
基于改进YOLOv3 算法的水下小目标分类与识别
2021-03-01 09:28邵慧翔
上海大学学报(自然科学版) 2021年3期
邵慧翔,曾 丹
(上海大学通信与信息工程学院,上海 200444)
水下目标识别一直是水声领域的研究热点.水下目标识别技术应用广泛,在军事领域可用于侦察跟踪、布雷探雷和海上救援等,在民用领域可用于海底管道铺设、鱼群监测、海底状况考察、海底设施的维护与监测等.针对声纳图像识别技术,国外研究方向主要有3 个:一是通过大量的测绘与试验,收集海洋环境数据信息和人类在海上的活动信息;二是通过大量试验测量海洋中声纳信号的传播特性;三是研究主动声纳工作的特性,根据目标噪声或回波的波形音调、节奏分布特征进行人为识别.基于传统机器学习方法进行水下目标识别的研究已有很多,例如Sherin 等[1]采用语言信号在不同频率范围的分布(梅尔频率倒谱系数(Mel frequency cepstrum coefficient,MFCC))特征,对每帧特征向量利用K-means 算法进行聚类,构造声纳图像纹理特征,作为支持向量机(support vector machine,SVM)的训练集来训练二分类模型,泛化误差为9%.在深度神经网络出现之前,早期的传统声纳图像目标检测方法耗时且精度不高,随着基于深度学习的区域卷积神经网络(region-convolutional neural network,R-CNN)方法[2]提出后,目标检测的性能有了质的飞跃.在目标检测领域,主要有两类方法:一类是以R-CNN 为代表的二阶段(two-stage)检测算法,使用区域候选网络(region proposal network,RPN)产生候选区域,然后通过神经网络对候选区域进行分类及定位,这种方法的准确度较高,但检测速度稍慢;另一类是以YOLO(you only look once)[3]为代表的单阶段(one-stage)检测算法,直接回归得出目标区域,再通过神经网络进行分类,one-stage 检测算法不需要RPN 阶段,所以检测速度较快,但检测精度较低.
已有的检测算法中以深度学习的目标检测算法最为“优秀”,不过单发多框检测器(single shot multibox detection,SSD)[4]、R-CNN 系列的网络复杂度过高,即便使用运算速度非常快的GPU,推断速度仍然很慢.而YOLO 系列的网络解决了复杂度过高的问题,在主流GPU 上运行速度达到60 帧/s 以上,满足实时的需求.本工作采用改进的YOLOv3[5]算法进行水下小目标的分类与识别,使用改进的聚类方法对ground truth 进行聚类,即随机确定k 个聚类中心,再进行聚类计算;同时调整YOLOv3 的网络连接结构,提高了算法对小目标的检测能力;最后,使用水雷声纳图像数据集进行验证.实验结果表明,改进的YOLOv3 算法实现了端到端的水下小目标检测,具有较高的准确度和较好的实时性.
1 YOLOv3 算法原理
1.1 检测原理
当声纳图像中的目标雷很小,所占像素面积约小于30×30 时,称这种目标雷为小目标.由于神经网络不断下采样,自然会造成小目标的丢失,一般在检测器关于物体大小的平均精确率报告中,小目标的平均精确率是最低的.
相比原始YOLO 系列算法,YOLOv3 算法在小目标检测方面的精度有显著提升.在目标位置的预测上使用预设的锚点框(anchor boxes),采用特征金字塔[6]布局网络,使用3 个不同尺度的特征图,通过拼接和卷积运算,融合浅层特征与深层特征.YOLOv3 网络分别对提取出的3 个不同尺度的特征图进行检测,提升了算法对不同大小目标的检测性能.如图1 所示,对于一张输入图像,YOLOv3 算法将输入图像分为S×S 个网格,网格的宽为cx,高为cy,在每一个网格中预测B 个边界框(bounding boxes),输出是边界框中心点相对于当前网格左上角坐标的偏移量(tx,ty,tw,th),然后用如下公式计算出边界框相对于特征图的位置和大小(bx,by,bw,bh),对应图1 中的蓝色实线,
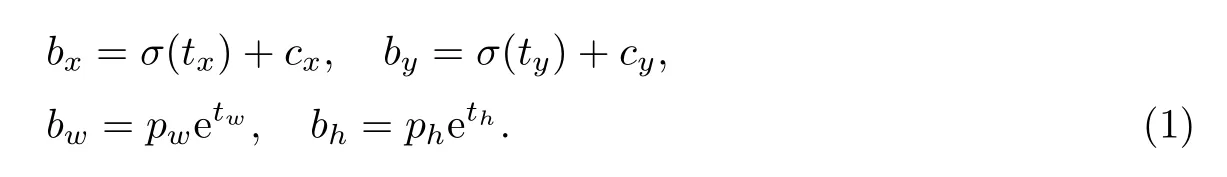
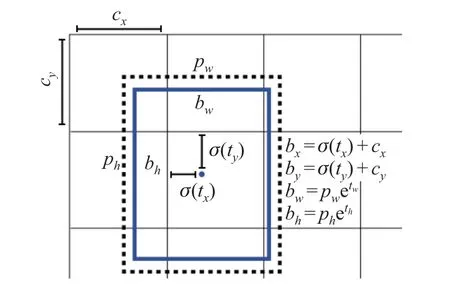
图1 预测框Fig.1 Prediction box
1.2 候选框的确定
图像中总共有S ×S 个网格,每个网格预测出B 个边界框,每个边界框对应5 个预测参数:4 个坐标和1 个置信度.参与损失函数计算的值包括预测框的中心点位置和宽高,预测框的置信度指的是预测框与标记框之间的交并比(intersection-over-union,IOU)[7],YOLOv3 中设置IOU>0.7 的预测框为正例,IOU<0.3 的预测框为负例,忽略0.3∼0.7 之间的预测框,即只是用被判定为正例和负例的预测框信息计算损失函数.
1.3 激活函数
改进激活函数也可以提高小目标的识别能力,激活函数的选取标准应是使更多的浅层神经元被激活,并且赋予不同的权重.YOLOv3 中使用Leaky ReLU[8]作为激活函数,
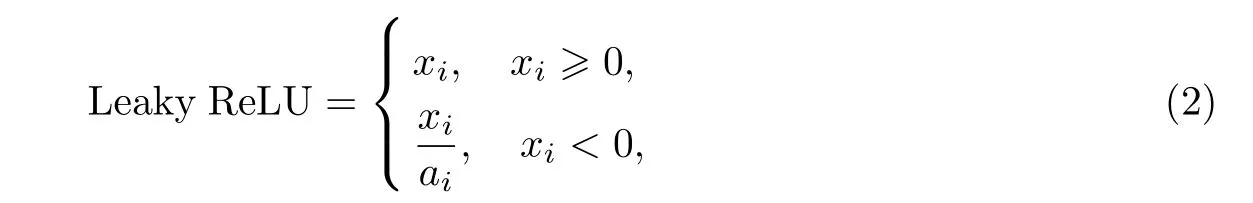
式中:ai是(1,+∞)区间内的一个值.可知,ReLU[9]将输入为负值都设为0,但是在Leaky ReLU 中是在输入为负值时添加一个非零斜率.如图2 所示,横坐标为网络输入,纵坐标为网络输出,解决了ReLU 中在输入值为负值时,输出始终为0,一阶导数也始终为0,导致神经元不能正常更新参数的问题.由于在负值处引入了很小的坡度,使得导数不为0,因此允许进行很慢的梯度学习[10].
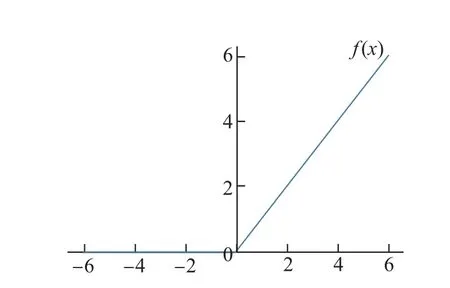
图2 Leaky ReLU 函数图像Fig.2 Leaky ReLU function graph
1.4 损失函数
在模型优化过程中,通过调整学习率对模型的优化起到的作用很小[11],而使用更优的损失函数对于模型的优化有很大的作用.YOLOv3 中将loss 分为3 个部分:回归损失lbox是通过边界框坐标计算loss,对应式(3);置信度损失lcls是置信度带来的loss,对应式(4);分类损失lobj是类别带来的loss,对应式(5).
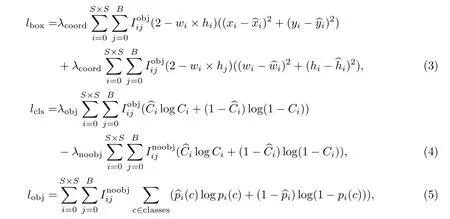
式(3)∼(5)中:S 为图像的划分系数;B 为每个网格预测的边界框个数;C 为类别数;p 为类别概率;xi,yi,wi,hi为网格中边界框中心点处的横纵坐标及宽高;λ 为权重系数.
从YOLOv3 中的损失函数来看,并不是网络的所有输出都需要计算loss,当物体中心落入cell 中,就需计算分类损失和置信度损失,预测出的边界框与ground truth 的交并比较大的需要计算回归损失.而回归损失会乘以(2 −wi×hi)的比例系数,以提高对小目标的识别能力,其中wi和hi分别是ground truth 的宽和高.
2 YOLOv3 算法的改进
2.1 改进的K-means 聚类算法
不同数据中目标的尺度大小及纵横比不同,所以选择合适的锚框尺度对于算法识别能力有很大影响.那么,给定若干个尺度大小的数据,如何将其进行归类呢?这里的“类”是指具有相似特征的数据的集合.聚类算法就是将整个数据集划分为多个类,使得最后每个类内数据相似,类间数据差异尽可能大.K-means[12]是一种简单且经典的基于距离的聚类算法,也称为k 均值聚类算法,一般采用距离作为相似性评价指标,即认为两个对象的距离越近,那么二者的相似度就越大.给定一个数据集{x1,x2,···,xn},其中每个数据都是一个d 维度数据点,k 均值聚类就是将这n 个数据划分到k 个集合中,并使得组内平方和最小.换句话说,K-means 聚类的目标就是找到使式(6)满足的聚类Si,

式中:µi是Si中所有点的均值.
K-means 的实现是多次迭代的结果,算法分为如下4 步.
(1) 随机产生k 个位置,作为k 个聚类中心;
(2) 对数据集中的每个点,计算其与聚类中心的距离,离哪个聚类中心近,就划分到聚类中心所属的集合;
(3) 将数据归好集合后,重新计算每个集合的聚类中心;
(4) 若重新计算出的聚类中心与原始的聚类中心之间的距离小于某个阈值,表示趋于稳定,就可以认为聚类已经达到期望的结果,算法终止.否则返回步骤(2),继续迭代.
在YOLOv3 中,Anchors 参数需要人为设定,通过K-means 聚类得到给定数据集先验框的宽高,然后将聚类结果按照大小顺序分配给3 个feature map 作为先验框,使用IOU 作为聚类的距离函数,聚类的目的是使anchor boxes 和临近的ground truth 有更大的IOU 值,
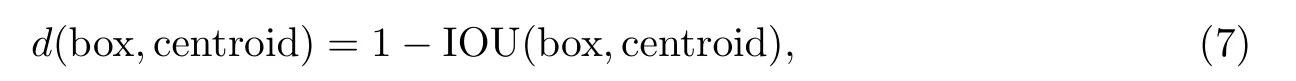
可见距离越小越好,但IOU 越大越好,所以使用1−IOU 就可以保证满足条件.
针对YOLOv3 的网络结构,采用特征金字塔网络(feature pyramid networks,FPN)进行多尺度特征预测,使用小尺度的feature map 检测大目标,大尺度的feature map 检测小目标,但是考虑到水下小目标数据集中的目标尺度大小是比较集中的,所以没有充分发挥出YOLOv3 多尺度的价值,而且在实验过程中发现ground truth 比大多数聚类得到的锚框尺度要大.
本工作针对以上问题进行了特定改动,即将K-means 聚类后的结果进行线性缩放,将锚框的尺度进行拉伸(见图3),简单来说就是将锚框的尺度乘以一定的系数,使大的尺度更大,小的尺度更小,
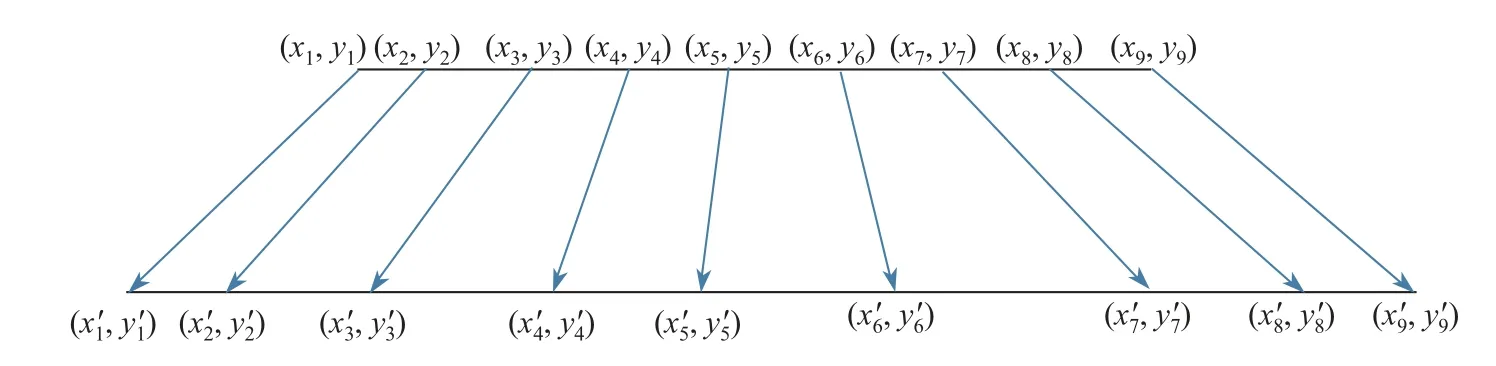
图3 线性缩放K-means 聚类算法Fig.3 Linear scaling K-means clustering algorithm
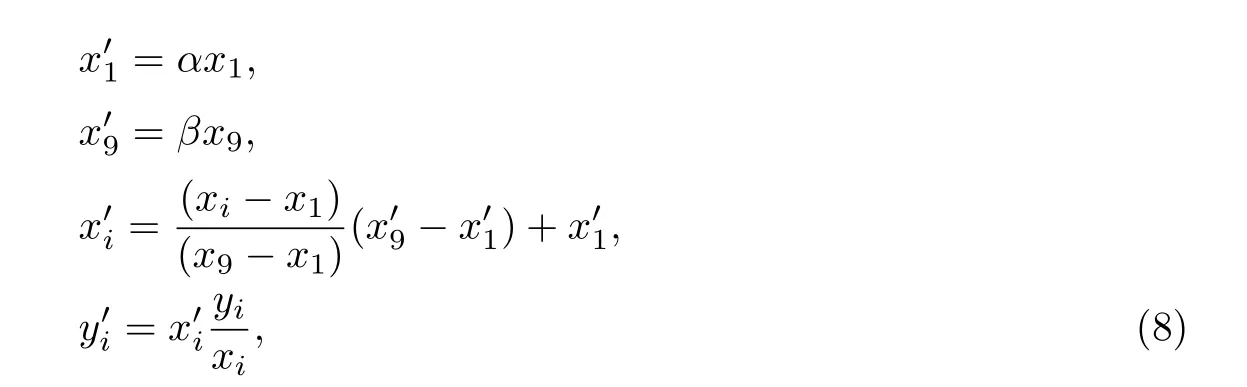
式中:设定α=0.5;β=3.
本工作中的缩放方式是一种线性缩放,并不会改变真值框中心点的位置,即缩放方式是对真值框中心点进行长宽的同步拉伸.但这种缩放方式也有一定的局限性,当目标尺寸接近训练图尺寸时,无使用的必要性.由于自建数据集中目标较小(远小于训练图尺寸),人为框出的真值框并不是紧贴目标,所以将小尺寸真值框进行缩小或者大尺寸真值框进行放大,并不会造成真值框框不全目标.并且本工作以原始YOLOv3 为基础进行多尺度训练,而对真值框进行线性缩放能够使真值框的尺度更加符合多尺度,有益于选框的多样性.
选定K=1 ∼14(坐标轴x 对应1∼14)分别对数据集中的ground truth 框的尺度大小进行聚类计算,得出K 与Avg IOU 之间的关系如图4 所示.随着K 值的增大,目标函数的变化趋于平稳,从数据上可以分析出,当K 等于12 时,Avg IOU 的值达到最大.
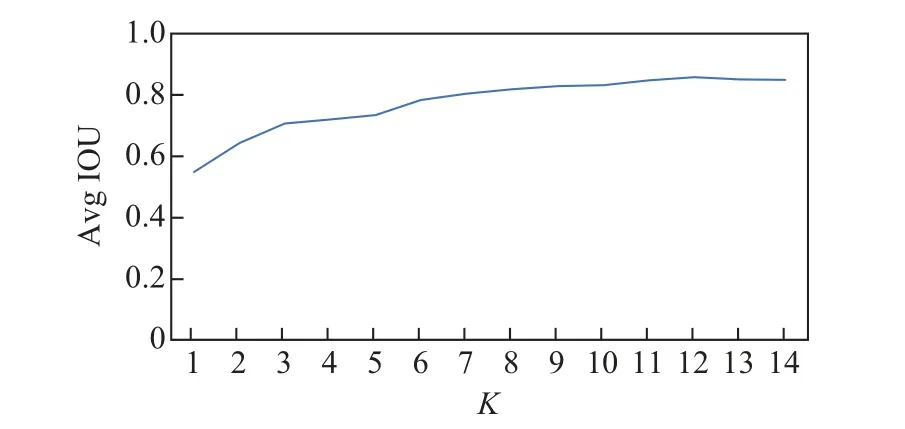
图4 K-means 聚类分析结果Fig.4 K-means clustering analysis results
2.2 网络结构改进
YOLOv3 中图像特征提取采用Darknet-53 的网络结构(见表1),含有53 个卷积层,并借鉴了残差网络[13],用1×1 和3×3 大小的卷积核构成残差块,在一些层之间设置快捷链路(shortcut connections),避免了网络层数增加后梯度消失的问题.每个卷积层之后使用Batch Normalization[14]和Leaky ReLU,提高了网络的泛化性及推断速度.Darknet-53 为全卷积结构,去掉了所有的最大池化(MaxPooling)层,使用步长为2 的卷积层代替,避免使用池化后小目标特征丢失.以自建数据集为例,使用原始的YOLOv3 网络进行检测,输入图片的大小为512×512,最终划分的网格大小分别为16×16,32×32,64×64,通过3 个检测层检测后,能够得到的预测框数量有5 376 个.原始YOLOv3 中使用表1 中的32×32,16×16,8×8 大小特征层,在两两之间上采样后拼接,对小、中、大尺度目标进行预测.
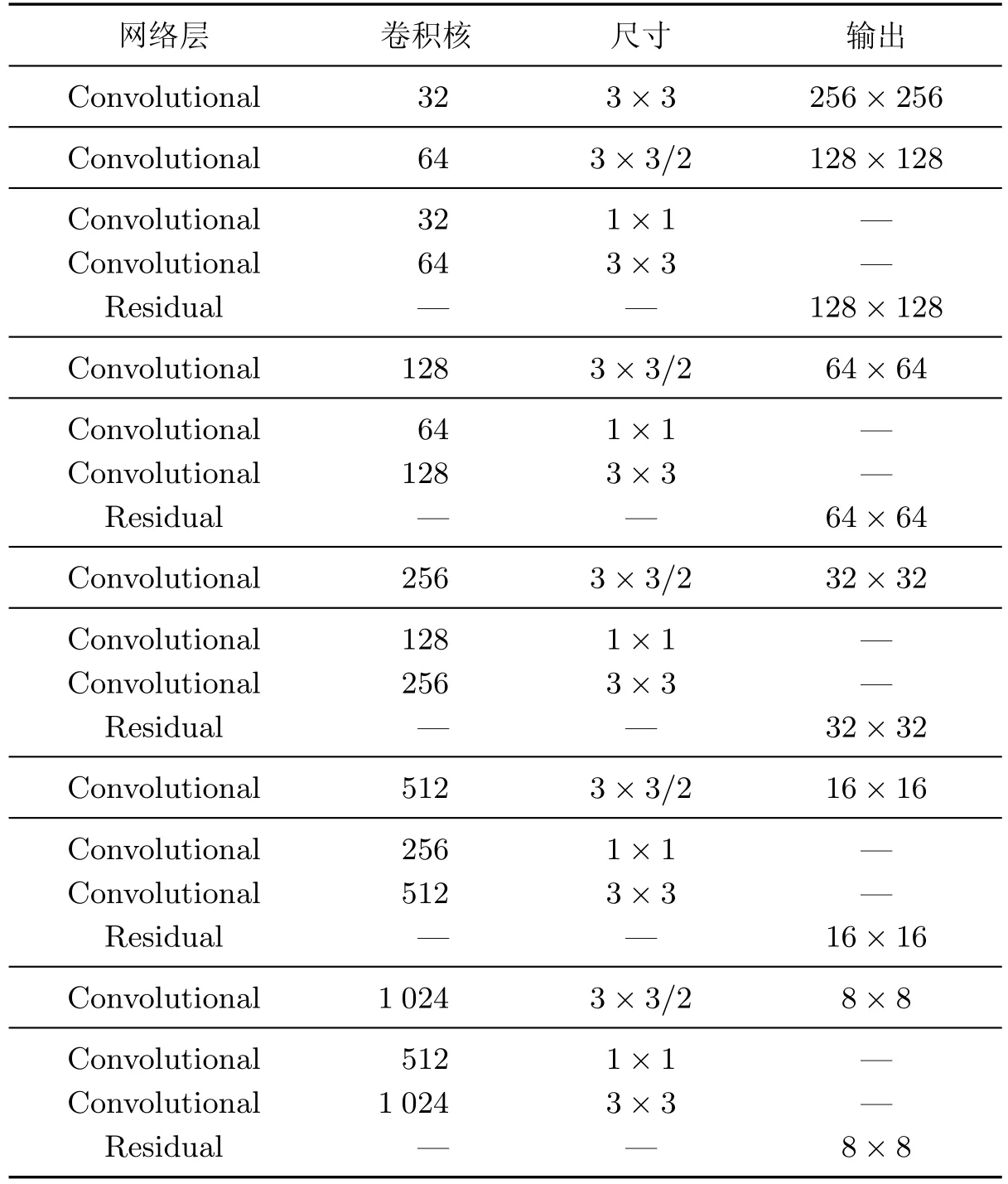
表1 Darknet-53 网络结构Table 1 Darknet-53 network structure
使用上采样的原因是,越深层级中的细节越容易丢失,甚至丢失小目标的语义,所以上采样的操作对小目标是“友好”的.但是直接使用浅层的特征进行预测往往不可行,因为浅层的语义信息不够丰富,所以对深层的特征图进行上采样后与浅层的特征图拼接成一个更大的特征图更有利于预测.
与原始YOLOv3 相比,本工作的改进算法利用了更浅层的特征图与深层特征图上采样后进行拼接,获得了更大的特征图,并且使用了更浅的层去学习小目标的特征.调整后的网络如图5 所示,其中DBL 模块、Res-unit、resn 模块均与原始YOLOv3 保持一致,图中虚线部分即为改动部分,新的大尺寸特征图更有利于小目标检测.以自建数据集为例,使用本工作算法进行实验,输入图片的大小为512×512,最终划分的网格大小分别为32×32,64×64,128×128,通过3 个检测层检测后,能够得到的预测框数量有21 504 个,预测框数量是原始YOLOv3 的4 倍,预测框数量的增加提高了模型的检测能力.
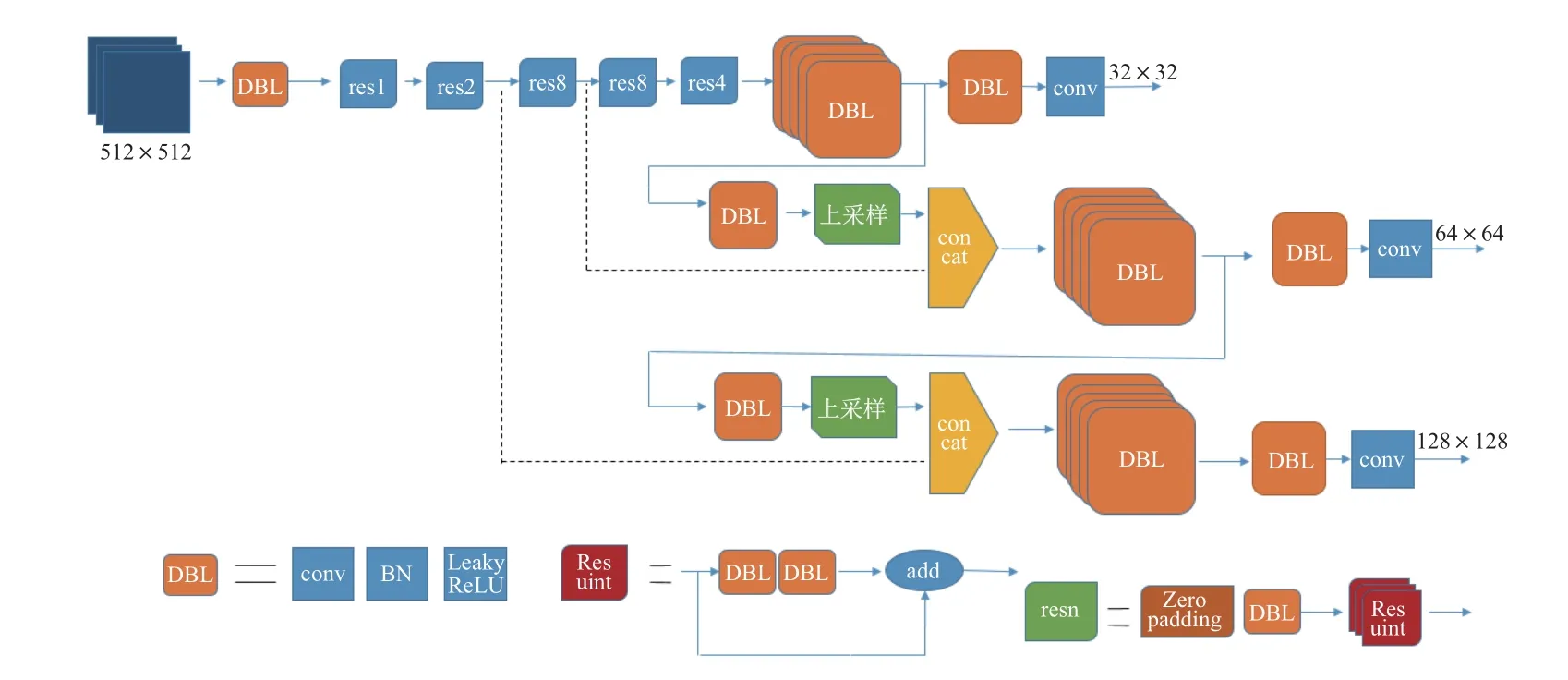
图5 改进的YOLOv3 网络结构Fig.5 Improved YOLOv3 network structure
3 实验与分析
3.1 数据集和实验平台
实验数据库使用的是实验室自建的水下目标数据集,图像为声纳采集的水下目标,其中目标尺度基本属于小目标,且目标尺度分布跨度大,数据量较少,容易产生过拟合,所以使用数据扩增方式扩大了数据集规模,包括随机生成类似目标形状的数据、最近邻放大目标[15]、线性增加像素值、目标梯度图[16]、左右翻转、旋转一定角度等操作.自建仿真数据集约1 812 张图像,其中60%作为训练,20%作为验证,20%作为测试使用.
采用批梯度下降的方式训练网络,批大小设置为4,初始学习率设置为0.001,动量设置为0.9,权重衰减设置为0.000 5,训练时对图像进行饱和度调整、曝光量调整和色调调整等操作,提高模型的泛化性能.
实验基于Anaconda3 平台,通过Python 3.6 完成,所有实验均在Intel Core i7-9750H CPU 和NVDIA GeForce RTX 2070,16 GB 内存的Windows 平台上完成,深度学习框架为Pytorch 1.4.0.
3.2 实验结果分析
由于自建数据集131 和138 只有一类目标(雷),因此采用精确率P (precision)和召回率R(recall)作为模型的评价标准[17],
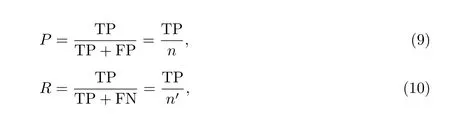
式中:TP 为网络预测出的真目标数;FN 为未能成功预测出的真目标数;TP+FP(n)为预测的目标中是正类目标的数目;TP+FN(n′)为所有完全满足标注的目标的数目.精确率计算公式(9)表示预测出的准确目标数占总的正类预测数的比例;召回率计算公式(10)表示预测出的准确目标数占实际目标数的比例,以交并比大于阈值0.5 为真目标.
3.2.1 合适的anchor 个数K 对网络的影响
使用原始YOLOv3 算法和线性缩放K-means 聚类算法进行实验,验证聚类中心个数对网络的影响.实验选取3 个不同的聚类中心个数,分别为9,12,15.单纯比较聚类算法的准确率在不平衡的样本中并不准确,所以使用自建数据集131 和138 进行模型的训练与测试,表2 为不同anchor 个数K 下网络的性能对比.选择更多的anchor 数来增加检测的密度,有利于召回率的提升,在anchor 个数从9 增加为12,15 的过程中,单类别目标的平均精确率从0.96 下降至0.95,0.88,平均精确率下降明显,所以一味增加anchor 的个数并不可行.
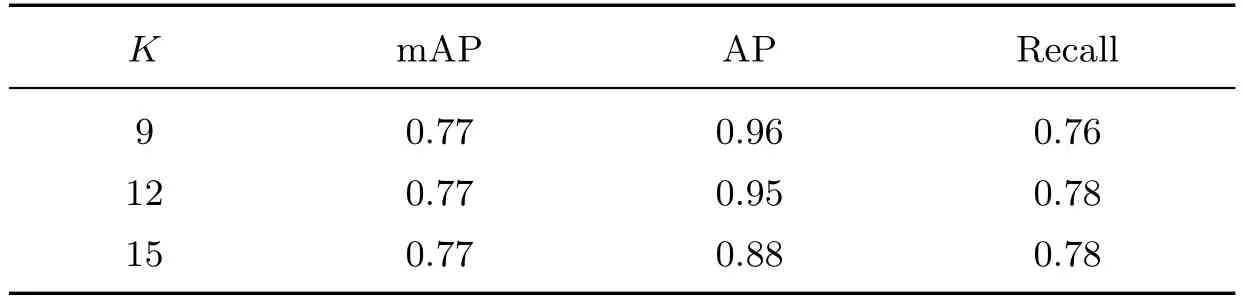
表2 不同anchor 个数K 下模型的性能Table 2 Performance of the model under different anchor numbers K
3.2.2 验证改进的聚类算法的优异性
分别采用原始YOLOv3 和改进聚类方式的YOLOv3 对自建数据集131 和138 中的目标进行单类别检测,结果如表3 所示.可见,使用线性缩放的YOLOv3 算法对小目标检测的平均精确率为0.96,与未使用聚类的YOLOv3 算法相比提高了3 个百分点,与使用了聚类的YOLOv3 算法相比提高了5 个百分点,且召回率均有一定的提升.
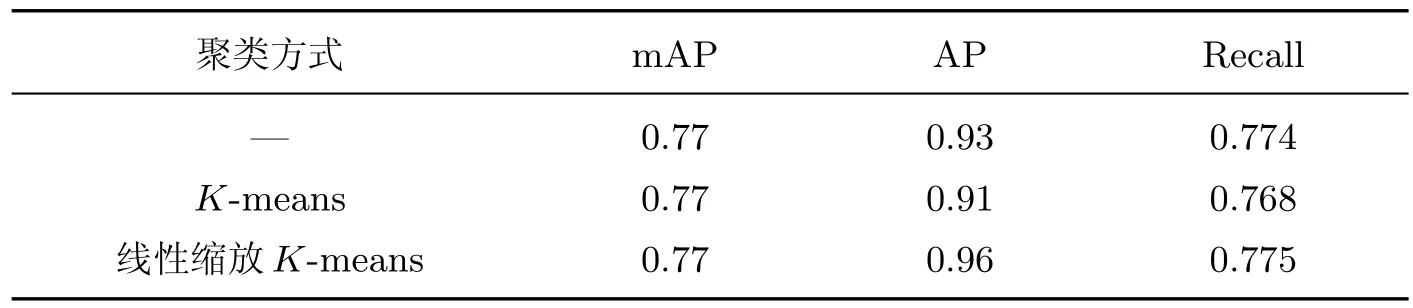
表3 聚类方式不同的YOLOv3 算法目标检测结果对比Table 3 Comparison of target detection results of YOLOv3 algorithm with different clustering methods
3.2.3 验证改进网络连接结构对小目标检测的优异性
分析了改进的YOLOv3 网络和原始YOLOv3 网络对自建小目标数据集131 的检测效果,从表4 中可以看出,改进的YOLOv3 算法在自建小目标数据集131 上的各项性能有明显的提升.与原始YOLOv3 算法相比,改进的YOLOv3 算法的均值平均精确率(mAP)提升了7 个百分点,召回率(Recall)提升了2 个百分点,能够有效检测出场景中的小目标,并且在一定程度上避免了对小目标的错检漏检.

表4 不同YOLOv3 算法目标检测结果的对比Table 4 Comparison of target detection results of different YOLOv3 algorithms
3.2.4 验证改进YOLOv3 算法的综合性能
使用规模更大的新一批次的自建数据集,其中包含4 类目标(雷、管线、基阵、潜标),进行模型综合性能的分析.表5 是对改进YOLOv3 的综合性能进行分析,其中新增的APmine 为雷的平均精确率,APpipeline 为管线平均精确率,AParray 为基阵平均精确率,APbuoy 为潜标平均精确率,Params 为模型总参数量.从表中可以看出,对于小目标(mine),改进YOLOv3 算法的平均精确率为0.95(提升了9 个百分点);对于管线,改进YOLOv3 算法的平均精确率为0.94;对于基阵,改进YOLOv3 算法的平均精确率为0.98;对于潜标,改进YOLOv3 算法的平均精确率为1;相比原始YOLOv3 算法,改进YOLOv3 算法的均值平均精确率为0.97(提升了2 个百分点),召回率为0.98(提升了2 个百分点).并且,改进YOLOv3 模型的参数量为62.6×1012,能够保持原有算法的实时性.

表5 改进YOLOv3 算法的综合性能分析Table 5 Comprehensive performance analysis of improved YOLOv3 algorithm
4 结束语
针对水下声纳小目标检测问题,本工作提出一种改进的YOLOv3 算法,首先使用线性缩放的K-means 算法代替传统K-means 算法对先验框尺度进行聚类,接着简单改动YOLOv3 算法的多尺度连接方式,从而获得了一种快速、准确的适合水下声纳小目标的检测算法.应用改进YOLOv3 算法对自建数据集进行目标分类与识别,验证了基于深度学习进行水下目标检测任务的可行性.实验结果表明,本工作所提出的改进YOLOv3 算法能够实现对小目标的有效检测,且针对所有类别的检测精度均达到90%以上,召回率高达98%,相比原始YOLOv3 算法在检测小目标上性能明显提升.
猜你喜欢
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
作文新天地(初中版)(2019年6期)2019-08-15
现代计算机(2018年27期)2018-10-25
北京航空航天大学学报(2017年6期)2017-11-23
雷达学报(2017年6期)2017-03-26
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
