
基于深度学习的红外和可见光图像融合
2021-03-08 02:05李宏伟
新一代信息技术 2021年15期
李宏伟
(1. 河北地质大学信息工程学院,河北 石家庄 050030;2. 河北省智能传感物联网技术工程研究中心,河北 石家庄 050030)
0 引言
红外成像和可见光成像的融合是一个重要且经常出现的问题。最近,许多学者已经提出了融合方法来将红外和可见光图像中存在的特征组合成一个图像[1]。这些最新的方法广泛应用于许多领域,如图像预处理、目标识别和图像分类。
图像融合的关键问题是如何从源图像中提取显著特征,并将其组合生成融合图像。几十年来,许多信号处理方法被应用于图像融合领域来提取图像特征,如离散小波变换[2]、四元数小波变换[3]等。对于红外和可见光图像融合任务,Bavirisetti等人[4]提出了一种基于两个尺度分解和显著性检测的融合方法,其中通过均值和中值滤波提取基层和细节层。然后利用视觉显著性获得权重图。最后,通过这三部分结合得到融合图像。
除了上述方法之外,稀疏表示(SR)和低秩表示的作用也引起了极大的关注。宗等[5]提出了一种基于随机共振的医学图像融合方法,该方法利用方向梯度直方图(HOG)特征对图像块进行分类,并学习多个子字典[6]。采用l1范数和最大选择策略重构融合图像。
随着深度学习的兴起,源图像的深度特征也用来重构融合图像。Yu Liu等人[7]提出了一种基于卷积神经网络(CNN)的融合方法。他们使用包含输入图像的不同模糊的图像块来训练网络,并使用它来获得决策权重。最后,利用决策权重和源图像得到融合图像。虽然基于深度学习的方法取得了较好的性能,但这些方法仍然有很多缺点:1)文献[7]中的方法只适用于多焦图像融合;2)这些方法只使用最后几层计算的结果,中间几层得到的大量有用信息都会丢失。当网络越深时,信息损失越大[8]。
本文提出了一种基于深度学习框架的红外与可见光图像融合方法。结构如下:第一节介绍了基于深度学习框架的图像样式转换。第二节介绍了提出的基于深度学习的图像融合方法。第三节是实验结果。最后,第四节得出结论。
1 基于深度学习的图像样式转换
众所周知,深度学习在许多图像处理任务中取得了最先进的性能,例如图像分类。此外,深度学习也是提取图像特征的有用工具,图像特征每一层都包含不同的信息。深度学习的不同应用在过去两年里受到了很多关注。因此,深度学习也可以应用于图像融合任务。在CVPR 2016年,加蒂斯等人[9]提出了一种基于 CNN的图像风格转换方法。他们使用VGG网络[10]分别从“内容”图像、“风格”图像和生成的图像中提取不同层的深层特征。通过迭代来最小化从生成的图像和源图像中提取的深度特征的差异。生成的图像将包含来自“内容”图像的主要对象和来自“样式”图像的纹理特征。虽然这种方法可以获得良好的风格化图像,但即使使用图形处理器,其速度也非常慢。由于这些缺点,在ECCV 2016年,贾斯廷、约翰逊等人[11]提出了一个前馈网络来实时解决文献[10]中提出的优化问题。但是在这种方法中,每个网络都绑定到一个固定的样式。为了解决这个问题,在ICCV 2017年,黄浚等人[12]使用VGGnetwork和自适应实例规范化来构建一个新的风格转换框架。在这个框架中,风格化的图像可以是任意风格的,并且该方法比文献[9]快近三个数量级。这些方法有一个共同点。它们都使用多层网络特性作为约束条件。受其启发,在本文的融合方法中,多层深层特征是通过一个神经网络提取的。我们使用在 ImageNet上训练的VGG-19[10]来提取特征。本文融合方法的细节将在下一节介绍。
2 融合方法
下面将介绍基础部分和细节部分的融合处理。
假设有K个预处理源图像,在本文中,选择K=2,但是对于K>2,融合策略是相同的。源图像将表示为Ik,k∈{1,2}。首先将待融合的红外图像利用中值滤波进行预处理。然后对图像进行分解,与小波分解和潜在低秩分解等其他图像分解方法相比,优化方法[13]更有效,并且可以节省时间。因此,在本文中,使用这种方法来分解源图像。对于每个源图像Ik,获得的基础部分和细节部分由[13]分隔。基础部分通过解决以下优化问题获得:
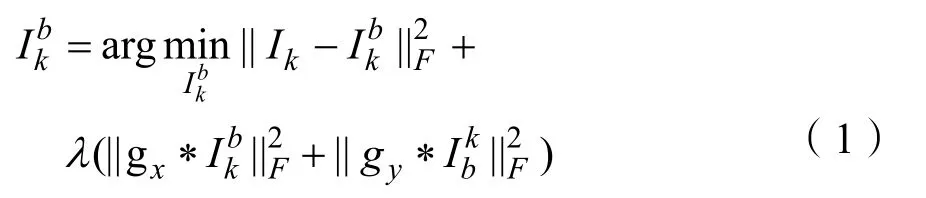
其中gx=[-1 1]和gy=[-1 1]T分别是水平和垂直梯度算子。本文中,参数λ被设置为5。在获得基础部分之后,通过公式(2)获得细节部分,

本文的融合方法框架如图1所示。

图1 本文方法框架Fig.1 the method framework of this paper
源图像表示为I1和I2。首先,通过求解方程得到每个源图像的基础部分和细节部分,I1和I2,其中k∈{1,2}。然后通过加权平均策略融合基础部分,通过深度学习框架重构细节部分。最后,将通过基础部分Fb和细节部分Fd来重构融合图像F。
2.1 基础部分的融合
从源图像中提取的基础部分包含共同特征和冗余信息。在本文中,选择加权平均策略来融合这些基础部分。融合的基础部分由公式(3)计算。
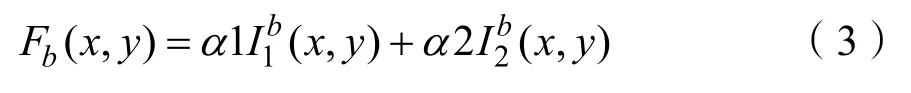
其中(x,y)表示图像强度在中的对应位置。1α和α2分别表示中像素的权重值。为了保留共同特征和减少冗余信息,本文选α1=0.5和α2 =0 .5。
2.2 细节部分的融合
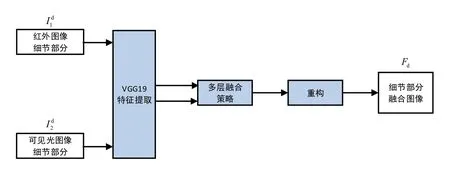
图2 细节部分融合过程Fig.2 detail part fusion process
在图2中,使用VGG-19提取细节部分的深层特征。然后通过多层融合策略得到两个细节部分的权重图。最后,通过权重图和细节部分重构得到融合后的细节部分。
接下来,详细介绍多层融合策略。

其中每个Φi(·)表示 VGG网络中的一层,而i∈ { 1,2,3,4}分别表示 relu_1_2、relu_2_2、relu_3_2和relu_4_2。
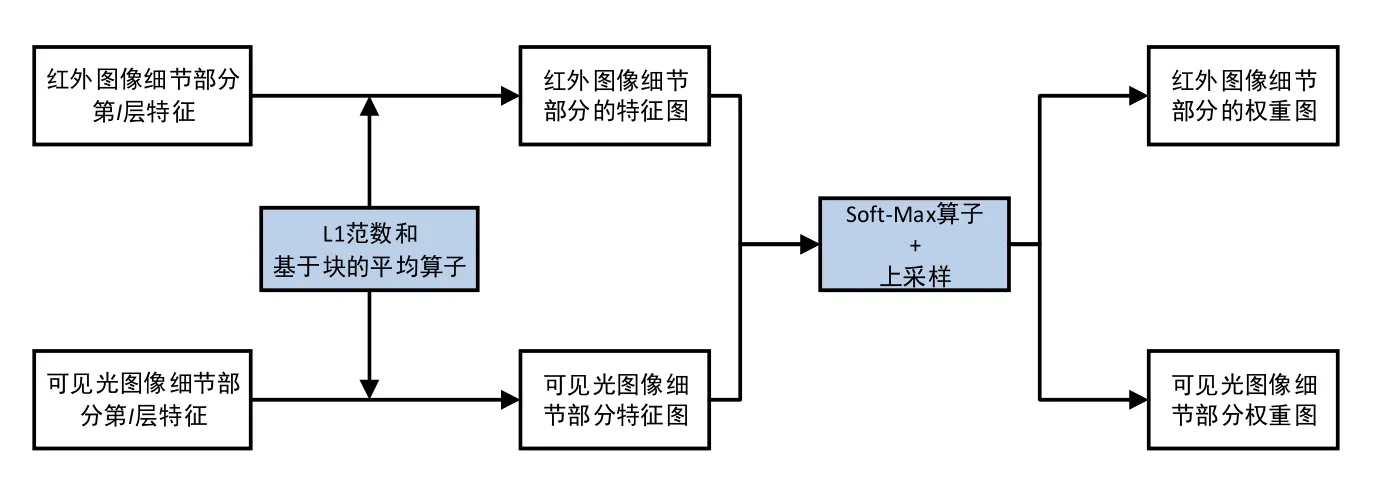
图3 细节部分的融合策略流程Fig.3 integration strategy process of details
受[12]的启发,的l范数可以作为源1细节部分的特征度量。因此,初始特征图由下式获得。
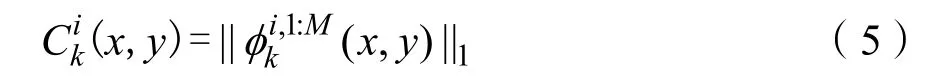
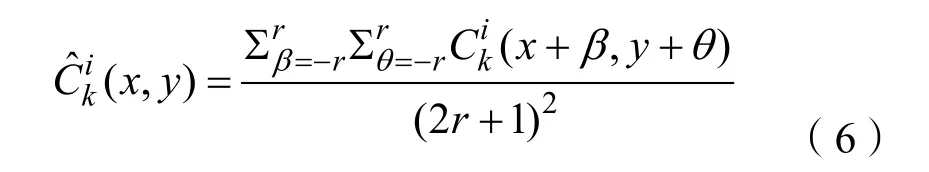
其中块的大小取决于r的值。r值越大,融合方法对配准错误的鲁棒性越强,但大概率会失去一些细节。所以,在本方法中r取1。
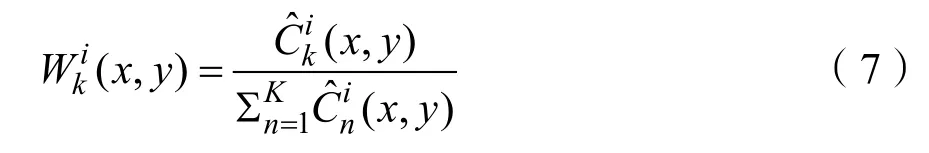
其中K表示特征图的数量,在本文中设置为K= 2 。表示[0,1]范围内的初始权重映射值。
众所周知,VGG网络中的汇集算子是一种子抽样方法。每次该运算符将要素映射的大小调整为原始大小的1/s倍,其中s是池化的步长。在VGG网络中,池化的步长是2。因此,在不同的图层中,特征图的大小是详细内容大小的 1 /2i-1倍,其中i∈ { 1,2,3,4}分别表示 relu_1_2、relu_2_2、relu_3_2和relu_4_2的图层。在得到每个初始权重图之后,使用一个上采样将权重图的大小调整到输入细节部分的大小。最终的权重图由公式(8)计算。
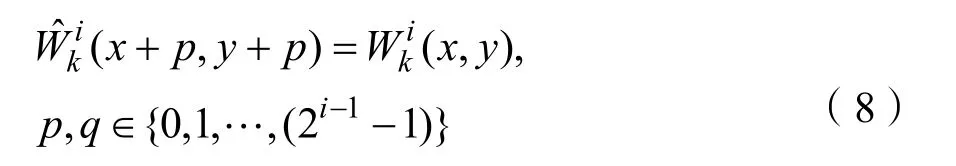

最后,通过公式(10)获得融合细节部分Fd,从每个位置的四个初始融合细节部分中选择最大值。
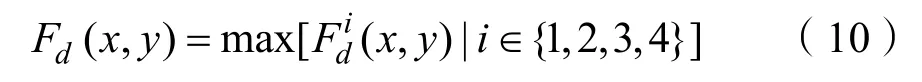
2.3 重构
获得融合的细节部分Fd后,使用融合的基础部分Fb和融合的细节部分Fd来重构最终的融合图像,如公式(11)所示。
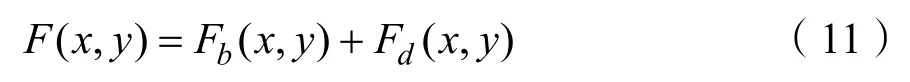
2.4 融合方法概述
在本节中,将提出的基于深度学习的融合方法总结如下:
(1)图像去噪:通过中值滤波去除红外图像的噪声。
(2)图像分解:通过图像分解操作[13]对源图像进行分解,以获得基础部分和细节部分,其中k∈{1,2}。
(3)基础部分的融合:选择加权平均融合策略来融合基础部分,每个基础部分的权重值为0.5。
(4)细节部分融合:通过多层融合策略获得融合后的细节部分。
(5)重构:最后,由公式(11)给出融合图像。
3 实验结果与分析
实验将本文方法与现有方法进行比较。然后使用主客观标准验证本文方法的效果。
3.1 实验设置
在实验中,有18对源红外和可见光图像。所有融合算法均在3.4 GHz Intel(R) Core(TM) CPU上的MATLAB R2020a中实现。
在多层融合策略中,从预先训练的 VGG-19网络[12]中选择几层来提取深层特征。这些层分别是relu_1_2、relu_2_2、relu_3_2和relu_4_2。
为了与本文方法比较,选择了几种最近的和经典的融合方法来进行相同的实验,包括:交叉双边滤波融合方法(CBF)[14]、联合稀疏表示模型(JSR)、具有显著性检测的 JSR模型融合方法(JSRSD)[15]、基于加权最小二乘优化的方法(WLS)[7]和卷积稀疏表示模型(ConSR)。
3.2 主观评价
图4表示出了由五种现有方法和本文方法获得的融合图像。由于篇幅限制,仅在一对图像上评估融合方法的相对性能。

图4 融合图像结果Fig.4 fusion image results
正如从图 4(8)中看到的,通过本文方法获得的融合图像中保留了更多的细节信息,并且包含更少的人为噪声。由CBF、JSRSD、WLS和ConvSR得到的融合图像含有较多的人工噪声,显著特征不明显,图像细节模糊。相比之下,JSR和本文的融合方法包含更多显著特征,并且保留了更多的细节信息。与现有的五种融合方法相比,本文方法得到的融合图像看起来更加自然。
3.3 客观评价
为了定量比较本文方法和现有的融合方法,使用了四个质量指标。它们是:分别为离散余弦(FMI)和小波特征的互信息(FMI);N[16]dctwabf表示通过融合过程添加到融合图像的噪声或伪影的比率;和改进的结构相似性(SSIMa)。在本文中,通过公式(12)计算SSIMa。
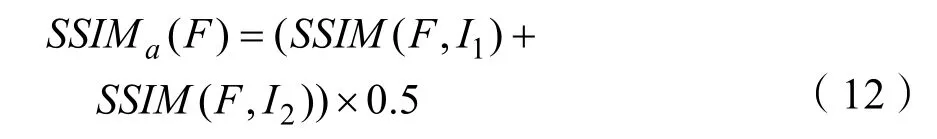
其中SSIM(·)表示结构相似性运算,F是融合图像,I1,I2是源图像。SSIMa值用来评估图片保存结构信息的能力。
方法的性能随着FMIdct、FMIw和SSIMa数值的增加而提高。相反,当Nabf值较小时,融合性能较好,这意味着融合图像包含的人工信息和噪声较少。用现有方法和本文方法得到的18幅融合图像的Nabf均值如表1所示。
在表1中,FMIdct、FMIw、SSIMa和Nabf的最佳值以粗体显示。如表所示,本文方法具有这些指标的所有最佳平均值。这些值表明,通过本文方法获得的融合图像更加自然,并且包含较少的人工噪声。从客观评价来看,本文的融合方法比现有方法具有更好的融合性能。更进一步的,图5中给出了通过这些方法产生的18对图像的所有Nabf值的折线图。
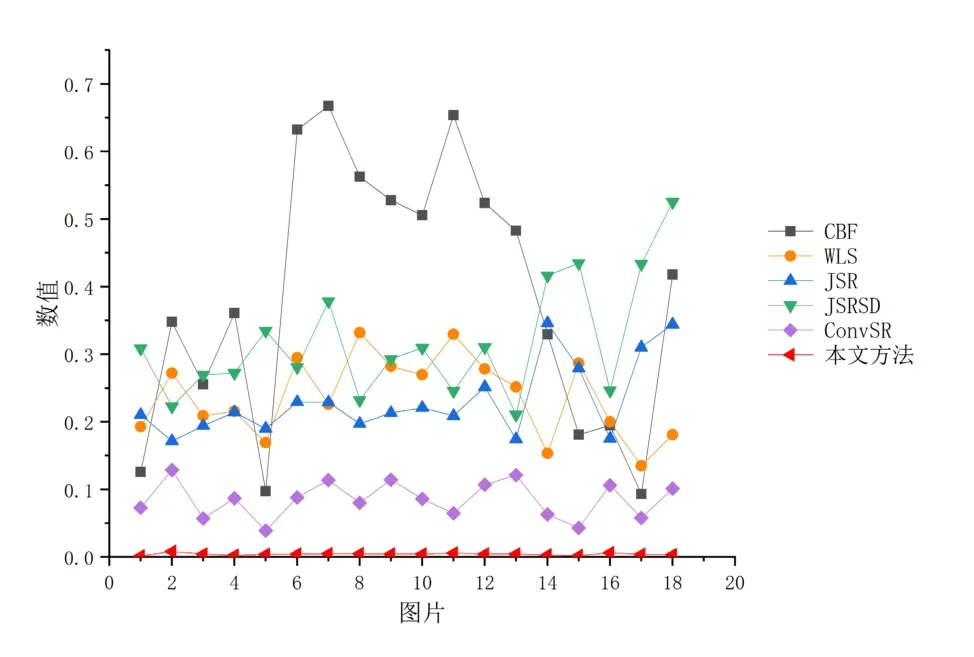
图5 18幅图像的所有Nabf值Fig.5 All Nabf values of 18 images
从表1可以看出,本文方法测得的Nabf值比CBF、JSR和 JSRSD大约低两个数量级。与ConvSR相比,该方法的Nabf值也非常小。这表明该方法得到的融合图像包含较少的人工信息和噪声。
4 结论
本文提出了一种简单有效的基于深度学习框架(VGG网络)的红外与可见光图像融合方法。首先,将红外图像运用中值滤波去除噪声。然后将源图像分解为基础部分和细节部分。前者包含低频信息,后者包含纹理信息。这些基础部分通过加权平均策略进行融合。针对细节部分,提出了一种基于预训练的VGG-19网络的多层融合策略。细节部分的深层特征由VGG-19网络获得。运用l1范数和块平均算子获得初始权重图。最终的权重图由Soft-Max算子获得。由每对权重图和输入细节部分生成初始融合细节部分。融合的细节部分通过这些初始融合的细节部分的最大选择算子来重构。最后,通过融合后的基础部分和细节部分来重构融合图像。然后使用主观和客观的方法来评估本文方法。实验结果表明,该方法具有较好的融合性能。
猜你喜欢
心理学报(2022年5期)2022-05-16
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
当代陕西(2020年17期)2020-10-28
求学·文科版(2018年10期)2018-11-02
求学·理科版(2018年10期)2018-11-02
人大建设(2018年5期)2018-08-16
劳动保护(2018年5期)2018-06-05
证券市场红周刊(2018年3期)2018-05-14
