主任务和辅助任务的CNN模型记为CNN-Mul-Aux.模型CNN-Mul-Aux的辅助训练中,我们将带噪语音的MFCC和基音周期与输入端的LPS拼接在一起,并将干净语音的MFCC和基音周期拼接在语音增强的输出端.
表1、表2和表3分别在Laughing、Wind和Train类噪音下对模型性能进行了对比.从表1-表3可以看出,CNN增强模型在3种噪声下均实现了不错的效果,除了10dB的Train噪声下的SSNR外,CNN在不同SNR级别以及环境下的各指标要一致的比DNN都要好.并且CNN在噪声的滤除上也比DNN实现了更好的效果,说明CNN确实更好的利用了LPS频域和时域的相关性,使其可以更好地估计语音中的平稳与非平稳噪声.另外,加入辅助任务的CNN-Mul-Aux模型在各项指标上均好于未加入辅助任务的CNN-Mul模型和DNN,说明将MFCC特征和基音周期拼接在输入输出端确实可以显著提升模型的增强效果,并且可以避免模型在单独的LPS任务上过拟合,从而增强模型的鲁棒性.

表1 Laughing噪声下的语音增强性能测试

表2 Wind噪声下的语音增强性能测试

表3 Train噪声下的语音增强性能测试
如图4所示分别为各模型对带噪语音进行增强之后的结果的对数功率谱图对比,可以更直观的体现增强效果的差异.我们取一段加入-5dB的Train噪声的语音并用各个模型进行增强,图中从上到下依次为干净语音、带噪语音以及模型增强之后的对数功率谱图.其中,横轴代表分帧之后的帧数,纵轴代表频率,Z轴代表信号在相应频率的振幅.
从图4中几种算法的对数功率谱结果对比可以看出,采用CNN算法增强后的语音纯净度比DNN更高,对噪声的抑制效果更好.另外,CNN-Mul-Aux相较于未加入辅助任务的CNN-Mul模型,更好的保留了原始语音的信息.

图4 对数功率谱结果对比
本文通过x-vector说话人识别算法来评估经过增强后的语音在说话人信息上的失真程度.搭建的模型框架基于Kaldi工具箱,训练集采用AISHELL-1中文语音数据集[21].x-vector与CNN说话人识别模型在测试阶段均取softmax之前的向量并进行概率线性判别分析(Probabilistic Linear Discriminant Analysis,PLDA)打分.注册集为Free ST Chinese Mandarin Corpus中与训练集不重叠的127个说话人的1270条语音,测试集来自相同说话人的另外2540条语音.采用的性能评价指标为等错误率(equal error rate,EER)和最小检测代价准则(minimum detection cost function,DCF).DCF函数计算公式如下:
DCF=CFREFRPtarget+CFACFA(1-Ptarget)
(22)
CFR与CFA分别为错误拒绝和错误接受的惩罚系数,Ptarget与(1-Ptarget)分别为真实说话测试和冒充测试的先验概率.我们采用NIST SRE 2016设定的CFR=1,CFA=1,Ptarget=0.001这组参数.当这3个值选定后,选取一组FRR与FAR的取值使得DCF最小,此时的DCF即为minDCF.本文中采用NIST SRE 2016设定参数的minDCF记为minDCF16.因为minDCF16不仅考虑了两种错误不同代价,还考虑到了测试情况的先验概率,因此在评估说话人识别模型的性能上比EER更加合理.
为了验证本文提出的模型的说话人识别性能,本文对比了几种不同的方法.其中,x-vector为用x-vector模型直接识别带噪语音的结果;DNN-x为经过DNN增强之后的语音在x-vector模型上的结果;CNN-ori-x为未加入辅助任务的多任务CNN模型增强之后的语音在x-vector模型上的结果;CNN-x为经过本文提出的CNN模型增强之后的语音在x-vector模型上的结果;CNN-direct为本文提出的CNN模型直接进行说话人识别的结果.各算法的在不同信噪比下的EER以及minDCF16如表4所示.
由表4可知,噪声环境下,尤其是低信噪比情况,x-vector的识别效果受到了较大的影响,说明对带噪语音进行预处理是有必要的.经过DNN增强之后的语音在x-vector上的识别率有了较大提高,但是效果依然不理想.另外可以看到,尤其在-5dB情况下,CNN增强之后的识别率要显著高于DNN模型,说明融合网络的说话人识别任务通过参数共享给增强模型提供了更多的说话人信息.这其中,CNN-x的效果要好于CNN-ori-x,说明辅助任务帮助CNN语音增强保留了更多的说话人信息;CNN-direct模型的效果要略好于CNN-x模型,原因可能是CNN的识别效果要好于x-vector中的TDNN、x-vector中的统计池化层(Statistic Pooling)和因为训练集的不同所导致的信道差异.

表4 说话人识别性能测试结果
5 结 论
在本文中,针对传统语音增强模型中忽略说话人信息的问题,研究了噪声干扰下的语音增强技术及对说话人识别的影响,提出了一种基于多任务和辅助任务约束的卷积神经网络语音增强方法.通过构建语音增强与说话人识别的融合网络多任务学习模型,同时在输入输出端拼接MFCC和基音周期特征,以及利用同方差不确定性自适应调整损失权重,显著提高了语音增强的效果,减少了去噪语音的失真,并在噪声干扰下的说话人识别任务上取得了优秀的表现.
猜你喜欢
应用心理学(2022年5期)2022-11-05
现代仪器与医疗(2022年1期)2022-04-19
北京大学学报(自然科学版)(2022年1期)2022-02-21
现代信息科技(2021年21期)2021-05-07
语数外学习·高中版中旬(2021年12期)2021-03-09
语数外学习·高中版上旬(2020年8期)2020-09-10
速读·中旬(2017年8期)2017-09-04
新高考·高一数学(2016年10期)2017-07-06
中国新技术新产品(2016年23期)2016-12-26
科技视界(2016年11期)2016-05-23
