
基于近端策略优化的作战实体博弈对抗算法
2021-03-09 02:34黄炎焱张永亮陈天德
南京理工大学学报 2021年1期
张 振,黄炎焱,张永亮,陈天德
(1.南京理工大学 自动化学院,江苏 南京 210094;2.陆军工程大学 指挥控制工程学院,江苏 南京 210007)
随着机器学习和人工智能在现实生活中得到越来越广泛的运用,越来越多的游戏通过训练智能体的方式与人类进行对抗,典型代表有在围棋领域获得成功的人工智能AlphaGo以及在游戏《星际争霸》人机对抗赛中获得成功的人工智能AlphaStar[1]等。
越来越多的研究将人工智能方法融入到计算机兵棋推演领域。胡晓峰等[2]从AlphaGo的成功分析了兵棋推演面临的瓶颈,指出了作战智能态势认知是兵棋推演中亟需突破的关键环节。戴勇等[3]基于兵棋推演的特点以及人工智能发展现状和核心技术,明确了将人工智能如深度学习应用在兵棋推演领域中将会遇到的问题以及解决途径。李承兴等[4]以装备维修保障兵棋推演为仿真环境,针对装备维修保障过程中的装备受损和机动维修分队抵达受损装备位置点等具体内容,提出了一种基于马尔可夫决策过程和深度Q学习的训练算法,使兵棋算子具备了一定意义的智能性。赖俊等[5]针对在室内无人机搜索中目标搜索效率不高、准确率较低等问题,提出了一种基于近端策略优化(Proximal policy optimization,PPO)算法[9]的训练方法,可有效地缩短训练周期,同时提升搜索效率和准确率。王旭等[7]利用兵棋推演分析了城市内涝灾害应急联动体系建设,说明了智能兵棋推演在现实应用中同样具有较好的应用前景。
研究表明,人工智能[6]在智能推演与分析方面受到广泛关注,并在近年的全国兵棋推演大赛上初露端倪[10]。但是在宽泛条件下的收敛问题以及收敛速度问题,依然还缺乏有效地解决方法,特别是在对抗方面,采用融和深度强化学习的算法仍面临挑战。为此,基于PPO的作战实体博弈对抗算法,围绕基于深度强化学习的智能兵棋推演方法,本文将进行以下研究:
(1)态势感知与动作决策。即算子通过感知地图态势,并通过分析态势信息决策下一步的动作。主要解决思路为使用神经网络模拟人类,以态势信息作为神经网络输入,通过训练神经网络参数以达到智能化;
(2)加快训练收敛速度。即解决智能体训练过程中奖励稀疏[8]造成的智能体策略不收敛以及收敛速度慢的问题。主要解决思路为使用监督学习进行与训练以及设计额外奖励并将其加入训练过程;
(3)提升算子智能体训练胜率。即提升智能体在训练过程中对抗特定规则智能体的胜率。主要解决思路为通过监督学习和深度强化学习相结合的方式,以版本迭代的形式提升智能体的胜率。
1 基于PPO的作战实体博弈对抗算法框架
智能兵棋对抗事实上是兵棋智能体的算法战。在目前的兵棋推演对抗环境下,算法面临着如下挑战:地图环境较大,直接使用随机初始化参数的动作决策神经网络进行训练会导致很难达到收敛状态或者陷入局部最优解等情况的发生。为了解决这个问题,本文拟研究一种采用监督学习和深度强化学习相结合的算法,为此建立了相应的作战实体博弈训练框架,如图1所示。

图1 智能博弈训练框架示意图
图1中,使用监督学习算法对特定规则智能体对战数据进行监督学习,将从仿真环境获取的态势信息作为监督学习神经网络的输入,利用人类在当前态势下的动作选择对神经网络进行参数更新,逐渐对神经网络在各种态势信息下的动作选择向人类选择进行拟合。经过对人类对战数据进行监督学习,智能体可以有效对对抗中的一些基本行为进行学习获得初级智能体网络,最后使用深度强化学习算法以及稀疏奖励继续对初级智能体网络进行强化学习训练迭代,获得最终的智能体网络。其中,监督学习部分和强化学习部分是该训练框架的主体内容,起到预训练和迭代生成最终兵棋智能体的作用。
2 基于PPO的作战实体博弈对抗算法
2.1 监督学习部分
本文使用反向传播(Back propagation,BP)神经网络对收集的人类对战数据进行监督学习,神经网络结构设计如图2所示,其主要由输入层、三个隐藏层和输出层组成,其中三个隐藏层激活函数均使用线性整流函数(Rectified linear unit,ReLU),输出层使用Softmax激活函数并选择概率最大的作为动作进行输出。
训练过程使用预先收集的1 000组特定规则智能体对战数据胜方作为训练数据集进行决策学习,训练数据集采用多个不同规则策略加不同程度随机化的智能体相互对抗产生,经过信号前向传播以及误差反向传播对神经网络参数进行训练,其中训练过程中代价函数如下
(1)


图2 神经网络示意图
在参数更新过程中,通过事先收集的特定规则智能体对战数据根据当前态势做出的动作决策与当前神经网络计算做出的动作决策进行比对,再经过反向传递对神经网络参数进行更新,训练完成之后可以作为初级智能体网络作为深度强化学习的初始智能体网络。
2.2 深度强化学习部分
2.2.1 PPO算法
本文的深度强化学习算法使用PPO算法,该算法结合了Q-Learning和深度神经网络的优势,是一种基于Policy Gradient和Off-Policy的学习深度强化学习算法[2],其相较于置信域策略优化(Trust region policy optimization,TRPO)算法更加易于实现,PPO算法将TRPO算法中的约束作为目标函数的正则化项,降低了算法求解难度。同时PPO算法采用截断(clip)机制,其参数更新公式如下
(2)
式中:Lclip(θ)为目标函数:
(3)
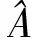
clip直观示意图如图3所示。
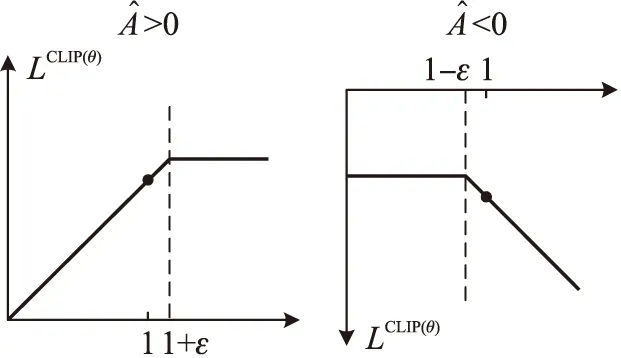
图3 clip直观示意图
2.2.2 深度强化学习中的Reward Shaping
稀疏奖励问题是深度强化学习在解决实际任务中面临的一个核心问题,其本质是在深度强化学习过程中,训练环境无法对智能体参数更新起到监督作用。在监督学习中,训练过程由人类对战进行监督,而在强化学习中,奖励承担了监督训练过程的作用,智能体依据奖励进行策略优化,在本文所讨论的仿真环境中,由于兵棋推演环境只针对动作进行规则判断以及交战决策,并不在发生机动或者交战之后提供任何奖励信息,只会在我方算子到达夺控点或者全歼敌方算子之后发送胜利信息或者敌方算子到达夺控点或者我方算子被全歼之后发送失败信息两种情况,也即在训练过程中的每一步都是无奖励的,推演状态的具体步骤如图4所示。稀疏奖励的问题给算法收敛带来了一定的负面影响,甚至于导致算法无法收敛。

图4 仿真环境奖励示意图
本文使用额外奖励法解决稀疏奖励问题,经过对推演环境进行分析可以发现,由于推演环境判断对抗胜利条件为到达夺控点或者全歼敌方算子,无法满足获胜条件时,通过计算剩余算子血量来判断胜负,因此本文在训练过程中根据上述经验加入了额外奖励,同时为了防止智能体在探索过程中陷入局部最优的情况,加入了智能体获胜之前每多一个回合都会接受惩罚。具体额外奖励设置规则如表1所示。

表1 额外奖励表
经过验证,训练过程在加入上述额外奖励之后,训练过程中收敛速度可以得到明显加快,通知智能体陷入局部最优的情况也明显减少。
2.3 深度强化学习流程
在使用监督学习对人类数据进行模仿学习之后,初级智能体网络已经可以针对一些场景也即状态信息模仿人类对战数据进行决策,但在实际对抗过程中,还需要对更多的场景进行探索,因此还需要在监督学习训练的基础上进行深度强化学习进行自主探索学习,同时使用表1中的额外奖励对智能体行为进行修正。
本文所采用的深度强化学习算法主要流程如下。

3 智能仿真推演算法建模与设计
3.1 仿真推演环境
本文所涉及算法基于某在研兵棋推演对抗环境进行设计与仿真。仿真环境基于Python实现,主要形式为回合制兵棋对抗,仿真地图为由六角格构成的多地形环境,对战双方各有两个算子(坦克),此外还有一个夺控点,获胜条件为任一算子到达夺控点或者全歼对方算子,无法满足以上条件时,通过计算剩余算子总血量来判断胜负。算法验证时采用基于深度强化学习的智能体与基于规则的程序对抗的方式进行。图5为一部分仿真环境地图,地图基本地形信息包括城镇居民地、松软地、道路以及高程等,其中地图左边为红方两个坦克算子,右上标有红旗的六角格为夺控点。
仿真环境的主要架构如图6所示,每个回合智能体通过仿真环境获取当前环境的状态信息,以及稀疏奖励设计输出本回合奖励,并通过智能体中已经训练完成的或者正在训练中的神经网络,输出我方当前回合的动作。
3.2 仿真推演实验
基于上述兵棋推演对抗环境设计仿真实验,智能体输入状态信息也即智能体神经网络输入信息包括两个部分,主要为算子周边地图信息,敌我双方算子信息等。输入状态信息如表2所示。

图5 仿真环境地图(部分)

图6 仿真环境架构

表2 输入状态信息
输出编号与算子执行动作对应表如表3所示。

表3 输出编号与算子执行动作对应表
训练智能体所使用的PPO算法以及神经网络参数如表4所示。

表4 PPO算法及神经网络参数
在本实例中,训练智能体使用的强化学习优化算法为PPO算法,神经网络结构分别为2层的Critic神经网络和3层的Actor神经网络,其中Critic网络的学习率为0.000 9,Actor网络的学习率为0.000 3,单次训练局数为2 000局,训练过程中记录单局累计奖励变化情况。训练完成之后,对训练过程中产生的单局累计奖励变化情况进行可视化,可以看到Agent的训练结果,使用本文算法训练的智能体通过探索环境获得的奖励值曲线图如图7所示,可以看出在监督学习训练完成之后进行强化学习过程中,每个回合结束之后,智能体在本回合获得的总奖励曲线是呈上升态势的;同时,在训练的后期,智能体每回合获得的的总奖励值收敛在12附近,这说明智能体在经过训练之后,找到了在当前状态下取得对战胜利的最优策略。

图7 监督学习+PPO算法奖励曲线图
本文还设计了3组对比实验,其中图8所示为使用单PPO算法对智能体进行训练奖励曲线图,可以看出智能体的总奖励会在1 500局左右收敛在7.1的局部最优点,此时随着训练回合数的提升智能体也无法达到全局最优点;图9所示为不添加额外奖励时对智能体进行训练时的奖励曲线图,此时智能体可以获得的奖励只有0和1两种,经过2000局的训练,奖励值曲线无法达到收敛;图10所示为使用监督学习以及普通策略梯度(Policy gradient,PG)算法对智能体进行训练时的奖励曲线图,可以看出在训练回合数达到1 400局时,可以看出收敛迹象,但是在2 000局训练结束时,依旧无法达到收敛。

图8 单PPO算法奖励曲线图

图9 监督学习+无额外奖励PPO算法奖励曲线图

图10 监督学习+普通PG算法奖励曲线图
训练完成之后,使用多组对比实验训练的智能体与测试智能体集进行实战对抗,测试智能体集采用多种不同规则策略加不同程度随机化的智能体组成。经过对抗发现,仅使用监督学习算法训练的初始智能体进行对抗的胜率为49%,使用单PPO算法训练的智能体进行对抗的胜率为61%,使用监督学习+无额外奖励PPO算法训练的智能体进行对抗的胜率为25%,使用监督学习和普通PG算法训练的智能体进行对抗的胜率为72%,使用本文所述算法训练的智能体对抗的胜率为85%。
4 结束语
本文基于兵棋推演对抗环境,针对强化学习算法在智能兵棋训练中的无法快速收敛以及智能体对抗特定规则智能体胜率较低的问题,提出了一种监督学习和深度强化学习相结合的作战实体博弈对抗算法。实例验证表明,该算法可以通过较短时间的训练使智能体在探索环境时获得的奖励值稳步提升,同时在对抗特定规则策略智能体时的最终胜率可以达到85%,有效地解决了在大地图兵棋推演对抗环境下智能体神经网络随机初始化和稀疏奖励等问题带来的收敛困难的缺陷。
猜你喜欢
现代电力(2022年2期)2022-05-23
云南大学学报(自然科学版)(2022年1期)2022-02-21
军事文摘(2020年19期)2020-10-13
校园英语·上旬(2020年1期)2020-05-09
电子制作(2019年19期)2019-11-23
军事运筹与系统工程(2019年3期)2019-08-13
电子制作(2019年24期)2019-02-23
军事运筹与系统工程(2018年4期)2018-03-26
军事运筹与系统工程(2018年2期)2018-02-16
卷宗(2017年16期)2017-08-30
