
面向企业动态风险的知识图谱构建与应用研究
2021-03-08 02:55杨波廖怡茗
现代情报 2021年3期
关键词:知识图谱
杨波 廖怡茗

摘 要:[目的/意義]构建企业风险知识图谱,是对大数据环境下企业知识资源的有效组织和利用。针对现有企业知识图谱多为知识的静态映射问题,本文引入时间维度来刻画企业风险事件的动态性、突发性和时效性等演化特征。[方法/过程]经过企业风险知识的信息抽取、知识融合、本体构建以及动态知识推理等环节,自底向上系统性地构建了企业动态风险知识图谱。在企业风险知识融合阶段,针对企业领域数据集实体样本的不平衡分类问题,本文提出ResNet动态知识推理方法改进了Multi-Net模型的损失平衡函数。[结果/结论]实验表明该知识推理方法能够有效提高实体预测和关系预测的准确性,对于企业领域知识具有良好的适用性,最后本文将该知识图谱应用于一个智能问答系统。
关键词:企业动态风险;知识图谱;知识融合;动态知识推理
DOI:10.3969/j.issn.1008-0821.2021.03.011
〔中图分类号〕G203 〔文献标识码〕A 〔文章编号〕1008-0821(2021)03-0110-11
Research on the Construction and Application of
Knowledge Graph for Enterprise Dynamic Risk
Yang Bo Liao Yiming
(School of Information Management,Jiangxi University of Finance and Economics,Nanchang 330013,China)
Abstract:[Purpose/Significance]Constructing an enterprise risk knowledge graph is an effective organization and utilization of enterprise knowledge resources in a big data environment.Aiming at the problem of static mapping of existing enterprise knowledge graphs,this paper introduces the time dimension to describe the evolutionary characteristics of enterprise risk events such as dynamics,suddenness and timeliness.[Method/Process]Through information extraction,knowledge fusion,ontology construction and dynamic knowledge reasoning of enterprise risk knowledge,a bottom-up enterprise dynamic risk knowledge graph was systematically constructed.In the enterprise risk knowledge fusion link,aiming at the imbalanced classification problem of the entity samples of the enterprise domain data set,this paper proposed the ResNet dynamic knowledge reasoning method to improve the loss balance function of the Multi-Net model.[Result/Conclusion]Experiments showed that the new model could effectively improve the accuracy of entity prediction and relationship prediction,which had good applicability to enterprise domain knowledge.Finally,the knowledge graph was applied to an intelligent question answering system.
Key words:enterprise dynamic risk;knowledge graph;knowledge fusion;dynamic knowledge reasoning
随着Web技术普及和社会信息化程度的提高,Web技术正向着基于知识互联的语义Web方向发展,信息的多变性、异构性和自治性使得人们难以从海量信息中获取所需目标资源[1]。知识图谱以其强大的语义处理能力和开放互联能力,让大数据环境下的知识资源组织和管理更为高效,能够有效解决智能搜索、智能问答、个性化推荐等基于知识的推理和决策问题。知识图谱(Knowledge Graph)的概念最早在2012年由谷歌正式提出,是用于增强其搜索引擎功能的知识库,在智能搜索、情报分析、社交网络、深度问答以及垂直行业[2-3]等领域取得了广泛的应用,此后各互联网公司也纷纷推出各自的知识图谱产品。当前,国内外研究人员开发了诸多高质量大规模开放知识图谱,包括DBpedia、Yago、BabelNet、ConceptNet以及Microsoft Concept Graph[3]等通用知识图谱,以及阿里巴巴电商知识图谱、Linked Life Data医疗项目和Kensho投资咨询等垂直领域知识图谱[4]。
大数据环境下,企业风险管理面临信息爆炸的难题,企业风险知识涉及经济、产业、投资等覆盖全行业的相关知识,知识图谱在企业商业活动、创投咨询及证券等金融领域具有重要价值,广泛应用于挖掘潜在客户、反欺诈、内审内控、失联客户管理以及风险识别和预警等业务[5-6]。例如,建立行业、企业、客户的实体关联关系,根据贷款信息、行业信息建立关系挖掘模型,及时预测高风险行业及风险事件,企业可以尽早规避系统性风险;在风险预警中,构建基于企业现金流、经营信息等属性值的实体关联,通过深度学习方法对属性值以及其衍生指标进行实时监控,可以完善企业的风险预警系统。因此,研究企业风险知识图谱具有重要实践价值和理论意义,是对金融领域知识图谱的进一步探索和完善。
企业风险事件往往具有动态性、突发性和时效性等演化特征,与其发生时间密切相关,在构建企业风险知识图谱时加入时间信息,对于管理层把控决策风向标至关重要。目前已有学者构建了金融领域知识图谱,但是面向企业风险的知识图谱研究仍相对匮乏,且多数只集中于某一特定环节,如面向企业知识图谱的中文命名实体识别[7]、实体链接[8]、关系抽取[9-10]等技术过程。尽管陈晓军等[11]系统地研究了企业风险知识图谱,并通过智能问答实现了对知识图谱地检索和利用,但仅仅构建了一个静态的企业知识图谱,缺乏利用时间信息推理知识图谱的演化过程,且未考虑到风险知识的动态特征。领域知识图谱相对于通用知识图谱来说,知识的广度、深度和粒度都有更加严格的要求,企业风险知识的一个显著特征是高度动态性,其知识图谱的构建便需要结合风险知识的时效性。有鉴于此,本文面向企业动态风险引入时间维度,从信息获取、知识融合、本体构建和动态知识推理4个环节自底向上构建企业风险知识图谱,并基于该企业动态风险知识图谱构建了一个智能问答系统,以可视化的图谱形式实现用户对企业风险信息的动态把控。
1 相关工作
构建面向企业动态风险的垂直领域知识图谱,不仅要基于面向企业风险管理的领域知识,也需采用有效的动态图谱构建技术模型。本节将介绍企业风险知识图谱以及动态知识图谱构建方法的相关研究。
1.1 企业风险知识图谱研究现状
企业知识图谱是指关注于企业信息和关系的垂直领域知识图谱[10],属于金融领域,具有巨大的商业价值,目前国内关于金融领域特别是企业风险领域的知识图谱研究仍有待展开。王超[7]在经典的BiLSTM-CRF命名实体识别模型的基础上融入Self-Attention机制,提出SA-BiLSTM-CRF模型,将其应用于标注语料较少的企业领域,提出适用于企业领域的命名实体识别系统,并基于此完成了企业图谱的构建,具有一定的工程应用价值。刘波[8]提出了一个结合上下文匹配和知识库信息检索策略的实体指称扩展方法,根据候选实体消歧和实体生成方法设计了一个实体链接系统,最后使用Neo4j将其应用到企业领域知识图谱的构建中。孙晨等[9]针对企业知识图谱在关系抽取效果上的局限性,提出给予分类的中文实体关系抽取方法,使用最大熵模型构建更为完整的企业知识图谱。吴锦钰[10]提出BiGRU-CNN和BiGRU-Incep两种基于深度学习的关系抽取模型,并通过注意力机制给不同实例句子分配权重以提高实体关系抽取的准确率,构建了一个小型的企业图谱。然而,这些研究都只关注于知识图谱构建的某一环节而缺少全面性,也忽略了时间信息对风险演化的影响。
在风控场景中,企业图谱可以探查包括客户风险、竞争风险、政策风险以及市场风险等在内的企业外部风险,提供探究企业内外主体及关系链的工具,能够对行业热点、政策和关联企业等进行智能分析和风险预警,目前国内发展比较成熟的有阿里云企业图谱、百度云企业图谱和海致企业图谱[11]。在风险识别方面,马海波[12]结合企业基本属性和企业历史风险中的特征信息,构建企业关联信息知识图谱,通过分析企业节点和低信用列表实体节点的关系特征,提高了企业风险识别的能力。一些金融机构如浦发银行等也将知识图谱应用于风险预测中,但是企业风險知识图谱的工业级应用研究处于初步阶段,如何系统而又全面地构建风险知识图谱,提高企业风险管理中领域知识利用效率仍有待探索。
1.2 动态知识图谱研究现状
传统知识图谱被认为是对多关系数据的静态映射,而基于事件的交互知识除了有多关系性外,还具有复杂的时间动态特征,引起了众多学者的广泛关注,近年来融合时间维度信息来构建动态知识图谱的研究也逐渐兴起。Trivedi R等[13]采用随时间推移的非线性演化的实体表示形式,提出包含时间边沿的深度进化知识网络图(Know-Evolve),有效地预测了事实的发生概率或复发时间,但无法解决并发事件的推理难题。
一些学者还关注于研究基于时间信息进行建模的方法。García-Durán等[14]提出时序知识的补全方法(Temporal-Aware Version of Trans E,TA-Trans E),利用递归神经网络学习关系类型的时间信息表示,缓解了知识在时间表达上的稀疏性和异质性。Leblay J等[15]提出推演知识图谱的时序方法(Temporal TransE,TTransE),采用时间间隔注释实体边缘以反映实体关系时间维度的一致性,同时预测了未注释边缘时间有效性的任务。Dasgupta S S等[16]考虑知识图谱中的关系事实通常表现出时间动态特征,提出基于超平面的时间感知知识图谱嵌入方法(Hyperplane-Based Temporally Aware Knowledge Graph Embedding,HyTE),通过把每个时间戳与相应的超平面相关联,将时间合并到实体关系空间中。Liu J等[17]为了弥补演化知识图谱模态表征和算法的不足,提出进化知识图谱(Evolve Knowledge Graph,EvolveKG),揭示了跨时间知识交互以及所需的存储和计算性能,利用历史影响力来预测未来的知识。然而这些动态推理模型都是对单个时间点的处理,没有捕捉到事实的时间相关性,只能对某个时间戳的知识图谱进行处理。
为了实现在全时间域内对实体节点之间的时间、多关系和并发交互进行建模,Jin W等[18]提出对复杂事件序列进行建模的循环事件网络(Recurrent Event Network,RE-NET),解决了对多个时间点高并发事件的推理难题,以及随着时间的推移进行多步知识推理。在此基础上,为了进一步提高动态图谱在多关系对应下的推理能力,陈浩等[19]改进了RE-NET的邻近聚合器,提出多关系循环事件的动态知识图谱推理方法(Dynamic Knowledge Graph Inference Based on Multiple Relation Cyclic Events,Multi-Net),通过增强对同时间戳内多个关系实体的聚合能力,提高了实体关系预测和实体消歧的精准度。综上所述,目前对于动态知识图谱的时间维度建模、时序知识推理的相关研究已取得了不同程度的进展,然而这些方法主要针对大规模通用知识图谱,对于垂直领域特别是企业风险知识图谱的适用性仍有待探究。
2 企业动态风险知识图谱构建
知识图谱主要有自顶向下(Top-down)和自底向上(Bottom-up)两种技术构建方式[2]。自底向上的构建方式首先对实体进行归纳组织形成底层的概念,逐步向上抽取形成上层的概念[4],即从一些开放链接数据中提取实体,选择置信度较高的实体加入知识库中,再构建顶层的本体概念模式[2]。随着知识抽取和知识加工技术的不断成熟,目前大多数知识图谱采用自底向上的方式构建,例如微软的Satori知识库和Google的Knowledge Vault,都是基于公开的海量网页数据自动抽取资源来获取知识[20]。
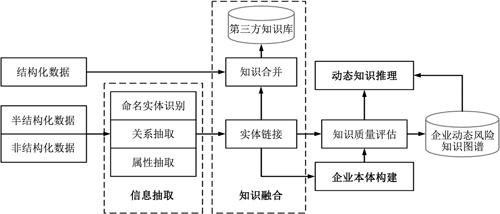
垂直领域知识具有极强的专业性,主要针对专业领域或行业的特定数据资源,同时考虑企业风险知识体系缺乏完备性的特点,本文采用自底向上的方式[20]构建知识图谱,企业风险知识图谱的技术架构如图1所示,主要由4个步骤构成,分别是信息抽取、知识融合、企业本体构建和动态知识推理。
2.1 信息抽取
信息抽取是知识图谱构建的首要环节,解决如何从多源异构信息中自动抽取出候选知识单元的问题,其中面向文本的信息抽取一般包括命名实体识别和关系抽取两个任务。本文选取的实验数据来自人民日报标注语料库,再通过百科数据得到企业基本信息对原始语料库进行补充;此外该语料库属于新闻领域,而企业风险知识图谱的构建重点关注于人物及企业领域的实体,于是又选择爬取到的3 461条企业新闻对已有数据集进行扩充。首先过滤和筛选了数据集中的冗余和不相关信息,再对这些半结构化和非结构化的风险数据进行抽取。
1)命名实体识别。命名实体识别又称实体抽取,是指从非结构化或半结构化的文本信息中提取出多种指定类别的实体,其识别质量对于后续实体链接和合并的效率影响极大,是信息抽取中最关键和基础的环节。企业领域命名实体识别主要关注于人名、机构名和地名实体等专有名词,以及与动态风险密切相关的时间实体信息,特别是公司名称、缩略词、企业专有名词等的识别。
根据命名实体识别技术的发展脉络,命名实体识别的方法可以分为:基于规则、基于词典、基于统计和基于深度学习4类。基于规则的命名实体识别可以根据不同行业的文本数据,制定出与该行业特点最适用的规则模型,但是可移植性较差,过于依赖具体领域、语言和文本风格;基于词典的方法根据文本在预先构建的词典中的匹配结果来识别领域实体,由于词典收录实体完备性不足且难以更新,一般与基于规则或基于统计的方法结合使用;基于统计的常用方法有隐马尔科夫链模型和条件随机场模型等,前者没有考虑实际文本处理中的上下文语义问题,对于领域标注的性能不高,条件随机场模型则需要使用标注好的语料训练模型。由于企业风险知识图谱的构建对知识的准确率有更高的要求,且企业领域的规范语料标注较少,本文采用基于迁移学习的SA-BiLSTM-CRF模型[7]识别企业领域实体,迁移学习可以使得范围更广泛的语料数据在企业领域得到较好的识别效果。
经典的BiLSTM-CRF命名实体识别模型包括Embedding层、BiLSTM编码器和CRF层,其中LSTM网络在处理长语句序列中较远距离的依赖特征时,经过多时间步骤的累积才能实现特征间的聯系,于是加入Self-Attention机制缩短距离来提高这些依赖特征的利用效果,模型结构如图2所示。其中X={x1,x2,…,xn}是由n个中文字符组成的输入序列;经过Embedding层字符嵌入后,E={Ec,Ep}分别表示字向量Ec,以及兼顾语句中词序信息的位置向量Ep;字符向量分别以正向和反向顺序输入LSTM网络,得到含有上下文信息的特征Hi=[i,i];其次在Self-Attention层中通过Softmax函数归一化,再加权求和得到含有正反语义信息的输出H′i=[i,i,i,i];CRF层的作用在于解决有依赖关系的标签分类问题,输出与输入序列等长的标签序列Y={y1,y2,…,yn},最后使用BIEO标注体系对各实体进行标注。
值得注意的是,企业领域语料标注较少,人民日报语料库属于新闻类标注语料库,直接使用会导致一些企业领域特征在新闻领域的局限下被忽略,本文通过迁移学习来优化上述深度学习模型。对于提取人名、地名、机构名的实体识别来说,企业和新闻领域的数据有极大的相似性,以新闻领域为源领域,企业领域为目标领域,首先使用人民日报语料库的新闻语料进行预训练,再基于百科网页爬取到的1 429条企业领域标注数据进行训练,将前者的SA-BiLSTM-CRF模型的参数训练结果分别迁移到后者模型的Embedding层和CRF层上,形成4个参数各异的对比实验。从表1的实验结果来看,人民日报语料库与企业领域数据存在一定程度上的相似性,迁移学习能够有效提升SA-BiLSTM-CRF模型的实体识别效果。
2)企业实体关系抽取。命名实体识别之后的企业领域实体是离散的,为了得到企业实体间的关联关系,通过关系抽取则可以获取语义信息;企业的属性一般包括创始人、董事长、高管、成立年份、城市等,通常也将企业属性作为实体关系的一种,因此还需从企业百科网页的基本信息中对各企业进行属性抽取。此外动态知识图谱的实体关系应当包含时序信息,吴锦钰提出的BiGRU-CNN和BiGRU-Incep关系抽取方法[10]不仅注重时序信息的提取,而且关注于位置信息的提取,本文分别采用了这两种模型进行实验和比较。在进行关系特征提取时,将语料句法特征与实体特征相结合,首先把输入的关系实例语句转化为二维特征向量作为主要输入特征,同时将实体特征如实体的长度、位置、上下文等特征输入到Softmax分类器进行特征融合,最终输出Softmax概率最大的节点即为抽取得到的实体关系。
实体关系一般与前后实体形成“<实体1><关系><实体2>”结构的知识三元组存储到知识库中,实体属性则通过
2.2 知识融合
经过信息抽取,获取了企业实体和实体间的关系、属性以及部分时间信息,尽管优化的深度学习模型在实体识别和关系抽取中都存在优势,这些结果还可能包含大量的冗余和冲突信息,同时为了提升知识的逻辑性和层次性,有必要对知识进行融合,删除错误和冗余的知识,消歧矛盾和冲突知识,从而达到提升企业风险知识质量的目的,其中实体链接和知识合并是知识融合的两个主要任务。
1)实体链接。实体链接是指将从文本中抽取到的企业实体对象,链接到企业知识库中所对应的、指向现实世界同一事实的命名实体[20]。由于企业领域实体指称复杂多样,如“阿里巴巴集团”和“阿里巴巴(中国)有限公司”指向同一实体,此外来源于网络的语料和百科数据不规范,通过实体链接则可以有效解决企业实体指称的多样性和歧义性。目前实体链接的算法主要有无监督的和有监督的,无监督的算法一般基于字典匹配或者相似度计算,对数据的规范化程度要求较高,企业领域实体数据复杂且不规范,于是采用融合卷积神经网络(CNN)和余弦相似度[8]的有监督算法进行企业实体链接。
融合CNN和余弦相似度的实体链接模型结构主要分为:输入层、CNN表示层、匹配层和输出层。根据实体命名识别的结果,首先对语料数据进行预处理,把以缩写、简称、别名等存在的企业实体进行查询修正,使用上下文匹配和知识库信息检索策略对实体指称进行扩展,得到标准的实体名称集合M={M1,M2,…,MN},并基于匹配规则[8]的方法生成候选实体集C={C1,C2,…,CN},使用Google开发的开源计算工具Word2Vec对候选实体集的词向量化作为模型的输入。其次通过CNN表示层计算语义特征,将原始的高维文本特征,映射到低维的语义空间向量中,输出一个概念向量,再使用经典的余弦相似度算法完成对实体概念向量的匹配。为了提高实体排序算法的性能,引入空实体判别机制,若候选实体集为空则认为不存在歧义实体,对于候选实体排序结果设定阈值,若相似度小于该阈值也判定为空實体,最后与不使用空实体判别机制的实验进行了对比。表3所示的实验结果表明,与单一的候选实体消歧算法相比,空实体判别能够有效提升模型的准确率和召回率。
2)知识合并。人民日报语料库以及企业新闻数据属于半结构化和非结构化的文本数据,除此之外第三方知识库和已有的结构化数据可以扩展现有知识库,于是选取百度百科、维基百科中文版和互动百科知识库中的部分企业网页信息,爬取网页源代码中Title=“同义词”的标签获取同义词作为候选实体集,对其进行实体消歧后得到了企业的属性信息,再将这些知识元素经实体链接后加入到了企业风险知识库,实现了结构化风险知识的合并。
2.3 本体构建
知识图谱从逻辑上可以划分为数据层和模式层[20],知识融合后得到了一系列正确的企业领域的基本事实表达,然而事实本身并不等同于知识,为了获取具有逻辑结构的知识体系,还需要进行本体构建来建立模式层的概念模板,借助本体库来规范企业实体、关系以及实体的属性和类型等对象之间的联系。目前常用的本体构建工具主要有可视化手工构建和半自动化构建两类,尚未出现自动化的构建工具,其中基于Java语言的Jena推理机[22]提供了通过程序调用算法半自动化地构建本体的方法,Jena推理机能够存储大规模的RDF数据,同时提供处理OWL本体语言和RDFS本体的API,大大提高了本体构建的效率。数据驱动的半自动化本体构建过程[2]主要可以分为3个阶段:①概念的并列关系计算;②实体的上下位关系抽取,主要是实体隶属关系(HasA)的抽取,例如淘宝网和阿里巴巴集团之间属于隶属关系;③生成本体,一般采用层次聚类[23]的方法,对各层次的抽象概念进行聚类并指定公共上位词来构建本体结构。
3 基于动态知识图谱的智能问答应用
企业动态风险知识图谱实现了对融合时间信息的企业风险知识的关联与整合,是对风险知识专业化和结构化的语义表示,然而通过关键词搜索知识图谱的结果,用户还不能获得与风险防控密切相关的有效信息,因此本文将企业动态风险知识图谱应用于风险知识智能问答系统,进一步提升用户获取目标知识的针对性和准确性。问答系统对用户问题的自然语言理解程度决定了系统生成答案的准确性,多輪问答机制通过多次追问的策略补充用户问题所缺失的语义系统信息,帮助系统更准确地理解用户意图。本文采用多轮自动问答系统框架[26]构建了基于企业动态风险知识图谱的智能问答系统,主要包括问题理解、知识图谱查询和问答生成3个模块,该系统的框架如图8所示。
如图8所示,问题理解模块旨在将非结构化的问题文本转化为结构化的语义表示。本文首先使用Jieba分词对输入的问句文本进行中文分词和词性标注,以及日期和数值处理等一系列预处理,如将“今天”一词转化为系统当日时间“2020年7月18日”;其次进行风险事件识别,风险事件实例一般分为4类:研发风险、管理者认知风险、产品适应性风险和社会网络风险;意图识别是指对问句文本中用户提问意图的识别,与后续生成问答结果直接对应;本体属性识别则是对问句文本中实体属性和属性值的识别。例如,输入问句“2020年8月14日,饿了么逼迫商户二选一遭20户商家联名举报,市场监督管理局会罚款多少?”,所识别到的实体为“饿了么”“商户”和“市场监督管理局”,实体关系和风险事件时间为<举报><2020年8月14日>,风险事件实例为管理者认知风险,意图识别结果为罚款结果,蕴含的属性为饿了么平台的“商户数量”,属性值为“20”。知识图谱查询模块按照预定义的Cypher查询模板,输入问题理解中所识别的风险事件、问题意图、实体属性和属性值进行查询;再对查询到的子图谱进行结果计算,通过将问句文本中识别到的实体属性集合与子图谱依次计算差集来完成。若用户输入的问句文本语义完整,并且查询结果符合答案阈值,则直接将查询结果返回给用户,否则通过Cypher查询模板对用户进行缺失语义信息的追问。
本文通过Django实现对该智能问答系统的问答结果可视化。Django提供的Model-View-Controller开发框架无需第三方库和工具便可以创建网站,是一个功能较为全面的Python Web开发框架。图9所示为该智能问答系统输入“与阿里巴巴创始人相关的风险关联关系有哪些”等问题的可视化界面。
4 结 语
针对现有企业风险知识图谱的构建方法大多为静态知识映射,缺乏对企业风险的时间动态特征建模,本文将时间信息融入企业知识图谱构建。本文详细阐述了自底向上构建面向企业动态风险知识图谱的完整过程,首先对企业风险领域的语料文本进行信息抽取;其次通过实体链接和知识合并技术,将抽取到的命名实体、关系和日期或时间信息进行知识融合,并构建了企业风险领域本体;针对企业领域数据集实体样本的不平衡分类问题,本文提出的Multi-Net(ResNet)动态知识推理方法改进了原模型的损失平衡函数,实验表明该方法能够有效提高实体预测和关系预测的准确性;最后构建了企业动态风险知识图谱,并将该知识图谱应用于智能问答系统。本研究仅仅是面向企业动态风险知识图谱构建的初步探索,对于模型中知识随时间演化、转移的完善还需进一步研究。
参考文献
[1]谢能付.基于语义Web技术的知识融合和同步方法研究[D].北京:中国科学院研究生院(计算技术研究所),2006.
[2]徐增林,盛泳潘,贺丽荣,等.知识图谱技术综述[J].电子科技大学学报,2016,45(4):589-606.
[3]漆桂林,高桓,吴天星.知识图谱研究进展[J].情报工程,2017,3(1):4-25.
[4]王昊奋,漆桂林,陈华钧.知识图谱:方法、实践与应用[M].北京:电子工业出版社,2019.
[5]姜渊,黄桦,赵奕.知识图谱在金融行业的应用展望[J].金融电子化,2016,(9):87.
[6]雷丰羽.知识图谱在金融信贷领域的应用[J].现代商业,2018,(10):89-90.
[7]王超.面向企业图谱构建的中文命名实体识别技术研究[D].南京:东南大学,2019.
[8]刘波.面向企业图谱的实体链接技术的研究[D].南京:东南大学,2019.
[9]孙晨,付英男,程文亮,等.面向企业知识图谱构建的中文实体关系抽取[J].华东师范大学学报:自然科学版,2018,(3):55-66.
[10]吴锦钰.面向企业图谱构建的关系抽取技术研究[D].南京:东南大学,2019.
[11]陈晓军,向阳.企业风险知识图谱的构建及应用[J/OL].计算机科学:1-11.http://kns.cnki.net/kcms/detail/50.1075.TP.20200721.1547.078.html,2020-07-28.
[12]马海波.面向风控的企业关联信息知识图谱构建与应用研究[D].北京:北京工业大学,2019.
[13]Trivedi R,Dai H,Wang Y,et al.Know-Evolve:Deep Temporal Reasoning for Dynamic Knowledge Graphs[J].2017.
[14]García-Durán,Alberto,Dumani S,et al.Learning Sequence Encoders for Temporal Knowledge Graph Completion[J].2018.
[15]Leblay J,Chekol M W.Deriving Validity Time in Knowledge Graph[C]//Companion of the the Web Conference,2018:1771-1776.
[16]Dasgupta S S,Ray S N,Talukdar P.HyTE:Hyperplane-based Temporally Aware Knowledge Graph Embedding[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,2018.
[17]Liu J,Zhang Q,Fu L,et al.Evolving Knowledge Graphs[C]//IEEE INFOCOM 2019-IEEE Conference on Computer Communications.IEEE,2019.
[18]Jin W,Jiang H,Qu M,et al.Recurrent Event Network:Global Structure Inference over Temporal Knowledge Graph[J].2019.
[19]陳浩,李永强,冯远静.基于多关系循环事件的动态知识图谱推理[J].模式识别与人工智能,2020,33(4):337-343.
[20]刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研究与发展,2016,53(3):582-600.
[21]任飞亮,沈继坤,孙宾宾,等.从文本中构建领域本体技术综述[J].计算机学报,2019,42(3):654-676.
[22]王向前,张宝隆,李慧宗.本体研究综述[J].情报杂志,2016,35(6):163-170.
[23]Wang C,Danilevsky M,Desai N,et al.A Phrase Mining Framework for Recursive Construction of a Topical Hierarchy[C]//Proc of the 19th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining.New York:ACM,2013:437-445.
[24]黄庆康,宋恺涛,陆建峰.应用于不平衡多分类问题的损失平衡函数[J].智能系统学报,2019,14(5):953-958.
[25]Bordes A,Usunier N,Garcia-Duran A,et al.Translating Embeddings for Modeling Multi-relational Data//Burges C J C,Bottou L,Welling M,et al.,eds.Advances in Neural Information Processing Systems 26.Cambridge,USA:The MIT Press,2013:2787-2795.
[26]陈金菊,王义真,欧石燕.基于道路法规知识图谱的多轮自动问答研究[J].现代情报,2020,40(8):98-110,120.
[27]刘良.基于领域知识图谱的智能问答关键技术研究[D].成都:电子科技大学,2020.
(责任编辑:孙国雷)
猜你喜欢
