
结合图卷积神经网络的文献作者姓名消歧
2021-02-28 06:20聂铁铮申德荣
小型微型计算机系统 2021年10期
施 浓,聂铁铮,申德荣,寇 月,于 戈
(东北大学 计算机科学与工程学院,沈阳 110169)
1 引 言
近些年来,由于学者拥有相同的姓名,所以出现了越来越多属于不同的学者,但却拥有相同的学者姓名的文章.大量重复的作者姓名,降低了数字图书馆、web检索信息的性能,从而导致错误地认为某几篇文献是同一位作者所写.针对这种情况,传统的处理方式是由人工的进行确认,因此需要做大量的繁琐工作,浪费大量人力资源.还有一些机构采用了名称标识的方式,给作者分配一个唯一的标识符,但仍存在有大量文章作者没有标识的问题.因此迫切需要提出切实有效的方法,实现可自动化对作者文献进行聚类,进行正确的归属.
解决这类问题,常用思路是使用聚类的方法,从论文中提取特征,定义聚类相似度度量,从而将一堆论文聚成几类论文.聚类得到的论文簇要尽可能的相似,而聚类与聚类之间的论文应不属于同一作者,最终得到的每一个聚类论文是属于同一学者的论文.例如,文献[1]是使用图聚类解决同一姓名问题的经典方法,利用论文之间的结构以及属性关系等信息去构建统一的概率图,最后通过算法估计聚类人数值.文献[2]考虑到使用传统特征具有局限性,因此采用低维语义的空间向量表示方法,通过将论文映射成低维空间的向量表示,使用基于特征向量的聚类方法,但是其聚类的准确度不是很高.
当前,针对作者姓名消歧技术的研究具体有如下几个问题:1)由于作者和文献均是不同的来源,并且很有可能没有重叠的信息,如何对来自不同数据源实体进行量化;2)如何确定几篇文献是否属于同一作者,量化几篇文献的相似性;3)如何确定每一个作者文献的数量.
本文设计一个框架来更好的解决作者姓名消歧的问题,研究结合最新的嵌入模型,量化的捕捉文本之间的关系,该方法将每篇文献实体投影到一个空间向量中,每篇文献都作为一个节点;为了确定几篇文献是否属于同一作者,本文提出将作者姓名消歧的聚类问题,转换成为基于链接的聚类问题,根据节点的上下文来推测节点与其邻居之间的链接可能性,提出使用图卷积网络(GCN)的可学习的聚类方法;最后,根据GCN输出链接可能性,本文采用伪标签传播策略,不需要输入簇的数量,可传递的合并链接的节点并获得聚类结果.文献作者姓名消歧方法框架如图1所示.
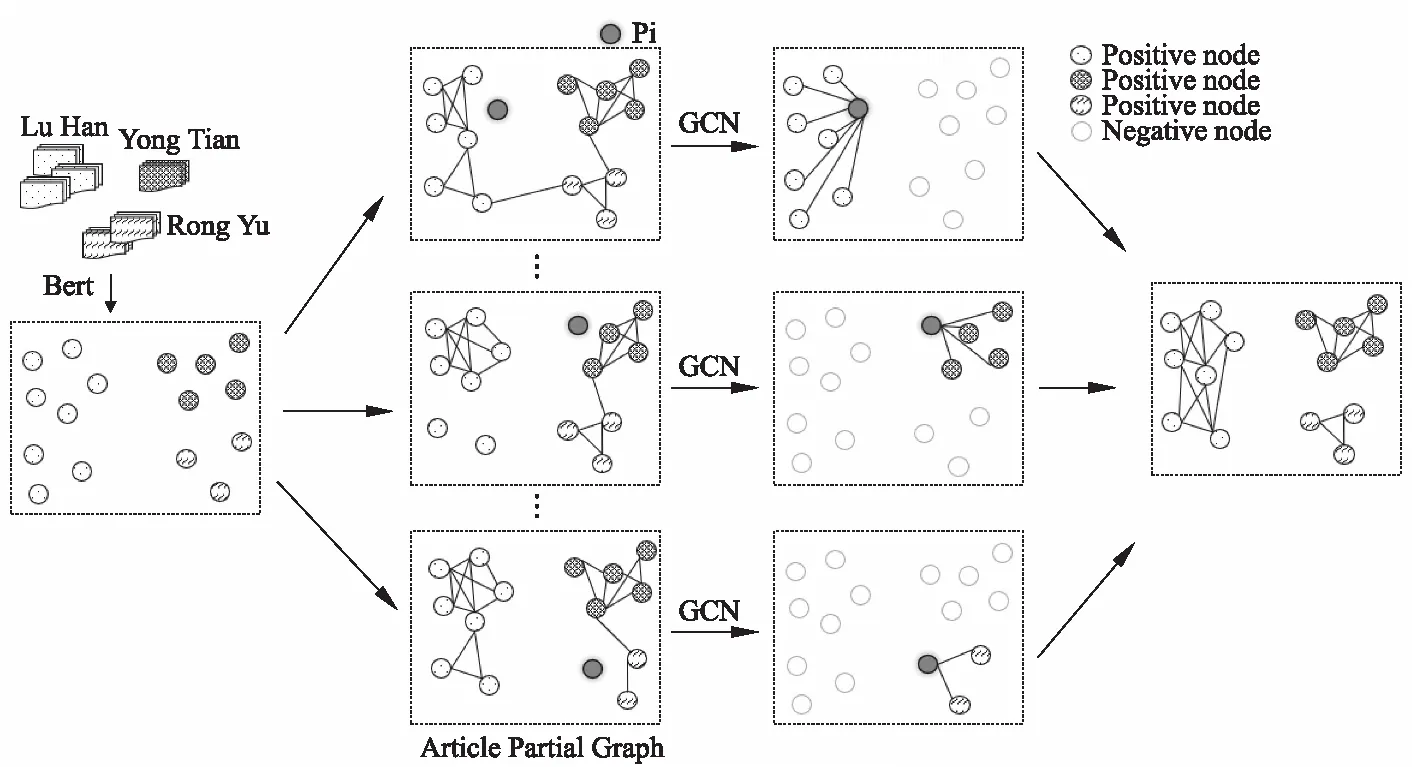
图1 文献作者姓名消歧方法框架
2 相关工作
在文献检索中,多个作者拥有相同的姓名,相同的研究方向或者其他一些属性相似,这是很正常的现象,但这种现象可能会导致人们错误的引用文献、检索结果不准确,数据库集成的性能等问题.实体消歧的主要任务是将属于同一个姓名多个人的文献进行分区,每个区域都是由唯一一个人的文献组成.命名实体识别消歧通常可以被看作是一个聚类问题[1],和其他聚类的任务一样,如何确定是否相似、聚类的大小是主要的两个挑战.在作者姓名消歧问题中,如何量化相似性是急需解决的一个问题,现有的解决方案可大致分为两类:一种是基于数据的特征,另一种是基于连接.
基于特征方法的文献有很多,比如,Han等人[3]提出使用作者姓名,文章标题,以及会议或期刊名等特征,采用支持向量机等监督方法对作者姓名进行消歧.Zhang等人[4]利用文献作者姓名包括合作者姓名、文献标题、出版地点或期刊、出版时间等作为特征进行提取,并计算特征之间的距离,使用特征和距离相结合的半监督概率模型,解决作者消歧问题.MinoruYoshida[5]提出两阶段聚类的方法,采用命名和关键词等信息进行相似度计算,将计算结果进行聚类,第1次聚类完成后,再提取相应特征进行第2次聚类.Liu等人[6]主要使用的是元路径,基于元路径来确定两个实体的相似度.元路径的图形需要自己制定,可以转化为矩阵运算的问题,最后基于不同图案的元路径相似度加权求和进行最终的决策,本质仍然是基于传统的特征工程,里面除了包含大量的特征工程外,将元路径引入其中,可以将路径中的隐藏关系以及路径中跨度加大的关系加入进去.文献[7]提出两个策略:一个分类器训练一个name,一个分类器训练所有name.使用ELM(极限学习机)技术使用作者姓名,标题作为特征向量,但因为特征维度较大,所以使用了PCA进行降维.
基于链接方法的文献有TanayKumarSaha[8]提出的一种从协作网络获得时间戳得连接信息来解决实体消歧任务的方法,该方法使用匿名网络的拓扑图,不侵犯隐私.文献[9]受到词嵌入的影响,利用作者名,文章名构建了3个图,同时采用一种新的表示学习模型,将每一个文档嵌入到一个低维的向量空间中,在这个空间中,名字消歧使用层次聚集聚类算法进行解决.Zhang等人[9]提出文献全部属性和局部属性相结合的方法,首先利用文献的部分属性信息将所有文献都表示在一个统一的向量空间中,使用图自编码器对已经构建的局部链接图进行学习得到待消歧姓名文献集的最终向量表示,最后利用得到的向量进行聚类分析.
本文结合上述两种方案的优点,使用BERT[10](Bidirectional Encoder Representation from Transformers)对文献的多个特征进行词和句子的嵌入,将文献的作者、所属机构和摘要等特征嵌入到一个低维的向量空间中,结合将词嵌入和句子嵌入进行结合,量化特征,使得到的特征向量更为准确.然后进行文献局部图(Article Partial Graph)的构建,将聚类问题转换为链接问题,使用GCN进行自动学习文献之间生成链接的可能性.
第2个挑战是如何确定聚类的大小,以前的大多数文献都是假定该数字是事先已知的,并且在解决方案中忽略这个问题.现有的文献中有一些使用诸如DBSCAN的聚类方法来避免提前设定聚类的大小,但仍需要提前指定几个基于密度的超参数.唐等人[1]对X-means算法进行改进,通过贝叶斯信息准则(BIC)来测量聚类质量,从而迭代的估计最优的聚类大小.但是,有一些实验表明,基于BIC的方法倾向于将聚类合并在一起,而且缺少比较好的离群值控制,因此导致准确性降低.在本文中,为了将文献更准确的聚类在一起,根据文献的链接权重信息,在图上使用连通域搜索并动态剪枝进行聚类.
3 问题定义
3.1 文献定义
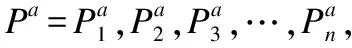
定义1.(名称消除歧义)作者消除歧义是找到一个方法F,将Pa划分为一组不相交的簇,例如:
(1)
3.2 K-NN连接
本文提出构建文章局部图的原因是:只需要计算一个实例与它的k个最近邻居之间的链接可能性,就可以产生很好的聚类效果[11].不同k值的聚类性能的上限都很高,如果邻居与该实例具有相同的作者,则直接将每个实例与其k-NN连接,预测实例与其k-NN之间而不是所有潜在对之间的链接更加有效.
姓名消除歧义工作的重点在于消歧结果的准确性,因此本文采用预测文献与其k-NN之间的链接的可能性.因为预测是否链接是基于文献所提供的信息和其邻居所提供的信息,所以本文设计了一个名为“文献局部图”(APG)的局部结构.APG是一个以文献P为中心的子图.每个“文献局部图”都是由一个中心节点文献P和P的k个临近邻居组成.
4 方 法
4.1 使用BERT对文献多特征进行嵌入
首先将数据中所有的文献特征都进行表示学习,然后展现在一个统一的向量空间中.如图1所示,每篇文献都由节点表示,比如,文献作者名字有Lu Han使用左侧带点的圆圈节点表示.文献用Pi进行表示,文献的特征由Pi={p1,p2,p3,…,pk}一组长度可变的特征集表示,其中文献的特征由标题、共同作者、出版单位或者期刊、关键词和摘要等多特征构成.输入N篇文献的特征,输出N×K维的特征矩阵,其中K代表维数.
受无监督表示学习技术的启发,本文使用BERT(Bidirectional Encoder Representation from Transformers)模型[10]进行全局表示学习.本文考虑到一个重要的特征文献摘要,由于文献摘要句子过长,得到嵌入表示不够准确,前人研究时都选择忽略掉文献摘要这个重要的特征.而BERT是对文本摘要进行双向的建模,类似于全连接网络输入完整的句子模式,而不是LSTM等RNN网络有序输入的模式,考虑到句子中每个词的位置和词与词之间的相对位置,会更加准确的获得嵌入向量得表示.因此,本文将文献摘要也作为一个特征进行嵌入,使用多特征生成一个嵌入向量,使嵌入结果更加准确.
4.2 构建“文献局部图”
本文需要根据文章中的上下文特征来估计两篇文章之间的链接可能性.在本文中,构造文章局部图APG(Article Partial Graph),APG由3个步骤生成.首先,找到APG的所有节点,然后邻居节点减去枢纽特征来标准化节点特征,最后在节点之间添加边.
第1步.如图2所示,查找节点,给定文献C,本文将使用kNN连接方式进行查找邻居结点,范围到h-hop的邻居作为APG的节点,对于每一跳节点,选择的邻居数量可能会有所不同.将第i个跳跃点的邻居数表示为ki,i=1,2,3,…,h.比如:C是中心节点,那么APG中对于C定义为Gc(Vc,Ec),其中Vc表示G的节点集,Ec表示图G的边集.举个例子:当h=3时,k1=9,k2=6,k3=3,表示APG是由9个距离中心点C最近的邻居组成,每个邻居节点有6个临近的一阶邻居,每个一阶邻居有3个最临近的二阶邻居.如果一个邻居在C进行临近搜索时,始终离得很远,那么这个邻居和C的连接可能性很小.
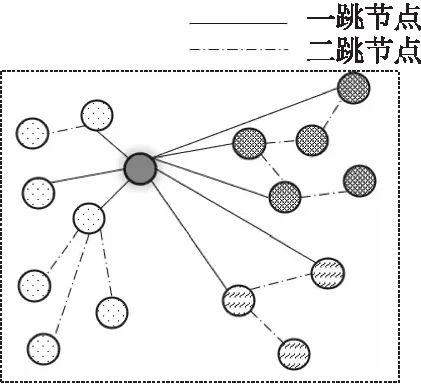
图2 找到节点p的邻居节点
第2步.节点标准化,如图1所示.有了中心节点C,节点集Vc,以及节点的特征Ci,定义其中一个邻居节点{Cq|q∈Vc}.为了标准化各个节点特征,每个节点减去pc来进行标准化.
Ηc=[…,pq-pc,…],∀q∈Vc
(2)
第3步.在节点之间添加边.最后一步是在节点之间添加边缘.对于一个节点q∈Vc,首先在原始整个集合中的所有节点中找到最接近的u个邻居.如果该邻居节点r也出现在Vc中,那么将(q,r)添加到节点边集Ec中.此操作是为了保证节点的集合不会有太大变化.最后,使用Ac∈R(|Vc|×|Vc|)和节点特征矩阵Ηc表示APG的拓扑结构.生成的文献局部图,如图1所示.
4.3 使用图卷积神经网络对APG进行连接预测
APG中节点包含的特征信息对于确定其它节点是否应该连接到文章局部图上有很大的作用.为了充分的确定两个节点边缘是否应该链接,本文应用了图卷积神经网络(GCN)[12],在APG上进行预测.将文献局部图的节点特征矩阵X和邻接矩阵A一起输入到图卷积层,训练后输出节点特征矩阵Y.
在第1层中,输入节点特征矩阵是原始节点特征矩阵X=H.形式上,图卷积层具有以下公式:
Y=σ([X‖GX]W)
(3)
其中,X表示特征矩阵,是输入矩阵维度是N×K维,而Y则是N×K维输出矩阵,激活函数σ使用的是ReLU,G=(P,A)是大小N×N的聚合矩阵,运算符‖表示沿着特征维进行矩阵连接,W表示可学习的权重,σ(.)是非线性激活函数.
图卷积操作可以分为两个步骤:
第1步.将P乘以G,该步骤是为了对节点和节点邻居之间的关系进行汇总.然后沿着特征维度将输入节点特征P与聚合信息GP串联在一起.
第2步.由一组线性滤波器对级联特征进行变换,该线性滤波器的参数W将被学习.其中g(.)用类似于图注意力网络[13],本文试图学习邻居的聚集权重.即,G中的元素由两层MLP使用一对枢轴邻居节点的特征作为输入来生成.MLP是端到端的训练.注意聚合是在邻居之间执行加权平均池,在加权池中自动学习权重.
方案二:选用STM32F103 系列MCU 用于控制方案,使用STM32 MCU 作为核心控制芯片[5],该芯片可以进行扩展,与外设进行连接通信,且控制速度较快,非常利于资源开发。
本文使用的图卷积神经网络是由ReLU功能激活的4个图卷积层的堆栈.然后将softmax激活后的交叉熵损失作为优化的目标函数.实际上,本文仅反向传播一跳邻居节点的梯度,因为仅考虑了枢轴及其一跳节点之间的联系.与完全监督的情况相比,采用节点一跳邻居的方式不仅可导致相当大的加速,而且还可以提高准确性.原因是高阶邻居大部分为负,因此一跳邻居中的正样本和负样本比其他邻居中的样本更加均衡.
为了演示图卷积的工作机制,文本设计了一个具有二维输入节点功能和两个图卷积层的玩具示例.不同的颜色表示不同的ID.虚化的深灰色节点是中心节点.在图3中,本文显示了每一层的输出嵌入如何随着训练迭代而变化.在每个图卷积层之后,正节点(左侧)分组更加接近,而负节点(右侧)形成另一组.这是因为邻居的消息在聚合步骤中传递到节点,并且邻居的消息充当嵌入的平滑度,将链接的节点连接在一起.同时,将正节点组和负节点组分隔开.最终,系统达到其平衡点,在该平衡点上,不同类别的节点彼此远离,同一类别中的节点相互接近.

图3 GCN工作机制
4.4 使用伪标签传播策略聚类相同作者文章
本文遍历所有文献,将每篇文献都构造一个文献局部图,并预测该文章所涉及其他文献之间关联得可能性,节点分类器输出softmax概率.
实验得到了一组关于链接可能性的且带有权重的边.为了得到聚类图,一种比较简单的方法是剪切权重低于某个阈值的所有边缘,然后使用广度优先算法来传播伪标签.但是,在传播的过程中,性能很有可能会受到阈值的影响.因此,本文采用了文献[14]中提出的伪标签传播策略.首先,基于图形中当前边找到连接的文章,并将这个文章添加到队列中.
在每次迭代中,本算法都会在某个阈值以下切割低分边缘,并在其大小保持大于预定义的最大值的链接簇中,维护要在下一次迭代中处理的队列.在下一次迭代中,增加要切割的阈值.重复此过程,直到队列为空,这意味着所有文章都用伪标签标记.
5 实 验
5.1 数据集
本实验采用AMiner提供的数据集,数据集基准测试包含来自12798位作者的70258个文档.数据格式是由一个字典组成,存储为JSON对象.具体来讲,数据集中包括每一篇文献的编号、文章标题、作者个人信息、工作单位、出版地、文章关键词和文章摘要等,具体信息如表1所示.本文从标记良好的AMiner数据库数据中中抽取了100个作者姓名进行实验.
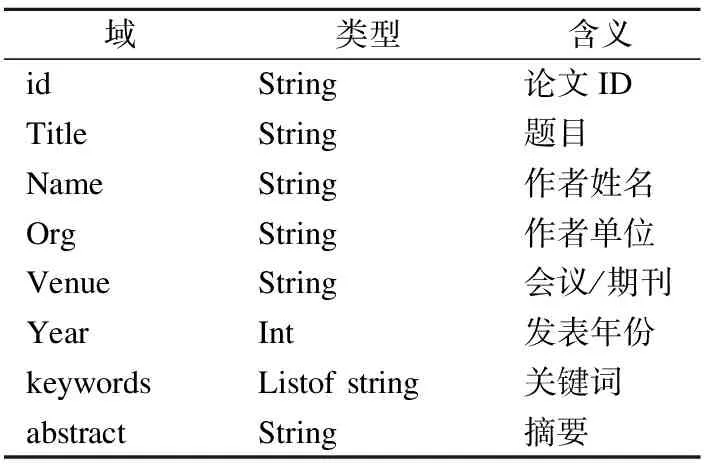
表1 数据集表示信息含义
5.2 评价指标
本文使用Precision公式(4)、Recall公式(5)、F1公式(6)作为评价指标对实验结果进行度量.
除了Precision和Recall以外,本文还使用F1作为评价指标,因为Precision和Recall有时候会出现矛盾的情况,这样就需要综合考虑它们,最常见的方法就是使用F1-measure,当F1较高时则能说明实验方法比较有效.
(4)
(5)
(6)
5.3 实验参数选择
用于APG构造的3个参数:跳跃点h,每一跳中最近的相邻邻居的数目,以及链接的最近邻居u的数量.本文首先用不同的数值进行实验,发现当h=3时不会带来性能提升,因此在以下实验中将h设置为2.同时,本文探索了值不同的ki影响:k2和u.
为了研究k1,k2和u如何影响性能,本文进行了两组实验,结果如图4所示.首先,本文保持u不变,改变k1,k2,并显示F量度是如何变化的.在图4中观察到,当u=10时,随着k1和k2的增大,F度量会增加.k1越大,预测的候选链接越多,因此召回率越高.k2越大,涉及到的2跳邻居越多,因此更精确地描述了1跳邻居的局部结构,因此预测更加准确.但是,当k1和k2足够大时,性能达到饱和.对于参数u,即邻居的链接数,本文在图5中观察到性能对u的值不敏感.考虑效率,k1和k2的值不能太大.经研究发现k1=40;k2=5;u=4产生了效率和性能之间的良好折衷,并在以下实验中使用此设置.

图4 k1、k2取值对F1影响
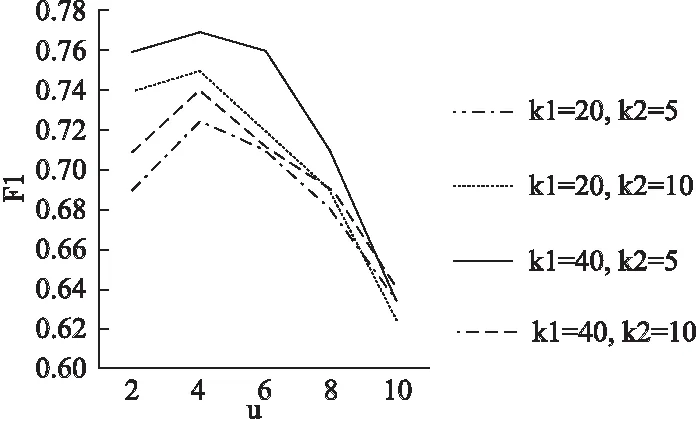
图5 k1、k2、u不同取值对F1影响
5.4 实验结果
实验整体效果提升姓名消歧的准确性,部分结果如表2所示,pubs表示包含该名字的文献数,Cl表示同一个姓名的作者被聚类成多少簇(cluster),P表示的是准确率,R表示的是召回率,F1表示的是F-measure方法.比如:在321篇文献中出现了Bo_Hong这作者名字,实验将其结果聚类为13个簇,聚类结果的准确率为0.84,召回率为0.71,F1值为0.77.
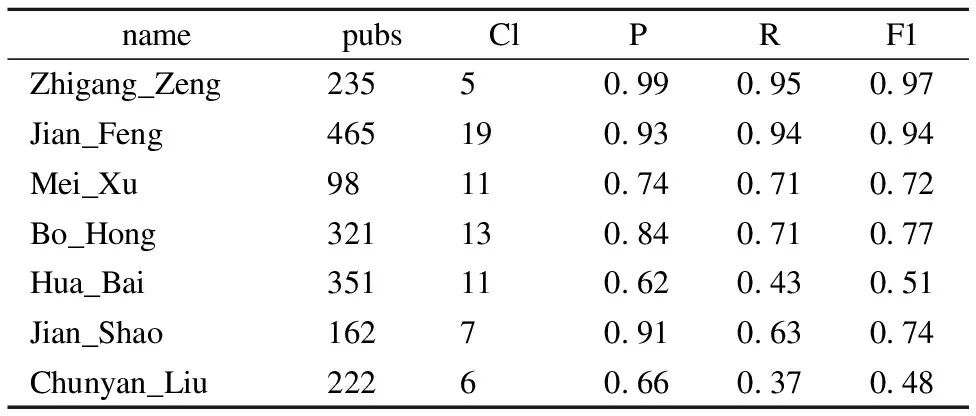
表2 部分实验结果
5.5 对比实验
为了验证本文提出的方法(Our)的性能,下面将本文的方法与其他几种同名消歧方法进行比较.本文提出的方法用"Our"表示,其他研究者的方法使用该文章作者表示.
1)Zhang等人[4]:该方法是基于文章合作者和文档相似性为候选集,构建了3个局部图,通过从图中抽取三元组,为每个候选集学习图嵌入.最终的结果是通过聚集层次聚类进行生成的.
2)GHOST[15]:第2种方法是仅仅基于合作者的名字来进行消歧处理的,并未考虑其他特征.通过将每篇文献的合作者折叠到一个节点,计算两个节点之间的距离,最通过亲和传播算法生成聚类结果.
3)Louppe等人[16]:此方法首先根据一组精心设计的相似性特征训练成对距离函数,然后使用半监督的HAC算法用于确定聚类.
4)Rule:规则的方法是在文献作者和出版地点严格匹配的情况下,通过连接两个文献来构造两个文献的局部链接图,然后将图划分为连通的组件来获得聚类.
如图6展示了在AMiner数据集上,5种不同的作者姓名消歧算法的结果.Our是本文提出的消歧方法,使用F1-measure来评估所有的方法.Louppe等通过学习文章的特征得到相应相似函数,相反,本文将原始文献的多个特征进行输入,进行表示学习.GHOST和Zhang等人都利用了图的拓扑结构,将图嵌入到低维向量空间中,本文对文献的多个特征进行嵌入,结合图卷积神经网络进行学习.从实验结果可以看出,本文提出消歧方法在大部分作者消歧上都表现更好的聚类效果.
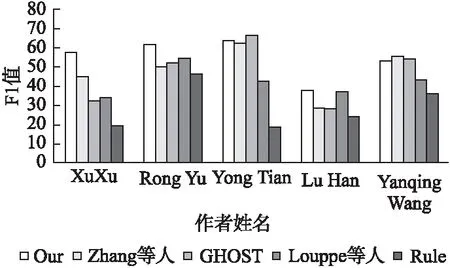
图6 部分作者消歧F1值
6 总 结
本文提出了一种基于图卷积神经网络的作者姓名消歧方法.文本强调了邻居在作者消歧过程中的重要性,并构造每篇文献的文献局部图(APG).在APG上,本文使用图卷积网络来推理给定节点与其邻居之间的链接可能性.实验表明,与传统方法相比,该方法对作者姓名相同的复杂分布效果更好,并且本文的方法可扩展到大型数据集.接下来,可以在本文的基础上,再继续研究图卷积网络在文献数据量多时的时间效率问题.
