
基于孪生卷积神经网络的手机型号识别方法
2021-03-08 10:57韩红桂任柯燕伍小龙杜永萍乔俊飞
北京工业大学学报 2021年2期
韩红桂,甄 琪,任柯燕,伍小龙,杜永萍,乔俊飞
(北京工业大学信息学部,计算智能与智能系统北京市重点实验室,北京 100124)
随着智能手机行业的快速发展,产生了越来越多的废旧手机,为了减少废旧手机闲置造成的资源浪费和环境污染,提高废旧手机的循环利用率,废旧手机回收已成为我国电子信息产业发展中无法忽视的重要问题[1-2]. 然而,目前回收过程中分拣识别效率已成为限制回收的主要瓶颈. 在废旧手机回收分拣过程中,需要将手机按品牌及型号分类处理以获得更大的经济效益[3]. 因此,快速识别手机型号成为影响废旧手机回收效率的重要因素,目前普遍的废旧手机识别方法是通过人工方式辨认手机外观并确定型号,该过程极为烦琐和耗时,且长时间生产线工作易导致误操作,造成误检率较高. 此外,较低的识别效率也难以满足回收大量废旧手机的需求. 因此,设计一种快速准确识别手机型号的方法成为实现废旧手机高效自动化回收的关键,不仅可以极大提升手机回收效率,减小误检率,同时还能提升废旧手机回收企业经济效益.
为了提高废旧手机回收效率,废旧手机型号的快速识别成为实现工业自动化回收的重要保障[4]. 目前,工业自动化回收过程的废旧手机型号识别方法主要是利用数理统计和支持向量机(support vector machine,SVM)等分类器提取废旧手机外观图像中的纹理、形状和颜色等局部特征,并依据提取到的特征信息遍历整个图像进行对比,从而识别不同型号的废旧手机[5-8]. 例如,Ye等[9]设计基于尺度不变特征变换(scale invariant feature transform,SIFT)和SVM的组合识别方法,并将该方法应用于废旧手机回收分拣识别中. 该方法通过提取手机标志、摄像头、指纹传感器等局部特征进而识别手机型号,识别结果显示该方法对具有清晰边缘的废旧手机具有较高的识别精度,但由于识别和遍历均耗费较长的识别时间,导致该方法无法用于大规模废旧手机回收中. Martin等[10]提出基于轮廓和形状匹配的识别方法,该方法可以根据图像的局部纹理特征识别废旧手机的轮廓,但对于各元件轮廓和形状相似度极高的部分型号废旧手机,致使该方法在识别废旧手机范围上受到约束. Feng等[11]依据识别目标丰富的边缘特征信息,提出一种改进型方向梯度直方图(histogram of oriented gradient,HOG)提取手机边缘特征值,并与SVM结合实现了快速识别. 然而,该方法对手机部分占图像比例要求较高,若识别的手机图像比例过小时,会使得SVM识别模型难以收敛,造成识别的错误率增高. 综上分析,虽然通过SIFT、HOG等算子可以提取和表达手机外观中的局部特征,并通过若干个局部特征确保手机特征识别精度,但由于手机型号众多,重复相似的局部元件会大幅降低型号识别精度[12-13]. 此外,解析能够精准区分手机型号的局部特征较为困难,且特征标注的工作量极大. 因此,该类方法还难以满足大规模废旧手机快速识别的需求.
针对局部图像特征提取方法识别准确率较低的问题,研究者提出基于卷积神经网络(convolutional neural networks,CNN)的深度学习算法识别废旧手机型号[14-16],该方法能从废旧手机图像以及大规模数据中提取全局特征,并能够实现复杂特征降维,提高手机型号的识别速度. Wei等[17]使用CNN替代传统的关键点特征提取方法,对废旧手机外观边缘及其形状进行描述,实验结果显示提出的方法在废旧手机品牌外观识别中取得较好效果. 然而,CNN在图像特征提取时需要大量的标注数据,运用小规模样本训练会影响到特征提取的可靠性. Huang等[18]使用CNN构建废旧手机的通用识别器,该识别器的识别结果相比数理统计、SVM等方法的识别精度更高,但该方法只能依据手机表面上的标识进行品牌的粗分类,难以实现废旧手机型号的精确识别. Federica等[19]利用候选区域方法将图像分割成固定尺寸的图像,分别输入到CNN网络中,由全连接层实现目标分类,实际使用效果显示该方法相较于传统的CNN网络具有更高的识别精度,但由于在模型训练过程中计算量大、耗时长,因此该类方法还难以满足识别实时性要求高的废旧手机回收任务. 上述手机型号识别研究均须在训练前规定废旧手机型号类别,并收集各类别的数据样本对识别模型并进行训练,从而完成识别模型的设计. 然而,在实际手机回收场景中手机型号的类别随着新机型上市而动态更新,且由于新机型训练样本较少使得CNN模型难以及时学习和提取有效的特征信息.
为了在保证废旧手机型号识别准确性和快速性的同时提高识别模型在手机样本不足时的识别准确率,一种基于相似度对比的识别方法在文献[20-21]中被提出. 该类算法通过评估输入样本之间相似度来进行废旧手机识别模型的训练,在输入图像与数据库中所有的机型相似度均未达到阈值的情况下,判定该输入图像为已更新机型,并对手机图像特征重新定义. 该方法不仅能确保识别精度,同时还能降低废旧手机型号更新时带来的重复训练的复杂度,提高识别模型在实际应用中的实用性[22]. 例如,Weinberger等[23]、Abeywickrama等[20]通过计算废旧手机图像样本向量间的欧氏距离作为类别相似度并使用最近邻搜索法(K-nearest neighbor,KNN)对目标进行识别. 实验验证结果表明该方法不仅能在少量样本下快速完成识别任务,而且具有较高的精度. Zhu等[24]提出一种基于三元组损失的CNN识别模型,该CNN模型由多个通道组成,共同学习输入训练样本的全局和局部特征,并通过改进的三元组损失函数对网络参数进行训练,训练得到的模型对相似度较高的样本具有更高的识别能力. 上述方法主要使用相似性度量方法学习提取手机各型号间的特征,尽管该类模型精度高,但由于模型使用的网络层数较多,涉及大量的网络参数,当网络参数训练不充分时仍然影响模型对废旧手机型号的识别精度.
为了实现废旧手机回收过程中手机型号的快速准确识别,同时使模型在小样本情况下也具有良好的性能,文中设计了基于CNN的手机型号识别模型,该模型结合CNN特征降维和孪生神经网络结构(siamese convolutional neural network,S-CNN),同时运用基于自适应学习率的模型参数更新策略更新S-CNN的网络参数,确保手机外观型号的准确识别,为了完成识别模型的设计,文中主要从以下几个方面进行研究:首先,在第2节对废旧手机外观特征进行分析并引入边缘检测算法提取回收人员拍摄验机照片中可识别的手机区域,获得手机型号数据集;其次,在第3节描述基于孪生CNN的特征提取结构和对比损失函数,建立废旧手机型号识别模型并进行训练;最后,在第4节通过实际案例验证该方法的有效性.
1 废旧手机特征分析
1.1 特征分析
目前大多数废旧手机外观上均具有明显类型信息,包含手机的品牌标志、摄像头、闪光灯、指纹传感器,是识别废旧手机型号的重要依据.
为了提取图像特征,进而实现废旧手机的识别,本文收集和整理各类废旧手机在验机时回收人员拍摄的照片,并筛选计算机可识别和分类的系列图像. 选取回收过程中需要被分拣出来的重要型号构建热门机型数据集,包含huawei m7、huawei m8、sumsung A7、sumsung S8、iphone 4等13个热门机型,这些机型市场回收量大,因此训练样本均超过50个. 另选取37个机型构建非热门机型数据集,由于该数据集中的机型在市场中流通量较低,搜集得到的训练样本数均小于50个,文中以此数据集测试模型在小样本下的识别性能. 此外,统一图像分辨率为512×512,并将2个数据集随机分成2个部分,90%的图像样本作为训练集,另外10%作为测试集,数据集中不同型号手机样本如图1所示.

图1 不同型号手机样本Fig.1 Different models of mobile phones
1.2 特征区域提取
由于照片的角度、设备、光源等拍摄条件各异,因此需要去除照片中的无关区域,具体实施操作是将验机照片灰度化,然后使用边缘检测算法提取手机区域边界,形成感兴趣区域(regin of interest,ROI).
1.2.1 灰度化
为了提升图像处理速度,在进行手机区域提取前需要将R、G、B彩色图像转换成单通道灰度图像. 转换后的灰度图像仍保留彩色图像的色度和亮度分布特征,灰度化转换公式为
P=αR+βG+γB
(1)
式中:P为灰度化后图像的像素矩阵;R、G、B分别为原图中红、绿、蓝3个通道的像素矩阵;α、β、γ为灰度调和权值.
1.2.2 手机特征区域提取
为了去除灰度图像中的无关区域,使用Canny边缘检测算法提取手机轮廓[21],具体步骤如下.
1)为了抑制灰度化时可能出现的噪声,使用高斯滤波算法对灰度图像中的每一个像素点(x,y)进行平滑处理,滤波器函数为
(2)
式中:p(x,y)为点(x,y)经过高斯滤波后的像素值;x、y分别为图像中像素点的横、纵坐标;σ为方差,σ在区间[1.2,2.4]随机取值.
2)使用Canny边缘检测算子提取手机轮廓,计算公式分别为
(3)
(4)
式中:M(x,y)为图像中像素点(x,y)的梯度幅值,反映图像的边缘强度;θ(x,y)为图像中像素点(x,y)的梯度幅值方向,反映图像的边缘方向;px(x,y)和py(x,y)分别为像素点在水平与垂直方向的偏导数. 为了精确定位边缘,并对所得梯度进行非极大值抑制,寻找图像梯度中的局部极大值点,设非局部极大值点为零,使图像边缘得到细化.
3)使用基于最大类间差分的阈值分割法去除伪边缘点,设定φ1、φ2分别为高阈值和低阈值,验机照片像素中的最大类间方差δ2计算公式为
δ2(φ)=ρ1(φ)×ρ2(φ)×(μ1(φ)-μ2(φ))2
(5)
式中:ρ1(φ)为手机像素数占图像像素总数的百分比;ρ2(φ)为无关区域的像素数占图像像素总数的百分比;μ1(φ)为所有目标像素的平均灰度值;μ2(φ)为所有无关区域像素的平均灰度值.
遍历图像求得令最大类间方差δ2(φ)最大的阈值φ为该验机图片的最佳阈值. 将该阈值作为Canny算子的高阈值φ1,则低阈值φ2=0.5φ1. 当候选边缘点的梯度幅值M(x,y)<φ2时,该点为伪边缘点;当M(x,y)>φ1时,该点为边缘点;若M(x,y)小于高阀值而大于低阀值,那么判断此点与前面得到的边缘点是否连通,若连通则将此点记为边缘点,连接边缘点得到边缘图像后,对边缘图像进行形态学闭运算,去除孤立的毛刺和缺口,得到边缘图像.
最终得到通过以上基于边缘检测算子的ROI提取步骤,可有效去除与识别无关的区域,实现手机型号的特征提取,同时降低待学习图像尺寸的分辨率.
2 废旧手机型号识别方法
废旧手机回收过程具有类别数目多且不断变化的特点,而传统神经网络方法在添加新机型时,重新训练过程复杂烦琐,难以胜任大规模废旧手机型号的识别. 因此,作者设计一种基于S-CNN的废旧手机型号识别方法,如图2所示,该模型主要包含模型建立、型号识别和参数学习3个模块,各模块的主要功能为:
1)模型建立. 随机从基准样本集和训练样本集中各抽取一张手机图像组成训练样本对,将随机组成的训练样本对输入到S-CNN模型中,根据模型输出的相似性度量动态更新S-CNN模型中的参数,最终获得最优参数组合.
2) 参数学习. 建立基于自适应学习率的手机识别模型参数更新策略,该策略能够在训练过程中自适应调整学习率,以加速模型训练速度、提高识别准确率.
3)型号识别. 将基准样本集中的全部图像输入到训练好的单边S-CNN模型中,建立基准机型数据库,将待识别图像与基准机型数据库中的数据进行相似性对比,遍历检索出相似性最高的目标机型.
2.1 模型建立
文中提出通过度量输入样本之间相似度的S-CNN来构建手机型号识别网络,该网络由2个相同的CNN组成孪生结构,2个网络之间共享所有的参数w,如图2所示. CNN作为一种前馈神经网络,能够使提取后的样本特征具有平移旋转不变性,实现样本空间的降维,已被广泛应用于图像和视频的特征提取. 除输入、输出层外,卷积网络通常由卷积层、池化层、全连接层等结构叠加组成. 一般卷积层与池化层是交替使用的,这样的结构能够使提取后的样本特征具有平移旋转不变性,且可以降低参数数量,有利于网络优化. 通常CNN的结构主要包括以下方面.

图2 基于卷积神经网络的手机型号识别模型Fig.2 Mobile phone model recognition model based on convolutional neural network
1)卷积层. 卷积层的作用是对从输入层获得的图像进行特征提取. 卷积层在上级输入层上通过固定步长的滑动窗口计算得到卷积特征图,计算公式为
rl+1=f(ωlrl+λl)
(6)
式中:rl+1为l+1层的激活特征图;f(·)为激活函数;ωl为第l层的卷积核;λl为第l层的输出偏置参数.
2)池化层. 在图像特征提取过程中,池化层的作用主要是剔除冗余区域,降低数据维度. 池化的方法主要有最大池化和平均池化2种. 所保留的特征使得最后的特征表达保持旋转、位移、伸缩的不变性. 文中使用的平均池化公式为
(7)
式中:Qa×b为池化后的输出向量;r为输入向量;S1、S2为池化步长;a、b为平均池化后卷积特征图的维度.
首先从基准样本集T和训练样本集X中各随机挑选一个样本t和x输入到S-CNN中,通过网络的前向传播得到2个长度相同的向量Gw(t)和Gw(x),定义2个输出向量间的欧式距离为样本t和x的相似度,计算公式为
d(t,x)=‖Gw(t)-Gw(x)‖2
(8)
式中:d(t,x)为样本t和x的欧氏距离;Gw(x)为训练权值是w时,样本x经前向计算后的输出.
为了获得更好的识别效果,使得同机型下获得d(t,x)趋近于0,不同机型手机的相似度计算d(t,x)趋于无穷,对损失函数进行改进. 在每个训练批次中,同时从训练样本集中随机抽取2个样本x1和x2,其中x1与基准样本t型号相同,x2与t型号不同,为使得同机型的距离小于异机型的距离. 即要求d(t,x1)尽可能小,d(t,x2)尽可能大,建立对比损失函数为
L(x1,t,x2)=max (d(t,x1)-d(t,x2)+u,0)
(9)
式中:L(x1,t,x2)为输入样本为x1、t、x2时的对比损失函数值;超参数u为大于0的极小数;max为取最大值函数.
同时将同型号手机t和x1、异型号手机t和x2送入孪生卷积网络中,经过网络的前向计算,得到2个单边网络间的距离计算结果,使用该结果计算损失函数,从而完成网络的前向传播.
2.2 参数学习
为了实现神经网络参数的在线更新,文中提出了一种自适应学习率的手机识别模型参数更新策略,其学习过程可以表示为
(10)

wk=wk-1+Δwk-1
(11)
(12)
式中:wk为第k次迭代时的参数集合;Δwk-1为第k-1次迭代时参数更新时的变化向量;k为当前迭代的次数;ε取任意常数;nk为一个对角矩阵;η为学习率,控制每次在负梯度所在的方向上改变的步长.
2.3 型号识别
为了实现手机型号的快速准确识别,需要在识别过程中精简重复的结构,建立基于单边S-CNN的手机型号识别算法,具体步骤如下.
步骤1为削减与识别无关的冗余结构,取训练后权值为w的单边S-CNN模型作为废旧手机型号识别模型.
步骤2设基准特征数据集T中共有n个手机型号,将所有样本t1-tn依次输入到单边S-CNN识别模型中,将模型的输出值Gw(t1)-Gw(tn)以向量的形式存储到基准数据库G(T)中.
步骤3将待识别图像d输入到单边S-CNN模型中,得到输出值Gw(d).
步骤4遍历对比识别输出值Gw(d)与基准数据库G(T)中的值,当距离最近且小于0.5时,该基准样本为目标机型.
步骤5若机型基准数据库G(T)中无满足距离要求的基准样本,则认定该检测样本为未知机型,自动将改图片添加到未知机型数据库中. 人工查验无误后并将该机型对应的机型数据补充到T中以更新基准特征数据集.
利用S-CNN进行识别,手机型号在识别前将基准样本集输入到S-CNN,得到降维后的手机型号基准输出值并存储进数据库中,减少基准样本的重复卷积计算,缩短识别时间.
3 实验结果与分析
3.1 实验条件
搭建训练平台配置如下:CPU为Intel Corei5-9400,主频3.40 GHz;内存为24 GB;GPU为Nvidia RTX2060super独立显卡;操作系统为Windows 10.
文中单边S-CNN网络以经典识别网络Alexnet[25]为基础结构,包含5个卷积层、3个池化层和2个全连接层,输入层大小为512512像素,卷积层P1-P4卷积核尺寸分别为11×11、5×5、3×3、3×3和3×3,步长均为1. 池化层C1-C3尺寸为2×2,步长为2.P4连接1个4 096个节点数的全连接层,再经过1个全连接层得到节点数为100的输出层.
在训练开始前,对模型中的各项参数进行初始化,设定灰度化调和参数α=0.299,β=0.588,γ=0.114;训练批量为64,代表同时输入模型的样本数;最大迭代次数为2 000;使用均值为0、方差为1的正态分布随机值对向量w中各个模型的权值进行填充,采用5折交叉策略对数据集进行训练以保证模型的泛化性能.
3.2 性能分析
在训练过程中,使用文中模型更新策略对模型参数进行调整,文中选取了随机梯度下降(stochastic gradient descent,SGD)、Adam[26]与文中模型参数更新策略进行对比训练实验,每种方法各训练200次,得到的损失函数收敛曲线如图3所示.

图3 训练收敛对比曲线图Fig.3 Training convergence comparison curve
通过上述结果,在模型训练方面,传统的SGD算法原理为每次迭代计算当前批次样本的梯度,并对参数进行更新,该算法对于网络的训练速度较慢,SGD方法选择合适的学习率比较困难,且比较容易收敛到局部最优,文中模型参数更新方法能够在训练的过程中自适应地调整各个参数的学习率,因此具有更快的收敛速度,且在训练后期的波动较小.
为反映各个型号废旧手机的识别效果,将热门机型数据集中的手机图像测试样本逐个输入到模型中进行识别,记录预测结果与该样本的真实机型,得到混淆矩阵如图4所示. 混淆矩阵中对角线上的黑色方格为正确识别的手机数,方格a(i,j)为第j类手机误分到第i类手机中的个数.
由图4验证集识别混淆矩阵可知,热门数据集各机型检测精度均保持在90%左右,混淆情况主要出现在上市年份相近的机型之间,分析原因为年份相近的机型在外观上往往具有更高的相似性,如iphone 6与iphone 5s在背部的相同位置有2个清晰的颜色分界线,在计算相似度时具有更高的权重,为解决此问题,应适当扩大样本输入分辨率.
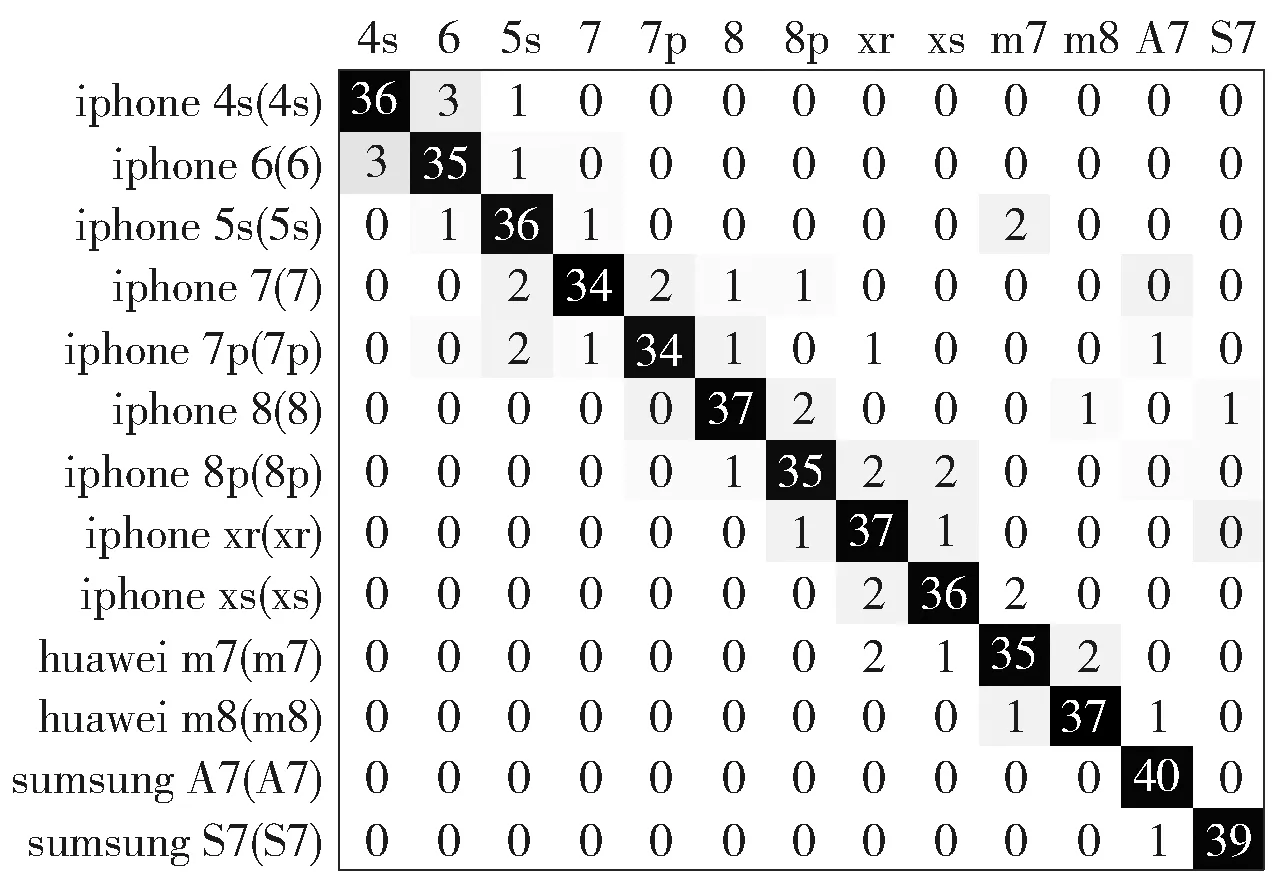
图4 验证集混淆矩阵Fig.4 Different models of mobile phones
使用检测时间tr(单位:ms)、平均识别精度(mean average precision,MAP)、Recall和F1值4项性能指标评价模型性能,MAP的计算方法为
(13)
式中:Precision为检测精度;MAP为平均识别精度;Recall为检测结果召回率;TPm为第m类样本被模型分类正确的个数;FPm为第m类样本被模型分类错误的个数;FNm为第m类样本被模型漏报的个数;n为总类别数;m为样本类别编号. 对比结果如表1所示.

表1 不同算法识别热门机型精度与速度对比
在识别准确率方面,当训练数据集为热门机型,即总数N=13时,由于这13个热门机型具有丰富的训练样本数,因此S-CNN、SIFT+SVM和Resnet-152模型均能较准确地对13种手机型号进行区分和识别,在热门数据集上的平均检测准确率超过90%,但在识别速度方面,传统的SIFT方法单张图像的检测时间大于1 s以上,不能满足实时需求. Resnet-152凭借152层网络结构和巨大的参数规模取得最高识别准确率,但由于网络结构复杂,识别单张图像的时间达到23 ms. 而基于S-CNN的手机型号识别方法由于网络结构较Resnet-152更加简单,使得单张检测速度达到9 ms,优于其余方法. 因此作者提出的基于S-CNN手机型号识别方法具有较高的识别精度和更快的识别速度.
为验证文中提出的手机型号识别方法在小样本机型中的有效性,将37个非热门机型加入数据集中,即N=50,测试结果如表2所示,此时测试数据集中除了部分机型样本量较少外,还存在各机型间样本数量不均衡的情况. 因此各模型的识别准确率均出现不同程度的降低,其中S-CNN模型的降幅最小,平均检测精度仍保持在90%以上,而其余各模型由于缺乏足够的训练样本,检测准确率降幅明显. 因此,文中提出的S-CNN对小样本数据的宽容度更高,更适用于样本数小,且类别间样本数量不均衡的手机型号识别任务中.

表2 不同算法识别非热门机型精度与速度对比
4 结论
针对废旧手机回收过程中型号难以精准快速识别问题,提出一种基于CNN的手机型号识别方法,使用在实际回收过程中验机人员真实拍摄的手机图像建立手机型号识别数据集,评估该方法的有效性,得到结论如下:
1) 设计一种孪生结构的CNN网络用于评估废旧手机图像特征和手机验机照片特征的相似性,可以实现手机型号的快速识别.
2) 建立基于对比损失函数和反向传播算法的自适应学习率模型更新策略,可以提高手机型号识别精度.
3) 在后续工作中,将实现手机颜色、摄像头类型、材质、尺寸等其他属性的在线识别,并研究手机回收过程中手机表面划痕、磨损等参数的快速准确识别.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
军民两用技术与产品(2022年2期)2022-06-01
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
军民两用技术与产品(2021年12期)2021-03-09
民用飞机设计与研究(2020年4期)2021-01-21
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年9期)2020-12-28
航天工业管理(2020年4期)2020-06-16
