
基于改进YOLOv4的X射线图像违禁品检测算法
2021-03-05 00:56穆思奇林进健汪海泉魏雄志
兵工学报 2021年12期
穆思奇, 林进健, 汪海泉, 魏雄志
(武警警官学院 训练基地, 广东 广州 510440)
收稿日期:2020-12-21
作者简介:穆思奇(1969—),男,教授。
通信作者:林进健(1993—),男,讲师,硕士。E-mail:dgszgdut@163.com
0 引言
X射线图像检测违禁品主要是对违禁品进行定位与分类,即用目标检测算法自动从待检测的安检图像中判断是否有违禁品,并判断违禁品的类别、位置及置信度。X射线是一种波长短、能量高的电磁波,能够穿透一般物体。物体密度越低,X射线越易穿透。X射线源发出射线照射被检测物品后,图像采集器接收X射线,生成不同灰度大小的图像,经过伪彩色处理后由专业人员对伪彩色图像进行观察、分析,在无需开箱的情况下判断有无携带违禁品。为了有效应对日益增长的旅客运输量,减少安检人员工作量,加快安检效率和降低漏检风险,将人工智能方法应用于违禁品位置和种类检测的研究已成为热点之一[1-3]。
X射线图像的成像结果主要与物品自身的密度、成分以及成像时空间位置等有关,最重要的是安检过程中待检测物品随机性和物品摆放随意性,导致X射线图像与自然图像相差较大,不利于安检人员进行识别判读。卷积神经网络(CNN)具有强大的特征提取能力和权值共享等特点,得到广泛应用研究,基于CNN的目标检测算法也取得了进一步研究和应用,形成很多经典的目标检测算法,如空间金字塔池化网络(SPPNet)、单次多盒检测器(SSD)、YOLO系列。尽管目标检测技术取得了飞速发展,但由于X射线图像违禁品检测任务有别于其他目标检测任务,应用上仍具有较大挑战,存在很大的提升潜力和空间[4-7],特别是X射线图像成像背景复杂、物品间存在严重重叠、遮挡现象和违禁品多尺度等问题受到越来越多学者的关注[8-9]。
本文主要针对X射线安检图像检测难点,同时考虑到安检对实时性要求较高,以YOLOv4[10]算法为基础网络,利用CNN具有平移不变性,可有效提取背景复杂的目标特征,提出空洞密集卷积模块和注意力多尺度特征图两个模块:前者用于加强网络对违禁品目标细粒度特征学习能力,提升遮挡违禁品的检测精度;后者通过对融合后特征信息引入注意力机制,增强有益特征通道,有利于降低多尺度目标的漏检率。实验结果表明,在X光安检领域公开的数据集,本文算法取得了令人满意的效果,能有效提高X射线图像检测违禁品目标的精度,满足安检速度要求。
1 违禁品目标检测研究工作
违禁品检测具有十分重要的现实意义,运用图像处理技术自主对X射线图像进行违禁品分类和检测研究工作发展迅速。在以传统图像处理算法的研究、探索与应用方面,文献[11]针对车轮胎子午线检测图像中的质量问题,通过高斯- 拉普拉斯算子检测边缘和改进模板匹配算法,采用先全局扫描、后小范围区域扫描来满足实时性和精度,得到轮胎子午线图像得到较理想的检测效果。文献[12]针对X射线安检图像的特点,使用小波分解重构的方法进行边缘提取,进而使用形态学处理得到刀具违禁品形态特征元素,最后采用决策树与随机森林相结合方法降低了刀具识别错误率。文献[13]实现了一种X射线行李扫描图像中手枪目标的自动检测系统,利用不同核大小的Sobel算子进行边缘检测,为每个方向设置一个支持向量机分类器来实现旋转不变性,取得了较高的准确率,但对重叠目标的检测效果有待研究。安检系统生成的伪彩色图像中含有重叠的纹理信息,利用传统图像处理算法难以提取到违禁品目标有效的纹理细节信息,特别是对重叠遮挡和方向变化的违禁品目标分类与检测效果不佳。
相比而言,基于CNN的目标检测算法则取得了更好的研究进展和效果。文献[14]设计了一种基于改进SSD方法的检测网络,实现了基于X射线安检图像并且能够满足实时任务要求的限制品检测模型,但对尺度变化和遮挡问题未考虑,检测器对小目标检测效果不理想;文献[15]中通过基于颜色信息来提取前景特征,然后提出了一种基于深度卷积神经网络(DCNN)的物体检测框架Faster R-CNN检测违禁品,但Faster R-CNN检测速度较慢,难以达到实时检测;文献[16]通过使用YOLOv2算法对两类枪支违禁品检测问题达到较高的检测精度,但该数据集复杂度不大和检测物品种类较少。
综上所述,单一的目标检测算法不能完全满足X射线安检图像违禁品检测的需求,安检任务对实时性要求较高,X射线安检图像特点导致检测目标相互重叠遮挡,多尺度违禁品加大检测难度,背景与违禁品密度相近的X射线安检图像泛化性差。
2 X射线图像违禁品检测算法
为解决第1节中所述问题,本文提出适用于X射线安检图像违禁品检测的网络,网络结构如图1所示。
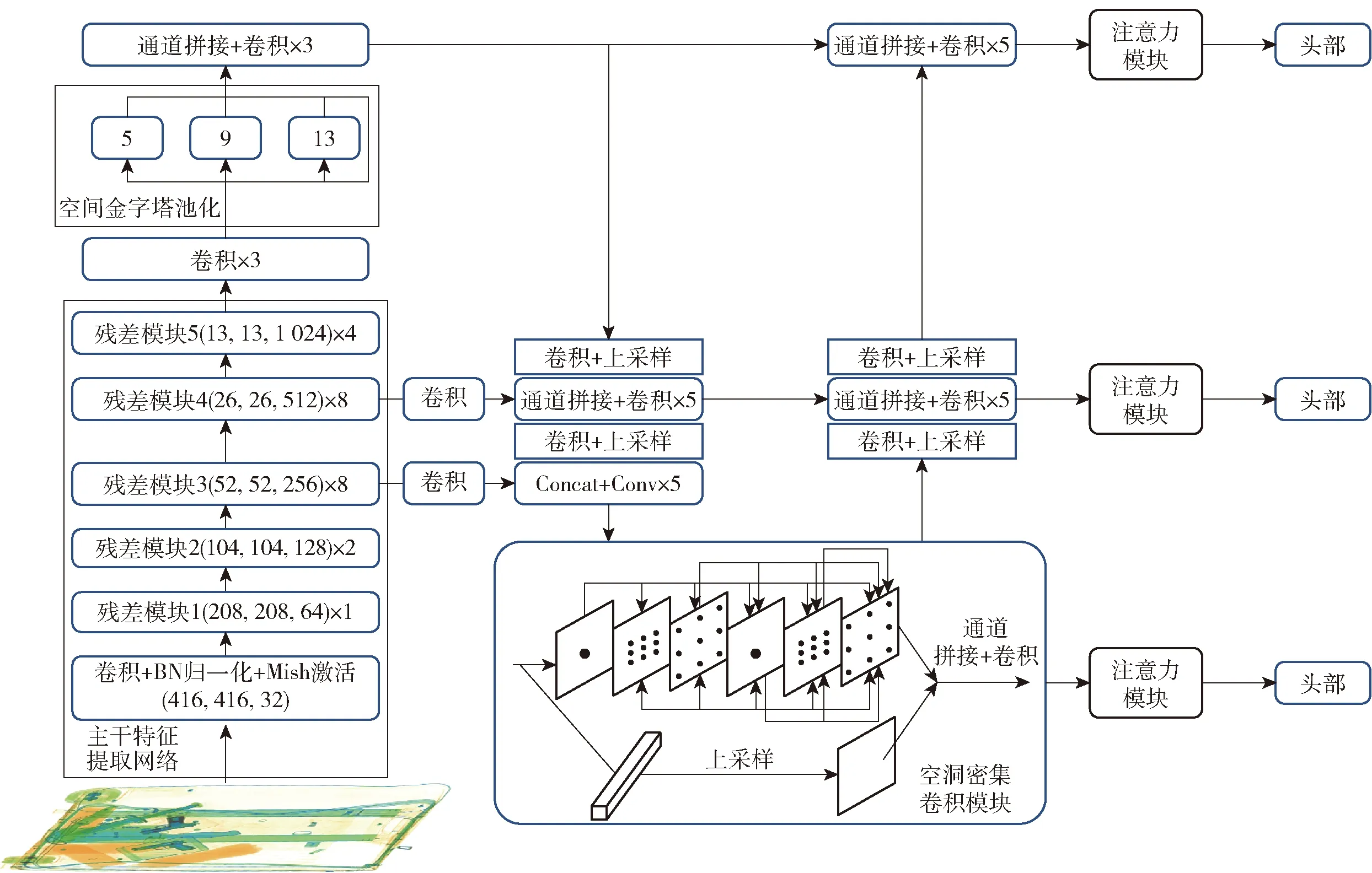
图1 本文网络结构图Fig.1 Network structure diagram
本文以精度和速度都表现出色的YOLOv4算法为基础,首先由主干特征提取网络(记作CSPDarknet53)对输入图像进行特征提取,CSPDarknet53的输出进行3次卷积后作为空间金字塔池化(SPP)模块的输入,SPP输出经过通道拼接和3次卷积得到的特征图,与残差模块3和残差模块4输出的特征图输入到路径聚合网络(PANet)中,利用上采样链路中将高层特征的语义信息与低层特征的高分辨率信息相融合;然后将融合后特征信息输入本文设计的空洞密集卷积模块,进一步精细地合并多尺度信息,再沿着从低层到高层的信息传输路径,通过下采样加强特征金字塔;最后将不同层的特征图输入到注意力辅助模块进行融合,聚合成针对任务的更高级语义特征来做预测,从而达到整体性能提升的效果。
2.1 空洞密集卷积模块
X射线检测系统生成的伪彩色图像中物品纹理信息相互重叠遮挡,导致图像中违禁品目标信息不完整,特别是高密度违禁品成像信息会覆盖低密度违禁品成像信息,质地接近违禁品相互叠加遮挡,导致算法模型出现漏检、误检现象,从而影响违禁品检测的召回率和准确性。本文设计的空洞密集卷积模块如图2所示。对输入特征X,利用密集卷积加强对特征的学习能力,通过不同卷积膨胀率来扩大网络感受野,得到加强特征X′输出,从而提高对遮挡违禁品的检测精度。
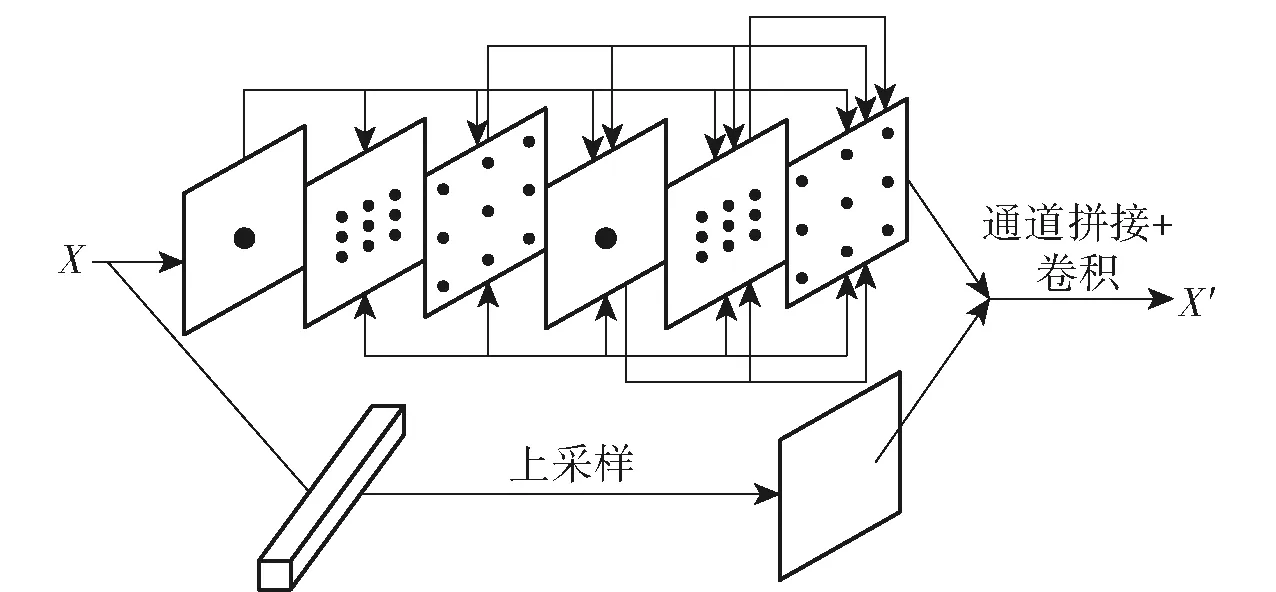
图2 空洞密集卷积模块Fig.2 Dilated dense convolution module
为了减少引入过多额外参数,利用不同大小的卷积核对特征图进行卷积操作,提高捕获不同尺度的违禁品目标能力。为了精细地合并多尺度的信息,使用密集连接,使感受野每个层都接受其前面所有层作为其额外输入,然后输入到下一个感受野层,从而加强了特征传播。
使用密集连接多个空洞卷积叠加时,减少损失信息的连续性与相关性,避免产生网格效应,采用3×3卷积核和膨胀率为1、2、5循环结构[17]。
为了保持初始输入的粗粒度信息,对原始输入特征进行全局平均池化压缩,见(1)式,再通过上采样恢复特征尺寸与空洞密集连接层的输出拼接起来,并将拼接结果输入到1×1卷积层,以融合粗粒度和细粒度的特征。
(1)
式中:zc表示通道全局平均池化输出结果;F(·)表示对通道全局平均池化映射函数;μc表示某一个通道特征;W表示宽度;H表示高度;i、j表示特征图像素的索引。
2.2 注意力多尺度特征图
融合不同尺度的特征对网络性能有较大提升,主要表现在:低层特征分辨率高,细节信息丰富,对位置平移旋转比较敏感,但其语义性更低,噪声更多;高层特征分辨率低,对象语义信息丰富,但对细节的感知能力较差。为了充分利用不同特征层语义信息,通过融合高低层特征信息对不同尺度大小的违禁品进行分类和定位目标。但并不是所有的信息都会对目标检测精度有效果,过多冗余信息可能会减弱了语义信息和位置信息的依赖关系。借助DCNN的有效信道注意(ECANet)[18]、选择核心网络(SENet)[19]注意力机制思想,通过改善特征图不同通道的权重系数,增强有益特征通道并抑制无用特征通道,可实现特征通道自适应校准。本文将CSPdarknet53骨干网络输出的3个有效特征图经由高低层特征信息融合后加入注意力机制,聚合成针对违禁品检测任务的注意力多尺度特征图,再输出到检测头部中。多尺度特征图加入注意力机制后形成的注意力多尺度特征图如图3所示,图中C表示通道数。
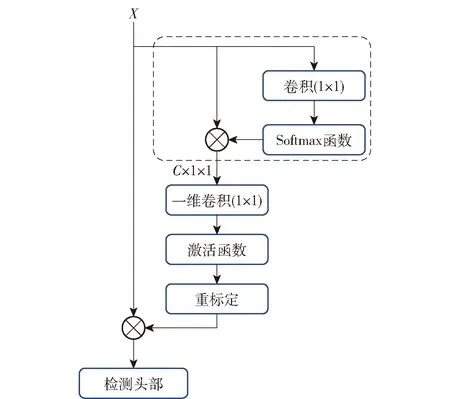
图3 注意力多尺度特征图Fig.3 Attention multi-scale feature
由图3可知:注意力模块对输入的融合特征信息的一个分支进行挤压操作,得到一个C×1×1的向量,然后特征激活过程,利用一维卷积计算得到每个通道的权值后进行激活函数处理;接着恢复原来特征图尺寸;最后通过乘法将其逐通道加权到初始的特征上,完成通道维度上对原始特征的重标定,再输入检测头部中。一维卷积的卷积核大小通过一个函数来自适应,使通道数较大的层可以更多地进行跨通道间的信息交互。
自适应卷积核大小的计算公式为
(2)
式中:k为自适应卷积核大小结果;ψ(C)表示对通道C进行非线性映射;γ为缩放因子,在这里取2.
2.3 损失函数
在目标检测中,损失函数的优劣对模型收敛的效果有很大影响。YOLOv4算法的损失函数由边界框回归损失、置信度损失和分类损失3部分组成,损失函数如下:
Loss=bbox_loss+conf_loss+prob_loss,
(3)
式中:Loss为损失函数;bbox_loss为边界框回归损失;conf_loss为置信度损失;prob_loss为分类损失。
在计算边界框回归损失中常使用均方误差(MSE),但MSE损失函数将检测框中心点和宽、高等坐标信息作为独立变量,实际上框的中心点和宽、高存在一定关系。因此,引入交并比(IoU)损失代替MSE损失函数,预测框与真实框的重叠度越高,IoU值越大。IoU的计算公式如下:
(4)
式中:A表示预测框;B表示真实框。
基于此思想,文献[20]对其进行改进,并提出一种新的损失函数(记作CIoU损失),CIoU损失将目标与Anchor之间的距离、重叠率、尺度以及惩罚项都考虑进去,克服了预测框与真实框不重合、缺失两边界框中心点距离等信息的不足,使目标框回归变得更加稳定,能够更好地反映预测框与真实框的重合情况。CIoU损失的计算公式如下:
(5)
式中:p2(b,bgt)表示预测框和真实框中心点的欧式距离,b表示预测框的中心点坐标,bgt表示真实框的中心点坐标;c表示能够同时包含预测框和真实框的最小闭包区域的对角线距离;α为一个正数,
(6)
v用来测量长宽比的一致性,
(7)
wgt表示真实框的宽,hgt表示框的高,w表示预测框的宽,h表示预测框的高。
由此得到本文使用的CIoU损失函数为
(8)
3 实验结果与分析
本文算法的实验过程包括实验数据集与数据预处理、实验对比和消融实验三部分,由此可得出本文算法在X射线安检图像违禁品检测上的有效性。
3.1 实验数据集与数据预处理
本文实验使用的数据集来源网络公开,且由实际安检场所拍摄的SIXray数据集[21]。SIXray数据集包含枪、刀、钳子、扳手和剪刀5类违禁物品共8 900张X射线图像。该数据集中图像背景较复杂,违禁品与违禁品、违禁品与非违禁品会以任意数量和类型相互混合、重叠存在,故SIXray数据集能较好地反映安检实际情况,具有很大的研究价值,满足研究要求。
为了提高模型的泛化能力并获得更好的训练效果,在数据预处理阶段,本文采用Mosaic数据增强的方法(见图4)。首先从训练数据随机选取4张图片进行翻转、高斯模糊、色域变换等操作;然后对图片随机缩放尺寸;最后随机拼接为一张新的图片,同时获得这张图片对应的框。

图4 Mosaic数据增强Fig.4 Mosaic data angmentation
Mosaic数据增强方法有效扩充了原始数据集数量,训练时相当于一次性计算4张图片的数据,不仅可以降低网络模型训练难度,而且有利于模型更好地学习安检X射线图像数据集中的背景特征,丰富图像的上下文信息。同时,该方法的随机缩放处理增加了很多小目标,平衡了原始数据集目标尺度问题,从而网络具有更好的鲁棒性。
3.2 实验环境与评价方法
本文实验使用的硬件环境为:Intel(R) Core(TM) i7-8750H CPU@2.20 GHz处理器,Nvidia GeForce GTX 1070 8GB显卡,16GB内存;实验使用的操作系统为Windows 10,采用Pytorch深度学习框架。
采用Pascal Voc 2012的评价标准均值平均精度(mAP)和每秒帧率(FPS)作为模型的评价指标。精确率P、召回率R、平均精度AP和mAP的定义分别为
(9)
(10)
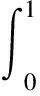
(11)
(12)
式中:TP表示被预测为正样本、实际为正样本的数量;FP表示被预测为负样本、实际为负样本的数量;FN表示被预测为正样本、实际为负样本的数量;N表示类别数。一般地,mAP指标越高,模型的检测效果越好。
FPS定义为模型1 s内检测的图像数,模型的FPS越高,检测速度越快,实时性越高。
3.3 目标检测算法实验对比
本文选取3种具有代表性的单阶段目标检测算法(包括SSD[22]、YOLOv3[23]和YOLOv4算法)与本文改进算法进行对比实验。其中SSD算法使用VGG19作为骨干网络,YOLOv3算法使用Darknet53作为骨干网络,YOLOv4算法和本文算法使用CSPDarknet53作为骨干网络。在IoU=0.5时,SSD、YOLOv3、YOLOv4、本文算法4种算法在X射线图像测试集上的mAP检索结果及各类别目标预测结果如图5所示。
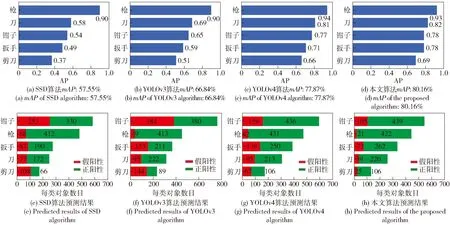
图5 4种算法测试集上的mAP结果及各类别目标预测结果Fig.5 mAP results and target predicted results on test sets by 4 algorithms
由图5可以看出,YOLOv3、YOLOv4算法和本文算法的mAP比SSD算法的mAP高,其中本文算法在检测精度上获得最好的检测效果。同时,与其他3种算法相比,本文算法对钳子、枪、扳手、刀和剪刀5类违禁物品进行预测,均获得最高的准确率,分别为80.69%、95.25%、78.20%、84.94%、80.91%. 4种算法的检测性能如表1所示。由表1可以看出,与其他3种算法相比,本文算法的mAP最高,达到80.16%,高于文献[21]中获得的最高mAP值79.56%,本文算法的检测速度相比YOLOv4算法FPS略有下降,但比SSD算法和YOLOv3算法FPS有所提升。

表1 4种算法的检测性能Tab.1 Detection performances of 4 algorithms
进一步将本文算法与SSD、YOLOv3、YOLOv4 3种算法在X射线图像测试数据集上进行检测验证,部分检测结果可视化如表2所示。
由表2可见,SSD算法在该数据集上检测违禁品的效果较差,有部分违禁品未能检测出来,特别是重叠遮挡、小目标违禁品漏检,YOLOv3和YOLOv4算法虽然检出率和检出精度有一定提升,但在低密度物品被高密度物品遮挡和相近密度物品相互遮挡两种情况下容易产生漏检:第1张X射线图像中有3把刀重叠在一起,表明SSD、YOLOv3和YOLOv4算法均存在漏检问题;第4张X射线图像中有1把小剪刀小目标,表明SSD和YOLOv3算法均存在漏检问题;本文算法在定位准确情况下表现出较高检出率,对小目标有较好的检测效果,在重叠遮挡情况下也表现出较低的漏检率与误检率。
3.4 消融实验
通过消融实验验证本文改进算法的有效性,得到实验结果如表3和表4所示。其中,表3是预置条件和设置不同Trick(图像分辨率、数据增强、正则化、损失函数)对X射线图像违禁品检测结果的影响进行评估,以确定最优的初始条件并论证模型的非结构改进作用。表4是在表3取得最优检测结果的模型基础上,增加本文提出空洞密集卷积模块、注意力多尺度特征图模块与YOLOv4算法检测效果对比,得到的本文设计的模块对检测性能的影响。

表3 不同Trick对X射线违禁品图像检测结果的影响Tab.3 Influences of different Tricks on detected resultsof prohibited items in X-ray image

表4 不同模块对检测性能的影响Tab.4 Influences of different modules on detectionperformance
由表3第2行和第3行可知,使用高分辨率图像输入训练,比低分辨率图像输入训练获得更高的mAP值;由第2行和第4行、第2行和第5行可知,使用Mosaic数据增强和DropBlock正则化,对mAP分别提升了1.91%和0.85%;由第6行、第7行、第8行和第9行可知,使用CIoU损失函数,相比MSE、GIoU、DIoU损失函数获得更高的值。
由表4可知:在检测精度方面,改进后模型的mAP相比改进前模型的mAP提升接近2.29%;在检测速度方面,改进后模型速度略有下降。对比改进前后多尺度特征融合网络的检测结果可以看出:增加了空洞密集卷积模块后,相对于原始多尺度特征融合网络,多尺度特征融合网络有着更好的特征表达能力,mAP提升接近1.18%,增加注意力模块改进后的网络也有1.11%的提升。
4 结论
本文对X射线图像中违禁品自动检测算法进行了研究,针对X射线图像中违禁品目标的特点,对YOLOv4检测算法进行了改进,在SIXray公共数据集上验证了改进后YOLOv4算法对X射线图像中违禁品检测效果。得到以下主要结论:
1)本文改进YOLOv4检测算法X射线图像违禁品检测的mAP达到了80.16%,检测速度为25帧/s.
2)提出空洞密集卷积模块和注意力多尺度特征图能够在扩展网络宽度、提高信息利用率的同时,保持较快检测速度,促进检测模型性能的提升。
3)本文改进YOLOv4算法能够更好地完成X射线图像中违禁物品的检测。
猜你喜欢
社会科学战线(2022年7期)2022-08-26
小天使·四年级语数英综合(2020年11期)2020-12-16
百科探秘·航空航天(2019年8期)2019-08-01
职工法律天地·上半月(2018年3期)2018-04-22
科学之谜(2018年1期)2018-02-03
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
读者·原创版(2014年9期)2014-01-16
视野(2009年7期)2009-05-22
消费导刊(2009年8期)2009-05-22
