
数据科学的内涵探究
2021-03-02 01:10程学旗李国杰等
中国信息化周报 2021年4期
程学旗 李国杰等
大数据已成为信息社会的普遍现象,是数字经济的关键资源。以深度学习为代表的大数据驱动的人工智能技术在很多行业和领域获得了成功,这类人工智能本质上源于计算能力,故可将其归为计算智能。
与此同时,大数据是这类人工智能成功的重要因素,这类智能也被称为数据驱动的计算智能,从这个意义上讲,当前数据和智能是一体两面的关系。虽然大数据与计算智能技术在大规模工程化应用方面取得了长足进步,但支撑技术进步的理论基础和技术体系尚处于早期阶段。
当前,大数据“红利”效应在逐渐减弱,计算智能技术的单点突破难以为大数据驱动的智能应用提供持续支撑,亟待对数据科学和计算智能的基础问题进行深入思考,重构其理论基石,从而推动技术与工程应用持续进步和跨越式发展。
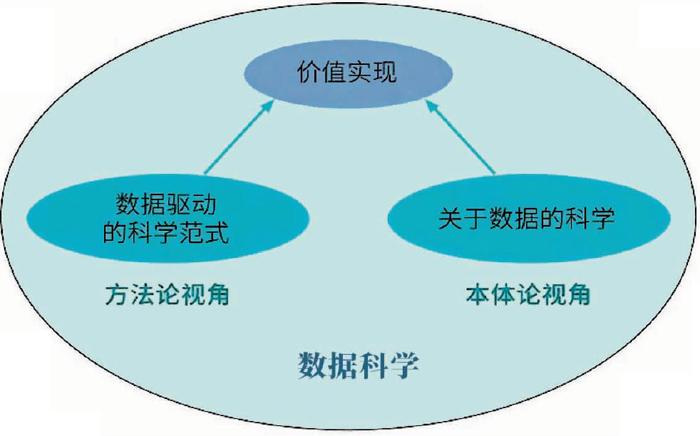
基于方法论视角的数据科学内涵
关于数据科学的内涵,一种流行的看法认为数据科学就是图灵奖得主吉姆·格雷(Jim Gray)提出的第四范式(the fourth paradigm),即在实验观测、理论推演、计算仿真之后的数据驱动的科学研究范式。
第四范式的基本思想是把数据看成现实世界的事物、现象和行为在数字空间的映射,认为数据自然蕴含了现实世界的运行规律;进而以数据作为媒介,利用数据驱动及数据分析方法揭示物理世界现象所蕴含的科学规律。这是一种类似方法论视角来定义的数据科学的内涵,即数据驱动科学发现。第四范式将数据科学从其前的3个科学研究范式中分离出来,带来了科学发现和思维方式的革命性改变。借用美国谷歌公司研究部主任皮特·诺维格的话来说,“所有的模型都是错误的,进一步说,没有模型你也可以成功”。海量的数据使得我们可以在不依靠模型和假设的情况下,直接通过对数据进行分析发现过去的科学研究方法发现不了的新模式、新知识甚至新规律。
第四范式的一个典型研究案例是关于帕金森病的起因研究。通过对160万份病历的大数据分析,研究人员发现帕金森病的起因与人的阑尾有关。这是基于大数据统计帕金森病患病率与切除阑尾的相关性得出的结论。第四范式通过大数据分析能够发现数据中蕴含的大量相關关系,为科学发现提供了新视野。但是,第四范式本身无法从大量的相关关系中甄别出事物的本质规律。在发现了帕金森病和阑尾的相关性后,有些对第四范式十分执着的学者召集了更大量的帕金森病患者,以彻查他们的基因,调查他们的生活环境和生活习惯,以期从中发现一些共性;如果这种共性存在,可能就是防治帕金森病的解决方案。
但是,其结论却不尽如人意。可以想象,人体的器官何止一个阑尾,且帕金森病患者的生活习惯何其繁杂,单独靠第四范式的数据驱动方法做漫无边际的相关性分析,不仅要消耗大量的计算资源,也难以真正预测未来的趋势与变化。因此,从方法论来看,第四范式在揭示事物本质规律方面存在固有的局限性,数据科学需要在方法论上突破第四范式。
基于本体论视角的数据科学内涵
数据科学另外一种值得探讨的内涵是基于“本体论”视角,认为数据是反映自然世界的符号化表示。既然自然世界是客观存在并具备共性科学规律的,那么反映自然世界的数据空间也可能具有独立于各个领域的一般性规律。因而,数据科学应该是“用科学方法来研究数据”,数据科学也应该有类似“信息论”这样的学科基础理论。
更具体来看,当我们把世界看成是由物理世界、机器世界和人类社会组成的三元世界时,新型的“感知、计算、通信、控制”等信息技术使三元世界相互影响和融合,形成了一个平行化(孪生)的复杂数据空间。
这样的数据空间,除了映射物理世界,其本身是否具有独特的一般性规律?如何用科学的方法来研究数据的一般性规律,揭示其内在机理?这些是数据科学更基本的问题。例如,数据科学中的一些常数规律(对称性、黄金分割、长尾分布等)和更广意义上的大数据非确定性、数据广义关联、时空演化、数据复杂性等。
数据科学到底应该从哪些视角来定义其独有的内涵与特征?一般认为,作为一门学科的定义,至少应该从其研究对象、方法论和学科目标3个维度去界定。
数据科学的内涵应该既包括本体论内容和方法论内容,还包括其独特的价值实现目标。基于这一认知,可以定义“数据科学是有关数据价值链实现过程的基础理论和方法学,它运用基于分析、建模、计算和学习杂糅的方法,研究从数据到信息、从信息到知识、从知识到决策的转换,并实现对现实世界的认知和操控”。这“三个转换、一个实现”是数据科学的学科目标。而实现这一目标的方法论来自多个学科方法的融合,包括数学(特别是统计学)、计算机科学(特别是人工智能)、社会科学(特别是管理学)等。
数据科学与相关学科的关系
数据科学与统计学
统计学将数据作为研究对象,致力于收集、描述、分析和解释数据,其为数据科学提供了重要基础和工具。然而,在大数据面前,统计学也面临着诸多问题和挑战。
例如:统计假设在复杂大数据分析中难以满足、数据自身及分析结果的真伪难以判定、端到端的大数据推断缺乏基础理论支撑等。统计学面对这些问题目前基本上是束手无策的;而统计学所依赖的一些传统强假设(如独立同分布假设、低维假设等),也都无法适用于目前多源异质的真实数据。因此,数据科学虽然在研究对象上和统计学是相同的,但在研究问题的范畴上却是超越统计学的。譬如:数据科学该如何深入认识数据固有的共性规律?是否能建立一套数据复杂性理论体系?数据规模、数据质量和数据价值有什么定量关系?如何刻画大数据所表现出来的多层面的非确定性特征?
数据科学与网络科学
数据科学的发展可以借鉴网络科学的发展历程,以类似的方法寻找研究对象的共性规律。网络科学发现了物理世界中广泛存在的网络所呈现出的共性规律(如幂率分布、小世界现象等),从而促进了其从图论和随机图论中分离出来独立发展,实现了其研究对象从作为数学工具的图到作为物理对象的网络的转变。
那么在数据科学中,数据的共性规律是什么?在现实世界中是否有完全不同的两个数据集之间存在某种共性?一方面,一下子找到所有领域的共性规律可能是不现实的,因而可以先从几个关键领域出发,寻找部分领域的共性规律;另一方面,寻找数据的共性规律需要能够问出合适的基础性问题,类似网络科学中关于度分布、聚集系数、网络直径、网络脆弱性、网络适航性等方面的问题。目前,尚不明确各个领域的数据是否存在统一的规律。因此,数据科学还需要在应用领域进行一定时间的探索,从领域知识中汲取养分,并逐步发现规律、寻找共性。
数据科学的起源与发展离不开计算机科学,但这两个学科由于研究对象和研究方法的不同,未来也许会平行发展。简单而言,从研究对象的角度来说,计算机科学是关于算法的科学,而数据科学是关于数据的科学。从计算机科学到数据科学,研究手段从传统计算机领域的算法复杂性分析,转变为对数据的复杂性和非确定性等特性进行分析研究。
如何对非确定边界的数据,在有限时间空间下进行计算?数据复杂性、模型复杂性与模型性能之间是什么关系?解决某个问题所需要的大数据的量的边界如何确定?是否能发展一套理论,为基于大数据的计算模型提供其能力上、下界的保证?这些都是数据科学独立于计算机科学之外所需要解决的问题。
数据科学目前尚处于发展的早期阶段,其研究方法也应该与传统科学有所区分。数据科学,正处于“无知”到“科学”的中间状态。它目前还没有形成一门完整的学科——信息是不完备的,环境也是非确定的
(节选自公号“中国科学院院刊”。)
猜你喜欢
保健医苑(2022年6期)2022-07-08
甘肃教育(2021年10期)2021-11-02
福建江夏学院学报(2021年6期)2021-08-10
大连民族大学学报(2020年2期)2020-06-16
杂文月刊(2019年14期)2019-08-03
活力(2019年22期)2019-03-16
英美文学研究论丛(2018年1期)2018-08-16
中国工程科学(2017年3期)2017-09-05
中国市场(2016年12期)2016-05-17
医学研究杂志(2015年5期)2015-06-10
