
基于RF特征选择和XGBoost模型的赤潮等级预测
2021-03-05 02:42赖祥源朱勤东陈火荣陈佩君
渔业研究 2021年1期
赖祥源,朱勤东*,陈火荣,王 臻,陈佩君
(1.福州大学空间信息工程研究中心数据挖掘与信息共享教育部重点实验室,福建 福州 350003;2.福州大学数字中国研究院,福建 福州 350003;3.福建省渔业资源监测中心,福建 福州 350003)
赤潮的形成是海洋中的生物、物理、化学等众多因素综合作用的结果[1],赤潮生物的生长繁殖是一个较为复杂的非线性动力过程,水质环境因子、天气状况等都会对其产生影响,同时这些环境因子之间的关联错综复杂,要对赤潮进行更快速、准确的预测非常困难。近几年,许多学者对赤潮形成的影响因子有进一步的研究,桓清柳等[2]运用相关性分析的方法研究了深圳近岸海域赤潮变化趋势,认为氮、磷营养盐超标是赤潮发生的主要因素;彭模等[3]运用数理统计中的相关性分析方法对江苏连云港海域的赤潮特征及其与环境因子的关联性进行分析,结果表明叶绿素a、溶解氧、海温等环境要素与赤潮发生相关性显著;郑钦华等分析了2012年4—10月三沙湾赤潮监控区的富营养化特征,发现无机氮是该水域浮游植物生长繁殖的重要因子[4],此类研究大多是从定性的角度进行探讨。
近年来,诸多学者采用各种算法和模型对赤潮进行定量的研究,马玉梅等[5]构建改进的三层BP(Back propagation)神经网络模型对赤潮灾害进行监测和预报,但是该实验的训练样本个数只有24个,预测精度有待提高;张承慧等[6]建立了基于IOWA算子的赤潮LMBP神经网络组合预测模型,其预测精度比单项LMBP神经网络预测模型有较大提高,但是纳入模型的特征是人为主观筛选的,具有不确定性;苏新红等[7]进一步利用BP神经网络,发现以气象因子作为预测模型自变量是可行的,但是研究海区较大,模型结果对实际情况的指导意义不大。
针对上述问题,本文提出一种基于RF(Random forest)特征选择[8]和XGBoost(eXtreme gradient boosting)算法的赤潮等级预测方法。在特征选择时,利用随机森林算法中基尼指数对特征的重要程度进行排序,比较不同特征数下模型准确率的变化情况,进而找到最佳的特征数M。根据计算出的特征重要性排名情况,选取前M个特征组成最优特征集合,力图在保证模型精度前提下,能够减少与赤潮发生关联较低或不相关的特征[9]。在模型分类时,利用分类效果更好的XGBoost算法作分类模型,以期能够进一步提高赤潮等级预测的准确率。
1 材料与方法
1.1 数据来源
本文收集整理了宁德三沙湾赤潮监控区(图1)2005—2019年共计40次赤潮事件的统计调查数据、水质数据、气象数据。统计调查数据主要包括了赤潮发生时间、消亡时间、发生地点、影响面积、赤潮优势种、赤潮生物细胞丰度、经济损失情况、赤潮等级等要素。水质监测数据包括水温、盐度、pH、溶解氧、溶解氧饱和度、硝酸盐-氮、亚硝酸盐-氮、叶绿素-a、化学耗氧量等要素。水文气象观测数据主要包含了气温、水深、风速、气压、光照等要素(本文统计调查数据、水质数据由福建省渔业资源监测中心提供,水文气象数据由福建省气象台提供)。

1.2 随机森林特征选择方法
随机森林算法是一种基于决策树所构成的Bagging(袋装)集成算法,算法结果由票选的方式得到。它解决了决策树算法性能的瓶颈,对数据噪声和异常值有较好的容忍性[10],而且在维数较大的数据分类问题中体现了良好的稳定性。基于此,本文利用随机森林算法特征重要性值[11](Feature importance)作为参考标准,对赤潮发生时环境影响因子进行重要性计算。
特征重要性的计算通常采用的方法有:频数统计、基尼(Gini)指数法[12]和平均精度下降法(Mean decrease accuracy)[13]。因为基尼指数无需对数运算,计算相对快速简单,所以本文通过计算赤潮发生时相关影响因子的基尼指数,将各因子的基尼指数作为特征重要性,并筛选出对赤潮相关性更强的因素,计算步骤具体如下。
步骤1根据基尼指数计算公式可得,第i棵决策树中,节点t的Gini指数为:
(1)
其中K表示特征节点t处有K个类别,ptk表示节点t中类别k所占的比例。
那么节点t分裂前后的Gini指数变化量为:
ΔG=GIt-GIl-GIr
(2)
式中,GIl和GIr分别表示节点分裂后两个新节点的Gini指数。考虑到节点处的样本数量较多,本文对节点的Gini指数进行加权处理,权重就是节点的样本数量n除以总样本数量N:
(3)
步骤2加上节点处权重后特征Xj在节点t处的特征重要性为:
(4)
步骤3如果特征Xj在决策树i中出现的节点在集合T中,那么Xj在第i棵树的重要性为:
(5)
步骤4若随机森林中共有n棵树,那么Xj在随机森林中的重要性为:
(6)
最后,把所有求得的重要性做归一化处理即可得到最终的特征Gini指数:
(7)
1.3 XGBoost算法
XGBoost是由Chen等[14]在2016年提出的一种基于回归树的提升算法,是梯度提升决策树(Gradient boosting decision tree,GBDT)的优化。XGBoost算法通过引入正则项来控制模型的复杂度,可以很好地防止模型过拟合,这就使算法在减少计算量的同时,能够更快速地求得模型最优解。XGBoost目标函数为:
(8)
(9)

当新的决策树生成时,需要拟合前一次预测的残差,生成了s棵决策树后,目标函数则相应的改为:
(10)
对目标函数进行泰勒级数展开可得:
(11)

(12)
将公式(9)代入式(12),整理可得最终目标函数:
(13)
其中:Gj=∑i∈Ijgi,Hj=∑i∈Ijhi,Ij定义为每个叶子上面样本的集合Ij={i|q(xi)=ji}。
1.4 赤潮等级预测模型
基于上述方法和理论的研究,本文赤潮预测模型主要分为特征筛选和模型构建两个部分,大致步骤如下。
首先,根据收集来的赤潮监测数据进行数据清洗,对赤潮监测数据中部分缺失的数据,采用缺失处的前一个值和后一个值二者平均值表示。因为“赤潮生物细胞密度”数据的量纲较大,本文利用对其采用min-max标准化处理,即对原始数据进行线性变换,使得变换后的数据落到[0,1]区间,标准化公式如下:
(14)
式中max为样本最大值,min为样本最小值,通过标准化的处理,可以使得模型的计算速度更快,让不同维度之间的特征在数值上有一定比较性,进而达到提高模型的效率和准确性的目的。
此外,为便于模型的训练和预测,本文结合福建省海洋渔业厅2014年发布的《福建省海洋赤潮灾害应急预案》和国家海洋局2008年发布的《赤潮灾害应急预案》中的赤潮灾害等级划分,从“赤潮面积”和“赤潮毒性”两个指标入手,将赤潮等级标签划分为五个等级:“轻微”“一般”“较大”“重大”和“特别重大”,各等级对应的赋值为“1”“3”“5”“7”“9”。赤潮的监测数据中有许多非数值型的特征变量,为方便模型的识别和学习,本文将非数值型的特征变量转化为离散数值型进行表示。“光照”特征用值“2”“4”“6”“8”表示“晴”“阴”“雨”“多云”四种天气情况。最终生成一个m×n的矩阵A:
其中,每一行表示相同时段各特征值的实测值,每一列则用来表示特征值的样本数量,用字母n表示,特征的个数用m表示。
其次,运用随机森林算法中求解基尼指数的方法,对采集的数据中各特征进行重要性计算,在保证特征的特征重要性的前提下,结合皮尔逊相关性分析特征与赤潮等级的相关性,取平均后得出综合的特征排序,根据实验得出的最佳的特征个数,选取特征综合排序靠前的特征组成最优特征子集。
最后,将筛选的最优特征数据集按照3∶1的比例划分为训练集和测试集,用于XGBoost分类模型进行训练和预测。具体技术路线如图2所示。
2 结果与讨论
2.1 评价指标
为了衡量训练后的模型性能,本文选取ROC曲线、AUC值和准确率这三个指标对算法性能进行综合评价。
ROC(Receiver operating characteristic,接受者工作特征曲线)曲线是以反正类率(False positive rate,FPR)特异度为横轴,以真正类率(True positive rate,TPR)灵敏度为纵轴的各点的连线[15]。FPR和TPR计算公式如下:
(15)
(16)
式(15)~(16)中TP(True positive)为模型正确分类的正样本;TN(True negative)为模型正确分类的负样本;FP (False positive)为模型错误分类的正样本;FN(False negative)为模型错误分类的负样本。准确率(Accuracy)是评价一个模型预测准确的概率值,计算公式为:
(17)
AUC(Area under curve)被定义为ROC曲线下的面积[16],由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。通常情况下,ROC曲线和AUC值都是对于二分类情况而言,因为本文实验的标签值(赤潮等级)分为多分类,可通过对标签值的转化获取AUC值和ROC曲线,具体方法如下:

1)假设测试样本个数为j,类别个数为k;
2)训练完成后,计算各测试样本在各类别下的概率,得到一个[j,k]形状的概率矩阵P,每一行表示一个测试样本在各类别下概率值(按类别标签排序)。
3)将每个测试样本的标签转换为类似二进制的形式:“0→100”“1→010”“2→001”,每个位置用来标记是否属于对应的类别,可以获得一个[j,k]的标签矩阵L。
将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,得到一个二分类的结果。
所以,此方法经过计算后可以直接得到最终的ROC曲线和对应得AUC值,运用AUC值作为评价标准辅助ROC曲线能够更加直观地对模型效果予以评价,AUC值越大,则说明当前的分类算法性能更好。
2.2 结果分析
2.2.1 实验1-特征筛选
首先,利用随机森林的特征重要性函数对赤潮影响因子进行10次特征重要性计算,结果如表1所示,为了避免结果的偶然性,本文将10次的特征重要性取平均值作为特征最终的重要性,降序排列结果如图3所示。

表1 赤潮影响因子特征重要性统计表
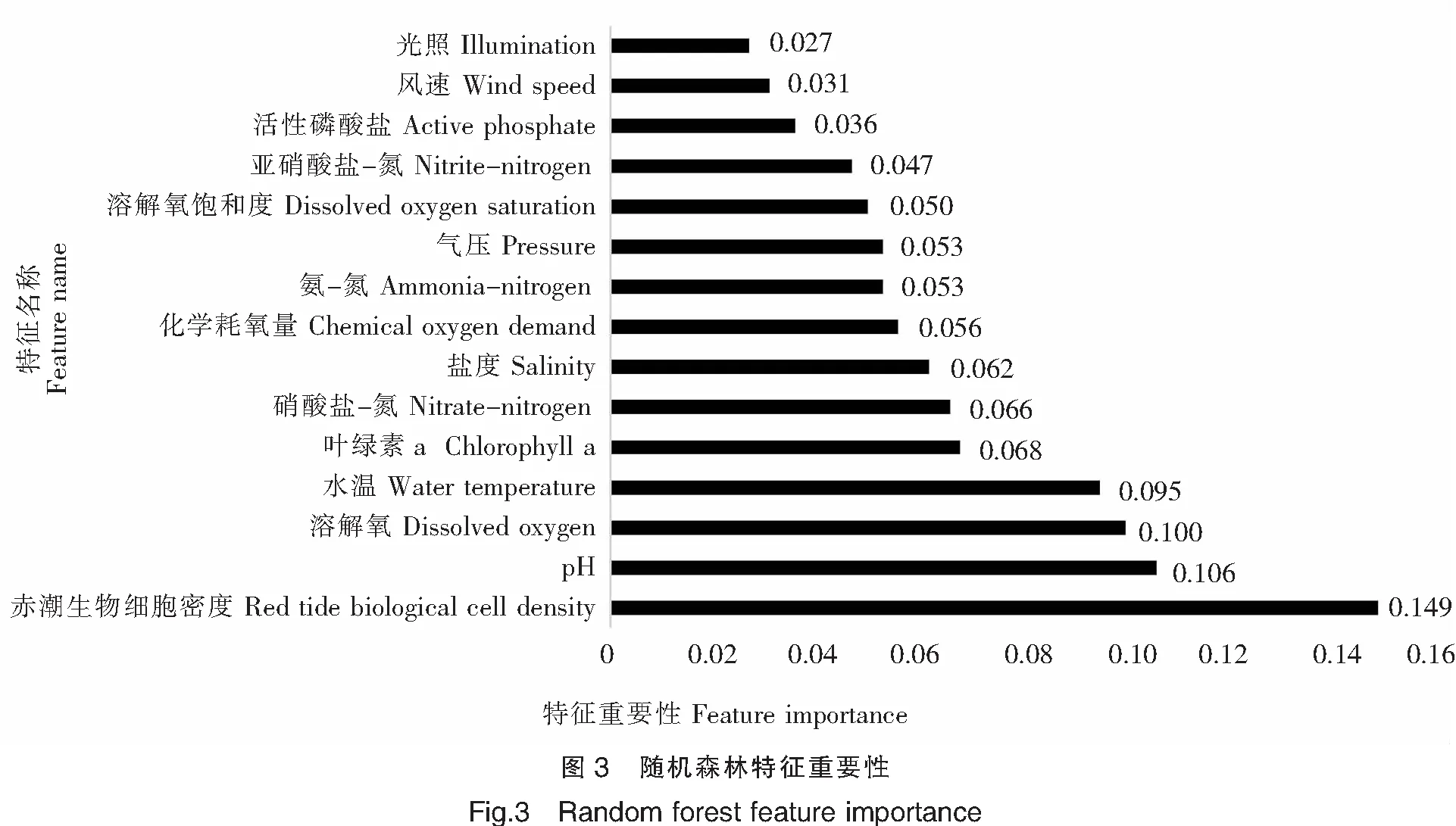
由图3可以看出,“赤潮生物细胞密度”的特征重要性最高,为0.149,“光照”环境条件重要性值最低,仅为0.027,说明“赤潮生物细胞密度”特征对赤潮等级预测结果的影响较大,而“光照”特征对赤潮等级预测结果的影响很小。“气压”和“氨-氮”的特征重要性相同,盲目地取舍特征值会影响模型预测的准确率和可靠性,为进一步对特征进行合理的筛选,本文在随机森林特征重性结果的基础上,利用皮尔逊相关性分析,对各特征与赤潮等级之间的相关性进行计算,结果如图4所示。

皮尔逊相关性r变化区间为[-1,1],当r>0表明两个变量是正相关;r<0表明两个变量是负相关。当|r|≥0.7时,两个变量高度相关;0.4≤|r|<0.7,两个变量中度相关;0.2<|r|<0.4,两变量低度相关;|r|<0.2,两变量极弱相关或不相关。由图4可知,“风速”“活性磷酸盐”“硝酸盐-氮”“亚硝酸盐-氮”与“赤潮等级”呈负相关,其余特征随着“赤潮等级”的提升而增大,呈正相关。硝酸盐-氮、pH、溶解氧、叶绿素a、赤潮生物细胞密度、化学耗氧量、盐度、活性磷酸盐、亚硝酸盐-氮、水温等特征与赤潮等级相关性达到显著水平,相关系数值较大,可作为赤潮等级预测的备选特征。由于特征重要性和相关性为同一量纲,所以将特征的重要性与相关性值进行求和,得到各特征最终的综合排名,结果如表2所示。

表2 特征重要性综合排序
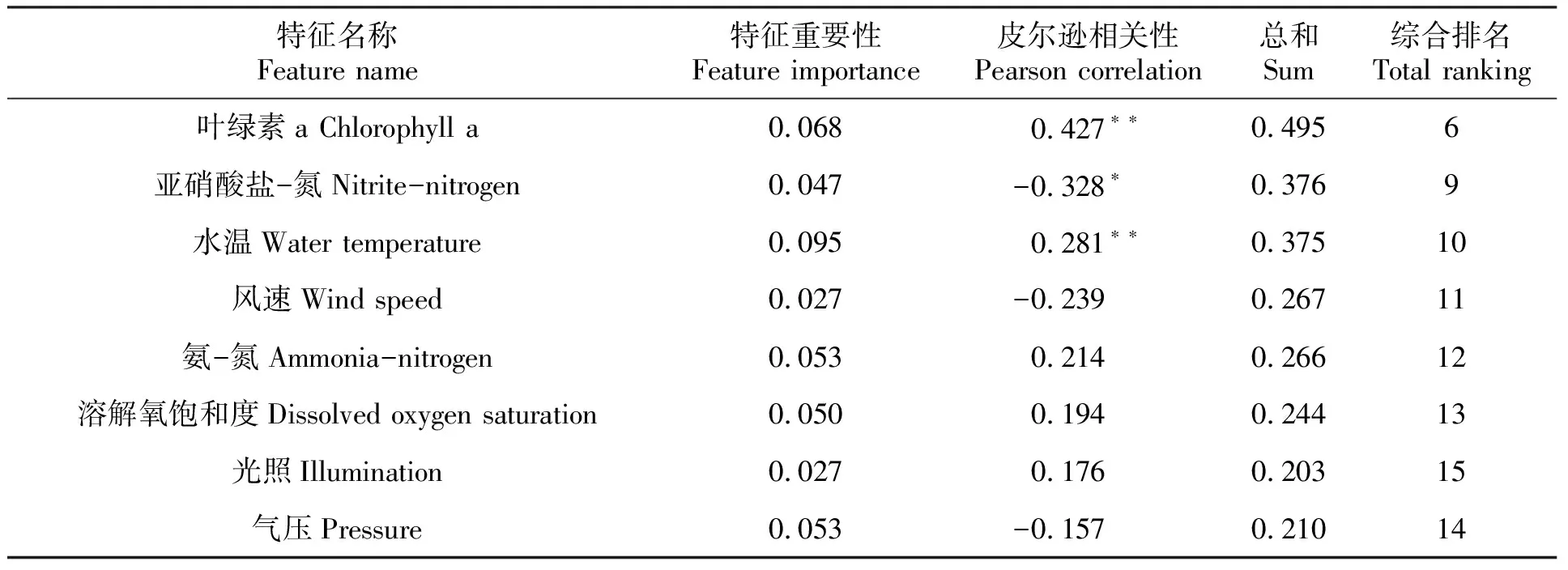
续表2
在对模型特征选择的过程中,过多或过少都不利于模型的学习与训练,会影响模型的准确率,为了找到符合模型的特征数量M,本文选取不同的M值,将模型运行得到的500个AUC值的平均值作为该特征数量下的AUC值,结果如图5所示。
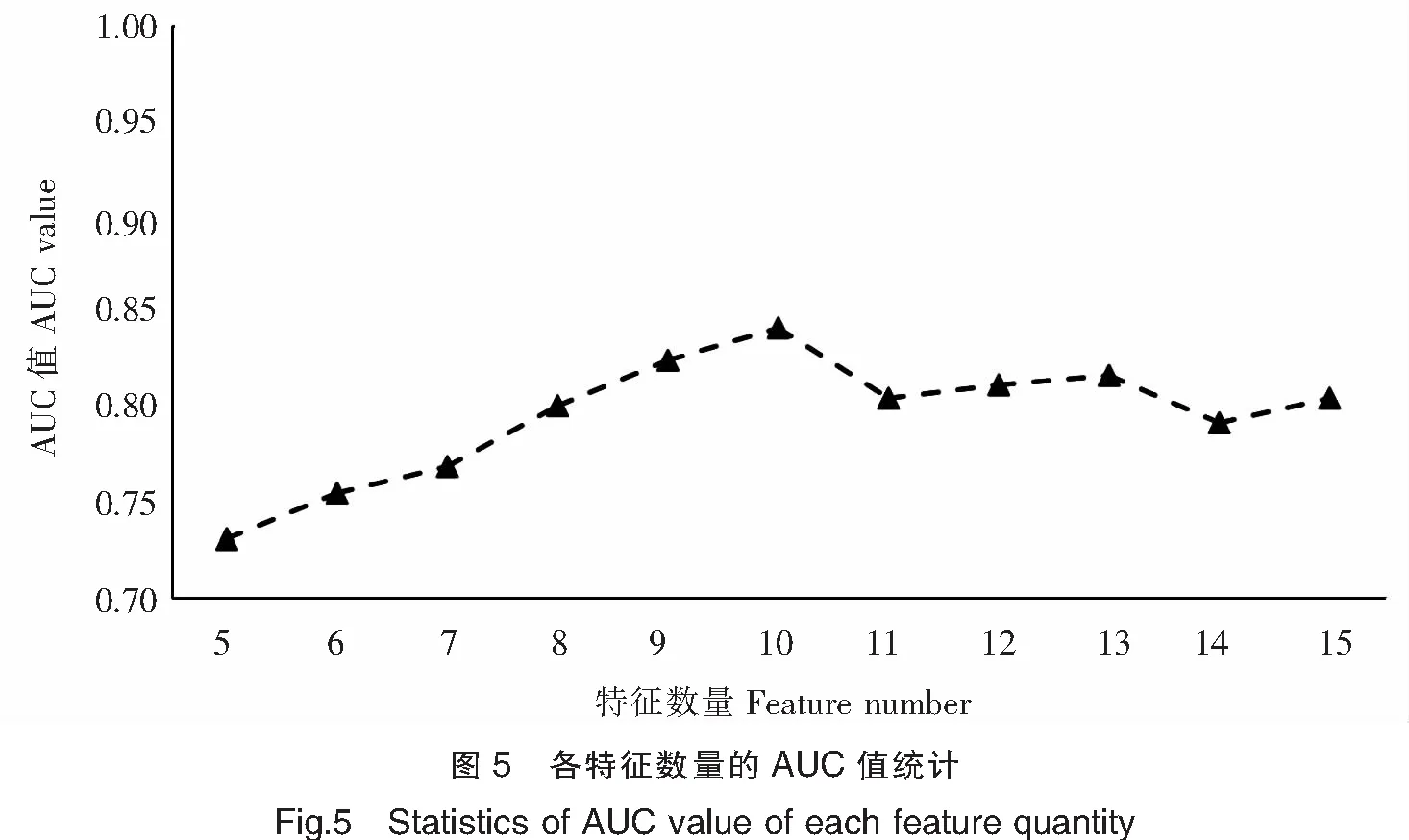
通过比较RF模型在不同M值下AUC值的大小,AUC最大值所对应的特征数则为最佳的M值,由图5可知,AUC值在特征个数为5到10之间呈单调递增的变化趋势,当特征数M=10时,AUC值达到最高0.841,特征个数在10到15区间,AUC值开始下降,虽然在M=13时的AUC值再次达到峰值,但是只达到了0.816,远低于M=10时AUC值,所以本文将综合排名前十的特征作为模型输入的特征参数,根据表1可知,选取的特征分别是:“赤潮生物细胞密度”“水温”“盐度”“pH”“溶解氧”“化学耗氧量”“活性磷酸盐”“叶绿素a”“硝酸盐-氮”“亚硝酸盐-氮”,这10个特征综合排序靠前,说明这些变量对分类结果影响和贡献大。
赤潮生物细胞密度在短时间内剧烈增长是引发赤潮暴发的内在因素,也是发生赤潮的前提,所以赤潮生物量的特征重要性最高,且皮尔逊相关性具有显著性,能够在赤潮的预测中具有重要的指示性作用。
适宜的水温和盐度是维持藻类细胞正常活动的必要条件和能量基础,有研究表明,水温在一定程度上能够促进或者抑制赤潮藻类的生长繁殖,而适宜的盐度不仅能够平衡赤潮藻类细胞内外正常的离子浓度,而且还能促进藻类的光和作用[17],所以将水温和盐度特征纳入模型的特征集合中具有合理性。此外,叶绿素作为赤潮藻类光合作用的物质基础,对赤潮等级预测具有较高的参考价值。
水体的富营养化通常容易导致赤潮的发生,而造成海域富营养化的主要原因是活性磷酸盐和无机氮(硝酸盐-氮、亚硝酸盐-氮)等营养盐浓度较高[18],近海水域中无机氮以硝酸盐-氮为主体[19],这些元素能够极大地促进赤潮生物的快速繁殖,是赤潮发生时较好的参考指标。
在赤潮发生过程中,赤潮藻类需要进行剧烈的光合作用,将水体中大量的CO2作为原料消耗,导致海水的pH值相应的升高,作为产物的O2也随之升高,当产生的氧气溶于水后,水体溶解氧含量也会明显升高,但是,当赤潮生物大量呼吸或者死亡时,分解产生的二氧化碳使水体pH降低,溶解氧含量随之降低,所以pH和溶解氧在赤潮的发展全过程都有密切的关系,其特征重要性也较高。
化学耗氧量在赤潮发生期间也具有明显的指示作用,有研究表明在赤潮发生期间,化学耗氧量明显升高[20]。所以本文将“化学耗氧量”特征加入到模型特征集合中具有合理性和科学性。
此外,本文以XGBoost算法为基准模型[21],对本文提出的方法的效果进行验证,选取决策树(Decision tree method ,DTM)、遗传算法(Genetic algorithms,GA)、序列后向选择(Sequential backward selection,SBS)三种不同的特征选择算法进行横向的对比实验,通过不同特征维度下不同算法的AUC值比较,取对应维度的500个AUC值的平均值作为各算法最终的AUC值,AUC变化曲线(图6)并对结果进行精度评价,结果如表3所示。
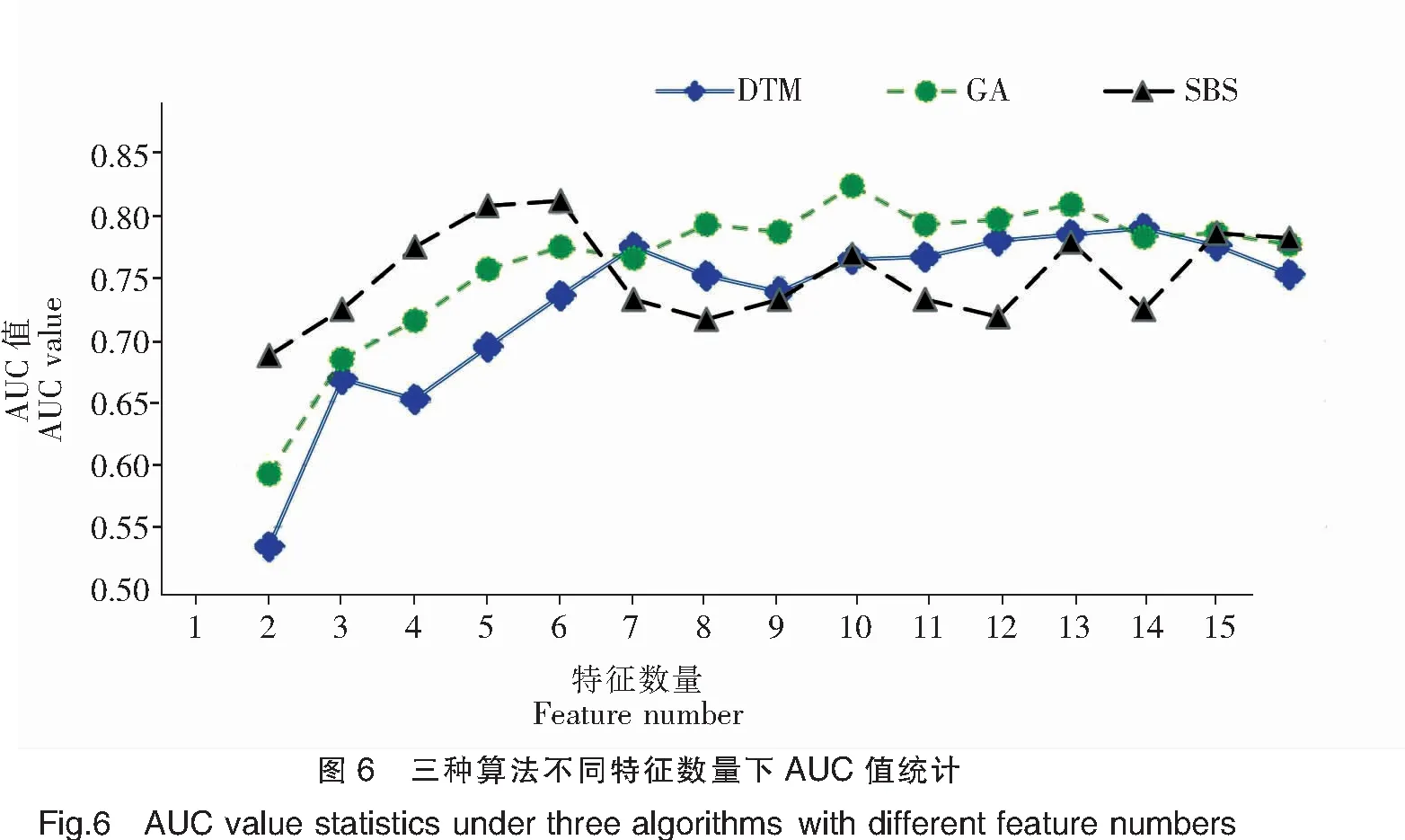

表3 不同特征选择算法基于XGBoost实验结果比较
由图6可知,DTM算法在特征数量为13时,AUC值达到最大为0.789;GA算法最佳特征数量为9,AUC最大值为0.823;SBS算法在特征数量等于5时,AUC达到最大值0.811。结合表2中各算法准确率来看,RF特征选择算法准确率达到了85.312%,均高于DTM、GA、SBS三种特征算法;从AUC值大小来看,RF特征选择算法同样优于其余三种算法;GA算法与RF算法在特征数量上相近,但是准确率不够;DTM算法由于特征降维的效果不理想,所以导致在AUC值和准确率上表现均不理想;SBS算法虽然在特征的降维上表现很好,但是特征筛选过多,模型学习的信息量不足,容易导致模型出现在训练集数据上表现很好、在测试集数据中表现很差的过拟合现象发生,最终影响模型准确率。因此,本文利用RF特征算法加入XGBoost模型的效果总体优于DTM、GA、SBS三种算法,验证了本文采用的特征选择方法具有科学性和有效性。
2.2.2 实验2-赤潮等级预测
为了检验本文构建的模型效果,本文选取决策树(Decision tree model,DTM)、支持向量分类机(Support vector classification,SVC)两种模型与XGBoost模型做对比实验,在特征筛选过程中,均采用实验1提出的RF算法。对上述3个模型分别进行10次实验取其均值后,得出的结果数据如表3所示,其中TPR为真正类率,FPR为反正类率,Acc表示准确率。由表4可知,本文方法的准确率最高,达到87.3%,AUC值也最高,达到了0.836,真正类率为0.926,反正类率为0.114,可以看出本文提出的方法综合性能明显优于DTM和SVC分类算法。

表4 不同算法实验结果比较
为能够更加直观地判断模型预测效果,本文根据表4实验结果,对不同算法下的ROC曲线进行绘制如图7所示,由于本文构造的模型是多分类的结构,属于多分类范畴,所以绘制的ROC曲线不如二分类光滑,但是不影响对模型效果的直观评价,根据图7可以看出在三个模型的ROC曲线中都处于y=x这条直线的上方,本文提出的基于随机森林(RF)特征选择和XGBoost模型的方法生成的ROC曲线所围成的面积最大,其次是SVC模型的ROC曲线围成的面积为0.764,DTM模型的ROC曲线围成的面积最小为0.719。根据ROC曲线的规律可知,XGBoost模型的曲线较DTM与SVC更往坐标的左上角凸,足以说明基于RF特征选择的XGBoost模型的AUC值更大,即模型的分类效果更佳。
3 结论
目前用于赤潮等级预测的数据量越来越大,能否更加精准地对赤潮等级进行预测是当下赤潮预测问题研究的热点。针对这一问题,本文提出一种基于RF特征选择和XGBoost模型的赤潮等级预测方法。以三沙湾赤潮监控区为研究区域,通过RF算法特征重要性评估结合双侧显著皮尔逊相关性对特征进行筛选,利用极端梯度提升(XGBoost)算法构建赤潮等级分类预测模型。在特征选择过程中本文提出的方法比DTM、GA、SBS特征选择算法准确率更高,能够达到87.3%,AUC值为0.836,均高于另外三种算法;在模型对赤潮等级预测过程中,应用RF特征选择的XGBoost模型相比DTM模型和SVC模型在准确率上分别高出7.6%和4.9%,AUC值达到最高为0.836。但是本文赤潮等级预测的方法在准确率方面也还有待进一步提高,用更高效的方法找到更优的特征子集,进而提高模型预测的准确率,将是今后重点研究方向。

猜你喜欢
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
棋艺(2001年9期)2001-07-17
棋艺(2001年11期)2001-05-21
